一种嵌入铁电晶体管内容寻址存储器的高能效浮点运算结构
2021-06-24卢旭东庞展曦陈闯涛尹勋钊
张 力 高 迪 陈 烁 卢旭东 庞展曦陈闯涛 尹勋钊 卓 成*②
①(浙江大学信息与电子工程学院 杭州 310007)
②(浙江大学国际联创中心 海宁 314400)
1 引言
随着大数据时代的到来,计算系统中的数据搬移问题成为热门话题,冯·诺依曼架构下的计算和存储分离,成为制约系统能效的一大瓶颈[1]。将数据从动态随机存取存储器(Dynamic Random Access Memory, DRAM)、Flash之类的存储器搬移出来造成的能耗和延迟,与数据在浮点运算单元(Floating Point Unit, FPU)中运算的能耗和延迟相比,要高出3个数量级以上,这就是所谓的“内存墙”问题[2]。考虑到数据密集型应用的日益增多,研究者在不断地寻找各种方法来缓解甚至消除“内存墙”瓶颈。
在这些研究中,三元内容寻址存储器(Ternary Content Addressable Memory, TCAM)受到了很大的关注,它的工作原理是将输入与多个存储单元的内容并行地进行比较,然后返回匹配到的数据地址[2]。TCAM作为一种特殊的内存计算形式,可以预先存储使用较频繁的数据和对应的计算结果,从而减少实际运算执行的次数,达到节约能耗的目的。由于其高并行性和在内存中进行计算的特性,它被认为是数据密集型应用的一种高效解决方案[1,2]。然而,仍然存在两个关键的挑战,阻碍了TCAM在实际应用中的进一步推广[2,3]:(1)如何在普通的FPU中部署TCAM,在不产生额外成本的条件下,充分地利用TCAM的优势?(2)如何解决传统的基于互补金属氧化物半导体(Complementary Metal Oxide Semiconductor, CMOS)静态随机存储器(Static Random-Access Memory, SRAM)的TCAM不菲的能量和面积消耗?
为了解决CMOS SRAM的高消耗问题,研究者提出了使用新型的非易失性存储器,如可变电阻型随机存储器(Resistive Random Access Memory,ReRAM)[3],来实现TCAM的方案。例如文献[3—5]研究了各种ReRAM TCAM结构以及它们用于FPU计算的使用方案。虽然这些设计相比传统CMOS SRAM提高了一定的内存密度,但它们仍然受限于器件的RON/ROFF,搜索和写入功耗较高[3,6,7]。铁电场效应晶体管(Ferroelectric Field Effect Transistor, FeFET)是另一个比较有前景的非易失性存储器TCAM设计方向,它具有更低的能耗、延迟和面积[6—9]。文献[6]提出了一种基于4T-2FeFET单元的TCAM,获得了比之前其它非易失性存储器和CMOS存储器都高的能效。然而,由于使用了4个CMOS晶体管,该TCAM面积仍然较大。文献[7]提出了一种2FeFET设计来提高密度,但只提供了功能验证,没有物理细节,导致得出了过于乐观的结论。此外,之前的工作都没有完全涵盖上述TCAM在FPU中使用的两个问题,因此需要一个全面的设计方案,通过FeFET TCAM实现高效节能的FPU计算。
本文提出一种新的2FeFET TCAM紧凑实现设计,并深入研究了其特性,从而解决上述能量和面积消耗问题;然后设计了一种嵌入了本TCAM的低功耗浮点运算结构。本方案的贡献包括:(1)提出一个集成了FPU和TCAM的高能效浮点运算结构,并设计一个支持通用GPU应用并显著降低能耗的执行流程;(2)设计一个超紧凑型2FeFET TCAM单元,以避免不必要的寄生效应和面积消耗,与16T CMOS TCAM单元[10]相比,最终实现了7.7倍的内存密度提升;(3)基于物理版图和多电压域Preisach模型[11],本文提出2FeFET TCAM的低能耗、低延迟设计指南。实验结果表明,本文提出的计算结构用于数据密集型应用是非常有前景的,与常规FPU相比,可节省高达33%的能耗。
2 背景
铁电材料氧化铬(HfO2)的最新发展吸引了越来越多的人关注FeFET器件,以及使用FeFET设计CMOS兼容的非易失性应用[7—11]。FeFET晶体管的典型特征是在金属-氧化物半导体场效应晶体管(Metal-Oxide-Semiconductor Field-Effect Transistor,MOSFET)的栅极上叠加一层铁电层,如图1(a)所示,由于铁电材料的极化可以长时间保留,使Fe-FET具有磁滞现象。由于底层MOSFET的固有增益[11,12],FeFET的开关电流比(ION/IOFF)可以高达106。又由于其三端结构和与CMOS兼容,FeFET可用于设计具有独立读取路径的紧凑型TCAM,从而显著降低写入能耗。
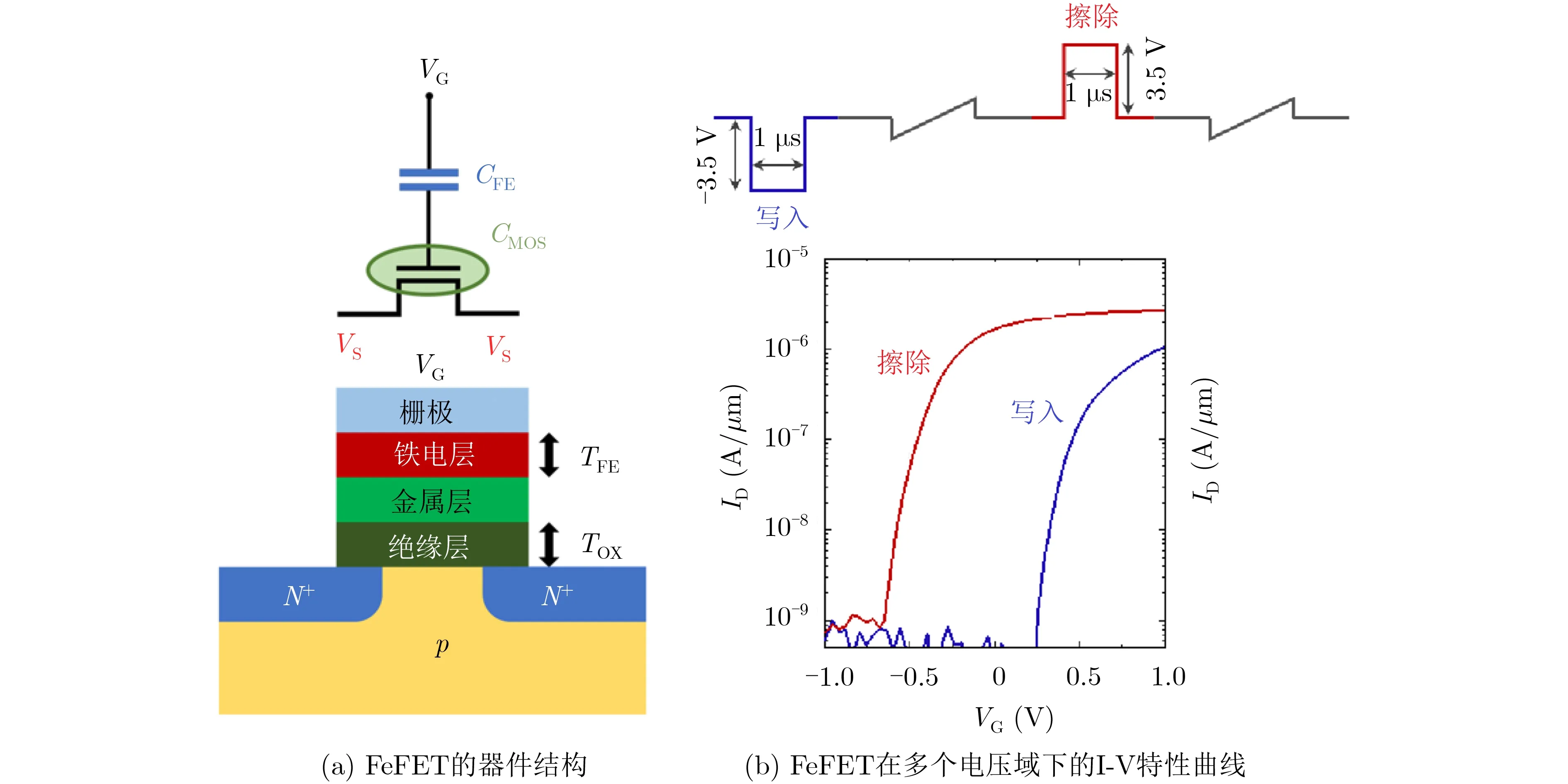
图1 FeFET的器件结构和I-V特征曲线
FeFET通常涉及多电压域切换,具有非饱和磁滞环、迟滞效应和极化开关动态特性,文献[11]提出了一种经过实验验证的多电压域Preisach模型,以精确描述如图1(b)所示的FeFET的I-V特性。本文将采用Preisach模型来描述TCAM的各种现象。
3 计算结构
图2展示了嵌入FeFET TCAM的浮点运算结构及其具体操作方案。为保证FeFET TCAM的高效集成并充分发挥其能耗优势,本文设计了如图2(a)所示的操作执行流程,该流程分为两个阶段:(1)计算样本分析;(2) FPU计算和TCAM搜索。在计算样本分析阶段,首先要统计得到出现频率最多的一组操作数,可以使用GEM5, GPGPU-Sim等微架构模拟器来进行仿真统计,统计时运行多个不同的测试脚本以确保较高的覆盖率[13],这样就得到了一个包含高频操作数和相应输出结果的统计列表。然后设定一个阈值来选择哪些操作数和结果要存储在FeFET TCAM中,这取决于TCAM容量和用户的定义。最后将选好的操作数和结果存放在FeFET TCAM阵列中以供计算过程中的搜索使用。
图2(b)和图2(c)展示了嵌入了TCAM的高能效浮点运算结构及其工作流程,当系统开始执行浮点数运算操作时,输入操作数被同时传送给FPU电路和FeFET TCAM。如果在FeFET TCAM阵列中找到匹配的操作数,那么在FeFET TCAM中预先存储的相应结果将被读出,同时产生一个数据选择器(MUltipleXer, MUX)的选择信号和一个disable信号。disable信号被发送到FPU的门控时钟,将FPU对该组操作数的计算中止掉。MUX选择信号选择FeFET TCAM的输出作为有效输出,屏蔽掉FPU的输出。另外,如果FeFET TCAM中没有匹配的操作数,FPU将正常执行,并将其结果作为输出提供给MUX。由于FeFET TCAM搜索流程的紧凑性,TCAM的搜索比FPU计算快得多,因为常见FPU的计算通常有几个周期的延迟(例如Radeon hd7000系列显卡中的FPU计算需要6个周期),所以当搜索TCAM操作数匹配时,是可以很快中止FPU计算、从而节省不必要的多阶段运算以及相应的能耗。由于不匹配通常发生在不常见的数据样本中,所以发生的概率较低,因此该设计总体上可以显著地降低能耗和计算时间。此外,由于FPU计算和TCAM搜索是并行执行的,这样的结构不需要对FPU进行额外的修改,从而使FeFET TCAM更易于集成。下一节将讨论FeFET TCAM设计的细节、运作及设计指南,来支撑本节的结构设计。
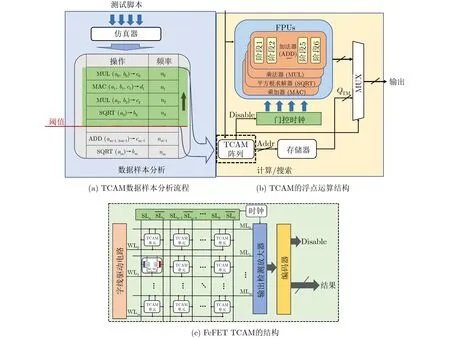
图2 嵌入FeFET TCAM的浮点运算结构及其操作方案
4 2FeFET TCAM设计
基于Preisach模型[11]和图1所展示的开关特性,4 T-2 FeFET结构[6]可以进一步优化成2 Fe-FET结构。因为FeFET可以看作一个单晶体管逻辑门,即将FeFET的栅电压当作输入A, FeFET的存储的值当作输入B,只有当栅电压和储值都是逻辑“1”时,漏极电流ID才为开启电流ION,其他情况下为闭合电流IOFF。换句话说,FeFET可以被用作一个与门,输出电流ID的两个状态分别对应逻辑“1”和“0”。
图3(a)为2FeFET TCAM的单元电路结构,2个FeFET平行放置,漏极连接到匹配线(Match Line, ML),源极连接到源线(Source Line, ScL),两个栅极分别连接到位线(Bit Line, BL)和选择线(Selection Line, SL)。然后将多个2FeFET TCAM单元紧凑地放置在一起,形成一个TCAM阵列。为了减少寄生效应,图3(b)展示了一个2×2 TCAM紧凑型阵列布局,宽度为46λ,高度为26λ。λ是该工艺下晶体管特征尺寸的1/2。其中SL和(或者BL和)共用同一根线,这根线可以是一根直线,不需要额外跨层走线,从而减少了单元中的寄生效应。与CMOS和ReRAM中的对应元件相比,如果根据无生产线芯片设计工艺渠道组织(Metal Oxide Semiconductor Implementation Service, MOSIS)的设计规则,使用45 nm工艺,2FeFET TCAM单元仅为16T CMOS TCAM[3]面积(1.12 μm2)的13%和2T2R ReRAM TCAM[10]面积(0.41 μm2)的35%。与4T-2FeFET TCAM[6]相比,该方案只消耗22%的面积。如此小的尺寸(7.7x内存密度提升)是实现低能耗快速搜索的关键。
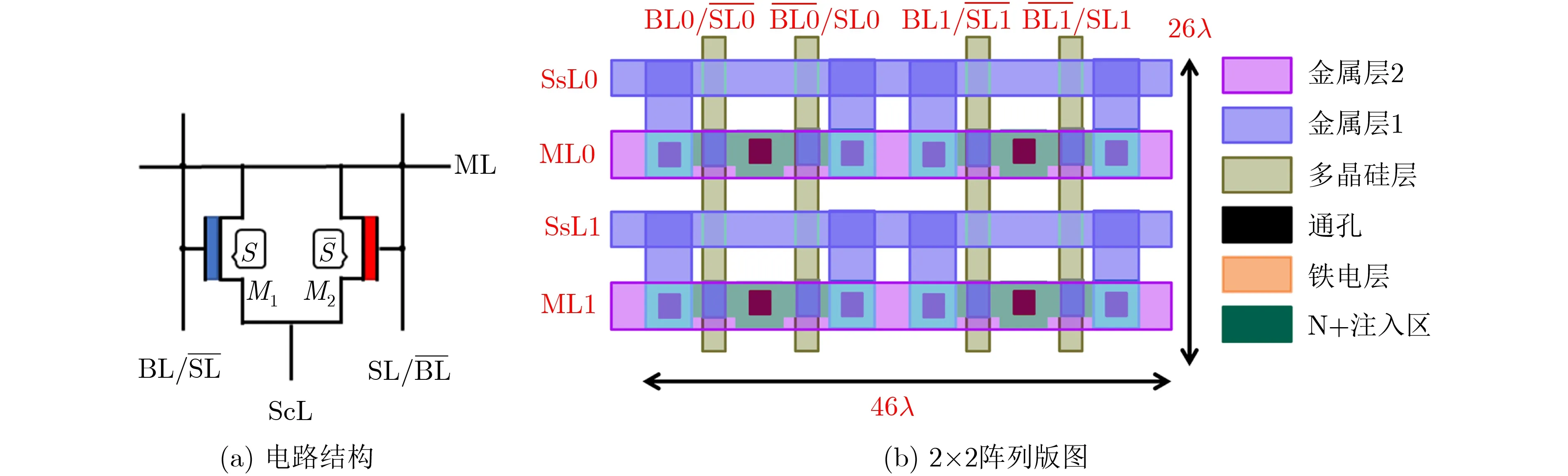
图3 2FeFET TCAM单元电路和阵列版图结构
5 操作和设计原则
针对图3所示的TCAM阵列版图,图4进一步阐述了2FeFET TCAM单元写入状态的操作流程,它可以写入“1”、“0”和“无效”3种状态。该操作需要两个步骤来完成写入,以写入逻辑“1”为例:(1)在ScL为“0”时,写入信号Vwr施加在BL和 SL上,从而使M1的栅极为4 V的高电压,该FeFET中铁电层极性就被翻转,S管就被写入一个“1”的状态;(2)将Vwr施加到ScL,两个FeFET的栅电压保持不变,M2的VGS此时为—4 V,就给写入了状态“0”。这两个FeFET的状态联合起来就表示了这个存储单元为逻辑“1”。以此类推,翻转Vwr的电平即可给这个单元写入“0”。当写入两个“0”状态到这两个FeFET中时,该单元就表示“无效”。这就是TCAM单元的存储实现逻辑。
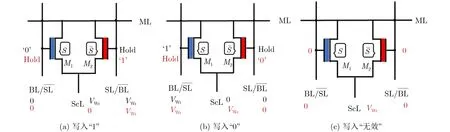
图4 FeFET TCAM单元的写入方法
搜索操作流程如图5(a)所示,与写入相似,也需要两个阶段:(1)预充电阶段,ML预充到高电平;(2)输入数据阶段,根据输入数据将Vsearch设置为图5中TCAM的SL和的状态,即逻辑‘1’设置为1 V,逻辑‘0’设置为0 V。如果存储的数据匹配了,这个单元的2个FeFET都会被关闭,ML停留在高电位。否则,其中1个或两个FeFET将被打开,ML线被拉低。图5(b)给出了搜索过程中匹配和失配两种情况的SPICE仿真波形。
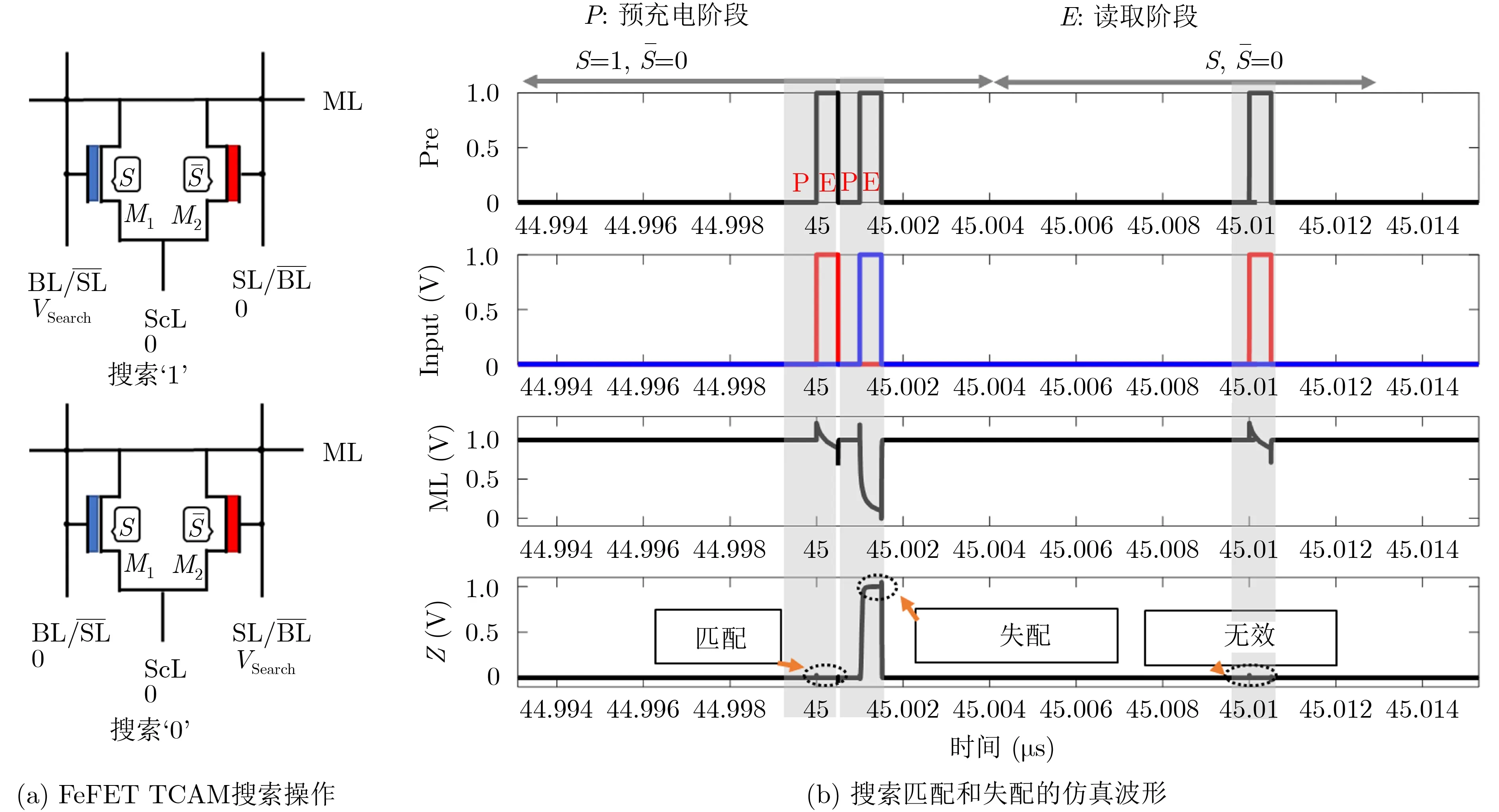
图5 FeFET TCAM的搜索操作流程与仿真波形
注意,上面的仿真电路不仅包含到2FeFET TCAM阵列,而且还包含了写入/搜索缓冲区、字线驱动电路、输出检测放大器(Sense Amplifier,SA)、时钟和编码器等电路结构。为了进一步缩小阵列的时延和功耗,本文有以下设计准则:(1)写入时,将ML保持在低电平,以减少漏电流;(2)在阵列中,ML和ScL位置平行,BL和SL相互垂直。这样的走线不仅使写入和搜索缓冲区的连接更简单,而且还使它们到SA和编码器的走线为一条直线,从而使FPU到MUX的走线有更大的空间;(3)对于阵列中未选中的行,可以将对应的ScL设置为Vwr/2,从而避免不必要的写入干扰。
6 验证实验与测试结果
本节将从两个层面论证该设计结构的优点:(1)不同类型、不同尺寸的TCAM阵列的能耗分析;(2)多种GPU脚本测试的实际性能表现。
本文使用Spectre仿真器分别对2FeFET TCAM, 16T CMOS[3], 2 T2R ReRAM TCAM[8]和4T 2FeFET[6]实现的64×64 TCAM阵列进行了仿真分析,得到了表1所示的性能对比。FeFET TCAM采用45 nm工艺,按如图3所示的版图排列,TCAM单元和SA中的晶体管都为最小工艺尺寸。为了便于比较,16T CMOS TCAM也采用相同的45 nm PTM模型和最小晶体管尺寸。对于2T2R ReRAM,本文采用与文献[3]中相同的参数,设置/复位电压分别为1.8 V/1.2 V, HRS/LRS为2000/20 kΩ。

表1 不同TCAM实现方式的性能对比
可以看到,由于图3所示超高密度的电路结构,该2FeFET TCAM与其它TCAM相比有着显著的能耗优势。ReRAM TCAM由于较高的Ron/Roff,需要有较大尺寸的晶体管来提供写入操作的大电流,因此写入能耗较大(~3225x)。CMOS TCAM由于晶体管数量较多,在面积和能耗方面均处于劣势。2FeFET TCAM紧凑的物理实现不仅使能耗方面受益,而且还可以降低延迟,它的速度是其他TCAM的1.03~3倍。本文进一步比较了尺寸1~64的不同大小TCAM阵列的能耗,结果如图6所示,可以看出,本文的2FeFET TCAM能耗优势是会随着阵列尺寸的增加而增大的。
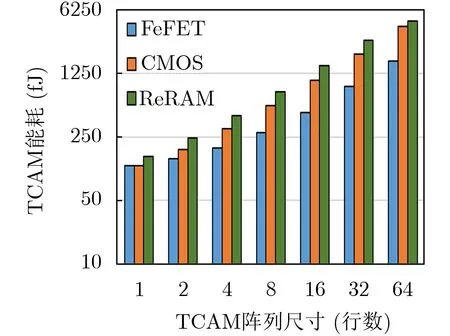
图6 不同工艺的TCAM在各种阵列尺寸下做搜索操作的能耗
最后,本文设计实验研究了嵌入TCAM的运算结构的能耗性能表现。使用Multi2sim仿真工具搭建测试平台,这是一款开源CPU-GPU多核计算机架构模拟器,允许用户自定义运算器功能和系统结构。首先将TCAM编写成Multi2sim支持模块代码,定义其功能、接口以及能耗性能参数。然后修改仿真器库中的AMD Radeon HD 7970 GPU模型,加入TCAM模块,与GPU自带的FPU一起组成图2所示的运算结构。切换TCAM尺寸定义和能耗参数,即可模拟不同尺寸、不同类型的TCAM。执行测试脚本,可统计各种运算操作的次数,计算出整个计算过程的能耗。本文采用Caltech 101数据集[14]中的多个数据密集型测试脚本来比较不同设计方案的能耗。在数据准备阶段,使用GEM5 +GPGPU-Sim仿真流程运行/分析测试脚本,随机选取了数据集中90%的数据用于分析,找出了最常见的一组操作数样本[13],然后将选择的数据存储在相应的TCAM阵列中。然后使用剩下的10%的数据用于实际测试。经过Multi2sim仿真器模拟GPU运行测试脚本,得到了图7所示的结果。这几组结果为3种不同类型TCAM+FPU结构、在不同测试脚本和不同阵列尺寸下的总能耗,结果数据使用文献[15]中的常规FPU能耗为基准进行归一化,图中红字分别为1行、32行、64行时的TCAM所存数据的命中率。如图7所示,采用本文2FeFET TCAM结构在各种情况下的能耗都低于其他两种。值得注意的是,图7的能耗变化还呈现出一种2次曲线的趋势:对于较小的TCAM阵列,能耗随着TCAM数量的增大而减小;到达一个特定的尺寸后,阵列会能耗达到最低;之后,能耗随着阵列大小的增大而增大。这是因为当阵列尺寸较小时,增大阵列可以存储更多的数据样本,实现更高的搜索命中率,从而减少FPU的执行次数。当数组大小超过高频样本的数量后,增大的数组大小对减少FPU执行的贡献不大,反而更大的数组在缓冲、写入和搜索方面消耗的能量更多。平均而言,在32行阵列的情况下,采用2FeFET TCAM的FPU结构在6种测试脚本下平均可以节省33%的能耗,而基于CMOS和基于ReRAM的对应结构的平均能耗节约分别为22%和13%。

图7 多个脚本测试不同TCAM实现的浮点运算结构的能耗
7 结论
本文介绍了一种嵌入新型FeFET TCAM的高效能浮点计算结构,本结构中的TCAM仅用2个Fe-FET实现,从而获得了非常高的集成密度。然后使用该FeFET TCAM设计了TCAM+FPU的计算结构,通过预存储高频计算数据来减少FPU的执行次数,从而节省计算能耗。实验表明,在不同的测试脚本下,本文提出的结构平均可以节省33%的能耗。
