基于改进Apriori算法的气象数据质量控制研究
2021-06-30韩格格黄艳红姜娜娜徐晓庆
韩格格,黄艳红,姜娜娜,徐晓庆
(宁夏气象信息中心,宁夏银川,750002)
0 引言
Apriori是数据挖掘经典算法之一,但是也具有一定局限性。Apriori算法每次生成频繁集都要重复扫描一次数据库,因此时间成本较大。王伟等[1]提出一种B_Apriori算法,该算法只需对数据库进行一次扫描,然后通过逻辑运算的方式,计算出每一项的次数,最终得到频繁项集。李亮等[2]针对经典Apriori算法的性能存在的问题,提出T-Apriori算法,该算法也只需要扫描一次数据库,将数据转化为布尔值矩阵,通过计算找出频繁项集。这些改进后的算法与Apriori算法相比,虽然达到一定缩减时间的目的,但只是减少了数据库扫描的次数,并没有缩小数据库的规模。本文提出一种基于布尔矩阵的压缩矩阵频繁项集挖掘算法,将矩阵进行多次压缩,对压缩后矩阵的行向量进行逻辑运算,计算出每一项出现的次数,最终得到频繁项集,可以同时达到缩减扫描数据库次数和缩小数据库规模的目的。
1 基于关联规则算法的气象观测数据质量控制模型
基于关联规则的气象观测数据质量控制算法包括以下三个步骤,即数据离散化处理、产生关联规则、进行规则匹配[3]。
2 数据离散化处理
关联规则的挖掘需要离散型数据, 台站得到的气象观测数据都是连续的,因此首先要对得到的基础数据做离散化处理。将基础数据中的各个气象要素按照现行标准,进行等级划分。以温度为例,将数据按照以下等级划分:大寒(-10 ~-14.9℃)、小寒 (-5 ~-9.9℃ )、轻寒 (-4.9 ~0℃ )、微寒 (0 ~4.9℃ )、凉 (5 ~9.9℃ )、温凉 (10 ~11.9℃ )、微温凉(12 ~13.9℃ )、温和 (14 ~15.9℃ )、微湿和 (16 ~17.9℃ )、温暖 (18 ~19.9℃ )、暖 (20 ~21.9℃ )、热 (22 ~24.9℃ )等。
3 产生关联规则
3.1 Apriori算法
3.1.1 定义及性质
定义:Apriori算法是一种用迭代思想来挖掘出频繁项集的算法,通过”k-1项频繁项集"得到”k-项候选项集",进而得到“k-项频繁项集”。首先,找出频繁”1-项集"的集合L1,通过L1找出频繁”2-项集"的集合L2,依次寻找L3、L4… Lk-1,直到不能找出频繁”k-项集"为止。
支持度(support):support(A=>B) = P(A ∪ B),表示要素A和要素B同时出现的概率。
性质1 若项集Lk是频繁项,那么Lk除空集外的所有子集也都是频繁的;
推论1 若项集Lk是非频繁项,那么所有包含Lk的项集都是非频繁项集,因此包含Lk的项集可以直接删除[4]。
3.1.2 算法流程
步骤1:设定一个最小支持度,将项集中所有不小于最小支持度的项,作为频繁1-项集 L1;步骤2:通过L1自身连接生成候选项集C2;步骤3:根据上述性质1和推论1,将候选项集C2进行剪枝处理;步骤4:生成2-项频繁项集L2;步骤5:重复步骤2~步骤4,直到不能找出频繁”k-项集”为止。
3.1.3 产生关联规则
通过以上步骤,将得到的所有满足最小支持度的频繁项集作为关联规则,形成关联规则库。
3.2 改进算法
不难看出,Apriori算法每一次寻找Lk的过程都要扫描数据库D,挖掘频繁项集存在时间效率低下的局限性,因此本文提出压缩矩阵的频繁项集挖掘算法。根据频繁项集的性质,通过对矩阵压缩来缩小数据库规模,进而对压缩后矩阵的行向量作逻辑“与”运算,加快计算的速度,提高效率,即本文提出的MC_Apriori算法。
3.2.1 布尔矩阵定义及性质
定义: 将数据库D按以下规则转化为矩阵M,项作为行,事务作为列,如果第j个项集在第i个事务中存在,则矩阵M的第i行、第j列的值dij=1,如果不存在,则dij=0。若数据库 D 中含有n个事务(T1,T2…Tn), m个项(I1,I2…Im),则M可以表示为:
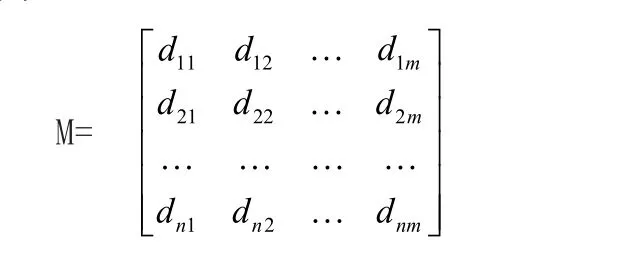
性质2:如果布尔矩阵M中某一项dnm与其他项进行“逻辑与”运算时,结果都是非频繁项集,则可以将此列从布尔矩阵 M中删除。
性质3:如果布尔矩阵中某一行的项数之和小于k,寻找频繁k-项集时,则可以将此行从布尔矩阵 M中删除。
3.2.2 MC_Apriori算法流程
步骤1: 将数据库D转化为布尔矩阵M;
步骤2:对布尔矩阵M中的列向量进行运算,与设定的最小支持度比较,得到1-项频繁集L1;
步骤3:寻找频繁1-项集时,如果项Ii是非频繁的,则可以将此列从布尔矩阵 M中删除,生成压缩矩阵M1,得到频繁1-项集;
步骤4:寻找频繁k-项集时(k>=2),某一行的项数之和小于k,则可以将此行从布尔矩阵 M中删除,生成压缩矩阵Mk,计算得到频繁k-项集;
步骤5:重复步骤4,直到不能产生频繁k-项集为止。
4 规则匹配
将得到的所有满足最小支持的频繁项集作为关联规则,用待检测的气象观测数据中的每条记录及其所有组合与关联规则库中的关联规则进行匹配,直到遍历完所有的规则为止,如果出现k条相匹配的规则,则认定当前观测记录为正常记录,否则为异常记录。
5 算法实验
5.1 数据的采集与预处理
选取宁夏石炭井站2020年7月~8月的700条数据作为样本数据,选择气温、10分钟平均风速、本站气压、整点相对湿度四个要素为例进行实验。经过等级划分预处理过的数据如图1所示。

图1 预处理之后数据
5.2 数据关联规则挖掘
(1)产生关联规则
用Apriori关联规则算法和MC_Apriori算法计算频繁项集,设置最小支持度阈值为0.05,获得实验数据集中的频繁项集共85项,将这些频繁项集作为关联规则。获得的部分关联规则如图2。
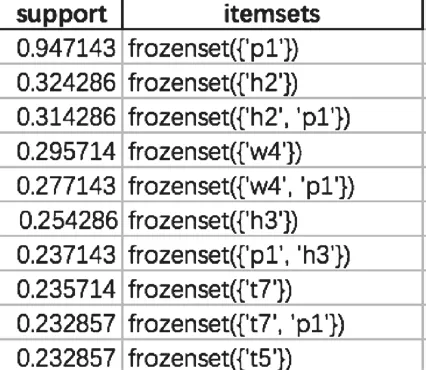
图2 部分关联规则
(2)改进前算法和改进后算法的时效对比
将Apriori关联规则算法和MC_Apriori算法处理数据产生频繁项集的时间进行对比。
对比结果表明:最小支持度小于0.35时,改进后的算法在时间效率上明显优于改进前的算法。
5.3数据的规则匹配
在700条样本观测数据中,植入30条异常数据进行测试。以气温为例,在原始气温值的基础上将每条气温值增加10摄氏度作为异常数据。设置质量控制参数k=8,如果满足匹配8条关联规则库中的规则时判定为正常数据,否则判定为异常数据。
检测结果为:30条异常数据中检测出28条,存在2条异常数据被误检,找出错误数据率达到93.3%。其余670条数据中检测出正确数据为662条,存在8条数据被误检,误检率为1%。
6 结论
本文提出基于关联规则的气象观测数据质量控制算法的模型,分析了Apriori算法存在的不足,提出了一种改进的MC_Apriori算法,对事务数据库对应的布尔矩阵进行行、列压缩缩减数据库规模,然后利用按位与运算提高频繁项集统计的速度,克服了传统Apriori算法重复扫描数据库的缺陷,提高了算法的执行效率。同时对Apriori算法与MC_Apriori算法进行了时间性能比较,仿真结果表明在一定的支持度范围内,MC_Apriori算法比Apriori算法更具时效性。最后,植入异常数据,与规则库中的关联规则进行规则匹配,找出错误数据率达93.3%。
