距离-关键字相似度约束的双色反k近邻查询方法
2021-07-02宋栿尧夏秀峰
张 豪,朱 睿,宋栿尧,方 鹏,夏秀峰
(沈阳航空航天大学计算机学院,沈阳 110136)
(∗通信作者电子邮箱13623212292@163.com)
0 引言
随着移动互联网技术的不断发展,基于位置的社交网络(Location-Based Social Network,LBSN)服务应用越来越广泛。许多学者研究了面向LBSN 的查询处理问题应对不同服务类型下的业务请求。
在众多查询处理问题中,面向反k近邻空间关键字(Reverse Spatial KeywordkNearest Neighbor,RSKkNN)[1]查询是一类重要问题,在市场分析、决策支持和交通信息等领域具有重要应用。具体地,在客户推荐系统中,该查询可以帮助商家根据客户偏好有针对性地利用短信等手段为客户推荐商品信息,从而增加营业收入。在交通信息管理领域,它可以通过分析乘客的用车偏好和位置信息,为乘客推荐车辆。
传统反k近邻查询可分为单色反k近邻查询(简称单色查询)和双色反k近邻查询(简称双色查询)。具体地,给定一组对象o和一个单色查询q,查询返回所有以q作为其k近邻的对象。与之不同,给定一组用户U、一组设施F和一个双色查询设施q,查询返回以设施q为k近邻的所有用户。反k近邻查询主要应用于推荐场景,其中单色反k近邻查询主要应用于同类型对象之间的推荐。例如,为某位用户推荐一些与他距离比较近的志趣相投的人。而双色反k近邻主要应用于两种不同类型对象之间的推荐,相较于单色反k近邻查询的应用更加广泛,比如推荐场景中更多的是为商场提供潜在的消费者,为司机提供潜在的乘客等,这些都是单色反k近邻查询无法做到的,所以本文重点研究双色反k近邻。接下来本文以k=2 为例简单说明传统反k近邻的查询规则,如图1(a)所示,对象{o0,o1,o5,o6}的k近邻对象包含q,所以对象q的单色反k近邻查询返回结果为{o0,o1,o5,o6};如图1(b)所示,用户{u0,u5,u6,u7,u9}的k近邻设施包含q,所以设施q的双色反k近邻查询结果为{u0,u5,u6,u7,u9}。本文研究双色反k近邻查询。
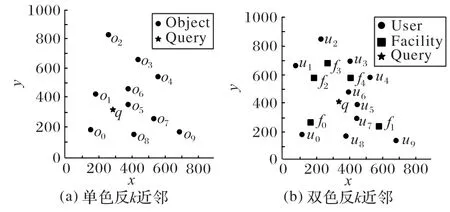
图1 传统单色和双色反k近邻Fig.1 Traditional monochromatic and bicolor reverse k nearest neighbors
传统反k近查询不能根据设施和用户需求针对性地返回查询结果,而带关键字约束的反k近邻查询可以很好解决此问题。鉴于此类问题的重要性,许多学者针对此类问题展开研究。例如:Lu 等[1]首次研究了基于关键字约束的反k近邻查询问题。给定查询点q和对象集合D,查询计算q和D中对象空间上的距离以及关键字间的相似性。以此为基础,算法利用打分函数评价各对象对于查询点q的重要性,并返回得分最高的k个对象。Zhao 等[2]提出了一种相关反近邻布尔空间关键字查询(Ranked Reverse boolean Spatial Keyword Nearest Neighbors,Ranked-RSKNN)问题。该查询返回一定数量与查询点相关程度最高的对象。
然而,这些研究存在的共性问题是没有考虑查询点与查询结果的距离对查询结果造成的影响,很多距离查询点很远但是关键字相似度较高的对象也将返回给用户。显然,和一些距离查询点较近但关键字相似度较低的对象相比,这些查询结果的质量较低。
因此,本文研究距离-关键字相似度约束的双色反k近邻(Distance-Keyword ReversekNearest Neighbor,DKRkNN)问题。和以往研究不同,DKRkNN 通过引入阈值φr过滤掉一些距离查询点相对较远的用户。为高效支持此类查询,本文需面对以下挑战:
1)高效的过滤能力。空间文本数据同时具有空间位置和关键字属性。因此,如何同时根据空间位置和关键字对数据进行筛选是极具挑战的。
2)高效的验证能力。对每个用户进行验证都需要遍历一次设施集。因此,在验证时如何尽可能少地遍历设施是极具挑战的。
针对上述挑战,本文提出了一种基于多分辨率网格树查询处理框架支持查询。本文主要工作如下:
1)提出了一种关键字多分辨率网格矩形树(Keyword Multiresolution Grid rectangle-Tree,KMG-Tree)索引管理设施和用户数据。该索引同时具有以下优点:①通过对网格中的单元格添加关键字信息,以达到通过这两个属性批量过滤数据的目的;②相对平衡的结构,通过对传统的多分辨率网格进行改进,KMG-Tree 用分辨率较高网格划分数据密集的区域;用分辨率较低网格划分数据稀疏的区域。这样一来,它可以保证索引各节点维护的对象数目大致相同从而保证了索引的平衡性。
2)提出了基于Six-region-optimize 的过滤算法。该算法将整个空间等分为6 个区域,根据位置关系定义过滤区域。这样一来,被过滤区域覆盖的网格节点可被安全过滤。此外,与查询点关键字无交集的网格节点也可被安全过滤。
3)提出了基于Six-region-optimize 的验证算法。在验证用户时,只需要访问该区域及相邻区域的对用户可能有影响的设施,这样可以快速找到用户的最近邻及k近邻,一定程度上提高了验证的效率。
1 相关工作
LBSN平台的数据规模越来越庞大,在做大数据查询时首先要对大数据进行分析,例如对于大数据分类问题,Xia 等[3]提出了粒度球邻域粗糙集(Granular Ball Neighborhood Rough Set,GBNRS)分类方法,该方法自适应地为每个对象生成不同的邻域,从而具有更大的通用性和灵活性,并提高了在公共基准数据集上的分类精度和性能。对于大数据“k-均值”问题,Xia 等[4]提出了一种称为“Ballk-means”的方法,用球来描述每个簇,减少了点质心距离的计算,提高了算法的性能。对于大数据噪声监测问题,Xia 等[5]提出了一种完整有效的随机森林方法,通过模拟网格的生成和扩展来检测类噪声,提高了噪声监测的性能。在这些大数据分析的基础上许多学者根据大数据推荐问题研究了反k近邻查询。
区域剪枝是处理空间反k近邻查询的方法之一,其主要思想是将空间分为几个区域,并针对每块区域的空间距离对用户进行剪枝。Stanoi 等[6]提出了一种基于Six-region 剪枝的方法。该方法以查询点为中心将空间分为6 个相等的区域。在每个区域中找到查询点的k近邻设施,以该设施到查询点距离为半径定义剪枝区域。
半空间剪枝法的核心思想是找到查询对q与设施对象f的中垂线。以此为基础,Tao 等[7-8]提出了半空间剪枝的算法,给定一个设施f和一个查询q,f和q之间的垂直平分线Bf:q将空间分成两部分。让Hf:q表示包含f的半空间,Hq:f表示包含q的半空间。Hf:q中的每个用户u满足dist(u,f)<dist(u,q)。换句话说,位于Hf:q中的每个用户u被f剪枝,被k个这样的设施剪枝的用户可以被过滤。Cheema 等[9-11]提出影响区概念,影响区是指当且仅当用u位于该区域内时,u为q的RkNN。建造影响区的方法是绘制所有设施的半空间,被小于k个设施过滤的区域为影响区。Lee 等[12]提出了相关反最近邻查询,该查询通过对数据对象与查询对象q的相关性进行排序,返回受查询对象q影响最大的t个数据对象。
Yiu 等[13]提出了在大型图上的反k近邻查询,并提出了两种剪枝方法:一种是在网络节点被访问后立即进行修剪的急切算法;另一种是在发现数据点时对搜索空间进行修剪的懒惰算法,实现了在大型图上的反k近邻查询。李佳佳等[14]提出了面向时间依赖的路网中的反k近邻查询,该查询提出了计算节点到达时间的方法,利用该到达时间查询出多个候选k近邻结果。Hidayat 等[15]提出了近似反最近邻查询,该查询将一些不是查询点的反最近邻但距离查询点也很近的点返回到了查询结果中。
以上几个算法都只是在空间或路网中反k近邻查询应用很好的算法,并不能够解决反k近邻空间关键字查询问题。Lu 等[1]首次提出了反k近邻空间关键字查询问题,将空间位置和关键字通过度量公式结合在一起,并设计了一种空间文本混合索引结构IUR-Tree(Intersection-Union R-Tree)。Zhao等[2]提出了一种相关反近邻空间关键字查询,简称Ranked-RSkNN。该查询可以返回固定数量的对象,并将这些对象按照查询相关程度的大小进行排序。该查询能保证找到一定数量的结果返回。
然而,在反k近邻空间关键字查询问题中,没有考虑空间距离太远和关键字相似度过低的情况,得到的查询结果并非是查询点所期望的结果。因此,研究基于距离-关键字相似度约束的反k近邻空间关键字查询问题具有重要意义。
2 问题定义
前文已经提到现有的空间关键字双色反k近邻查询都没有考虑查询点与查询结果之间的距离对查询结果造成的影响,很多距离查询点很远但是关键字相似度较高的对象也将返回给用户。显然,和一些距离查询点较近但关键字相似度较低的对象相比,这些查询结果的质量较低。具体地,在商场推销商品的场景下,通过双色反k近邻查询找到了一些潜在的消费者。当k≥2 时,这些消费者可能存在这样一种情况,商场a的位置在城市的中心,但是它的反k近邻中存在某个消费者u在该城市的郊区,在该郊区存在另一个商场b也可以满足u的消费需求,商场a对于u来说太远了,所以消费者u一定不会舍近求远,那么查询返回的消费者u对于商场a来说质量是非常低的。本文针对该问题设置了一个阈值φr,通过阈值φr可以将这些质量非常低的对象给过滤掉。下面详细介绍本文查询问题的形式化定义。
在介绍问题之前,本文首先定义一组符号。给定用户集合U和设施集合F,任意用户u∈U、任意设施f∈F均可用二元组表示。其中,u.l表示了u的位置信息,u.key表示了用户的关键字信息。给定任意查询q,它可用五元组表示。φr表示用户到查询设施距离与其到最近邻设施距离比值的阈值;φk表示用户与查询设施关键字相似度阈值。给定用户u和设施f,本文利用欧氏距离dist(u,f)计算u与f之间的距离。给定u和其最近邻NN(f),本文利用式(1)计算φr,利用式(2)计算u与q所对应关键字的相似程度。接下来介绍关键字-距离约束条件下的双色反k近邻查询。
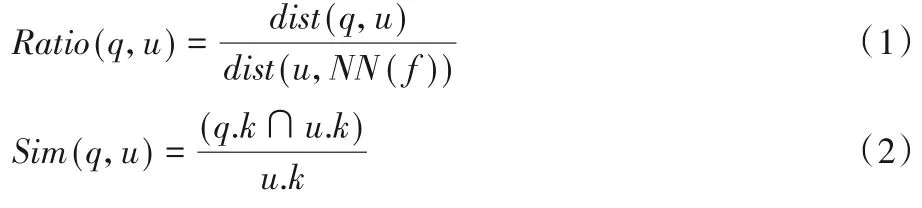
定义1距离-关键字相似度约束的双色反k近邻查询(DKRkNN)。给定一组带关键字的用户U、一组带关键字的设施F、一个带关键字的查询设施q、用户到查询设施距离与到其最近邻设施距离的比值阈值φr和关键字相似度阈值φk,返回满足条件Ratio(q,u) ≤φr和Sim(q,u) ≥φk,并以查询设施q为k近邻的每个用户u。
接下来,通过如下实例详细说明DKRkNN 查询。通过设施和用户来区分不同的数据类型。图1(b)为每个对象在二维空间中的位置。图中五角星q表示商场在空间中的位置,正方形fi表示其他商场在空间中的位置,圆形ui表示用户在空间中的位置(后文图中的正方形点代表设施,圆形点代表用户)。表1 分别为用户以及用户与商场q的关键字相似度、用户到商场q的空间距离。给定查询q,假设查询值k=2、φr=2、φk=0.3,关键字集合为{water,egg,meat,coffee,banana,milk},q的R2NN 为{u0,u5,u6,u7,u9}(见图1(b))。u0的最近邻为f0,u9的最近邻为f1,通过计算发现Ratio(q,u0)=3.05 >2,Ratio(q,u9)=3.47 >2(见表1)。因此,u0和u9不满足要求。进一步地,通过相似度计算发现用户{u5,u6,u7}的关键字信息与商场q的关键字的信息相似度分别为{0.09,0.71,0.50},显然Sim(q,u5)<0.3,最终,查询结果为{u6,u7}。
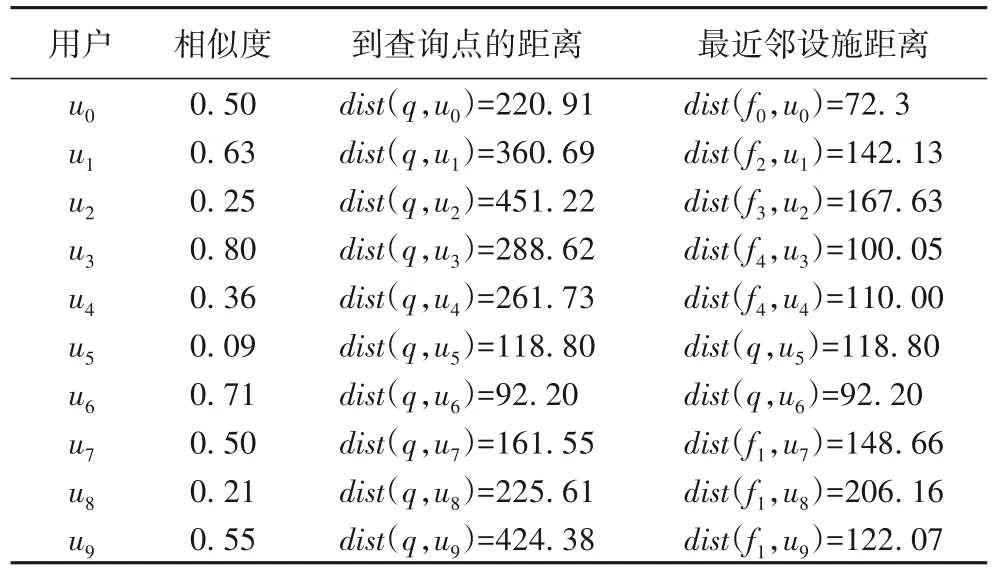
表1 用户与设施之间的关系Tab.1 Relationship between users and facilities
3 基于多分辨率网格树的查询处理框架
3.1 框架概述
本文利用基于Six-region 改进的Six-region-optimize 过滤-验证框架支持基于距离-关键字相似度约束的双色反k近邻查询问题。为支持高效查询,本文首先提出了一种基于数据依赖的多分辨率网格树索引实现数据的高效管理,随后本文提出了一种基于Six-region-optimize 过滤算法实现对用户和设施的过滤,最后本文提出了一种基于Six-region-optimize 的验证算法实现对候选用户的验证。
给定n个带关键字的用户,首先,根据用户空间位置将空间等分为个带关键字信息的单元格。然后,根据单元格中数据的密度对单元格进行合并和分裂操作,从而得到一个多分辨率网格结构。最后,通过多叉树维护网格之间的空间位置关系。该索引可以利用网格的特性降低维护代价,保证索引的平衡性,并在访问过程中根据单元格的关键字信息对用户实现批量过滤。
根据过滤算法得到候选用户集R和用于验证用户的设施集V,根据验证算法对候选集R中的每个用户进行验证。验证每个候选用户需要遍历设施集V,将满足查询要求的用户存储到结果集Result中。
3.2 多分辨率网格树索引KMG-Tree
本文提出了基于关键字多分辨率网格矩形树(KMGTree)索引分别管理用户和设施。该索引是一种以多分辨率网格为基础的数据结构。它对数据密集的区域使用分辨率较高的单元格进行划分,对数据稀疏的区域使用分辨率较低的单元格进行划分,从而保证每个单元格存储用户或设施数量基本相同。
首先,介绍一组KMG-Tree 索引用到的符号。KMG-Tree索引的每个节点t使用一个5 元组表示。KMG-Tree每个节点t唯一标识用t.id表示;t.c是一个数组,用来存储节点t的所有孩子节点;t.leaf是一个标记,它标记节点t是否为KMG-Tree 索引的叶子节点,值为true 表示为该索引的叶子节点,值为false 表示为该索引的非叶子节点;t.k用来存储每个节点中所有对象的关键字信息,该关键字信息是一个基于哈夫曼树构造的一个bit串。算法可以根据每个节点t存储的bit 串快速过滤对象。使用哈夫曼编码表示关键字信息可以有效地降低空间代价。与直接使用节点存储关键字方式相比,基于哈夫曼编码的bit串存储策略可以有效压缩存储空间。
接下来,举一个例子详细说明索引的构建过程。本文首先指定一个阈值m用来表示每个单元格存储对象数量的最大值。以m=2时为例,整个空间存在10个对象,将整个空间划分为个单元格,根据每个单元格中对象的数量判断单元格是否需要进行合并或者分裂。合并和分裂的条件如下:
1)当单元格中对象数量大于m时进行分裂;
2)当单元格中对象数量小于m时进行合并。
经过合并与分裂之后得到的逻辑空间如图2(a)所示,C0包含四个节点C1、C2、C3和C4;C1包含两个对象u1和u2;C2包含两个节点C5和C6;C3包含一个对象u0;C4包含两个节点C7和C8;C5包含一个对象u3;C6包含两个对象u4和u6;C7包含两个对象u5和u7;C8包含两个对象u8和u9。这时所有单元格都满足对象数量的限制。将C1、C3、C5、C6、C7和C8的leaf值设置为true。构建完成后的KMG-Tree 索引结构如图2(b)所示,索引中每个节点以及每个单元格集成对应的关键字集合存储在t.k中。
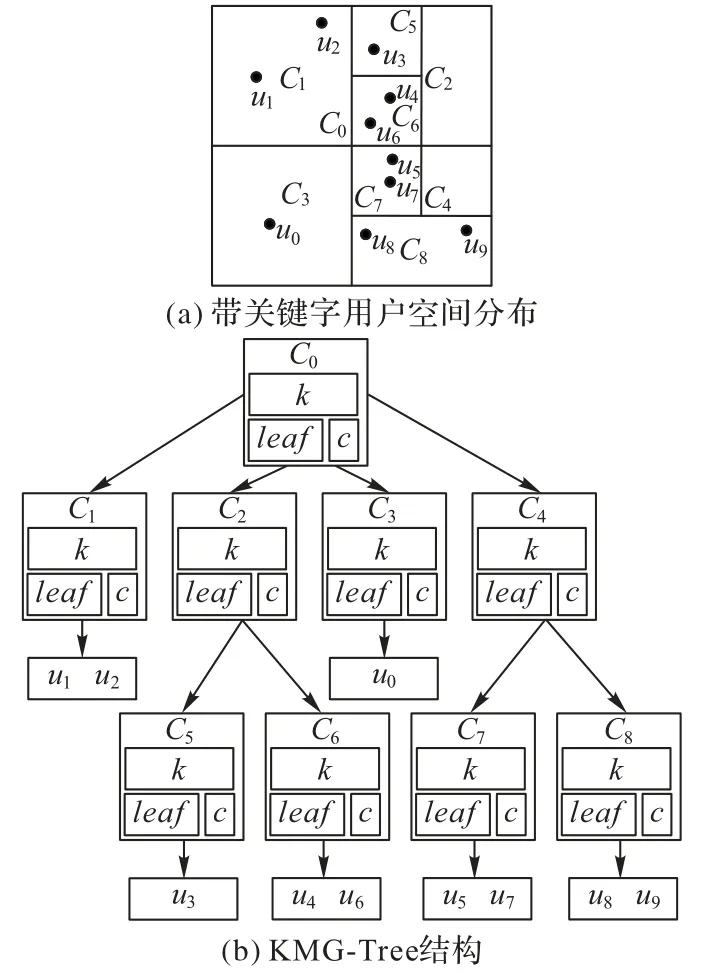
图2 索引结构示意图Fig.2 Schematic diagram of index structure
接下来,介绍构建KMG-Tree时间复杂度。构建KMG-tree索引需要遍历所有的对象,构建用户索引首先遍历所有用户时间代价为O(|U|),遍历过程需要将用户存储到网格节点中。根据网格划分得到个单元格,索引的高度为分裂与合并的时间代价为所以构建用户KMG-Tree 索引的总代价为O(|U|+同理构建设施KMG-Tree索引的总代价为
3.3 基于Six-region-optimize的过滤算法
Six-region 算法在处理双色反k查询时,不仅没有考虑关键字因素,而且只是对用户进行了过滤,这样在验证用户时需要遍历整个设施R-tree。针对以上问题本文提出了基于Sixregion 改进的过滤算法Six-region-optimize,该算法结合设施空间位置与关键字结合对用户和设施进行过滤。在介绍算法之前先介绍一个引理和一个定理。
引理1以查询点q为中心将空间划分为6 个相等区域,在区域i(i=0,1,…,5)中,找到距离设施q第k近的设施fk。以q为圆心、ri=dist(q,fk)为半径做一个扇形seci,位于seci外面的用户可以被过滤。
证明 在区域i(i=0,1,…,5)中,位于seci外面的任意用户u的kNN一定不包含q,因为在seci里面一定存在k个设施满足dist(u,f) <dist(u,q)。
定理1以查询点q为中心将空间划分为6 个相等区域,在区域i(i=0,1,…,5)中,以q为圆心、2Ri为半径做一个扇形SECi,位于SECi外面的设施可以被过滤。其中Ri为区域i及其相邻区域中r的最大值。r是根据引理1 得到的每个区域的seci的半径。
证明 在区域i(i=0,1,…,5)中,位于SECi外面的任意设施f一定不会影响查询点q成为任何候选用户u的kNN。因为每个区域中的任意候选用户u一定满足dist(q,u) ≤Ri,而位于i区域SECi外面的任意设施f一定满足dist(f,u) ≥Ri。
接下来,介绍基于Six-region-optimize 的过滤算法。该算法过滤过程分为批量过滤和局部过滤。针对用户的批量过滤,在遍历用户KMG-Tree 过程中根据定理1 对用户在空间位置上进行过滤,在区域i(i=0,1,…,5)中位于seci外面的网格节点可以直接被过滤。然后,根据关键字信息对用户进行过滤,没有被直接过滤的网格节点t需要检查该节点的关键字信息,如果t满足t.k∩q.k=∅,则t可以被直接过滤。针对用户的局部过滤,访问那些没有被直接过滤网格节点的用户,根据定理1 过滤掉那些在区域i(i=0,1,…,5)中位于seci外面的用户。
例如图3(a)所示,以查询q为中心的整个空间被划分为六个相等的扇形区域S0~S5。在区域S1和S2中,查询点q的2近邻设施分别为f4和f0,所以基于这两个设施定义了这两个区域的过滤空间,如图中阴影部分。被阴影部分完全覆盖的网格节点可以直接被过滤;被部分覆盖的网格节点将访问所包含的网格节点或用户,并将位于过滤空间中的网格节点或用户过滤。这样一来,算法无需要遍历所有用户便可批量过滤掉不满足要求的用户。
针对设施的批量过滤,在遍历设施KMG-Tree过程中根据定理1 对设施在空间位置上进行过滤,在区域i(i=0,1,…,5)中位于SECi外面的网格节点可以直接被过滤。针对设施的局部过滤,访问那些没有被直接过滤网格节点的设施,根据定理1过滤掉那些在区域i(i=0,1,…,5)中位于SECi外面的设施。
例如图3(b)所示,在区域S1和与其相邻的两区域S0与S2中,f4、f5和f0分别在各子区域中为查询q的2 近邻。它们满足不等式dist(q,f0) >dist(q,f4) >dist(q,f5)。设R1=dist(q,f0),在区域S1中以R1为半径做扇形SEC1,SEC1定义了过滤空间,如图中阴影部分。被阴影部分完全覆盖的网格节点可以直接过滤;被部分覆盖的网格节点将访问所包含的网格节点或设施,并将位于过滤空间中的网格节点或设施进行过滤。这样一来,算法无需要遍历所有设施便可批量过滤掉不影响候选用户的设施。
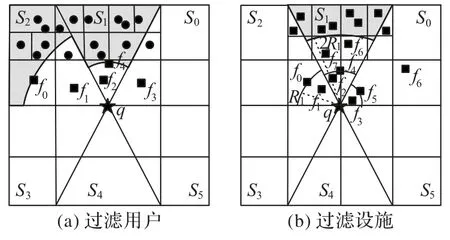
图3 空间属性过滤用户和设施Fig.3 Spatial attributes filtering users and facilities
基于Six-region-optimize 的过滤算法见算法1。利用两个队列分别缓存用户节点和设施节点如算法1第2)行。对用户进行过滤,不能被过滤的用户存储到候选用户集合R中如算法1的第2)~7)行。对设施进行过滤,不能被过滤的设施存储到验证集合V中如算法1中第8)~13)行。
算法1 基于Six-region-optimize的过滤算法。
输入 查询设施q,k值,用户树u‑root和设施树f‑root,每个区域扇形半径r;
输出 集合R,集合V。


接下来,介绍Six-region-optimize 算法过滤阶段的时间复杂度。该阶段首先需要访问设施KMG-Tree 索引进行空间划分,划分需要的时间代价为O(log|V|)。然后,再同时访问用户和设施KMG-Tree索引,根据划分空间对用户和设施进行过滤,该阶段的时间代价为O(log|V|+log|U|)。整个过滤阶段的总代价为O(2log|V|+log|U|)。
3.4 基于Six-region-optimize的验证算法
Six-region-optimize 的验证算法通过过滤得到候选集R中的每个用户u进行验证,如果用户u同时满足条件1)~3)时将用户存储到最终的结果集Result中。
1)用户u与查询设施q的关键字相似度Sim(q,u)≥φk。
2)以用户u为圆心、dist(q,u)为半径做一个圆,遍历集合V中的设施,圆中的设施数量小于k。
3)dist(u,q)与dist(u,NN(u))的比值Ratio(q,u)≤φr。
以φk=0.3、φr=2 和k=2 为例说明一下。首先,计算候选用户ui(i=0,1,…,3)与查询设施q的关键字相似度Sim(q,ui),如表2 所示,Sim(q,u0)=0.71、Sim(q,u1)=0.63、Sim(q,u2)=0.09 和Sim(q,u3)=0.67,所以u2不是查询结果。然后,检查满足关键字相似度要求的候选用户的kNN是否包含查询设施q,例如图4所示,以u1为中心、dist(q,u1)为半径的圆中有两个设施f1和f6,所以u1不是查询结果。u0和u3为q的R2NN。最后,计算dist(q,u0)与dist(u0,NN(u0))比值Ratio(q,u0)=0.7和dist(q,u3)与dist(u3,NN(u3))比值Ratio(q,u3)=2.5。u3不满足条件,u0为查询结果。
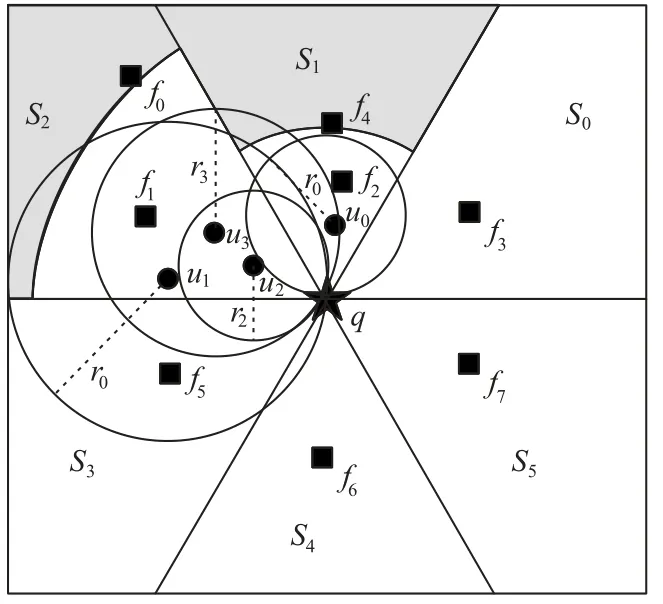
图4 空间范围验证用户Fig.4 Spatial scope authenticating users
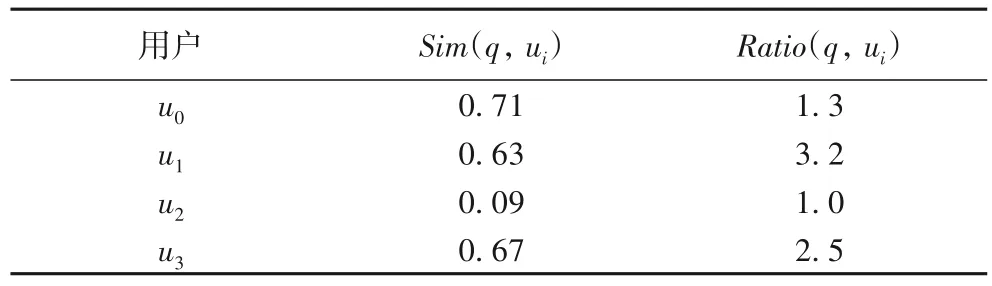
表2 关键字相似度和最近邻距离比值Tab.2 Keyword similarity and nearest neighbor distance ratio
基于Six-region-optimize 的验证算法见算法2。访问候选用户集合R如算法2 中的第2)~3)行。验证关键字相似度是否满足查询条件如算法2 的第4)行。验证用户的RkNN 是否包含查询设施q,并计算是否满足距离约束如算法2 的第5)~11)行。
算法2 基于Six-region-optimize的验证算法。
输入 集合R和集合V,查询设施q,k值,阈值φr和φk;
输出 集合Result。


接下来,介绍Six-region-optimize 算法验证阶段的时间复杂度。在算法的过滤阶段已经得到了候选集R和验证集V。假设候选集的大小为K,验证集的大小为2K。可以明确的是K≪U,并且2K≪V。验证阶段需要或每个候选用户发出一个布尔范围查询,每个布尔范围查询大概需要访问2/3的验证集中的设施,所以该阶段的时间复杂度为
4 实验与结果分析
4.1 实验准备
实验的配置环境为:64 位Windows 10、操作系统,Java 编程语言,实验内存为8 GB,CPU 为Intel Core i5-4460 处理器。采用的数据集如表3 所示,包括两个真实数据集德国(GE)的部分地理位置信息和北京(BJ)的部分地理信息以及一个模拟地理位置的数据集(SD)。
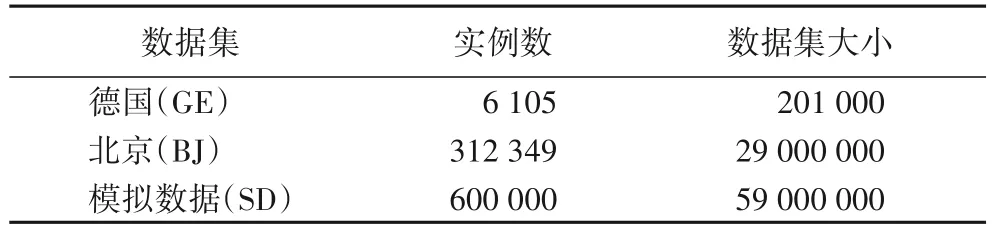
表3 实验数据集统计信息Tab.3 Statistical information of experimental datasets
4.2 结果分析
首先,对本文提出的DKRkNN 查询与Ranked-RSKNN 查询的返回结果进行比较验证该查询返回结果的有效性。然后,使用不同大小的数据集对本文提出的基于Six-regionoptimize的过滤验证算法进行实验分析,将它与最基本的简称baseline 的算法和Stanoi 等[6]提出的Six-region 算法进行对比,验证算法高效性。最后,通过改变参数的大小验证本文所提算法的稳定性。
4.2.1 DKRkNN查询的有效性分析
通过比较DKRkNN 查询和Ranked-RSkNN 查询在三个数据集上的返回结果数量分析DKRkNN查询结果的有效性。如图5 所示,设阈值φr=2 和φk=0.5,设置不同的k值为{5,10,15,20,25}。
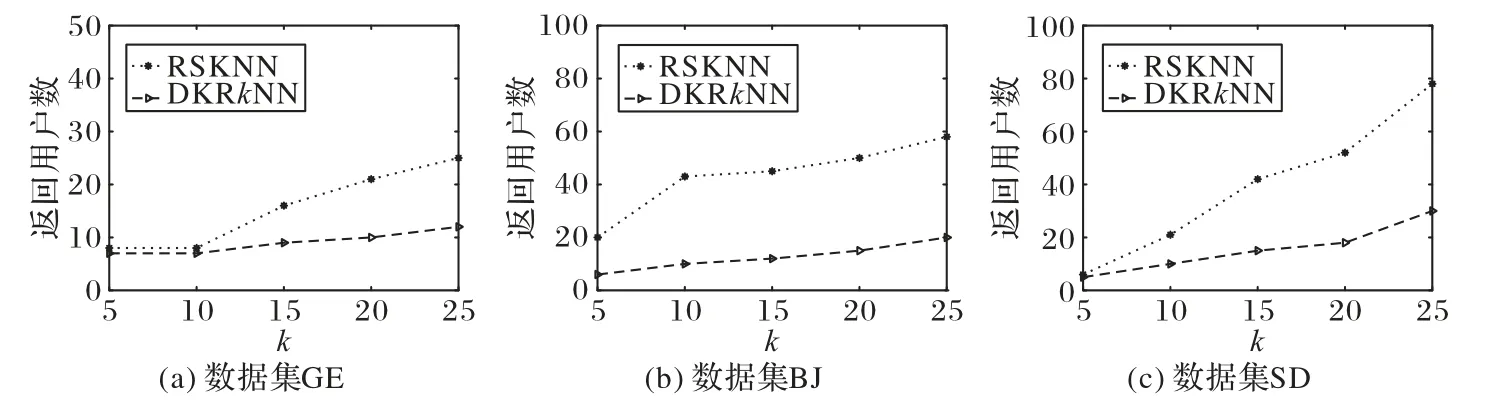
图5 不同k值时Ranked-RSKNN和DKRkNN返回用户数量Fig.5 Number of returned users by Ranked-RSKNN and DKRkNN with different k values
通过图5 可以发现,在不同数据集上,k值越大两个算法返回对象数量差距越大,表明DKRkNN 查询过滤掉的无效的对象越多,从而验证了DKRkNN查询返回结果的有效性。
4.2.2 Six-region-optimize算法的效率分析
通过评估Six-region-optimize 算法、baseline 算法和Sixregion 算法在数据集大小不同时CPU 处理时间的消耗分析算法的效率。数据集的大小不同时实验结果如图6 所示。由图6可以看出,在德国(GE)数据集的大小为6 105时每个算法在时间上的消耗都非常低,Six-region 和Six-region-optimize 算法表现得都不是很优秀。随着数据集的大小不断增加,例如在北京(BJ)数据集的大小为312 349 和模拟(SD)数据集的大小为600 000 时,很明显baseline 算法在时间上的消耗明显增加,而Six-region 和Six-region-optimize 算法时耗增加都不是很明显,而Six-region-optimize 算法时间消耗是最小的,验证了Six-region-optimize算法的高效性。
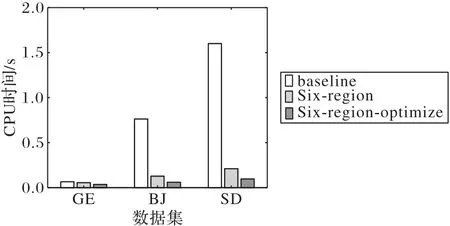
图6 数据集大小对不同算法时间消耗的影响Fig.6 Influence of dataset size on time consumption of different algorithms
4.2.3 Six-region-optimize算法的稳定性分析
接下来,通过改变参数的值比较Six-region-optimize 算法、baseline 算法和Six-region 算法在三个不同数据集上的变化,分析各个参数对于每个算法的影响。
1)k值对各算法的影响。
该组实验设阈值φr=2 和阈值φk=0.5,设置不同的k值为{5,10,15,20,25},三个算法分别在数据集GE、BJ 和SD 上的变化情况如图7 所示。由图7 可以看出,随着k值增加三个算法在CPU 时间上的消耗都在增加,这是因为k值越大满足条件的用户越多,从而过滤掉的数据就越少,需要验证的数据就越多。但是在数据集较大时,k值对Six-region 和Six-regionoptimize 算法的影响很小,表明了k值对这两个算法影响很小,验证了算法的稳定性。
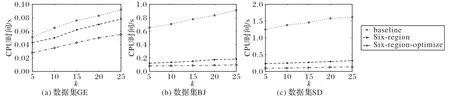
图7 k值对不同算法时间消耗的影响Fig.7 Influence of k value on time consumption of different algorithms
2)阈值φr对各算法的影响。
该组实验设k=5 和阈值φk=0.5,设置不同的φr值为{1.5,2.0,2.5,3.0,3.5},三个算法分别在数据集GE、BJ 和SD 上的变化情况如图8 所示。由图8(a)可以看出,三个算法在数据集GE上都基本不受影响,这是因为数据集GE非常小,距离阈值φr的变化对验证过程影响非常小,从而三个算法在CPU 时间上的消耗也比较稳定。由图8(b)~(c)可以看出,baseline 算法和Six-region 算法随着阈值φr的增加在CPU 时间上的消耗也有较明显增加,这是因为这两个算法在过滤阶段没有将大量设施过滤掉,这样使阈值φr增加时需要访问的设施也会大量增加。Six-region-optimize 算法不会存在这样的情况,该算法在过滤阶段已经把大量不影响结果的设施给过滤掉了,表明了Six-region-optimize 算法在CPU 时间消耗上的稳定性。
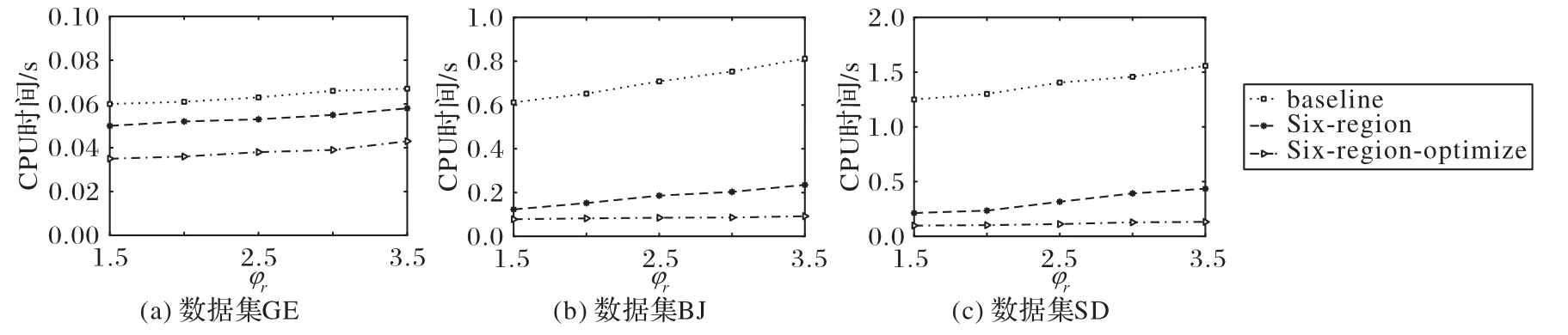
图8 阈值φr对不同算法时间消耗的影响Fig.8 Influence of threshold φr on time consumption of different algorithms
3)阈值φk对各算法的影响。
该组实验设k=5 和阈值φd=9 000,设置φk值为(0.2,0.3,0.4,0.5,0.6),三个算法分别在数据集GE、BJ和SD上的CPU时间消耗变化情况如图9所示。
由图9可以看出,随着φk值的增加,三个算法的CPU 时间消耗基本无变化,这是因为关键字相似度只需要在验证阶段计算一次。所以φk对三个算法都没什么影响,表明三个算法都是非常稳定的。
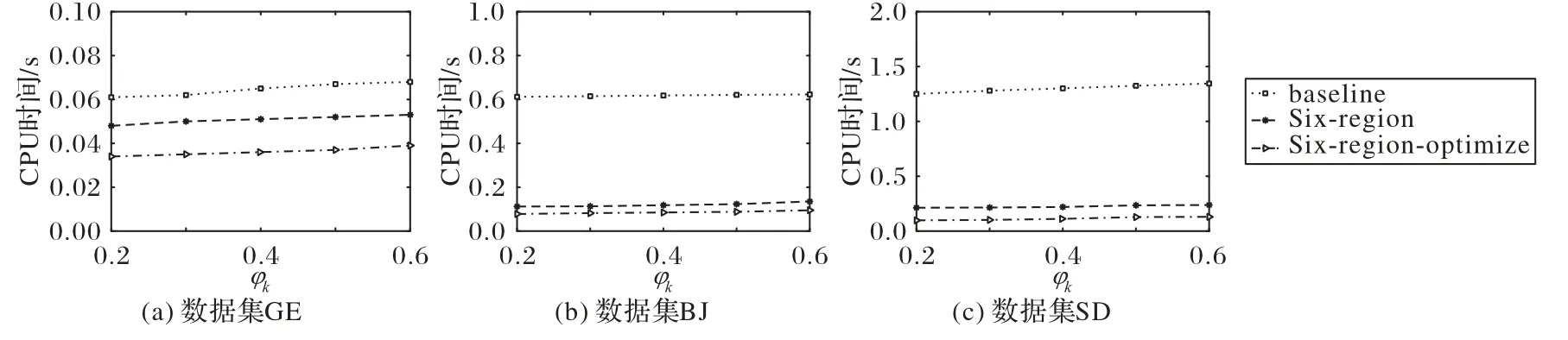
图9 阈值φk对不同算法时间消耗的影响Fig.9 Influence of threshold φk on time consumption of algorithms
5 结语
本文研究了距离-关键字相似度约束的双色反k近邻查询(DKRkNN)问题,并提出了一种基于多分辨率网格树索引查询处理框架。该框架根据区域划分规定过滤区域,访问多分辨率网格树,得到用户候选集和影响用户成为查询结果的设施,对候选用户进行验证,得到最终的结果集。基于两个真实数据集和一个模拟数据集进行实验,实验结果验证了本文算法的有效性和高效性,表明所提框架能够有效处理该查询。但是随着社会的发展,查询的需求会越来越复杂,空间文本信息可能不再是以关键字的方式存在,有可能是一段文字。因此,未来的研究需要对空间文本做语义分析从而为用户提供更高质量的查询体验。
