基于YOLOv3的轻量化高精度多目标检测模型
2021-06-22陈晓艳任玉蒙张东洋许能华闫潇宁
陈晓艳,任玉蒙,张东洋,洪 耿,许能华,闫潇宁
(1. 天津科技大学电子信息与自动化学院,天津300222;2. 深圳市安软科技股份有限公司,深圳518131)
当前行人车辆检测算法在边缘设备中的应用占用内存过大,且无法达到实时性要求.随着智慧城市建设和人工智能及大数据技术的迅猛发展,实现各种场景中的行人和车辆等重要目标的精准检测成为智慧城市的重要任务.目标检测一直被认为是计算机视觉领域中最具挑战性的研究课题之一,这是由于它需要在给定图像中精确定位特定目标类的对象,并为每个检测目标分配一个对应类的标签[1-2].
基于图像分类的传统目标检测方法是在检测图像中提取若干区域,用训练好的分类器逐个判断每个区域的所属类别[3].检测过程包含图像预处理、特征提取、特征分类及后处理等阶段.
HOG-SVM(histogram of oriented gradient,HOG;support vector machine,SVM)被描述为传统的目标检测算法中最成功的行人目标检测方法,并在一些实际场景中得到了广泛的运用[4];但该方法对物体的轮廓特征提取不够准确,且特征提取能力不够稳定.Krizhevsky等[5]提出的AlexNet网络,开启了基于卷积神经网络(convolutional neural networks,CNN)的目标检测研究.二阶检测器R-CNN系列算法[6-7]提出的以样本候选框提取特征的目标检测算法受到极大的关注,目标检测精度明显提高,但是由于选择性搜索得到的有效候选框的数量太多,卷积神经网络计算量十分庞大,要得到理想的检测精度,对时间和算力的要求显著提高.
近几年,YOLO(you only look once)系列算法[8-10]给目标检测领域带来了全新的思路,即将分类任务和定位任务进行合并,图片经过一次特征提取之后就可以获取目标的位置和类别.尤其是YOLOv3模型,它使用了end-to-end的设计思路,将整张图片进行特征提取,并将目标检测问题转换成单一的回归问题,可直接计算出多种目标的分类结果与位置坐标,既保证了检测的速度又保证了检测的精度[10].
然而,YOLOv3模型有235MB内存,参数量约65MB,检测速度不够理想,在模型的轻量化和处理速度上存在很大的提升空间.模型的轻量化意味着对终端图像处理芯片的需求降低,更便于在嵌入式设备上部署,这对智慧城市的建设具有十分重要的意义,不仅节约建设成本,而且提升城市安防的智能化水平[11].本文在YOLOv3基础上提出一种轻量化高精度模型,使其在目标检测保持高精度的同时,大幅减小模型,提升处理速度.主要针对特征提取网络、交并比计算以及损失函数进行了改进:将MobileNet作为特征提取网络,即将标准卷积替换成点卷积和深度可分离卷积,降低大量参数量;采用CIOU(complete intersection over union)进一步精确计算目标框和预测框的距离,并反映两者的重合度大小;在损失函数中引入了Focal loss,解决正负样本分布不平衡以及简单样本与复杂样本不平衡所造成的误差;同时在训练过程中引入标签平滑(Label Smoothing)抑制过拟合.
1 目标检测算法
YOLOv3网络的基本结构分为两个部分,如图1所示,特征提取部分和预测部分.其中特征提取网络Darknet53由1个CBL层和5个残差块组成.CBL层是由卷积层、BN层和LeakyRelu激活函数组成.残差块结构如图1绿框所示,由2个CBL单元和1个残差边组成.而预测部分融合了3种不同尺度的边界框.Darknet53提取出来的3个特征图经过卷积层加强特征提取之后进行上采样,再次进行特征融合来丰富不同尺度的特征.

图1 YOLOv3网络结构图Fig. 1 YOLOv3 network structure diagram
本文算法是在YOLOv3算法的基础上进行改进,其检测流程是先输入大小为418×418的图片,将图片划为S×S个网格,检测每个网格是否含有目标中心点.若有目标中心点,则计算该物体属于某一类的后验概率并同时预测多个目标边框.每个被预测的边框包含5个参数,分别为目标边框的中心点坐标(x,y)、宽高(w,h)和置信度评分Si.将置信度小于阈值的边界框置零,采用非极大值抑制算法筛除冗余的边界框,最终确定目标的位置.本文中的YOLO-A模型是将YOLO的特征提取网络替换成MobileNet.YOLO-B模型在YOLO-A的基础上将IOU(intersection over union)改进为CIOU、在损失函数中引入Focal loss以及引入Label Smoothing.
1.1 特征提取网络
MobileNet是Google公司在2017年提出用于移动端和边缘设备中的轻量级网络.它提出的一种新的卷积思路是将标准卷积替换成点卷积和深度可分离卷积,大大地降低了模型的计算量.深度可分离与标准卷积的卷积核运算如图2所示.

图2 标准卷积与深度可分离卷积 Fig. 2 Standard convolution with depthwise separable convolution
假设输入一张大小为 DF×DF×M的图片,输出图片大小为 DF×DF×N,卷积核大小为 DK×DK.计算量的计算公式为

式中:FLOPS表示计算量,Ci为输入通道,Co为输出通道,DK×DK为卷积核大小,DF×DF为输出图片大小.
若采用标准卷积,则计算量为式(2);若采用深度可分离卷积,则计算量为式(3).

本文算法的特征提取网络中N的值远大于1.由公式计算可得,深度可分离的计算量远远小于采用普通卷积所带来的计算量.
1.2 CIOU精选预测框
交并比IOU用于表示目标框和预测框的交集和并集之比,它不仅可以用来确定正样本和负样本,还可以反映预测框的检测效果[12].若预测框和真实框相近,IOU值就大,反之IOU的值就小.IOU示意图如图3所示,计算公式为

采用IOU度量两个框之间的距离和重合程度,在训练过程中存在两种极端的情况:其一,当两个框没有交集,即IOU=0时,无法表示两者的距离,也无法反映两者的重合度大小;其二,如图4(a)和(b),其IOU值虽然相等,但拟合程度是完全不一样的.

图3 IOU示意图Fig. 3 The schematic diagram of IOU

图4 目标框和预测框重叠情况示意图 Fig. 4 Schematic diagram of overlap between target box and prediction box
针对上述情况,采用CIOU度量目标框和预测框的距离与重合程度.CIOU在充分利用尺度不变性的基础上,融合目标框与预测框之间的距离及其重合程度[13],并将预测框长和宽的比值作为惩罚项,从而使预测框的效果更加稳定.CIOU示意图见图5.

图5 CIOU示意图 Fig. 5 The schematic diagram of IOU
CIOU公式为

其中:α为权重函数,ν为衡量长宽比的相似性参数,α和v的公式为
图中:d =ρ2(b, bgt)是预测框和真实框的中心点的欧氏距离, b =(x,y,w,h)是真实框的信息,bgt=( xgt, ygt, wgt, hgt)是预测框的信息;c是包含预测框和真实框的最小矩形区域的对角线距离.
1.3 损失函数
在YOLOv3模型中,由于产生的先验预测框绝大部分都不包含目标,这就造成了正负样本比例失衡,导致大量的负样本影响损失函数,少量正样本的关键信息不能在损失函数中发挥正常的作用.借鉴Focal loss损失函数概念[14],通过减少负样本在样本总量的权重,使得模型在训练时更专注于难分类的样本,即正样本可以发挥出在损失函数中的作用.
Focal loss是在交叉熵损失函数基础上进行修改,以二分类(即0和1两个类)交叉熵损失函数为例,表达式为

y′是经激活函数的输出概率,在0~1之间,对于输出为1的正样本,若输出概率越大则损失函数越小;对于输出为0的负样本而言,若输出概率越小则损失函数越小.由于输出为0的负样本太多,导致对损失函数的优化比较缓慢,难以获得损失函数的最优解.为了降低负样本在损失函数中所占的权重,充分发挥正样本在损失函数中所占的比重,即加入平衡系数α以降低负样本的比重[15],得到的损失函数为

在此基础上又增加一个动态缩放因子γ,自动降低简单样本的损失,帮助模型更好地训练困难的样本,最终形成的Focal loss为

1.4 Label Smoothing
在处理人车分类问题时,当使用最小化交叉熵损失函数更新模型参数时,模型的泛化能力弱,容易导致过拟合,所以先引入一个与样本无关的分布u(i)(平滑因子),将标签m修正为m′,见式(11),达到抑制过拟合的目的.
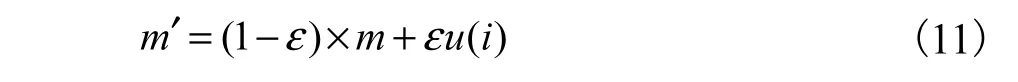
其中:i为标签类别数目,u(i)的取值1/i,本文中共有人、车两类,故 u(i) = 0.5;ε是伸缩因子,用来调整平滑之后标签数值的大小,有效抑制过拟合.本文YOLO-B网络检测示意图如图6所示.

图6 YOLO-B网络检测示意图Fig. 6 YOLO-B schematic diagram of network detection
2 实验及测试结果
本文所有的算法都是基于Keras框架实现的,并使用深圳市安软科技有限公司提供的39064张已标注的数据集(以下简称安软数据集),其中验证集包含3982张图片,测试集图片包含500张,测试集中人和车两类目标及其目标框数量如图7所示,每张图片的大小为1920×1080.实际应用场景包括人和车相交互的近景、远景、白天和夜景.本文任务是在实际应用场景下对行人和车辆进行快速准确地检测.

图7 测试集两类目标及目标框数量Fig. 7 Number of objects per class and target boxes in the two categories of test set
训练环境采用的是Ubuntu 18.04操作系统,CPU为Intel XeonE5-2360,显卡为两块NVIDIA GEFORCE GTX1080Ti 11GB.实验过程中batch size设置为16,即每个epoch在训练集中取16个样本进行训练,直至全部样本训练完成一次即为1个epoch.模型训练时共训练100个epoch.测试实验环境采用的是Windows10操作系统,CPU为i5-9400F@2.9GHz,显 卡 为 NVIDIA GEFORCE GTX1660 6GB.由于数据集所含目标框的数量不同,导致每张图片检测的时间有所不同.利用500张测试集的测试总时间计算平均检测速度(FPS).采用平均准确率(mAP)及模型大小等指标对目标检测模型进行评估.
为了验证本文YOLO-B算法的性能,采用YOLOv3 原 型、YOLO-Slim[16]、YOLOv3-tiny、YOLOv3-D[17]、YOLOv3-剪枝和YOLO-A进行对比.其中,YOLOv3原型是由YOLOv3作者提出没有加以改进的模型;YOLO-Slim是YOLOv3的骨干网络替换成MobileNetV2并进行剪枝处理,其目的是为了降低参数量和模型大小;YOLOv3-tiny是一个公开的目标检测轻量级模型;YOLOv3-D模型是在YOLOv3的基础上引入CIOU和Focal loss,从而提高目标检测的精度,但是模型大小不会发生改变;YOLOv3-剪枝是在YOLOv3的基础上降低通道数,从而实现减小模型、降低计算量和增加检测速度的目的.
2.1 平均检测速度测试结果
对7种模型分别进行训练和测试,平均检测速度见表1.YOLOv3的检测速度为11.2帧/秒,YOLOv3-剪枝的检测速度为14.3 帧/秒,YOLOv3-tiny是一种以YOLOv3为基础的轻量化模型,其检测速度达到25.1 帧/秒,检测速度优势明显.YOLOSlim的检测速度略微逊色于YOLOv3-tiny,而本文提出的YOLO-A和YOLO-B的检测速度均为20.6帧/秒,快于YOLOv3,检测速度相对提升了83.9%.由于YOLO-B相对于YOLO-A来说参数量相同,故YOLO-A和YOLO-B的检测速度是一样的.

表1 目标检测算法性能评价指标对比结果 Tab. 1 Comparison results of performance evaluation indexes of target detection algorithm
2.2 平均准确率测试结果和模型大小对比
7种模型的平均准确率测试结果见表1.由表1可知:YOLOv3的平均准确率值为57.80%,YOLOv3-D的平均准确率为58.32%,两者表现很好,但是模型太大;YOLOv3-剪枝、YOLOv3-tiny和YOLO-Slim的模型比较小,但是平均准确率均低于50%;YOLO-A和YOLO-B的平均准确率比其他5种模型都高.YOLO-A和YOLO-B的模型大小相同,由于通过改变损失函数以及其他优化方法使得YOLO-B的平均准确率高于YOLO-A的,达到59.23%,网络模型大小仅为原始YOLOv3的40%.
2.3 精确率测试结果
在测试集中对行人和车辆分别进行目标检测,检测精度见表1.结果表明,无论是检测行人还是检测车辆,YOLO-B的精确率均高于其他6种算法.通过进行对比得出YOLO-B算法综合表现优秀.YOLOB训练过程中的loss值变化如图8所示,随着迭代次数的不断增加,loss值不断降低,最终达到稳定状态.
为了直观地表达检测效果,在YOLO-B算法训练完成之后,使用Yolo-B算法对测试集进行测试并对结果进行可视化,测试集的场景均为摄像头真实场景,图9为真实场景测试的效果.
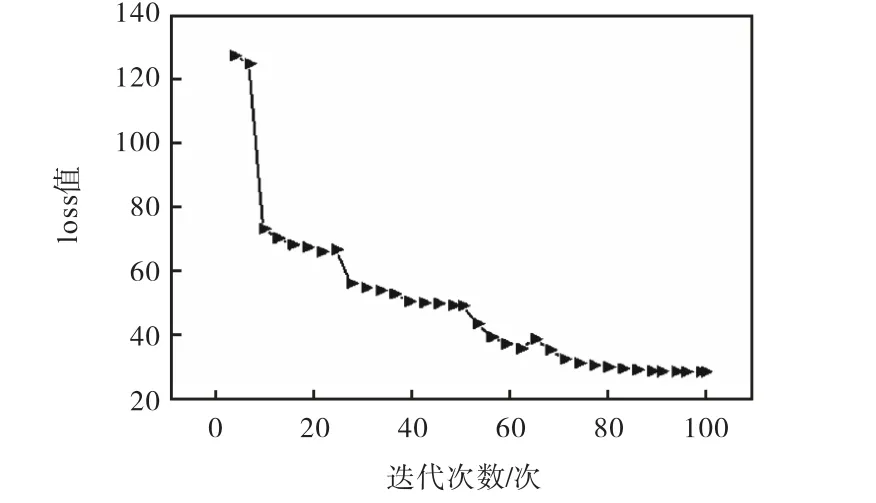
图8 YOLO-B训练过程中的loss变化情况 Fig. 8 Changes of loss during YOLO-B training

图9 YOLO-B算法真实场景测试效果图 Fig. 9 YOLO-B algorithm real scene test renderings
3 结 语
针对模型轻量化的需求,调整YOLOv3的网络结构.首先在YOLOv3的基础上将特征提取网络替换成MobileNet,大幅度降低模型大小;其次是将IOU改进为CIOU并在损失函数中引入Focal loss,并且又引入Label Smoothing,最终形成YOLO-B网络模型.通过对模型的对比实验以及测试结果显示:网络模型大小仅为原始YOLOv3的40%,并且通过模型优化策略,保证了检测的精度.
本文提出的网络模型在公共安全监控中能有效地做到快速准确的检测要求,为嵌入式平台应用提供了一种高性能的轻量化模型结构.下一步的工作是将该算法移植部署至多路摄像头终端,进行实际场景的应用.
