针对军事集群目标的YOLOv3 改进算法研究*
2021-06-26李晓婷赵彦东
张 奔,徐 锋,李晓婷,赵彦东
(北方自动控制技术研究所,太原 030006)
0 引言
巡飞弹是一种能够执行智能组网、编队飞行、侦察及打击任务的无人作战飞行器[1]。在其实际的作战应用中,敌方的军事目标在很多情况下会出现集群作战,密集集结的场景[2]。因此,对目标数量及状态的快速精准统计,可以为后续巡飞弹编队进行任务规划、展开攻击提供重要的数据支撑。
在机器学习应用于目标识别前,军事目标的检测依赖于领域内专家根据对不同目标的纹理、形状、颜色等特征的处理,设计多种类型的特征描述子[3-5],进行全局特征目标检测。随着近些年计算机处理数据的能力呈爆发式增长,以及深度学习相关领域算法的长足进步,基于深度卷积神经网络(Convolution Neural Network,CNN)[6]的检测模型,在特征提取方面相比传统方式有巨大的优势。现有的基于深度卷积神经网络的目标检测模型,一类是基于建议框的方法,这类方法的典型代表就是于2014 年提出的R-CNN[7],R-CNN 算法家族是典型的两阶段处理模式,先通过滑动窗口、Selective Search[8-9]等方法,从图像中提取出候选区域再进行识别。此类模型对小目标检测精度高,但由于计算量大,很难满足实时目标检测的要求。另一类免建议框方法即YOLO算法家族[10-11],不需要提前找到可能存在目标的Region,而是将目标的检测看作是一个基于回归的问题求解,将整张图片直接输入,通过神经网络的信息提取,从模型的输出中直接给出目标的所属类别置信概率以及位置边框。这种方法省去了候选区域的提取与分类,极大程度地减少了处理图像所需要的时间,使得基于处理视频流的实时军事目标检测成为了现实,同时兼有较高的准确率。
为了解决巡飞弹作战过程中,军事集群目标在YOLOv3[12]算法漏检紧邻目标的问题上,提出一种改进非极大值抑制算法,并采用k-fold 交叉验证策略对数据预处理的综合改进模型。
1 YOLOv3 算法介绍
You Only Look Once 是YOLO 家族模型的全称,该算法于2015 年由Joseph Redmon 等提出,用于单个深度神经网络的目标检测模型。截止到2018 年4月,在其官网上已经发布了第3 个版本即YOLOv3。该算法的检测性能非常快速且准确,其中YOLOv3-608(608 指输入图片的分辨率)其mAP 可以做到与RetinaNet 相当的水平,达到33.0%,但其检测耗时只需要51 ms,相较于后者的198 ms 快了4 倍。
1.1 YOLOv3 算法
该算法基本思想:首先通过特征提取网络DarkNet53 对输入的图像进行特征提取,得到一定大小的feature map。通过调整卷积的步长为2,达到下采样的目的。例如整个网络进行32 倍下采样,在输入图片大小为608×608 的时候,得到一个大小为19×19 的feature map,然后可以认为将输入图像被分为19×19 个grid cell。这样如果在ground truth中某个目标的矩形中心落在了哪个grid cell 里,就由该grid cell 负责预测该目标,并且预测的坐标会通过sigmoid 函数归一化到这个grid cell 中。每个grid cell 都会预测3 个边界框,这几个边界框初始大小的设置借鉴了Faster R-CNN 中anchor 机制。这些预测出来的带有类别置信度的预测边框,通过Objectness 分数阈值筛选和候选框NMS 处理,最后输出目标的分类和预测边框。
YOLOv3 一大改进点就是采用特征金字塔网络(FPN)[13]类似的结构进行多尺度预测,不同深度所对应的feature map 包含的不同信息就得到了利用,例如52×52 大小的特征图拥有更加精细的grid cell,对更精细的目标就有更高的检测概率。
1.2 特征提取网络Darknet-53
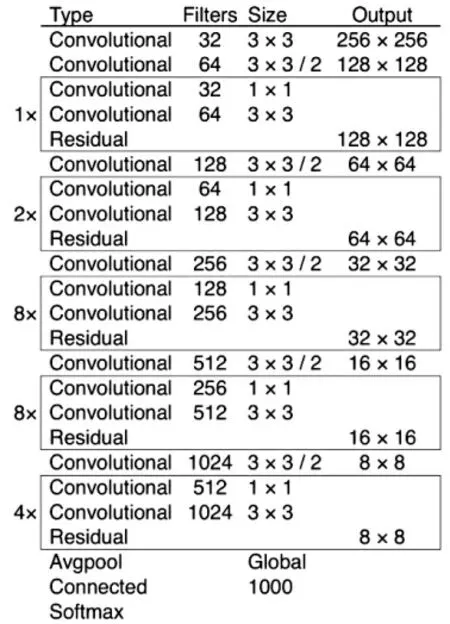
图1 Darknet53 网络结构
Darknet 网络的结构如图1 所示。本文不针对YOLO 的特征提取网络进行改进,故不进行细致的描述。需要说明的是,由于Darknet53 去掉了全连接层,实际这里的卷积层数应为52。
对模型最终的输出做处理是本次改进的重点,故在阐述改进之前,先给出几个概念的解释:
3 种不同尺度的输出特征图所提取的特征在深度这个维度上如式(1)所示:

其中,B 表示每个gril cell 预测出的边界框数量,C表示边界框的类别数,包含了每个类别网络预测出的类别置信度,5 表示预测边框的4 个坐标信息和1 个Objectness 分数。其含义如下:
1)Objectness 分数:表示目标在预测边界框中的概率;
2)类别置信度:表示检测到的对象属于某个类别的概率。
1.3 YOLOv3 边框选择算法缺点
YOLOv3 去除同一类目标由不同grid cell 预测出的冗余边框,采用非极大值抑制(Non Maximum Suppression,NMS)方法。该方法的基本思想就是通过搜索同一类目标的预测框,根据预测框的置信度得分和相互之间的IoU 比较,来找到与真实目标边框重合度最高的边框,并将冗余的边框提前剔除。
如图2 所示,YOLOv3 模型对自行火炮目标检测时,巡飞弹以俯视状态去拍摄军事集群目标,会出现目标相互遮挡的情况。非极大值抑制算法在执行过程中,如果IoU 阈值设置不恰当,相互遮挡的同类目标会因为彼此预测边框重合度超过阈值而有被误删的可能,导致检出自行火炮数量缺失,召回率下降。

图2 YOLOv3 对军事集群目标检测结果
2 针对YOLOv3 的改进方法
2.1 基于NMS 的边框选择机制改进
YOLOv3 目标检测模型中,基于NMS 的边框选择算法流程如下:
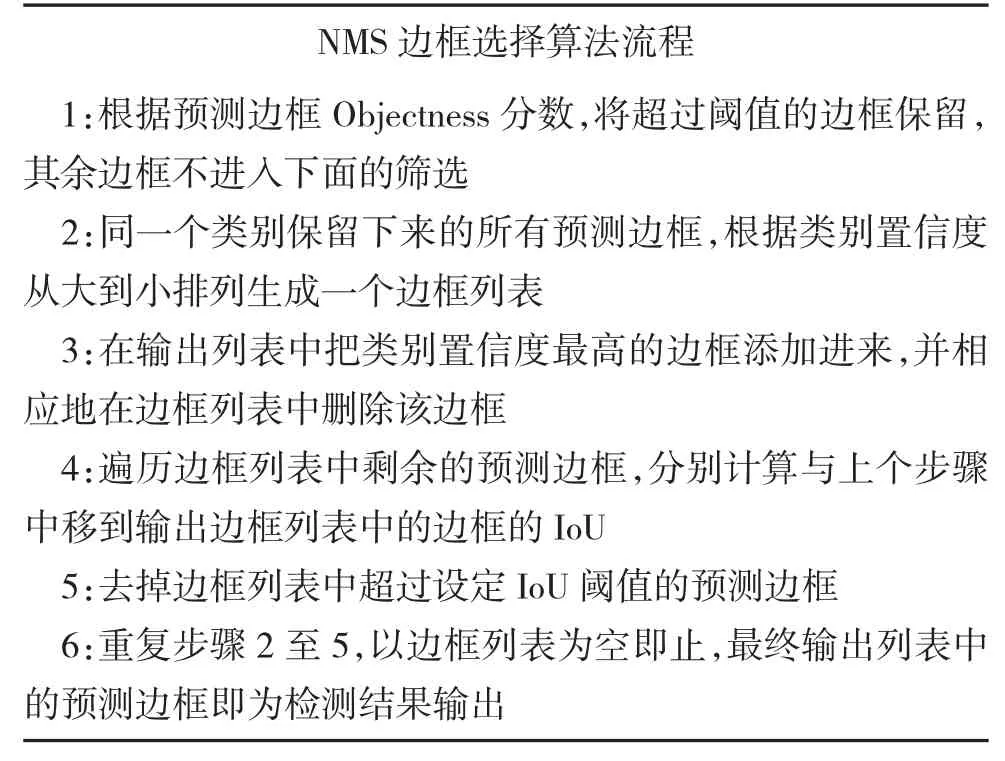
?NMS 边框选择算法流程1:根据预测边框Objectness 分数,将超过阈值的边框保留,其余边框不进入下面的筛选2:同一个类别保留下来的所有预测边框,根据类别置信度从大到小排列生成一个边框列表3:在输出列表中把类别置信度最高的边框添加进来,并相应地在边框列表中删除该边框4:遍历边框列表中剩余的预测边框,分别计算与上个步骤中移到输出边框列表中的边框的IoU 5:去掉边框列表中超过设定IoU 阈值的预测边框6:重复步骤2 至5,以边框列表为空即止,最终输出列表中的预测边框即为检测结果输出
可用式(2)来表示NMS 对回归边框的处理:
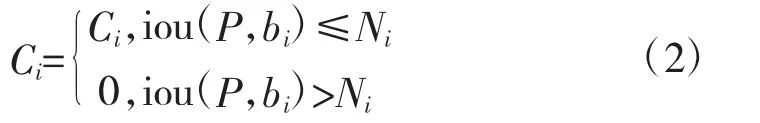
其中,Ni指YOLOv3-voc.cfg 文件中设定的ignore_thresh 值,即IoU 阈值。从算法流程和分数重置函数中都可以看出,NMS 对低于阈值的预测边框直接进行了“硬判决”,在集群军事目标中如果两个同类目标存在一定程度的前后遮挡,导致预测边框的重合区域较大,在超过IoU 阈值的情况下,NMS 算法就会“粗暴”地将类别置信度较低的边框排除在外,造成目标的漏检,从而降低了模型对该类目标的召回率。
Navaneeth Bodla 等人针对NMS 算法的缺陷提出了改进的soft-NMS 算法,其分数重置函数如式(3)所示:
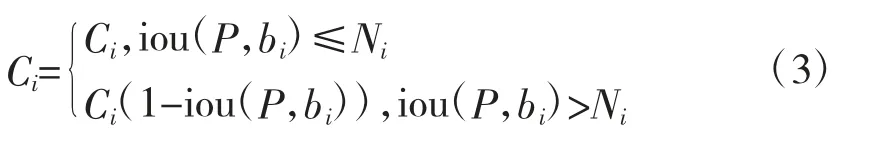
改进算法通过加入惩罚函数来削弱与检测框P有重叠的相邻预测框的类别置信度分数,使得重叠度越高的预测框对应的类别置信度得分衰减越大,而对没有超过阈值的预测边框则不作改变。通过soft-NMS 算法,保留了超过IoU 阈值的预测边框参加下轮筛选的机会,能在一定程度上减轻被遮挡目标预测边框被误删的概率,从而提高模型检测该目标的召回率。在Darknet 框架的src 文件中找到box.c文件即可修改模型候选框选择的方法。
2.2 基于k-fold 交叉验证策略的数据预处理
军事目标尤其是针对装甲目标进行攻顶袭击的图像在公开的信息中是非常稀少的,这将导致用于深度学习的训练数据不足。本研究采用模拟仿真的方式来获得所需训练素材,但是也需要考虑训练数据不足引起的模型过拟合现象。本文采用交叉验证(Cross Validation)思想[14-15]来抑制由于训练数据不足所引起的过拟合问题。交叉验证基本过程就是将数据集按照一定比例随机分为训练集和验证集,训练集的样本数量一般是验证集的3~9 倍,重复多次这样的分组并对模型进行训练来获得更加可靠稳定的权重文件。
k-fold 交叉验证方法是根据数据集不同的分割方法而命名的,其k 值指数据集随机平分为k组,并对模型进行k 轮训练。在k 轮的训练中,保证每组数据都做过一次验证集,剩余的k-1 组数据作为训练集来训练模型。最终以各次模型检测结果的平均值或检测结果最优的一组为衡量模型性能的标准。
3 实验验证
3.1 实验数据集
实验所采用的图像数据,以巡飞弹的实际应用场景为出发点,考虑到此类军事目标图像数据难以获得的情况,选择以模拟器生成图像为训练素材,针对自行火炮这类军事目标,以验证改进效果为目的,采用高空俯视的方式,从不同高度、角度对目标的图像数据进行采集。模拟图像的大小为1 920×1 080,自行火炮所占的像素点平均分布在20×20 到400×400 之间。并且目标的姿态涵盖了俯视情况下的大部分角度,在不同的尺度和不同的角度下都有充分的体现。本实验所采用的数据图例如图2 所示。所有训练图片都使用LabelImg 标图工具为其匹配一个.xml 文件。
通过删除相似图像,最终得到了2 191 张图片,按照3∶1 的比例将其分为训练集和验证集。整个数据集中包含自行火炮6 436 辆,其中,656 张图像中存在自行火炮两两遮挡的情况。同时单独制作了一个测试集,包含一个不同高度、不同角度俯视拍摄的模拟自行火炮视频,视频长度为3'11'',以及108 张测试图片。
3.2 实验平台与模型参数
本次使用所采用的软硬件平台如表1 所示,以下的对比试验均在此实验环境下展开。

表1 实验环境软硬件配置表
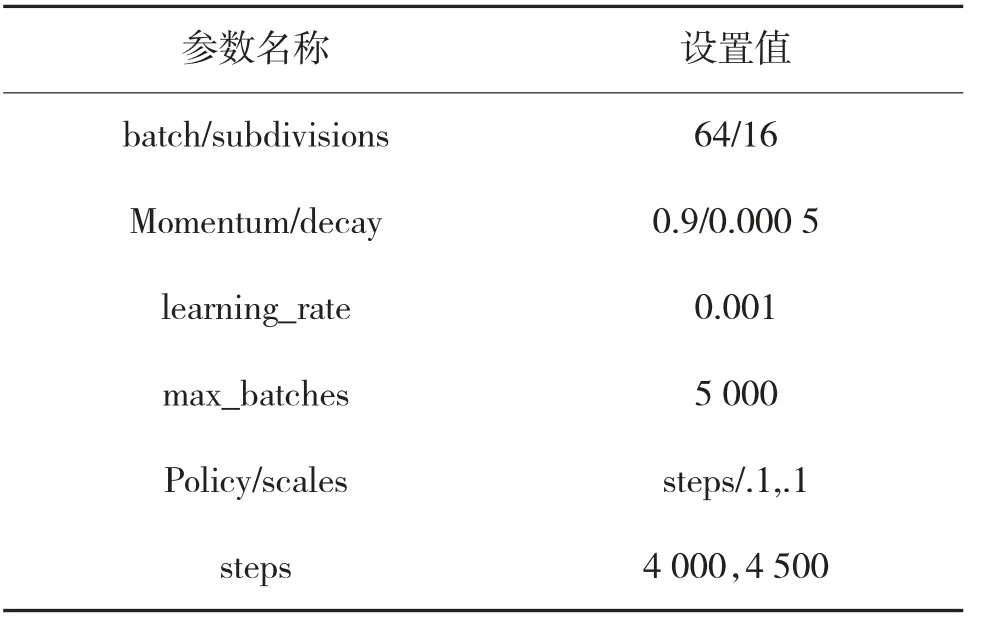
表2 训练.cfg 主要参数设置
表2 为模型的主要参数设置。在设置输入图片的大小时,分辨率越高,检测的准确度也会得到提高,但随之而来的是计算量的增加,综合考虑计算机的性能和对实时性的要求,选择输入图像的尺寸为608×608。
3.3 实验参照组数据以及实验结果评价标准
在按照以上参数配置表设置YOLOv3 的cfg 文件后,在不改变原模型其他任何参数的前提下,用收集到的数据集对模型进行训练和测试。采用模型的召回率Rcall 以及准确率P(Precision)作为对比标准。训练后参照组的召回率为69.65%,准确率P 为94.61%。
4 网络训练与结果分析
4.1 改进边框选择机制的对比实验
改进YOLOv3 的候选框选择方法后,在其他参数不变的情况下其训练的结果如表3 所示:
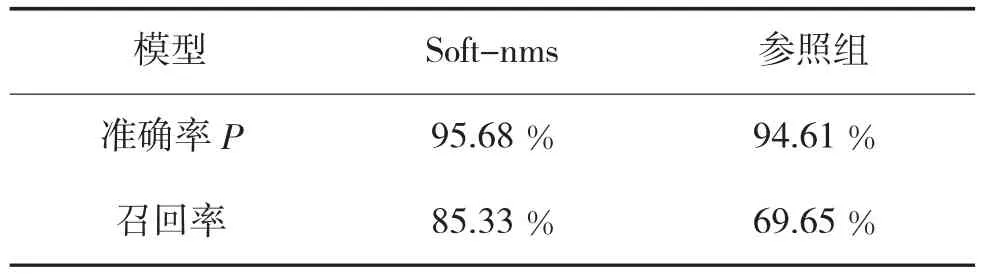
表3 soft-nms 与参照组实验数据比较
召回率提高了15.68%,显示针对候选框选择算法的改进有明显效果。
4.2 k-fold 数据预处理的对比实验
数据集按照3∶1 的比例随机分配成训练集和验证集,故k-fold 进行4 轮训练,其训练的结果如表4 所示:

表4 k-fold 实验结果
a-P 表示4 轮训练后的平均准确率,数据预处理后得到模型的a-P 相比YOLOv3 的准确率提升了1.99%。可见在该数据集上,k-fold 交叉验证方法能够对数据偏少时训练网络引起的过拟合现象起到抑制作用,有利于模型参数的优化。
4.3 综合改进模型的对比实验
将候选框和数据预处理的改进同时进行,4 轮训练后计算结果与参照组对比,实验结果如下页表5 所示。
实际的模型检测效果如图3 所示。综合改进后的模型相较于图2 所示的YOLOv3 的检测效果,可以明显看出在不同的目标尺度下,改进后模型把之前漏检的自行火炮都预测了出来,并且预测边框的位置也较为准确,识别的实际效果明显有了优化。漏检目标的重新检出提升了召回率,这与表5 所呈现的结果是吻合的,准确率提高了3.14%,召回率提高了17.58%。

表5 综合改进后与参照组实验数据比较

图3 综合改进模型对军事集群目标检测结果
5 结论
本次研究在YOLOv3 算法的基础上,通过数据交叉验证、候选框选择算法引入惩罚函数,提高了模型对复杂目标状态的适应性。3 次对比实验结果表明,改进算法在军事集群目标数据集上,有较高的检测准确率和定位准确率,同时对紧邻目标的漏检率低于原YOLOv3 算法。但本次研究为了提高对小目标检测的准确率,增大了网络输入图像的尺寸,牺牲了一定的检测速度。如何进一步优化模型,在保证小目标检测准确率的前提下提升检测速度,将是下一步研究的重点。
