地图线状要素眼动识别的朴素贝叶斯方法
2021-06-29董卫华王圣凯王雪元杨天宇
董卫华,王圣凯,王雪元,杨天宇
1. 北京师范大学地理科学学部,北京 100875; 2. 北京师范大学地理空间认知与可视分析实验室,北京 100875
近年来,眼动追踪技术在地图学领域得到了广泛发展[1],并应用于用户行为分析[2-3]、人机交互[4-5]、产品可用性评价等方面[6-7]。地图在提高人的空间认知效果方面具有显著作用[8],但当前地图信息传输模式在一定程度上限制了人的空间感知与认知[9]。研究发现,地图信息的传输效率依赖于人脑信息处理效率和视觉注意的认知能力[10-12]。相比于传统信息传输设备,眼动交互被认为是更自然、更直接的交互手段[13]。已有研究通过眼动追踪技术探究了用户阅读不同类型地图时的读图行为以及信息搜索与加工过程[14-15]。如何自动识别用户阅读地图要素的眼动行为,对于提高用户地图交互、信息搜索的效率,具有重要应用价值。
现有地图要素眼动识别研究主要以视点位置直接对地图要素进行匹配。文献[16]提出了一种基于马尔可夫的视点-地图要素匹配的算法。该研究主要针对路网图进行视点与路线矢量要素的匹配问题,在算法层面上对眼动数据与实际观看的地图要素的匹配进行了探究。文献[17]建立了一个城市旅行规划系统——iTourist。系统以某地的地图和一些图片作为交互刺激材料,通过对用户的视点进行兴趣得分建模,当得分达到某一阈值时激活该目标。但是,采用视点位置进行匹配时,准确率较低,尤其对线状要素的提取效果较差。
研究表明,用户地图读图行为受地图类型和读图任务的影响较大[18],基于用户对地图的认知特征以及要素阅读行为构建模型有助于提高地图要素识别准确率。此外,眼动视觉行为识别算法的效率也是目前的研究难点。文献[3]通过支持向量机(support vector machine,SVM)利用眼动数据识别用户读图行为,包括自由查看、搜索、路线规划、中心搜索、路线追随和多边形比较,算法平均识别准确率为77.7%。但该算法涉及了大量的特征参数,效率较低。文献[19]关于某文档编辑软件使用的日常行为识别中采用机器学习的方法识别出书写、阅读和复制等操作行为,识别准确率在62%~83%。该算法采用了特征选择处理,提高了模型效率。因此,需要结合用户视觉行为特征,同时进行特征选择,降低特征冗余度,以提高模型效率。
线状要素作为狭长的空间实体,其阅读行为识别相较与点要素和面要素具有特殊性,无法通过空间位置定位和面积占优的方法进行有效识别。线状要素阅读行为较为复杂,包括起点终点搜索、流线跟踪、要素对比等[15]。因此,本文拟围绕对线状要素阅读行为的眼动识别,通过设计眼动追踪试验,采集用户地图读图过程中的视觉行为数据,基于朴素贝叶斯分类器(naive Bayesian classifier,NBC)的机器学习方法,实现眼控交互过程中地图线状要素阅读行为识别算法,最后对算法的效率和准确率进行评估。
1 地图交互眼动试验设计
试验分为试验准备、眼动试验、眼动数据获取、数据分析、特征提取和结论6个部分。
(1) 试验准备阶段,根据试验目的,分别选取30幅以线条为主的线型地图和30幅普通地图。为确保眼动试验的可靠性,对被试者进行合理选取,样本容量足够大。被试者选取应考虑的因素:年龄、性别、专业分布,是否色盲、近视或远视。
(2) 眼动试验阶段,保证试验环境的稳定性,被试者在试验过程中不应受到任何非试验因素的干扰。
1.1 被试者
试验共选取25名被试者进行试验。这些被试者都来自北京师范大学地理科学学部专业的学生,分别是12女13男,年龄在19至25。所有被试者的视力均正常或矫正至正常,且未报告患有眼疾,能够产生正常的眼动数据。每名被试者产生60个眼动样本数据。
1.2 仪器
试验选用的仪器为:Tobii REX for developer眼动仪(精确度为0.5°),数据传输率/采样频率为30 Hz;联想扬天一体机(22.9寸TFT显示屏),1280×1024像素,数据传输率/采样频率30 Hz,Tobii Interaction Engine 2.0.4,TobiiEyeX SDK for .NET 1.8。试验和数据处理过程是在Visual Studio平台下进行算法模型的开发和试验的设计。
1.3 试验材料
试验过程中选取的试验材料遵循以下原则:
(1) 同一任务下采用同样风格的地图,因为分类器需要区分的是用户的地图行为,而不需要考虑地图设计。
(2) 参加试验的被试者需要对地图产品熟悉,即有地学背景,这样可以让采样数据缺少噪声。
(3) 试验材料对于被试者是陌生的,防止先验经验对于试验数据的影响。
基于上述原则,总共设计出60幅图,30幅图用于进行线状要素的跟踪和浏览选取,为防止用户受其他因素干扰,地图中仅包含线状要素。另外30幅图选取自网络,进行其他任务,地图为普通地图,包括自由观看地图、点的选择等。
1.4 试验任务
(1) 针对线状要素的跟踪和浏览行为所采用的地图,被试者需要针对地图中的路线设计1—3条路线。为模拟现实生活中的路线规划,用户要求在所设计路线中选取一条最佳的路线并指出,如图1所示。
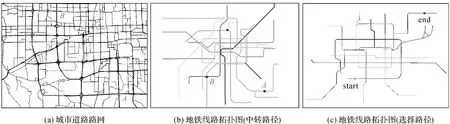
图1 眼动试验刺激材料Fig.1 Samples of eye tracking experiment materials
图1所包含的任务分别如下。
图1(a):指出从A地到B地的3条不同铁路路线示意图。或指出从A地到B地的最佳路线,并用鼠标沿线指出。
图1(b):指出从A地途径B地到达C地的2条不同路线走法,并用鼠标沿线指出。
图1(c):指出从start到end的3条不同走法,并结合换乘次数和路线长度给出最佳路线。
总共30幅图30个不同的任务需要被试者去完成,这些地图全部由笔者自己设计或来自于互联网,保证用户在进行试验之前没有接触过类似的地图。
(2) 针对非线状要素的阅读行为,对另外30幅图则让用户自由观看地图和进行面状要素识别,用户在进行自由观看行为的时候为防止产生数据量过大,限制用户自由观看地图的时间为25 s。面状要素识别具体为让用户选取地图中形状类似生活中常见物体的图形,并指明该面状编号以及所像物体,时间限制在30 s以内。
2 基于朴素贝叶斯的地图线状要素眼动识别方法
2.1 算法框架
本文的算法框架共有5部分,具体如下:
2.1.1 眼动数据获取和预处理
对于采集到的1500个眼动样本,应用I-VT算法对注视点进行识别。I-VT算法通过点与点之间的速率差异来区分注视点与眼跳点。当速率高于某一阈值的时候,该点就被定义为眼跳点;反之,则被认为是注视点。
2.1.2 眼动特征集构建
对上一步骤生成的注视点数据、眼跳数据、眼动轨迹数据进行进一步计算,一共提取了四大类特征,包括基于注视点的特征、基于眼跳点的特征、基于眼跳方向的特征以及基于视点编码序列的特征,共得到250个眼动特征,以作为算法输入数据集。
2.1.3 特征离散化过程
为了提高算法精度和效率,对生成的特征进行离散化。主要针对特征集进行了降维归约,针对连续的特征值使用平均值绝对差法进行离散化,将所有的数值用离散化的0/1/-1等值表示。
2.1.4 特征选择
由于特征较多,为了避免低效特征带来的输入冗余,需要对离散化后的特征进行特征选择。在特征选择过程中,采用最小冗余最大相关算法(minimum redundancy maximum relevance,MRMR)[20],通过计算特征与目标类别之间的相关性、特征与特征间的冗余性,从最初的特征集中选取出新的一套最优的特征子集,使模型达到更高的准确度或者在保持原有准确度的基础上保持更优的效率。
2.1.5 基于朴素贝叶斯的眼动特征分类
眼动特征分类是典型的多类分类问题,本文采用朴素贝叶斯分类模型进行学习和分类[21],构建地图线状要素阅读行为眼动识别方法。朴素贝叶斯分类模型是一种用于多类分类的集成机器学习方法,其核心思想在于特征的独立性。在朴素贝叶斯分类模型中,对于待分类的数据,根据其所具有的特征或属性,依据贝叶斯公式计算出各个类别的概率。最后算法选择概率最大的类别作为最终预测。
2.2 数据获取和预处理
通过眼动试验总共采集到了1500个眼动样本,各个数据的具体描述见表1。

表1 眼动样本数据描述
对数据进行预处理,视点导出后为gaze point at (x,y) @time的格式,应用I-VT算法对注视点进行识别。I-VT算法的原理如下:它是最简单的一种识别方法,通过点与点之间的速率差异来区分注视点与眼跳点。当速率高于某一阈值的时候,该点就被定义为眼跳点;反之,则被认为是注视点。这种方法的优点是运行效率高、直接简单并且便于实时运行。但是缺点也很明显,由于眼动追踪的噪音或平均时间数据造成的影响使点的速率在阈值附近摆动出现识别问题,造成本该单一的注视点被划分为多个注视点。
I-VT的算法步骤如下:
(1) 计算每一个视点与视点之间速度值,该速度的计算结合时间戳与屏幕像素位置得出。
(2) 设置阈值,结合文献[21]研究中所提到的阈值,速度小于3250像素/s时,定义该视点为注视点,直到下一个点的速度大于该阈值;而当速度大于3250像素/s时,将其定义为眼跳点。
(3) 将提取出的注视点存储至注视点组当中,而移除位于注视点区间的眼跳点序列。
(4) 计算注视点的质心坐标,并存储至系统当中。
共有242个样本由于采样率不合格被排除。其中103个样本被剔除是因为采样点中出现NaN(非数字)的情况,而另外139个样本则是样本中注视点采样异常,最终样本选取个数见表2。

表2 眼动样本数据统计
2.3 眼动特征集构建
对于单个被试者刺激材料眼动片段,采用以下3类特征来分别量化眼动统计特征和眼动时空特征,共计算了250种特征。
2.3.1 基本统计特征
这种类型的特征基于基本的眼动行为(注视和眼跳),它们在眼动追踪研究中被广泛采用为眼动指标[22-25]。注视点的识别是对观察到的眼动行为的一种固有统计描述。通常视觉和认知加工被认为发生在这一行为进行之间。眼跳点是位于两个注视点之间的一种眼动数据分类,是反映用户搜索情况的眼动行为。分别对注视点和眼跳点指标进行统计,最终得到32个基本统计特征。
2.3.2 眼跳方向特征
这种类眼跳方向特征可用于量化眼球运动的方向特征,可以直观反映用户在完成不同任务时的信息搜索方式的不同。首先使用幅度(大幅度、小幅度)和主方向(4方向、8方向)方案对眼跳行为进行分类编码,得到8分类和16分类两种编码标准,如图2所示。其中大幅度眼跳和小幅度眼跳的区分基于眼跳之间的视角角度阈值7.9°,结合用户到屏幕距离(一般认为是60 cm),结合屏幕像素我们定义大幅度的眼跳距离阈值为259像素值[26]。
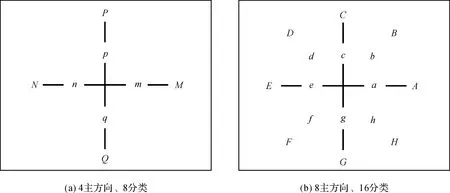
图2 眼跳方向特征Fig.2 Schematic diagram of saccade direction features
进而,对于每个编码类别分别计算其眼跳幅度和眼跳持续时长的最大值、最小值平均值,方差和偏度,共计120个特征。此外,本研究还统计了相邻相同方向的连续眼跳点发生的频率,即对连续两个眼跳点落入同一方向的或者相邻方向的眼跳子集的个数进行统计,共计两个特征。
2.3.3 眼跳编码序列特征
受文献[19]的启发,采用滑动窗口算法,对眼跳编码字符串,按顺序从左至右并且产生子字符串,最后再将这些子字符串存入到字典中进行统计分析。图3给出了滑动窗口算法依次存储长度为3的字符串的示例。
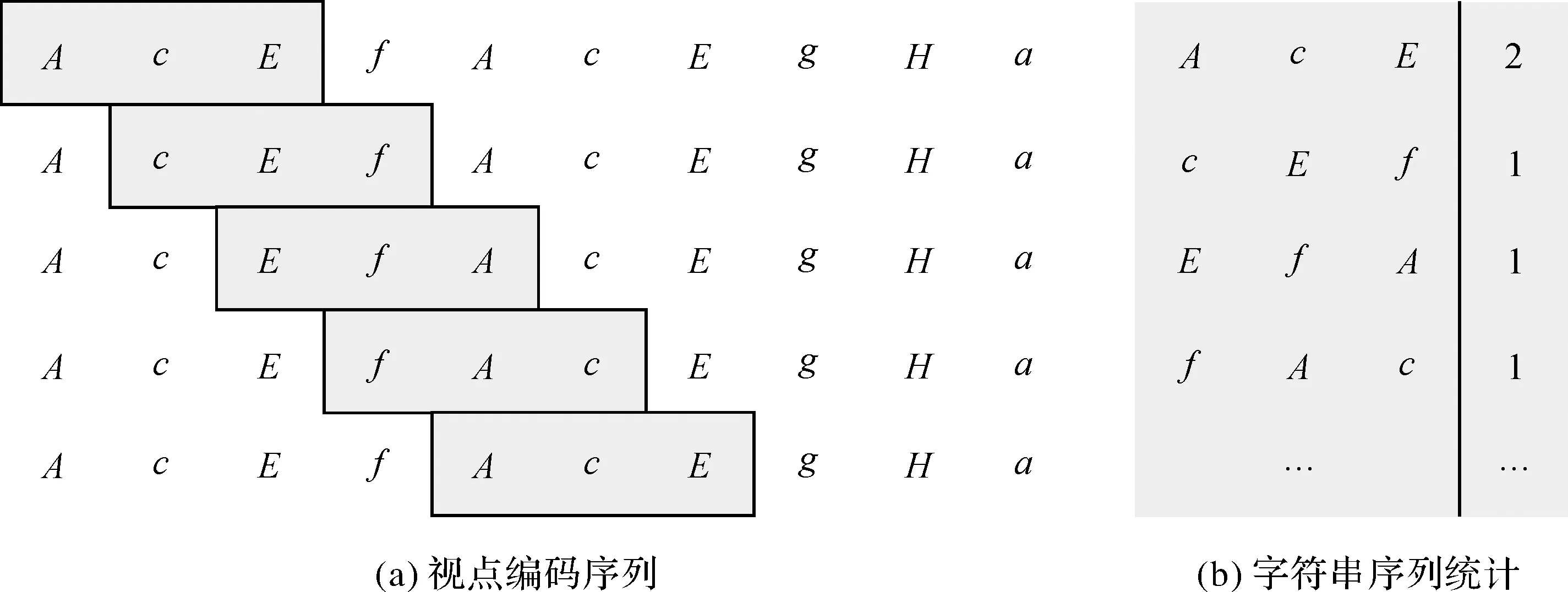
图3 应用滑动窗口对视点编码序列进行字符串统计的示意(滑动窗口大小为3)Fig.3 Schematic diagram of saccade code sequence statistics using a sliding window (size=3)
将滑动窗口大小,所有子字符串的数量,出现某一子字符串的最大值、最小值、平均值、方差及极差作为特征。其中滑动窗口大小取值为1~4。最终得到96个眼跳编码序列特征。
2.3.4 特征提取结果
表3为通过采集上述3类特征得到的朴素贝叶斯分类器的特征集,每一行中的具体特征以“特征参数”的“指标”来表示。在后文中,以每个特征指标的英文字母来表示,如GS-size3-16LS-max表示的是,基于视点编码序列的特征集中字符串长度为3时16分类大幅度眼跳字符串序列出现次数的最大值。

表3 眼动特征提取结果
3 分析与讨论
3.1 特征选择结果
本研究分别使用信息熵(mutual information quotient,MIQ)和信息差(mutual information difference,MID)的方法进行基于最小冗余最大相关的朴素贝叶斯模型训练,准确率结果如图4所示。基于MID和MIQ的两种曲线准确率并不相同,采用MIQ方法时,当特征数m=1时分类准确率已经达到了68.53%,但也是整个模型准确率的最低值;随后分类准确率出现了递增,在m=5时,出现最大值为78.28%;之后模型准确率出现降低,当模型特征数大于50的时候,模型趋于稳定,准确率可达73%,并且最终稳定在72.73%,这与未进行特征排序时的模型准确率结果是基本一致的。
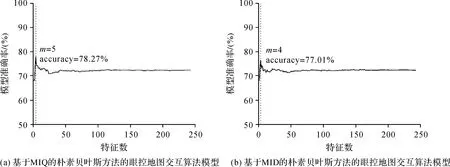
图4 算法准确率曲线Fig.4 Algorithm accuracy curve
应用MID方法时,m=1时,分类准确率同样为68.53%,这是因为二者所选取的第1个特征是一样的,与MIQ曲线不同的是,在m=4分类准确率达到最大值为77.01%,之后曲线总体呈现下降趋势,在m>50以后,分类准确率也稳定在了73%左右。之所以二者在后面的准确率趋向一致,是因为当选择的特征数量值m越大时,两种算法所重合的特征数量越来越多,到最后基本一致,所以结合算法原理,两种算法所得出的先验概率、条件概率和后验概率等均一样,所以模型准确率也一致。区别就在于特征数量较少时,由于不同特征组合导致准确率有差异。
3.2 基于MRMR的朴素贝叶斯分类结果
针对MIQ和MID方法达到准确率最大值时的m值,对精度和召回率进行验证,生成的混淆矩阵分别见表4、表5,模型准确率最大时特征选择结果见表6。

表4 基于MRMR(MIQ)-NBC算法模型在特征数量m=5时的混淆矩阵
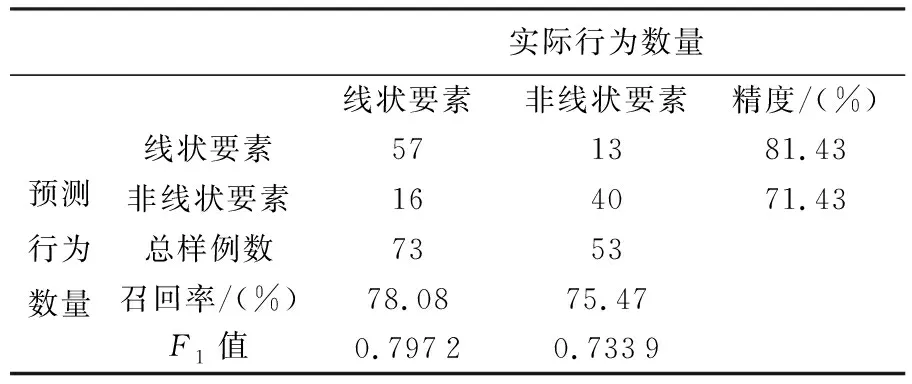
表5 基于MRMR(MID)-NBC算法模型在特征数量m=4时的混淆矩阵

表6 模型准确率最大时特征选择结果
从中可以看出,对于线状要素的阅读行为,在最主要的召回率方面,无论是基于MIQ(表4)还是MID(表5)方法,召回率均接近80%;同时,精度也基本维持在80%以上。此外,线状要素的识别行为F1值也达到了较高的水平。在性能方面,此模型所需要的特征数量为5,显著提升了模型的特征使用效率。
3.3 不同算法模型的准确率对比
文献[3]使用SVM模型对地图中的阅读行为进行过识别和预测。地图阅读行为包括自由浏览、全局搜索、路线规划、中心搜索、线状要素跟踪、面状对比等行为。其中的线状要素跟踪和路线规划与本文试验中的线状要素的跟踪选取行为基本一致。
文献[3]研究的最终模型结果与本研究中各算法模型的准确率及特征数对比如表7所示。结果表明,准确率最高的是基于MRMR(MIQ)的模型,其次是SVM模型,最后是基于MRMR(MID)的模型。其中,MRMR(MIQ)模型相较于SVM模型准确提升0.57%。在运算性能上,由于SVM要将229种特征属性加入到模型当中,MRMR(MIQ)模型(m=5)与MRMR(MID)(m=4)模型的运算性能远好于SVM模型。综上所述,MRMR(MIQ)模型在准确率优于SVM模型,而无论是MRMR(MIQ)还是MRMR(MID)模型,运算性能均远高于SVM模型。
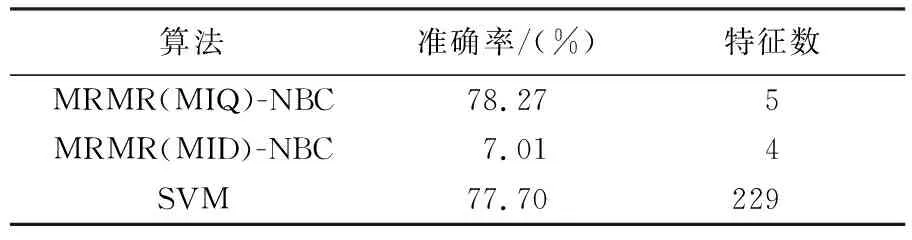
表7 算法准确率比较
4 结 论
本文提出了一种基于朴素贝叶斯的地图线状要素阅读行为眼动识别算法。针对用户在实际阅读地图中阅读线状要素的行为,总共设计了30个任务。基于任务结果,一共提取了3大类特征,包括基本眼动统计特征、基于眼跳方向的特征以及基于视点编码序列的特征,总共250种特征。研究所采用的机器学习模型为朴素贝叶斯分类模型,该模型分类效率较高,对小规模的数据表现很好。通过输入特征属性和训练样本构造模型,之后输入眼动测试样本数据,通过输出的结果对比实际样本类型,计算模型准确率。
本研究通过最小冗余最大相关对眼动也进行了特征选择,最终结果显示利用信息熵法得到的算法准确率最高可以达到了78.28%。并且,由于在达到最大值时所需要的特征数量只需要5个特征,与同类研究相比,大大提升了分类器的性能,也降低了算法的冗余度。也解决了传统方法对于地图阅读行为眼动识别方法分类性能差的问题,并且在准确率方面也进一步提升。
本文的研究还较为初步,主要提高了线要素识别算法的性能,今后的工作将集中在以下两方面。首先,将地图复杂度、地图要素分布类型等变量引入地图刺激材料设计,开展严格的控制性试验,分析用户要素阅读行为模式。在此基础上,改进要素眼动识别算法,实现更为精细的地图要素识别。其次,进一步增加被试者的数量、类型,如年龄、专业和空间能力等,提高算法对具有不同类型人群的适配性。
