异构云无线接入网下基于功率域NOMA的能效优化算法
2021-06-24李子煜管令进陈前斌
唐 伦 李子煜 管令进 陈前斌
(重庆邮电大学通信与信息工程学院 重庆 400065)
(重庆邮电大学移动通信技术重点实验室 重庆 400065)
1 引言
随着智能设备的爆炸性增长,诸如增强现实和虚拟现实等新兴高速率服务以及构建物联网(Internet of Things, IoT)的海量设备,使得设计高效的能效通信系统迫在眉睫,进而实现绿色经济和可持续发展的运营。与4G系统相比,5G系统需要达到1 ms的时延、10倍的频谱效率、100倍的能效以及1000倍的系统容量。作为有前景的新技术和网络体系结构,异构云无线接入网(Heterogeneous Cloud Radio Access Networks, H-CRAN)引起了业界和学术界的极大关注。可以预见,在H-CRAN中将采用各式的多址接入技术,以减轻小区间和小区内的干扰,并改善网络频谱效率和能效。作为一种新的多址方案,非正交多址接入(Non-Orthogonal Multiple Access, NOMA)被认为是有望显著地改善5G移动通信网络的频谱效率和能效的候选方案。文献[1]采用混合多址接入技术提高频谱效率,NOMA技术中的非正交性具有高频效、能效以及低传输时延的潜在优势。因此,本文在H-CRAN的下行传输场景下利用NOMA技术来最大化网络能效。
文献[2]在H-CRAN下行传输场景下研究网络能效性能,联合优化基站选择、子载波分配和功率分配,构建网络能效最大化的目标函数,利用连续凸近似理论进行求解,进而提高H-CRAN的能效性能。文献[3]在异构云无线接入网络的场景下提出一种能效优化算法,利用李雅普诺夫优化理论和拉格朗日对偶分解方法对优化问题进行求解。文献[4]在H-CRAN下行链路场景下,建立了网络总吞吐量最大化的随机优化模型,通过深度强化学习和迁移学习算法,智能化分配无线资源,提高网络的稳定性。
尽管上述的文献在无线资源分配上都取得了较好的研究成果,但仍然需要进一步的改进,主要存在3方面的问题:(1)多数工作忽略了NOMA技术带来的频谱效率和能效优势,同时没有考虑前传容量受限给接入网带来的吞吐量瓶颈,进而与实际的网络场景相脱离,无法取得合适的资源分配方案;(2)大多数研究仍采用传统非线性优化算法,当优化问题出现高维状态空间或动作空间时,可能会导致维度灾问题,使得优化算法陷入局部最优解;(3)尽管深度Q学习对无线资源的自优化具有一定的帮助,但其需要对动作空间进行离散化处理,导致求解的资源分配策略非常不稳定。此外,基于连续域的置信域策略优化(Trust Region Policy Optimization, TRPO)算法产生的计算量较为庞大,导致算法性能得不到有效的提升。
针对上述提出的问题,本文在H-CRAN下提出一种基于功率域-非正交多址接入(Power Domain Non-Orthogonal Multiple Access, PD-NOMA)的能效优化算法。所提算法的主要创新点如下:(1)为提高网络的频谱效率和能效,联合优化用户关联、功率分配和资源块(Resource Block, RB)分配,构建用户公平性和网络能效的优化模型;(2)针对无线网络资源分配的复杂性和动态性难题,引入基于自学习的置信域策略优化算法,大大降低了动作空间的维度,进而避免维度灾问题;(3)针对TRPO算法的标准解法产生的计算量较为庞大,采用近端策略优化(Proximal Policy Optimization, PPO)算法进行优化求解,进一步提高算法效率。
2 问题描述与系统模型
2.1 基于PD-NOMA的异构云无线接入网架构
考虑H-CRAN下行传输场景,如图1所示,建立了一个基于NOMA的H-CRAN架构,远端无线射频单元(Remote Radio Head, RRH)具有天线模块,只需执行射频处理以及简单的基带处理,主要的基带信号处理以及上层协议功能均在集中式基带单元(Base Band Unite, BBU)池中执行,RRH通常部署在热点区域负责海量数据业务的高速传输[5]。高功率节点(High Power Node, HPN)用于全网的控制信息分发,突发业务以及即时信息等低速率数据信息也由HPN承载,确保业务的无缝覆盖[6]。以此同时,采用基于PD-NOMA来提升频谱效率和网络能效,PD-NOMA允许不同用户占用相同的频谱、时间和空间等资源,通过主动引入干扰进一步地提升单用户速率和系统的和速率,尤其是保障了小区边缘用户速率。
2.2 无线通信模型


图1 基于PD-NOMA的异构云无线接入网架构

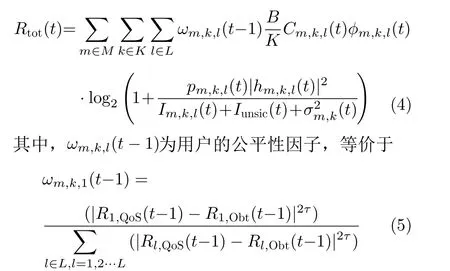
2.3 前传链路模型
随着移动设备的大量普及,移动流量也急剧增加,需要一种大容量、高可靠和低时延的传输网络作为前传网络,以此来满足移动用户越来越多的业务需求。在目前的前传网络选择中,无源光网络(Passive Optical Network, PON)具备低成本、大容量的特性,是一种高效可行的前传网络解决方案[7]。PON作为云无线接入网络(Cloud-Radio Access Network, C-RAN)的前传网络,不仅能够满足C-RAN架构对前传链路的传输要求,同时还能应对5G网络带来的高可靠、低时延和低损耗的无线网络需求。
如图2所示,PON是典型的一对多传输网络,其固有无源特性能够为前传链路提供极大的带宽容量和较长距离覆盖等优势,PON称为H-CRAN中光前传网络的最佳选择。因此,前传容量限制的模型为
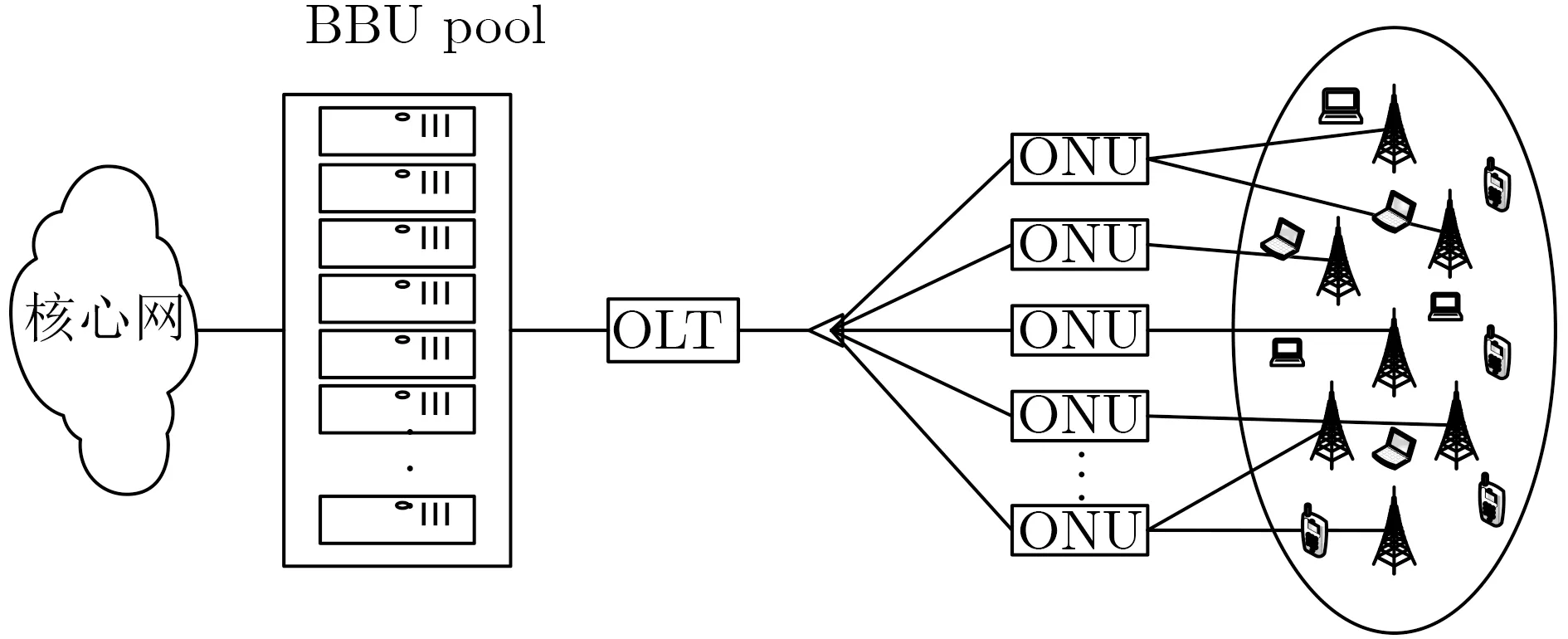
图2 前传链路框图

其中,ϑm表示第m 个RRH的有效前传容量。
2.4 网络能耗模型
由于H-CRAN和传统移动网络的架构不一样,传统网络的能耗模型不一定适用于H-CRAN。因此,本文在H-CRAN中建立了完善的网络能耗模型来描述RRHs, HPN, BBU池和前传链路的能耗

在建模前传链路的能耗时,本文考虑的是基于时分复用的无源光传输网络,PON包括一个光线路终端(Optical Line Terminal, OLT),该终端通过单个光纤连接一组相关光网络单元(Optical Network Unit, ONU)。根据文献[8]的分析,前传链路的总功耗为


2.5 两级队列模型
根据文献[9]的分析,本文使用两级队列模型来描述从核心网传输数据给用户。如图3所示,核心网传输给用户的业务数据首先进入基带资源池,首先分配给BBUs内的每个虚拟机。在VM的队列长度中处理后,数据将被传输到服务于用户的RRHs,再通过无线通道传输到用户。

图3 两级队列架构


本文将能效ηEE定义为整个网络长期时间下的和速率与长期的能量消耗的比值。在业务队列稳定的前提下,基于PD-NOMA技术的H-CRAN中能效问题被建模为如下随机优化问题

3 问题转化与算法描述
3.1 基于TRPO的能效优化算法
本文除了考虑约束条件外,还综合考虑网络功耗,于是资源分配问题变成了NP-hard问题,难以求出最优解。根据文献[12]的分析,深度强化学习(Deep Reinforcement Learning, DRL)可以通过与动态环境进行交互获取最优解,从而提升系统的总能效,但它只能处理低维和离散的动作空间,不能直接应用于连续域。因此,本节将引入基于连续性DRL的能效优化算法,利用RL与无线网络进行交互,并通过DL的非线性函数近似特征,使得基站做出满足优化目标的最佳决策。


策略梯度算法的缺陷在于更新步长难以确定,当步长不合适时,更新的参数所对应的资源分配策略是一个更不好的策略。因此,合适的步长对于整个H-CRAN系统是非常关键。本文的TRPO算法通过寻找使得回报奖励函数单调递增的步长,进而逐步完善网络的资源分配策略,将新策略所对应的回报函数分解成旧的策略所对应的回报函数加上优势函数项,如式(18)所示


3.2 近端策略优化算法
对于上述的目标函数,为了求解出最佳的资源分配策略。首先,需要将目标函数进行1阶近似;其次,利用泰勒级数对约束条件进行2次展开;最后利用共轭梯度的方法求解更新的参数。当选用深度神经网络表示策略参数时,TRPO的标准解法产生的计算量较为庞大[13],较难应用到H-CRAN网络的策略更新中。根据2017年OpenAI提出的PPO算法,其策略参数通过梯度估算进行迭代优化。PPO不需要估算状态转移函数,可以应用于大规模的连续域控制问题,因此,本文将使用PPO算法对式(21)的目标函数进行优化,获得最优的基站关联策略、RB分配策略以及用户功率分配策略。PPO是基于参考策略πθ0ld的η1阶近似值来对πθ的参数进行局部优化,两者间的概率比表示为

为了提高网络的能效性能,Actor和Critic中神经网络的权重值都需要通过反复的学习来拟合复杂的环境特征,具体的训练模型如图4所示。该过程通过最小化Critic神经网络的损失函数来训练神经网络参数:

图4 PPO算法框图

为了使Actor神经网络获得最佳的策略,通过最大化Actor的神经网络损失函数来训练其权重参数

其中,σ 为超参数,取值为0.2,即:缩减该变化率在0.8~1.2之间,以保证策略更新不会过大。在Actor-old网络中,其权重参数通过Actor-new网络定期地进行赋值更新,具体的学习流程如表1所示。

表1 近端策略优化PPO训练Actor网络参数算法
通过算法1将PPO模型训练好后,可以获取Actor神经网络的最优权重参数。利用上述参数,基站可以获得最优的策略来进行用户关联、RB分配以及功率分配,并且取得最大的能效性能。
4 仿真与讨论
在这一节中,通过与深度Q 学习算法[14]和TRPO算法[13]的对比研究,详细地分析所提算法的性能。
4.1 参数设置
本文设置的网络拓扑大小为800×800 m2, 1个HPN放置在网络中心位置,10个RRH均匀分布在网络中,HUE用户数为4, RUE用户数为35,且均匀地分布在HPN和RRH上。在仿真中,系统的时隙长度 τ为10 ms,总带宽为10 MHz,子载波数目设置为32,无线信道被建模为瑞利信道,噪声功率密度为—174 dBm/Hz, HPN的路径损耗模型为31.5+40.0 lg(d)、R R H 的路径损失模型为31.5+35.0 lg(d)。HPN的最大发射功率为43 dBm,RRH的最大发射功率为29 dBm, RRH和HPN的静态功率消耗分别为3.5 W和84 W。由于本文采用基于连续性的深度强化学习的算法来解决H-CRAN资源分配问题,还需要对神经网络中的参数进行训练,经验回放池的大小设置为5000,batch的大小为32。
4.2 性能分析
本节通过PPO算法的训练讨论了batch大小和损失函数对无线网络性能的影响。如图5所示,不同batch大小会使得系统的能效性能表现出巨大的差异,在batch较小的情况下,网络有可能会陷入局部最优解,并且算法的收敛速度较为缓慢。因此,合适的batch大小是DL的训练非常重要,本文将batch大小选为32。
图6展示了不同到达率对用户的平均队列长度的影响,随着仿真时隙的增加,平均队列长度起始迅速增加,随后趋于稳定。这也说明了所提的PPO算法可以有效地保证系统队列稳定性。以外,在不同到达率的条件下,平均队列长度会有所不同,随着到达率的增加,平均队列长度会越来越大。
如图7展示了不同算法下用户数对网络能效的影响,随着用户的增加,网络的吞吐量将占主导地位,网络能效越来越好。此外,由于PPO算法既解决了DQN算法无法应用于连续性以及高维动作空间的问题,又大大降低了TRPO算法的计算复杂度,因此,PPO算法对无线网络产生能效优势远远好于TRPO和DQN算法。如图8所示,PPO算法较TRPO算法而言,计算复杂度更低,从而可以更加快速、合理地获得最优的资源分配策略,避免不必要的能耗浪费。PPO算法较DQN算法而言,完美地解决了DQN在连续型环境下需要离散化的问题,使得神经网络的训练可以获得更加完善的状态信息,进而更合理地分配无线资源。
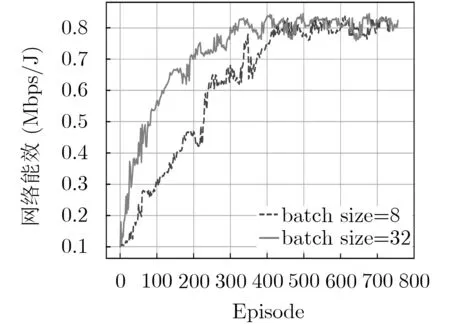
图5 PPO算法下不同batch的网络能效

图6 不同到达率的平均队列长度

图7 不同算法下的网络能效

图8 不同算法下的网络能耗
5 结论
本文在H-CRAN下行传输场景下,以队列稳定和前传链路为约束,联合优化用户关联、RB分配和功率分配,构建用户公平和网络能效的随机优化问题。将随机优化问题转化为置信域策略优化问题,通过自学习的方法求解最佳策略。此外,针对TRPO算法的标准解法产生的计算量较为庞大,采用PPO算法进行优化求解。仿真结果表明,本文所提算法在保证队列稳定约束下,进一步提高了网络的能效性能。
