基于改进的BSMOTE和时序特征的风机故障采样算法
2021-07-02赵计生强保华米路中唐成华李宝莲
杨 鲜,赵计生,强保华*,米路中,彭 博,唐成华,李宝莲
(1.广西图像图形与智能处理重点实验室(桂林电子科技大学),广西桂林 541004;2.北京华电天仁电力控制技术有限公司,北京 100039;3.中国电子科技集团公司第54研究所,石家庄 050081)
(∗通信作者电子邮箱qiangbh@guet.edu.cn)
0 引言
随着风机设备可靠性的不断提高,设备出现故障的概率逐渐变小,导致了风机运行数据集中很大比例都是正常运行的样本数据,而出现故障的样本数据比例非常小,从而使数据集不均衡。不均衡的数据集会对风机部件故障检测[1]的效果产生负面的影响,分类结果往往都会偏向于大类样本。因此在建立分类模型之前,如何对风机数据集进行处理[2-3],消除由不平衡性带来的负面影响尤为重要。
针对不平衡数据集通常使用抽样方法对其进行改善,常见的解决方法主要有欠采样和过采样两种方式,其核心分别是通过合理地减少大类样本数量和增加小类样本数量,以期获得一个较为平衡的数据集。目前国内外学者对抽样方法的研究主要有:Chawla 等[4]提出在少数类样本之间进行插值产生额外样本的SMOTE(Synthetic Minority Oversampling Technique)算法,该算法可能导致样本之间的重叠,生成一些没有提供有效信息的样本,降低分类性能;Han 等[5]在SMOTE算法基础上进行改进提出BSMOTE(Borderline Synthetic Minority Oversampling Technique),该算法仅对边界上的少数类样本合成新样本,减少了未提供有效信息的样本被合成的可能性,但选择样本时未考虑数据集的时序规律,且未对噪声类样本进行过滤;Bunkhumpornpat 等[6]提出一种根据每个少数类样本安全等级来决定是否过采样的Safe-level SMOTE 算法;刘余霞等[7]为了避免过拟合问题,提出了一种基于正例样本子簇簇心距离为标准的过采样算法;陈睿等[8]提出了一种基于BSMOTE 和逆随机欠抽样算法的不均衡数据分类算法;Devi 等[9]通过欧氏距离提出了一种清理噪声样本、重叠样本的欠采样算法Tomek-link,该算法通过减少多数类样本来达到类别平衡,可能使数据集太少导致分类器学习不充分;Georgios 等[10]提出了一种k-means 聚类与SMOTE 相结合的采样算法,解决类间不平衡问题的同时避免产生大量噪声样本,但k-means 聚类与SMOTE 算法都是基于欧氏距离的,没有考虑数据集的时序规律;夏英等[11]提出了一种基于层次聚类的不均衡数据加权过采样算法WOHC(Weighted Oversampling method based on Hierarchical Clustering),该算法根据簇类密度因子决定采样倍率N;李克文等[12]对SMOTE 算法进行改进提出基于欧氏距离度量的SDRSMOTE(Support Degree Random Synthetic Minority Oversampling TEchnique)算法;魏力等[13]结合NearMiss 和k-means 算法提出了一种Clustering-Based NearMiss欠采样算法,根据欧氏距离作为相似性依据来进行欠采样,可能因数据集太少导致分类器学习不充分。
以上处理不平衡数据集的算法在考虑对哪些样本进行采样时,核心思路要么是随机选择少数类样本,要么是基于聚类、欧氏距离选择少数类样本。这两种选择思路并不完全适用于具有时序特点的风机数据:一方面是会破坏风机数据集的时序特点[14],丢失风机从正常状态变为故障状态的信息;另一方面是未对类间重叠样本、噪声类样本进行过滤容易导致模型过拟合,从而降低分类精度。因此,本文提出了一种基于改进的BSMOTE 和时序特征的风机故障采样算法BSMOTESequence(Borderline Synthetic Minority Oversampling Technique-Sequence),在新样本合成时综合考虑了风机数据的时序规律和时空度,并且对噪声类样本、类间重叠样本进行了过滤,形成清晰决策边界。具体工作如下:
1)针对BSMOTE算法随机选择少数类样本点参与合成新样本的问题,采用风机数据的时序特征来解决。该方式生成的新样本综合考虑了空间距离、时间跨度,能有效减少噪声点的生成。
2)针对BSMOTE 算法合成新样本时可能产生噪声点、类间重叠样本,进而导致模型过拟合等问题,采用Tomek Links技术进行过滤处理,对后续模型的训练效率、分类效果有一定改善。
在真实的风机数据上将本文方法与已有的采样方法进行对比,使用支持向量机(Support Vector Machine,SVM)、卷积神经网络(Convolutional Neural Network,CNN)、长短期记忆(Long Short-Term Memory,LSTM)人工神经网络[15-16]作为风机齿轮箱故障检测模型[17],F1-Score、曲线下面积(Area Under Curve,AUC)、G-mean 作为模型性能评价指标,验证了所提采样策略在检测风机故障上的有效性。
1 本文风机故障采样策略模型
1.1 风机故障采样策略模型设计
1.1.1 BSMOTE算法基本思想
Han 等[5]提出的BSMOTE 算法基本思想是对每个处于边界上的少数类样本,通过K最近邻(K-Nearest Neighbor,KNN)算法选出K'个少数类近邻样本,然后从这K'个样本中随机选择K"个样本,轮流与该少数类样本合成新样本。假设原始训练样本为D,其中少数类为P,多数类为N,具体步骤描述如下:
1)计算每个少数类样本p(i)与D中所有其他样本的欧氏距离,获得该样本点的K个近邻样本。
2)对少数类样本p(i)进行分类。设K个近邻样本中多数类样本所占比例为r。若0 ≤r≤0.5,则p(i)是安全类样本;若0.5 <r<1,则p( i)是边界类样本;若r=1,则该p( i)是噪声类样本。
3)计算p(i)与P中所有其他少数类样本的K'个近邻,再从K'个近邻中随机选择K"个与p(i)合成新的少数类样本。
该算法在合成新样本时没有考虑数据集的时序特点,且没有对类间重叠样本、噪声类样本进行过滤,没有一条清晰的分类边界,对后期模型分类性能有一定影响。
1.1.2 BSMOTE-Sequence算法模型
针对BSMOTE 算法的问题,本文根据数据集特点提出了一种BSMOTE-Sequence 算法。该算法合成新样本时,首先标记出边界上的少数类样本x,然后根据空间距离、时间跨度规则选出x的少数类近邻样本集合L,再利用线性插值法合成新样本,最后过滤掉噪声类样本、类间重叠样本。该算法改进了原算法选点时的规则,关注了时序数据在变化过程中包含的关键信息,对后续故障预测有一定帮助;同时增加了过滤类间重叠样本和噪声类样本的过程,可以提高合成样本的可靠性,排除噪声点干扰,提升决策边界的清晰度,为得到良好分类器提供了数据保障。主要有两点改进:
1)将原算法随机选择少数类样本点参与合成新样本的步骤,改进为按照式(1),根据样本的时序特征,计算样本间的时间跨度,选出跨度最小的K"个少数类样本点,按照式(2)参与合成新样本,效果如图1(c)所示。
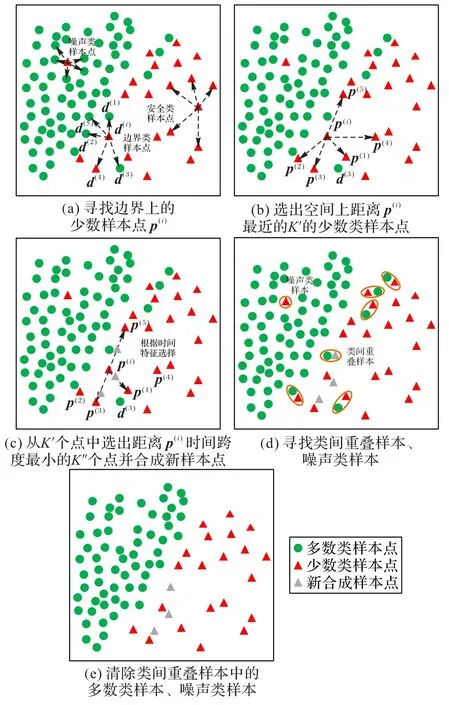
图1 BSMOTE-Sequence算法效果Fig.1 Effect of BSMOTE-Sequence algorithm
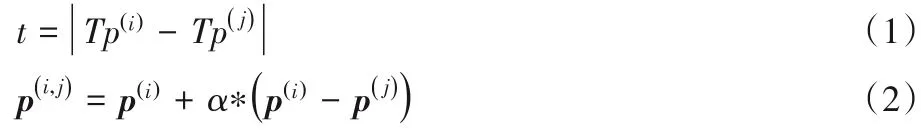
通过该方式生成的新样本综合考虑了空间距离、时间跨度,合成的样本具有一定可靠性,避免合成噪声类样本。
2)在合成完新样本后,按照式(3)~(5),增加过滤类间重叠样本的过程,若不存在其他任意样本d(k)使得式(3)~(4)成立,则p( i)与n( j)互为最近邻样本,需要过滤掉n( j)。再根据每个样本点周围的样本类别比例,增加过滤噪声类样本的过程,若某个样本点周围的样本全是与其类别相反的样本,则该样本点是噪声类样本,需要被过滤掉,效果如图1(d)、(e)。
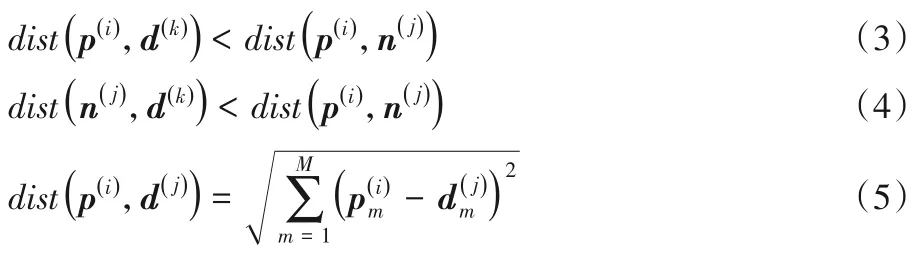
其中:p( i)代表某个少数类样本;n(j)代表某个多数类样本;d(k)代表某个其他任意样本;dist(p(i),d(k))表示样本p(i)与d(k)之间的欧氏距离。
增加该过程能排除噪声点干扰,提升决策边界的清晰度,对后续模型的训练效率及分类效果均有一定改善。
如图2所示,BSMOTE-Sequence算法流程如下:
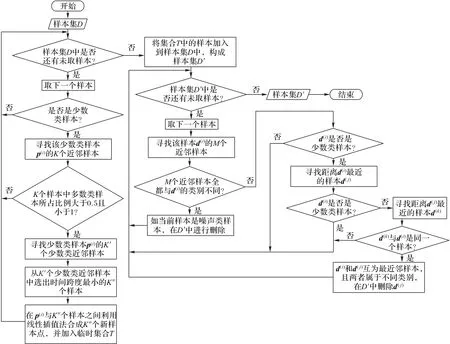
图2 BSMOTE-Sequence算法流程Fig.2 Flow chart of BSMOTE-Sequence algorithm
①对少数类样本集P中的每个样本p(i),按照式(5)计算它到其他所有样本d(j)的欧氏距离,选出距离最近的K个样本{d(1),d(2),…,d(K)}。
②设{d(1),d(2),…,d(K)}中有Np(i)个多数类样本,按照式(6)、(7)计算比例r、判断p(i)的类型Cp(i)。

Cp(i)取0、1、-1 时分别表示p(i)样本是安全类样本、边界类样本、噪声类样本。
③对于每个Cp(i)=1的p(i)样本,按照式(5)计算它到其他所有少数类样本p(j)的欧氏距离,选出空间距离最近的K'个样本{p(1),p(2),…,p(K')}。
④从{p(1),p(2),…,p(K')}中按照式(1),选出时间跨度最小的K"个样本{p(1),p(2),…,p(K")}。
⑤按照式(2)在p(i)样本与{p(1),p(2),…,p(K")}各样本之间合成新样本点{p(i,1),p(i,2),…,p(i,K")}。
⑥将第⑤步中合成的所有新样本点加入到少数类样本集P中。
⑦按照式(5)对P中的每个样本p(i),计算它到每个多数类样本n(j)的距离dist(p(i),n( j))。
⑧若不存在任意其他样本点d(k),使得式(3)或者式(4)成立,则称(p(i),n( j))是一个Tomek Links 对,从每个Tomek Links对中删除多数类样本点。
⑨按照式(6)、(7)计算每个样本周围的样本类别比例,可找出噪声类样本并删除。
1.2 算法实现
BSMOTE-Sequence 算法的伪代码见算法1,输入的是类别不平衡数据集D,其中N表示多数类样本集,P表示少数类样本集。该算法主要有两大步骤:1)第一个for 循环(伪代码第1)行处)是找出满足条件的边界少数类样本点,与它周围的部分少数类样本点合成新样本;2)第二个for 循环(伪代码第11)行处)是过滤掉类间重叠样本、噪声类样本。
算法1 BSMOTE-Sequence。
输入 样本集D,多数类样本集N⊂D,少数类样本集P⊂D;
输出 样本集D'。



2 实验与结果分析
2.1 实验设计思路
本次实验中所用数据集均来自云南某风电厂历史运行数据,如表1 所示。训练集有691 160 条记录,正负样本比例为3∶7。测试集有24 116 条记录,正负样本比例为4∶6。训练集与测试集都有18 个特征,分别是时间、齿轮箱润滑油滤网出口压力、齿轮箱油温、机舱柜温度、U1 项绕组电压、U2 项绕组电压、U3 项绕组电压、U1 项绕组电流、U2 项绕组电流、U3 项绕组电流、发电机冷却温度、发电机滑环温度、发电机转速、叶轮转速、风速1、风速2、风向1、风向2。

表1 数据集信息Tab.1 Information of datasets
为了验证BSMOTE-Sequence 算法在处理不平衡风机数据集中对齿轮箱故障检测任务的有效性,分别使用SVM、CNN、LSTM作为故障检测算法,与未处理、BSMOTE、ADASYN(adaptive synthetic sampling)、Tomek Links、SMOTE+ENN(Edited Nearest Neighbor)、SMOTE+Tomek Links 算法进行对比实验。
2.2 实验评价标准
评估分类模型的性能主要是基于混淆矩阵,它便于观察模型在各个类别上的表现。以二分类任务为例,表2 是其对应的混淆矩阵。其中:TP(True Positive)表示预测为正且真实为正的样本个数;FP(False Positive)表示预测为正但真实为负的样本个数;FN(False Negative)表示预测为负但真实为正的样本个数;TN(True Negative)表示预测为负且真实为负的样本个数。
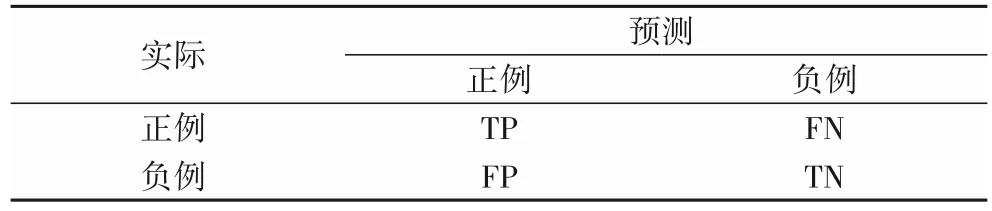
表2 混淆矩阵Tab.2 Confusion matrix
分类器性能评价标准有很多,如准确率(Accuracy,Acc)、精确率(Precision,P)、查全率(Recall,R)、F1-Score(F1)、受试者工作特征(Receiver Operator Characteristic,ROC)曲线、AUC、G-mean 等,然而对于不平衡数据集如果使用单一的准确率、精确率、召回率等指标是不合适的,因为它无法有效地反映对少数类的分类性能。故实验使用F1-Score[18]、AUC、G-mean[19-20]作为评价指标,这些指标能综合衡量分类性能。
F1-Score(F1)是常用来衡量二分类模型的一种评价指标,由于它是精确率和召回率的调和平均,所以能同时对模型的精确率和召回率进行综合衡量,对类别不平衡的数据集非常有效。在不平衡数据集的分类任务中,只有当精确率与查全率都比较大时,F1才会较大,否则其值会接近其中较小者,如式(8)所示。其中,P是精确率,表示在被预测为正的样本中真实结果为正的样本的比率,如式(9)所示;R是查全率,表示在真实结果为正的样本中被预测为正的样本的比率,如式(10)所示。

AUC 为ROC 下的面积,其数值不会大于1。ROC 曲线是由假正例率(False Positive Rate,FPR)作横轴,真正例率(True Positive Rate,TPR)作纵轴绘制而成,其中FPR 是在真实结果为负的样本中被预测为正的样本的比率,如式(11)所示;TPR 是在真实结果为正的样本中被预测为正的样本的比率,如式(12)所示。AUC面积能不受类别分布的影响,有效地评估、比较类别分布不平衡的数据集。

G-mean 指标可衡量分别有多少正例、负例被成功预测出来,其数值不会大于1,如式(13)所示,其中specificity是特异性,如式(14)所示。
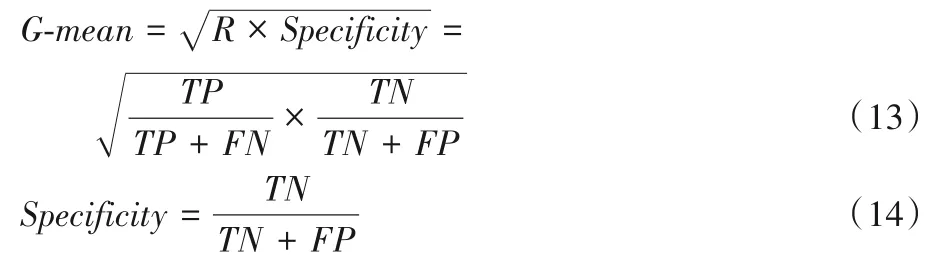
2.3 结果分析
将BSMOTE-Sequence 算法与原始数据直接分类、BSMOTE、ADASYN、Tomek Links、SMOTE+ENN、SMOTE+Tomek Links 等算法进行对比实验,分类器采用SVM、CNN、LSTM。BSMOTE 算法中的采样倍率N等于不平衡率IR×0.5并上取整,最近邻阈值K等于N×3。ADASYN 算法中的合成系数β等于1。Tomek Links 算法中的移除类间重叠样本策略设置为仅移除多数类样本。SMOTE+ENN 算法中的ENN 样本剔除策略设置为若多数类样本其K个近邻点中有超过一半不属于多数类,则剔除该多数类样本。为了消除随机因素的影响,每个算法都取20 次实验的结果,计算F1-Score、AUC、G-mean 的平均值,平均值越大表明分类效果越好。不同算法的实验结果如表3所示。
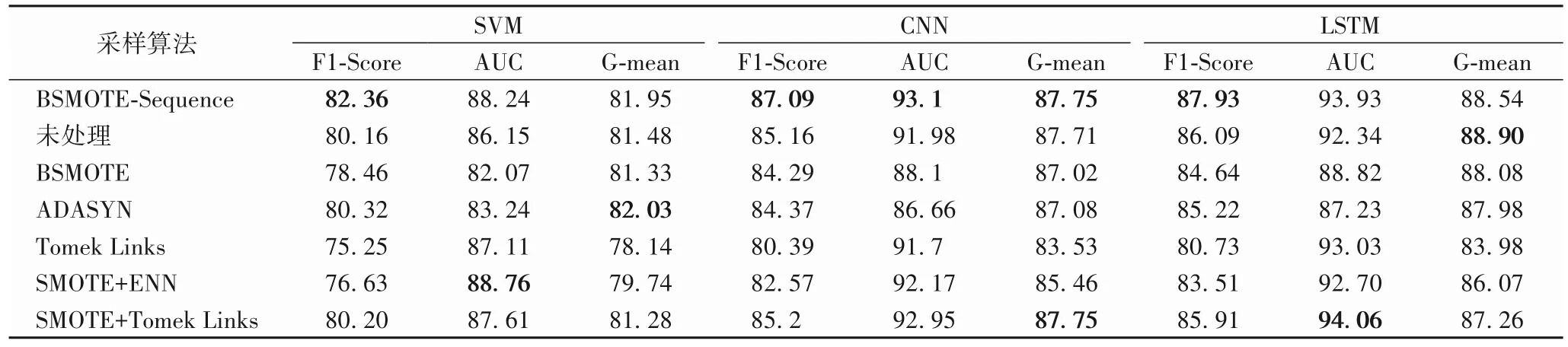
表3 不同采样算法的F1-Score、AUC、G-mean比较 单位:%Tab.3 Comparison of F1-Score,AUC and G-mean of different sampling algorithms unit:%
由表3 中的实验结果可以分析出以下结论:1)BSMOTESequence 算法相较于其他算法,在F1-Score、AUC、G-mean 上都有一定提升。2)仅使用Tomek Links 欠采样技术处理风机数据集,会丢失重要的特征信息,导致分类模型效果不佳,所以其F1-Score 最低。虽然它的AUC 不是最低,但对于不平衡数据集来说F1-Score比AUC更敏感。3)在处理不平衡数据集时,并非所有采样算法都适合,有时可能会适得其反,所以需要具体分析数据集的特点,选择合适的采样算法,才能提高模型分类性能。4)SVM 分类效果不如CNN 和LSTM,因为SVM是传统机器学习算法,需要做更多的特征工程、优化模型参数等操作来提高分类效果。5)LSTM 的分类效果比CNN 好,因为LSTM 能从时序数据中捕捉到重要的特征并进行关联建模,对时序特征的提取更充分,这也进一步验证了在对时序数据集进行不平衡处理时考虑时序规律的重要性。
从整体来看,BSMOTE-Sequence 算法的性能是优于其他对比算法的,这是由于该采样算法充分结合了风机数据集的时序特点,并且只对边界少数类样本点进行过采样,而不是全部少数类,最后还对类间重叠样本、噪声样本进行过滤,既避免了模型过拟合及丢失重要特征信息,又能有效地改善风机数据集的不平衡性,从而提升了模型的分类效果。
3 结语
本文针对风机数据集不平衡问题,采用数据挖掘领域重构数据集的思路,结合数据集的时序特点,提出了一种BSMOTE-Sequence 采样算法。该算法优点如下:1)基于数据集的特点,充分利用风机数据时序规律,生成合理的新样本,在一定程度上提高了对不平衡数据集的分类性能;2)对类间重叠样本、噪声类样本进行过滤,避免错误分类的负面影响;3)该算法采用了过采样、欠采样技术,避免了单独使用某种采样方法带来的问题;4)用SVM、CNN、LSTM三种分类器作为齿轮箱故障检测模型来系统地验证BSMOTE-Sequence算法的有效性。从实验结果可以看出,对风机不平衡数据集而言,本文所提出的BSMOTE-Sequence算法性能普遍优于其他数据采样方法,为处理风机不平衡数据集提供了一种可行的新思路。
