省级气象大数据存储模型设计
2021-06-25夏正龙钟艳雯郑秋生
夏正龙,钟艳雯,郑秋生,朱 亮
(1.湖南省气象信息中心,长沙 410118;2.气象防灾减灾湖南省重点实验室,长沙 410118)
随着Hadoop、HBase、ElasticSearch等大数据存储、处理、运算技术的日益成熟,基于大数据技术的应用研究也成为各行各业重要的课题,中国各级气象部门也展开了如火如荼的研究,如王若曈等[1]采用Cassandra进行实时气象数据存储,设计每类数据对应一个列族,每张表的行被称作列族的键值,类似于该类数据的某一种物理量的磁盘路径,解决了Micaps4业务系统的海量数据分布式存储;徐拥军等[2]利用地面自动站数据量,对分布式数据库的高性能、高可靠性与可用性、灵活性与可扩展性进行了存储测试,得出在入库性能与检索性能方面都高于传统数据库及具有高可靠性、灵活性和扩展性好的分布式集群系统,能提高服务能力、节约建设成本的结论;何林等[3]选用ElasticSearch智能化全文搜索引擎,以中国地面逐小时观测数据为例,设计了气象大数据原型系统,并选取5个典型应用场景开展数据检索和统计分析能力测试,基于ES的气象大数据原型系统在结构化数据的检索和统计方面,尤其是多并发访问的情况下,相比CIMISS(全国综合气象信息共享系统)数据服务接口,响应时间性能提升明显;徐熙超等[4]基于HBase已有的并行数据查询技术基础上进行了相应优化,在表设计阶段充分考虑了HBase特性与业务系统常规查询用例,通过协处理器建立适用于海量气象结构化数据的实时查询索引,实现了海量数据的快速查询,以支撑现代气象业务系统。
1 省级气象大数据存储模型设计
目前,已有了一些基于传统存储技术建设的成熟气象数据存储方案,熊安元等[5]、马渝勇等[6]对气象数据的分类和存储模型进行了详细的分析,实现了传统关系型数据库技术下气象数据的存储管理,结合气象云建设的研究和思考[7],本研究设计以Ha⁃doop为分布式文件系统,利用HDFS和HBase分别存储非结构化和结构化气象数据,选用Elastic⁃Search建立统一的气象大数据存储索引的省级气象大数据存储模型(图1)。

图1 省级气象大数据存储模型逻辑
1.1 非结构化气象数据打包存储关键技术
目前,省级气象部门通过CMACAST、国内通信系统等每日接收的气象数据量超过300 Gb,文件数达到百万级,既有卫星、雷达、各种数值预报预测产品等超过500 Kb的大文件气象数据,也有各种类型的气象预报服务产品、文本、图片、XML、HTML等各类气象数据产品,以500 Kb以下小文件为主,500 Kb以上文件数少量大。海量的气象小文件对HDFS的存储带来了严重的问题,HDFS设计以流式数据访问模式存储超大文件,由于namenode需要将每个文件、目录和数据块的存储信息都要存储在内存,海量的气象小文件必将占用大量的内存资源,影响系统性能,已有采用Sequence File技术对大量小文件合并处理后存储在Hadoop分布式文件系统中的研究[8,9],能有效地节约内存资源,提升文件的读写性能。本研究选用Avro(数据序列化系统)将气象数据进行打包后存储于HDFS,减少文件数,节省内存资源的消耗,同时便于管理,进行Avro数据打包,主要包括Avro数据模式设计、非结构化气象数据打包存储规则设计以及打包文件生成3部分,史栋杰[10]通过5种快速序列化框架对1种对象网络进行序列化和反序列化的时间消耗以及序列化结果的空间消耗,进行性能比较,Avro在总时间方面速度最快,空间耗费也偏小,Avro是独立于编程语言的数据序列化系统,通常用JSON定义数据模式,数据文件支持压缩、可切分的,比较适用于MapReduce的输入格式,拥有自己的接口描述语言Avro IDL。
1.1.1 Avro数据模式设计 压缩打包后的气象文件将以一个较大的Avro数据文件形式存储,为方便查询、检索、管理气象数据,不仅要保存原数据文件的内容,同时应尽可能保留原数据文件的名称、时间、大小、格式、压缩打包情况等描述性元数据,Avro可方便地通过数据模式来管理元数据信息和数据内容,有丰富的模式解析能力,支持查询、增加、删除、别名、排序等多种功能,Avro数据模式用JSON格式定义示例如下:

1.1.2 打包存储规则设计 根据非结构化的气象数据类型、文件数量、收集特征等制定具体的打包存储规则,包括打包后的文件名规则、存储目录、是否需要压缩等,用欧洲中心数值预报产品压缩打包配置举例,压缩后的打包文件存储规则设计为:存储文件名W_NAFP_C_ECMF_%y%M%d_P_C3E.avro,%y(年)%M(月)%d(日)表示按日打包,因该类资料本身为bz2压缩格式,可不再需要进行压缩,资料编码为:F.0010.0002.S001,存储路径为HDFS目录/file/
NWP_ECMF_DAM/。
1.1.3 Avro数据打包文件生成 根据制定的打包存储规则,利用Avro编程通过读取非结构化气象数据文件,新建GenericRecord记录实例,并使用Data⁃FileWriter类将记录实例序列化到Avro文件,并存储到HDFS目录中,流程包括:一是要判断目标文件是否存在,如果存在,获取追加写对象,如果不存在,新建目标文件后获取写对象;二是判断是否要设置压缩编码格式;三是读取非结构化气象数据文件内容和属性构造GenericRecord对象,并序列化到目标存储文件,并设置同步标记位;四是写入或添加相应的气象数据文件后,及时关闭目标存储文件读写对象,释放资源(图2)。

图2 Avro数据文件打包
1.2 结构化气象数据存储设计
随着观测业务现代化的发展,各种新型观测仪器设备、观测系统投入了使用,湖南省气象观测业务能力得到了极大的提高,观测的时空密度也得到了飞速的发展,自动观测替代定点定时的人工观测,观测频次由一天几次逐步提升到小时级,再到现在的分钟级,观测密度由固定数量的气象台站,发展到包括固定气象台站、自动气象站、区域自动气象观测站等多类,站点数量由原来几十发展现在的几千。同时,随着特定观测任务的开展,观测资料种类也有了极大的丰富,由原来仅有的地面和高空观测,增加了自动土壤水分、农气、GPSMET、L波段探空、闪电、负氧离子等各种类型观测。气象观测数据内容得到了极大的丰富,观测数据主要由气象站点属性信息、时间以及观测要素值等组成,属于结构化气象数据,传统的气象数据存储系统一般采用关系型数据库,分析数据特点,设计表结构和索引字段进行存储,通常为减少冗余字段、减少存储量,会将气象资料的观测要素进行拆分表设计,并通过关联字段进行关联。但随着海量气象大数据的发展,传统数据存储管理方式越来越表现出更多的问题,数据存储的冗余备份、关联查询的复杂和效率、索引容量和性能等方面都急需引进新技术解决面临的困境。目前,各级气象部门陆续开展针对海量结构化气象数据在分布式存储技术中的测试以及应用研究,肯定了大数据存储等新技术在海量气象数据存储中的可行性。HBase是一个在HDFS之上的非关系型数据库,它依靠HDFS来屏蔽底层系统的异构性,实现集群的负载均衡与容错。HBase采用键值对(Key-Value)存储数据,行键(Rowkey)采用基于LSM树(Log-Struc⁃tured Mergetree)的数据存储结构,所有行键在HBase表中有序排列,在主键范围内查找,速度很快。基于HBase数据存储技术基础,本研究设计省级结构化气象数据存储思路为:①因不同气象资料的观测要素、观测频次以及使用特点等不同,每一类气象资料单独建表管理;②基于HBase设计采用宽表存储模式,按观测特征以及应用需求,避免检索时需要进行关联查询,便于统计分析,设计将观测要素尽量存储于同一张表中,同时存储观测台站相关信息的元数据;对于观测要素众多,频次、结构以及应用需求等多样的气象资料,依据特定观测特征和应用需求,进行不同的应用分类,适当将特定观测要素进行分表存储,同时存储观测台站相关信息的元数据,如地面观测资料观测种类繁多,不仅包括气温、气压、湿度、风、降水等常规观测要素,而且还包括观测天气现象、云、能见度、分钟降水、地温、数据质控码等特殊观测,设计采用多宽表存储,将测站基本信息、气压、气温、湿度、风、降水、云、能见度、天气现象等气象预报业务常规要素存储于一张表,将测站基本信息、分钟降水、地温以及其他特殊观测项目存储于一张表;③气象观测数据一般都包含观测时间与区站信息,为确保行键的惟一性,同时以时间开始会造成“热点写”现象,行键设计为:区站号_观测时间_资料代码标识,对同一类资料区站号是具有惟一性的,故此行键设计是可以保障惟一性的,资料代码标识延用CI⁃MISS系统的气象资料分类与编码,可保障每一类资料的编码惟一性。
1.3 统一的气象大数据存储索引设计
省级气象大数据存储索引设计的优劣严重影响着气象数据检索策略和检索效率,气象数据检索策略多样要求索引设计灵活,检索效率高要求索引设计合理。传统气象结构化数据一般直接在存储数据表上设计索引字段,非结构化气象数据存储以数据库索引表和文件相结合的方式,本研究选用ElasticSearch全文搜索引擎工具(简称ES)设计统一的省级气象大数据存储索引库模型,结合应用需求,设计建立结构化气象数据字段存储索引和非结构化气象数据文件存储索引,ES本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个ES实例,ES在存储数据时会索引所有字段,经过处理后写入一个反向索引,查找数据时,直接查找该索引,从而提高查询速度。通过ES建立统一的省级气象大数据存储索引库,将索引和数据单独存储:一是统一了检索入口,提高检索的便捷性;二是可根据检索的不同需求,设计不同的存储索引,提高了检索灵活性;三是简化了管理,索引的变动不影响数据的存储。
结构化气象数据存储在HBase数据表中,而HBase是通过行主键快速定位并获取数据,对于其他要素字段的查询,则需要通过使用遍历过滤查询,对于海量数据查询时,不能快速确定行主键,数据行数越多,遍历过滤则越慢,主键的设计往往不能满足各方面的检索需求,本研究根据应用需求建立相关查询要素和行主键的索引,实现检索查询时,可先通过检索ES对应的索引,获取需要定位的行主键集合,再通过HBase的行主键快速定位并获取数据,可极大地避免使用HBase的遍历过滤,提高查询效率,以地面观测资料为例,如需实现对地面观测资料整行数据的检索查询,可建立“观测时间、台站号、经纬度、行主键”等字段的索引库;如需实现对指定气温范围的地面观测资料检索查询,可建立“观测时间、台站号、经纬度、气温、行主键”等字段的索引库(图3)。

图3 ES地面观测资料(结构化气象数据)索引查询示例
非结构化气象数据打包存储成Avro文件,并存储在HDFS中,打包后的Avro文件比较大,极大减少了小文件数目,节约了内存资源,提升了系统性能,虽然Avro数据模式可以进行解译,但往往查找保存在其中的一份非结构化气象数据文件,需要遍历Avro文件存储内容,不能快速定位,查询效率比较低,提升了检索难度,本研究通过ES设计建立每一份非结构化气象数据文件的名称、时间、大小、格式、资料编码等原始文件信息和打包后存储文件路径、文件同步标记位等存储信息的索引库,检索文件时,通过检索ES获取Avro打包文件存储路径,再根据文件同步标记位,可利用Avro编程方法中DatumRead⁃er和DataFileReader对象读取并解译,快速定位并获取指定数据文件(图4)。
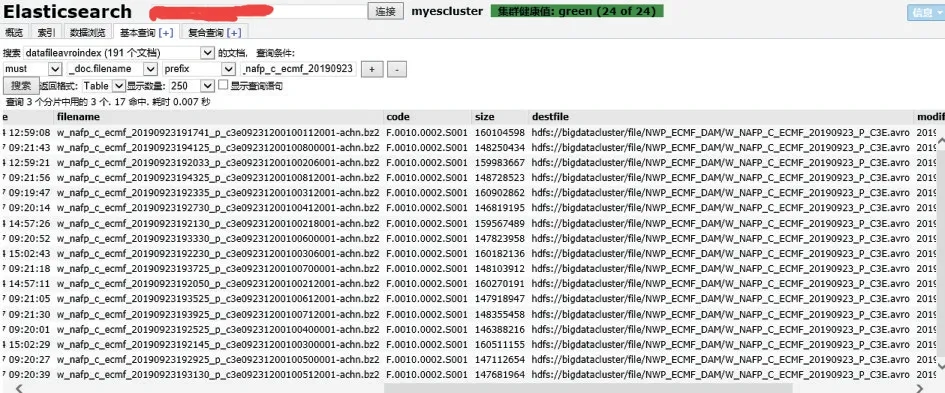
图4 ES欧洲中心模式数据(非结构气象数据)文件存储索引查询示例
2 结语
本研究设计了海量的非结构化气象数据小文件通过Avro打包后存储在HDFS、海量的结构化气象数据通过HBase采用宽表存储、选用ElasticSearch建立统一的省级气象大数据存储索引库的省级气象大数据存储模型,给各省气象部门开展气象大数据存储规划和方案制订等工作提供借鉴参考,但目前存储模型设计中仍有很多细节需要进一步完善,还未能满足业务化要求。
