基于面部特征与深度学习的疲劳驾驶状态检测研究
2021-07-02马雪婷费树岷
马雪婷,费树岷
(东南大学自动化学院,江苏南京,210096)
1 概述
随着机动车辆的大幅度增长,道路交通安全事故频发。研究表明疲劳驾驶是引发道路交通事故的重要原因之一[1-2],如果能够在交通事故发生前检测出驾驶员疲劳驾驶行为并及时给出提醒则可以减少事故发生。因此研究驾驶员疲劳状态检测对于提高道路交通安全具有极为重要的意义。
目前应用于检测疲劳驾驶的方法主要有以下三类:第一类是使用驾驶员的生理指标如脑电信号特征进行检测[3-4];第二类是使用驾驶员的行车数据如转向力、制动力等物理量进行检测;这两类检测方案主要缺陷是安装佩戴设备会降低驾驶员的驾驶舒适度,而且设备价格昂贵不利于疲劳驾驶检测产品的推广和应用。第三类检测方法是基于驾驶员面部行为信息的计算机视觉技术。
深度卷积神经网络在图像分类、目标检测、场景分割等计算机视觉任务颇有成效,人脸包含丰富的信息,因此可将人脸特征信息和深度学习相结合,而且不会干扰驾驶员的正常驾驶。徐[5]等人提出了基于AdaBoost算法检测人脸实现疲劳驾驶状态的检测;唐[6]等人提出了基于卷积神经网络模型定位人脸关键点,利用最大类间方差法对人眼嘴部进行最小二乘法椭圆拟合进行状态判别;文献[7]利用基于shuffle-channel思想的MTCNN模型和PFLD深度学习模型分别检测驾驶员人脸图像和检测人脸关键点,再用多特征融合的策略判定疲劳状态。 然而深度学习由于其本身庞大的结构规模,拥有较多参数冗余,如何提高检测方法的准确性和实时性依然是疲劳驾驶检测的研究重点。
针对以上问题,本文提出了一种基于面部特征和深度学习的疲劳驾驶状态检测算法。首先使用改进的卷积神经网络结构(CascadeCNN)快速检测人脸,然后利用轻量级特征提取最小单元确定面部关键点位置,采用基于眼睛纵横比和嘴唇纵横比的方法确定疲劳和清醒状态,最后通过支持向量机(SVM)的方法进行疲劳驾驶状态的判定。实验借助Python和Caffe深度学习框架实现疲劳检测,并将该算法与其他算法的性能作比较,展示了该算法在识别精度和检测速度上的优越性。
2 疲劳驾驶状态检测算法整体框架

图1 疲劳驾驶状态检测算法框架
3 级联卷积神经网络人脸检测
Li[8]等人受到AdaBoost算法[9]级联结构的启发,提出一种由粗到精的卷积神经网络结构(CascadeCNN),很大程度上提高了人脸检测速度,由于网络数量较多,故训练难度较大。文献[10]提出了使用全局平均池化层的结构来代替传统的全连接层的结构可以大大的减少网络结构参数量,所以本文提出了一种以边界框回归代替CascadeCNN中的人脸分类网络与边界框矫正网络来减少级联的卷积神经网络数量,并引入全局池化层代替全连接层。使用本文的网络对人脸图像的处理结果如图2所示。蓝色边界表示由该网络检测到的人脸区域,显然比采用传统的非极大值抑制算法绿色边界检测的更准确。

图2 使用本文研究网络的人脸检测图
4 人脸关键点检测
人脸关键点的位置在眼睛、嘴巴、鼻子以及人脸边缘轮廓等。人脸关键点检测是使用相应的检测算法对人脸图像定位出关键点所在坐标。文献[11]提出了一种三级级联卷积神经网络结构由粗到精来定位关键点。文献[12]提出卷积神经网络中卷积层占据了整个卷积神经网络约 90-95%的计算时间,故本文设计了一种基于深度可分离卷积结构[13]的轻量级特征提取最小单元。该最小单元结构首先使用逐点卷积以降维减少运算量,再使用深度卷积与逐点卷积结合提取特征,最后使用短连接结构连接输入与输出特征到最后的单元输出。
由图3和图4卷积操作计算深度可分离卷积如公式1所示。

图3 逐点卷积操作图

图4 深度卷积操作图

其中Y为输出特征图,K为卷积核,X为输入特征图,i,j为特征图中像素点的位置,k,l为输出特征图的尺寸,m为输入特征图的通道数。使用这种卷积结构与标准的卷积操作所减少的参数量比例如公式2所示。
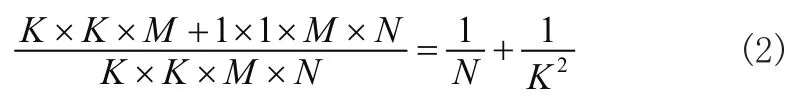
其中K为卷积核尺寸,M为输入特征图的数量,N为输出特征图的数量。由公式2可知,当卷积层输出的特征图数量越多时,使用深度可分离卷积操作相对于标准卷积操作的参数压缩率就越高。在使用3×3的卷积核时,网络的参数量可以压缩至标准卷积结构的1/8~1/9。在单元输出的最后添加短连接结构[10]将输入特征图与输出特征图连接,解决深度卷积结构梯度退化的问题,结构如图5所示。

图5 短连接结构
网络输入X与输出Y的关系如公式3所示。
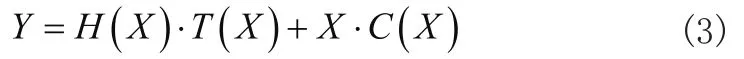
其中,H表示输入特征图经过卷积网络转换后的信息,X表示原始特征图的信息,而T和C分别为两条支路的权重系数。使用该网络得到的68点人脸关键点检测结果如图6所示。

图6 68点人脸关键点定位效果图
5 疲劳状态判定
5.1 基于EAR和MAR的测评原理
EAR即眼睛纵横比,文献[14]提出可以通过眼睛地标距离确定一个人是否眨眼,根据图9标定的二维坐标点得出EAR值的计算公式如式4所示。


图7 眼睛关键点坐标
当眼睛睁开的时候,EAR值基本保持不变,在小范围内上下浮动。当驾驶员疲劳驾驶时,人会不停地眨眼甚至闭合,考虑双眼的动作基本一致,将双眼的EAR值的均值作为人眼的EAR值[15],取0.3作为眼睛闭合的临界阈值。当人进入疲劳状态时,眨眼频率会变高,故可通过眨眼频率(即单位时间内眨眼次数)来判断驾驶员眼部是否疲劳。眨眼频率 fb如公式5所示。

式中NB表示时间T内发生眨眼的次数,由EAR值得出,N是时间T内的总帧数。
MAR即嘴唇纵横比,与EAR的测评原理相似。正常状态下,人的嘴巴是闭合或者说话时的微张状态,然而当进入疲劳状态时,便会不停地长大嘴巴打哈欠,故用MAR值表征嘴巴张开程度,根据图8标定的二维坐标点计算公式如公式6所示。
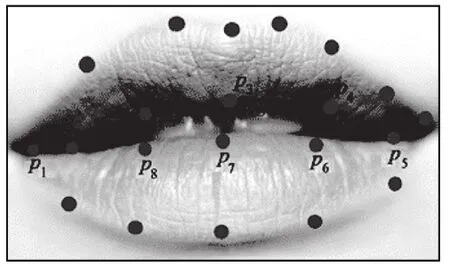
图8 嘴部的关键点坐标

通过打哈欠频率(即单位时间内打哈欠次数)来判断驾驶员嘴部是否疲劳。打哈欠频率 fy如公式7所示。

式中NY表示时间段T内发生打哈欠的次数,由MAR值得出,N是时间段T内的总帧数。由文献[16]可知,设定MAR的阈值为0.9,当大于此值时,便判定驾驶员打了一次哈欠。
5.2 基于SVM的疲劳驾驶检测原理
SVM通过建立一个分类超平面作为决策平面,将正反例之间的间隔最大,将分类转化为凸二次规划问题进行求解。本文研究的疲劳驾驶状态检测属于二分类问题,获取的眼睛和嘴巴特征的数据没有规律性属于非线性分类问题,因此适合采用SVM算法作为模型的分类算法。本文通过计算视频样本中与标记为疲劳视频的重叠帧数Nover,当Nover与视频样本总帧数Ntotal的比值不小于80%时,则标记该样本为疲劳视频,否则为清醒视频。计算公式如式(8),(9)所示。

采用交叉熵作为疲劳识别网络的损失函数,计算公式如式10所示。
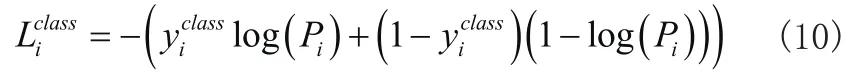
6 实验结果与分析
本文实验采用普通的摄像设置FPS为30,处理器的型号是Intel Core i7-6700。采用基准人脸数据集WIDER FACE[17]进行训练,其中50%作测试集,40%作训练集,10%作验证集。人脸关键点检测模型使用300-W评测集[18],每幅图像的每张脸有68个关键点,使用3148幅图作为训练集,689幅图作为测试集。该模型在驾驶环境下的检测效果图如图9,10所示。

图9 驾驶环境下的人脸检测效果

图10 驾驶环境下的人脸关键点检测效果
为了验证该算法对于真实环境的检测效果,在光照充足的环境下,采集10段分别为清醒状态和疲劳状态的视频,每段时长1min。由文献[19]可知,选择综合性能较好的120帧作为时间窗口长度。人的一次疲劳行为约为3~5秒,所以截取5s的视频样本足以覆盖所有疲劳动作的时长。采用滑动窗口对采集到的视频进行处理得到3928段视频作为训练和测试样本,其中标记疲劳状态样本947个,清醒状态2743个,正负样本比例约为1:3,训练集和测试集比例设为7:3。根据该模型的疲劳特征提取方法对整个样本集进行特征提取,然后送入疲劳识别网络。本文SVM模型选择高斯核函数,惩罚因子C为7,参数degree值6。当仅采用 fb和 fy作为检测指标时,准确率仅为83.2%和69.7%,而采用二者融合时,准确率为96.68%,测试结果如表1所示。

表1 疲劳驾驶检测结果
由表1结果可知,本文算法仅对第1982样本状态判断错误,对于其他视频样本均判断正确。
与基于生理信号检测疲劳状态的文献[20]的识别率90%和基于AdaBoost算法的文献[21]的识别率96.47%和基于卷积神经网络的文献[22]的识别率95.5%相比,本文研究算法有更高的准确率和更快速的检测时间。
7 结论
本文采用改进的三级级联卷积神经网络和深可分离的最小特征单元网络作为人脸的检测和脸部关键点的定位的网络结构,对采集的真实场景的驾驶视频的帧图像进行人脸检测、定位并识别出眼部和嘴部两个关键部位,大大减少了传统卷积神经网络的参数量,在保证网络的准确率下,提高了网络的运行速度。根据眼部和嘴部关键点坐标计算出EAR和MAR值,根据二值的大小确定眼部和嘴部疲劳状态,最后使用SVM分类算法进行疲劳驾驶状态判定,算法的识别率达96.68%。与同研究方向的其他算法相比有较高的准确率和运行速度,此外该算法大幅度减少网络参数量和较高的检测精度,有利于在嵌入式平台上移植开发。
