探索基于文本特征识别的电子档案自动归类系统
2021-06-30德州职业技术学院田绍敏
德州职业技术学院 田绍敏
本文根据传统分类方法的不便之处,经有效思考,提出了一种新型电子档案自动归类系统,通过以文本特征作为识别对象,可有效完成分类工作。该系统具有语料库模块,能够根据使用者日常搜索情况,分析其内在需求,实现对语料的挖掘,并完成相关操作。同时,借助排版模块,通过使用其中内容映射运作方式,能够对电子档案进行具体归档。建立在多种方法基础上,能够根据文本特征词,对电子档案中存在的文本特征进行识别,确定其最终归属。
1 基于文本特征识别自动归类系统分析
1.1 整体系统设计
本文系统整体系统设计如图1所示。以实现实时性对海量信息自动归类作为最终目的,本文系统借助文本特征识别技术,可有效缩短电子档案内容分析时间,并以此作为依据,实现相应的归类工作,能够为使用者提供有效便利。
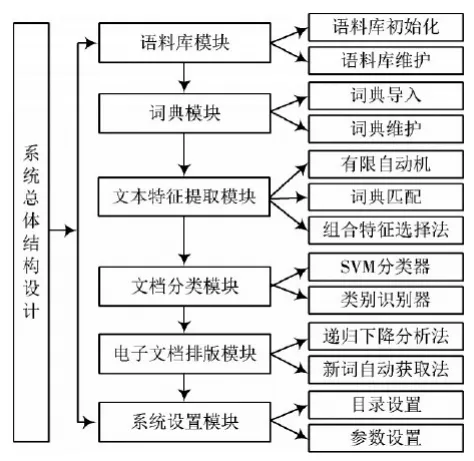
图1 系统整体设计图
在各系统模块中,语料库模块主要负责对相关算法学习进行管理,并构建训练档案集。词典模块负责构建词典,并在词典中完成添加、清除词条等操作。文本体征提取模块在所有模块中,具有核心地位,主要负责在合理切分词条的基础上,对词频进行统计,并以结果作为参考,制作文本特征项集。电子档案分类模块主要负责以上文项集作为依据,对档案代表向量进行分类处理,并分析不同向量中存在的相似度,实现自动归类。在电子档案排版模块,主要使用方法包括递归下降分析法、新词自动获取法,能够在总体电子档案中,自动对内容进行排版。系统设置模块负责根据实际工作情况,合理调整系统各项参数。
1.2 语料库模块
在本文研究系统中,主要应用语料库模块设计为Ontology,建立在明确使用者需求基础上,可有效实现对语料的深入挖掘,并进一步构建语料库,为查询、维护等相关操作提供便利,有利于促进文本特征提取模块工作。对于自动运转子模块而言,主要分为两部分,即后台运行、对使用者挖掘、操作命令进行响应等。在挖掘命令方面,借助自动转运子模块功能,利用元搜索引擎,能够在大数据中搜索相应的语料。同时,通过使用过滤子模块,能够将Web软件利用档案向量形式进行准确描述,以档案向量进行参考,将本体向量与其进行对比,在分析相关性基础上,能够准确获取相应的语料,并完成测试工作。在使用者抽象处理语料后,应将相关概念、Web页面完整体现在本题库、语料库中,并根据运转子模块,得到最终挖掘结果,向使用者进行展示。在操作命令方面,经运转子模块有效处理后,本题库操作模块将会接收到具体命令,并在语料库完成相关操作,将最终结果展示给使用者。
1.3 排版模块
在电子档案中,内容识别方法使用递归下降分析法,主题词识别使用新词自动获取法,上述方法不仅在识别方面性能良好,还能够起到对格式进行纠错的作用,借助内容映射功能,能够有效实现排版工作,排版效率显著。对于固定档案而言,排版子模块能够完成合理模板文件设计,具体需要参考格式固定情况,并以单一电子档案设计作为参考。并进一步按照固定程序,实现在固定路径内,对文件进行存储。基于上述工作,使用者通过将所需要的归档资料输入在相关区域内,经系统处理,可自动将资料进行规范。同时,针对文件类型不同,格式模板在标准方面也存在一定的差异,而应用格式模板子模块,能够有效对这一现象进行处理。针对格式校正模块,可完成对档案框架标题的修正,进一步实现对档案内容的解析,并将其予以合理处理。针对排版子模块,能够精准识别不规范标题,并进行有效修正,能够对文本中的各个段落进行重排,并将其按照相应的档案格式完成生成。
1.4 软件设计
(1)本特征识别算法。在电子档案中,通过深入挖掘语料库模块,能够有效获取相应的语料,建立在明确文本特征识别算法基础上,可将其有效应用在文本特征提取模块中,提高文本特征识别水平,优化其精确度,能够确保文本自动归类工作完成。在本文系统中,通过以文本特征作为重点,落实相应的识别方法,并配套实施两步特征选择方法,在有机结合各类方法基础上,进一步形成组合特征选择法。
(2)预选取。针对特征预选取,主要使用方法为有限自动机选择法,通过在档案中,对文本内容进行提取,可明确相应的特征词,并根据原电子档案,将文本内容进行有效转化,去除文本中原本存在的特征词,使其处于无特征词状态。可设置特征集,并将特征词作为其中一部分,在整个电子档案语料库模块中,设置待处理原始语料集为X={X1......Xn},设置最终文本特征集为Y={y1......ym},在完成模式抽取的同时,进一步生成相应的有限自动机,并对结果进行识别处理,可在整个X中,对全部文本特征词进行识别,进一步形成Y,经有效手段,对y中涉及到的所有字符串进行统计,将词频设置为xfj,将阈值设置为w,借助有效计算公式,可得出在w为3的情况下,将文本特征进行提取,能够达到最高精度。在Y中,如果xfj低于w,将会得到字符串yj,在这种情况下,针对原电子档案文本,可对文本特征词进行有效复原,使其转变为正常状态。同时,在原电子档案文本中,通过进行字典匹配,并借助有效识别法,能够有效改变档案文本集,使其转变为无特殊词状态。
(3)组合特征选择法。在X集中,对档案所有文本进行分词处理,借助组合特征选择法,将部分词进行有效选取,通过使用相关公式对剩余词进行计算,获取相应的CHI值,并以CHI值降序形式,对提取剩下的词进行排列,按照从上到下的原则,将选取的部分词,添加在Y集中。
建立在合理使用上述方法基础上,通过整合Y集,并根据部分词特征,可有效生成最终本文特征集。
(4)自动归类流程。以上文内容作为依据,通过获取相应的文本特征集,并合理使用SAV分类器、类别识别器,利用文档分类模块功能,自动归类相关电子档案。
建立在两次归类基础上,能够实现对电子档案的综合评定,确定其最终类别归属。借助SVM分类器,完成首次归类,主要围绕电子档案,对其是否存在敏感电子档案情况进行判断,如果判定为是,则可以直接将该档案按照敏感档案进行归类,如果判定为否,则需要对档案予以二次归类,在第二次归类中,主要选择类别识别器,以文本特征识别结果作为参考,进行分类,并最终实现归类处理,通过两次分类,确保电子档案归类合理性,并进一步保障所有档案均能够实现准确的自动分类。
2 实验分析
为有效验证上文系统准确性,本文在某图书馆中,集中抽取训练集、测试集电子档案共1000份,其中,前者500份,行封闭性归类测试,设为A组,后者500份,行开放性归类测试,设为B组。测试方向为查全率、精度。研究结果表明,A组查全率平均为97.70%,精度为96.30%。B组查全率平均为96.70%,精度为95.42%。两组并不存在明显差距,说明应用本文系统,能够精确识别电子档案,并且具有较高的普遍性,在有效性方面优势显著。
取相同实验环境,将本文系统设为A组,将层级类别信息归类系统设为B组,将权重自动优化归类系统作为C组,三组均接受自动归类实验,并集中在不同信噪比环境下,对比三组平均中断概率,分析不同系统稳定性情况。实验结果表明,A组平均中断概率为0.16%,B组为0.42%,C组为0.58%,A组相对较低。并且以平均信噪比在20db以下作为背景,三组在平均中断概率方面并不存在明显差异,并且在信噪比升高情况下,三组平均中断概率随之升高,但是A组整体上升情况低于B组、C组,说明应用本文系统,在稳定性方面优势明显。
对特征数进行调整,按照上文分组方式,对比三组准确率、召回率,具体实验结果显示:A组召回率、准确率均高于B组、C组。究其原因,在本文系统中,通过准确识别文本信息,完成自动分类,能够避免受到以往特征词丢失情况影响,并且借助组合特征选择法,本文研究系统降噪效果显著,稳定性良好。
结论:建立在有效电子档案自动归档基础上,可有效提取到海量信息。本文研究自动归类系统主要根据文本特征,并进一步配套两步特征选择方法,实现对文本特征的有效识别,通过合理使用SVM分类器,加强对类别识别器的使用,能够对文档进行两次归类,最终完成相应的归类。
