软件缺陷倾向性预测投票方法
2021-06-23刘亚娜吴彩华
刘亚娜 吴彩华 陈 浩 石 晶
(空军预警学院雷达士官学校,湖北 武汉430345)
1 概述
软件内部隐藏的缺陷可能导致其在实际运行时产生不可预料的后果,严重影响软件质量甚至有时会危及到人们的生命安全。而软件缺陷预测可以为软件开发过程提供决策支持,即:在项目的开发初期,通过预先识别出所有可能含有缺陷的软件模块,可以针对性地对这些程序模块设计测试用例,以确保充分测试,从而提高软件质量。程序模块根据实际测试需求可设置为包、文件、类或函数等。目前,缺陷预测模型在构建时常采用支持向量机[1]、Logistic 回归、朴素贝叶斯[2]、决策树[3]、集成学习[4]等常见的机器学习方法。
早期的关于缺陷预测的大部分研究都是集中于单分类器的研究,它们是根据交叉验证所得数据进行实验得到的性能的平均值来作为最终性能,并以此性能来度量模型的,但是平均后的性能并没有得到很大改善,只是在方差上有一定的改进,同时并不能给出样本最终的预测结果。而且软件缺陷预测一般都更加关注少数类的预测效果,但受数据不平衡的影响交叉验证平均后的性能偏向于多类。比如Kaur 等人[5]使用的随机森林分类器,Elish 等人[6]等人使用的支持向量机(SVM),Khoshgoftaar[7]等人使用的神经网络,它们的结果都偏向于多类而忽略了少类,导致结果出现较高的假负率。而本文提出了一种基于软件缺陷倾向性预测投票方法,该方法是使用单分类器的投票机制,即使用一种分类器对分层交叉验证的数据进行下采样构建模型,对其得到的多个预测结果进行投票得到最终的预测结果,并基于该结果计算模型的性能。
2 软件缺陷倾向性预测投票方法
以下将软件缺陷倾向性预测投票方法简称投票法,将软件缺陷倾向性预测平均法简称平均法。
2.1 PCA 及主成分个数的确定
本文采用一组3×2 交叉验证来选择主成分个数k,采用缺陷预测的性能指标(本文用F1 值)在测试集上最大来选。对数据KC1,PC3,PC4 分别构造一组3×2 交叉验证,对k=1,2,…p(p 为数据集中属性的个数)分别构建基于PCA 的缺陷预测模型,选取在6 份上的F1 指标平均值最大的k 作为模型的主成分个数,KC1 数据集上挑选的k=3,PC3,PC4 数据集上挑选的k=14。
2.2 投票法
给定一个数据集为D= {(xi,xy)|i=1,2,…n},yi的取值为{0,1},0 表示没有缺陷,1 表示有缺陷;给定二折交叉验证的重复次数m;给定一个机器学习算法L;给定一个m×n 的矩阵A,向量Pred,m×4 的矩阵Perf。
投票法首先对数据进行了m×2 的分层交叉验证,交叉验证结束后可以得到一个m×n 的矩阵A,其中元素A[i,j]表示第次二折交叉验证后对样本j 的预测结果(以0,1 的形式表示),二折交叉验证共重复m 次,所以可得到m 行n 列的预测结果A,得到矩阵A 后,对A 中的预测结果进行投票,其中A 矩阵中第j(j=1,2,…n)列存储的是第j 个样本的m 个预测结果,对这m 个预测结果进行投票,使用m/2 作为阈值,如果第j 列中m 个结果中1 的个数大于或等于它的阈值,则最终判断第j 个样本为有缺陷(1),否则为没有缺陷(0),重复n 次,将数据集D 中n个样本的最终预测结果存储到Pred 向量中,最后按照此最终预测结果计算出precision,recall,F1,accuracy 的值,其算法如图1所示。

图1 投票法算法伪代码
3 数据集及性能指标
3.1 数据集
本文实验数据来源于PROMISE 平台上的KC1、PC3 和PC4数据集。KC1 数据集包含2109 个样本,21 个变量;PC3 数据集包含1125 个样本,37 个变量;PC4 数据集包含1399 个样本,37个变量。
3.2 性能度量
本文使用的性能度量为precision、recall、F1 值、accuracy,其计算公式如下:

其中,TP 为实际有缺陷被预测为有缺陷的样本数;FP 为实际没有缺陷被预测为有缺陷的样本数;TN 为实际没有缺陷被预测为没有缺陷的样本数;FN 为实际有缺陷被预测为没有缺陷的样本数。
4 实验结果及分析
在KC1、PC3 和PC4 数据集上使用logistic 回归模型的实验结果如图2 所示,对于KC1、PC3 和PC4 数据集使用logistic 回归建模来说其对应的投票结果的precision、recall、F1 值、accuracy 值都高于平均结果。所以综合而言,在KC1、PC3 和PC4数据集上投票方法的性能优于平均结果的性能。
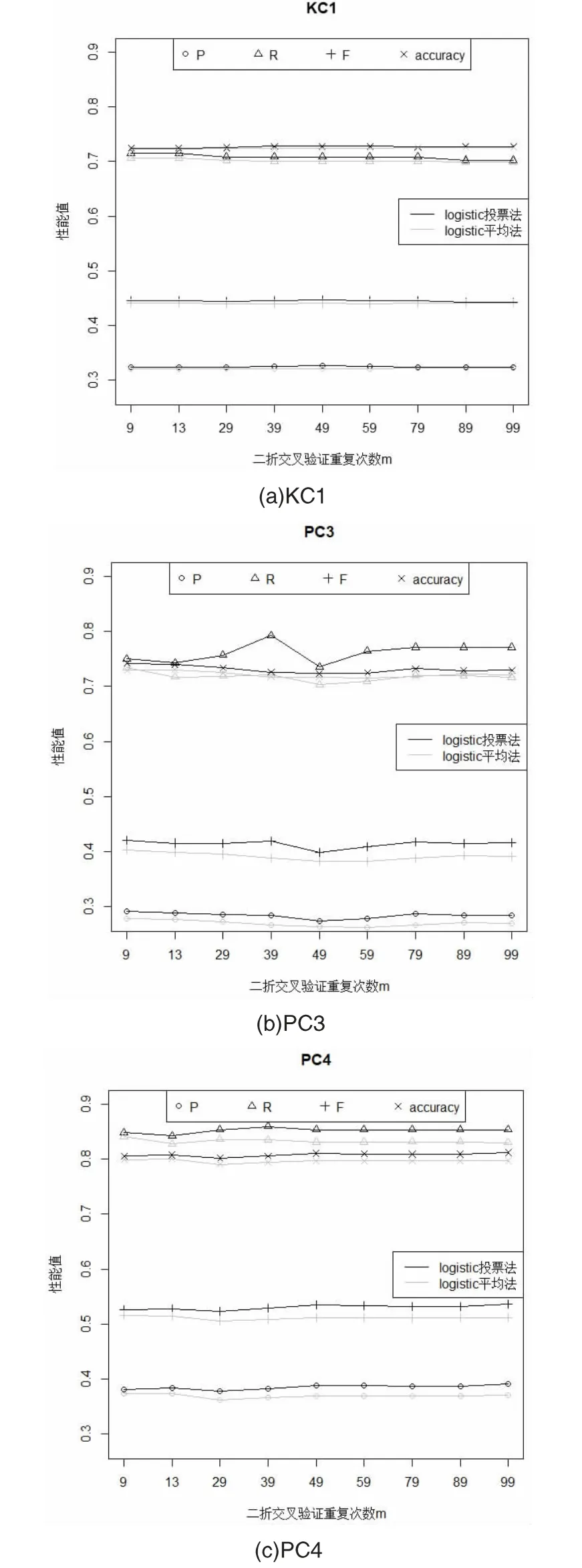
图2 数据集使用logistic 模型的投票实验结果
在KC1、PC3 和PC4 数据集上使用决策树模型的实验结果如图3 所示,对于KC1、PC3 和PC4 数据集使用决策树建模来说,其对应的投票法的precision、recall、F1 值、accuracy 值都高于平均法得到的性能结果。所以综合而言,在KC1、PC3 和PC4 数据集上投票方法的性能优于平均结果的性能。
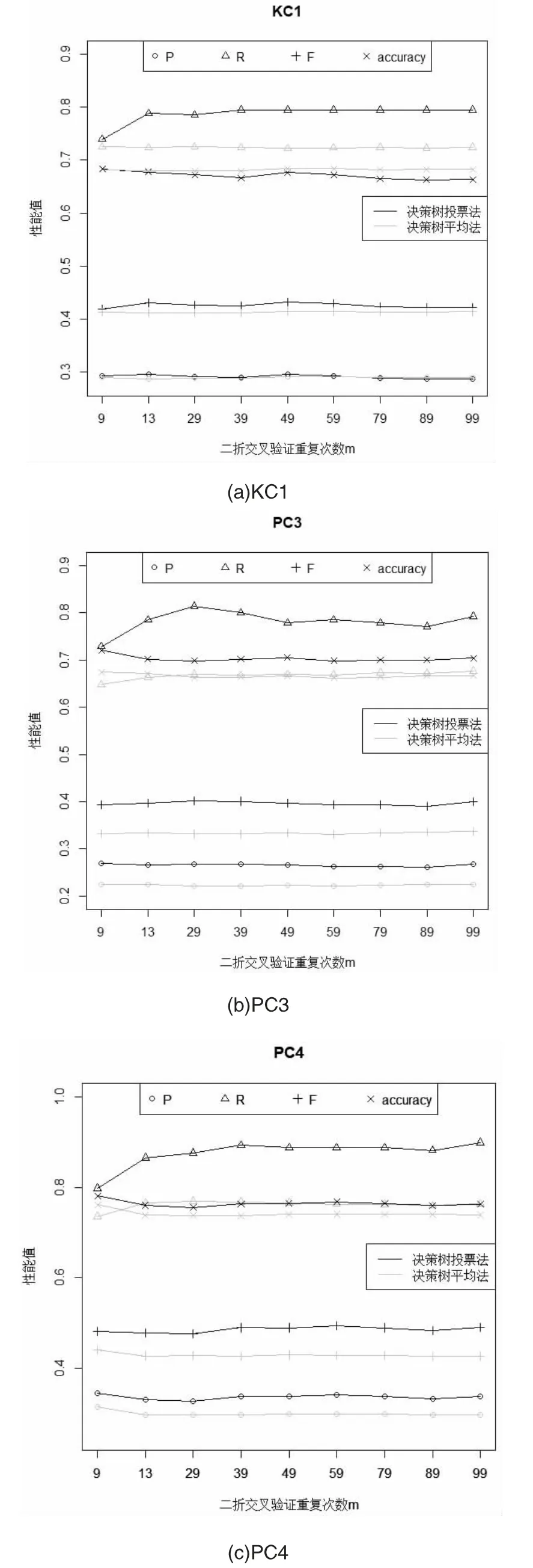
图3 数据集使用决策树模型的投票实验结果
5 总结与展望
针对传统的计算软件缺陷预测模型的性能是按照交叉验证后性能的平均值进行度量的,而本文则是按照交叉验证后投票得到的最终预测结果计算得到的性能值度量模型的。该方法在NASA 的KC1、PC3 和PC4 数据集上分别构建了logistics 回归模型和决策树模型,从实验结果可以得出,该方法可以得到待测样本的最终预测结果;其性能基本优于平均法计算得到的性能值。所以综合来说,该方法具有一定优势。
该方法仍有一些后续工作有待扩展:
(1)该方法只在NASA 数据集上进行了实验,之后将在其他跨项目数据集进行实验,验证该方法的有效性;
(2)尝试以特定的比例对数据进行下采样,以进一步缓解类不平衡问题;
(3)在该方法中进一步考虑特征选择方法,通过移除数据集中的冗余特征和无关特征来进一步提升软件缺陷预测模型的性能。
