基于M-Xception网络的戴口罩人脸表情识别
2021-06-22韦赛远林丽媛张怡然
韦赛远,林丽媛,张怡然
(天津科技大学电子信息与自动化学院,天津 300222)
人脸识别技术作为身份认证的重要工具,具有非接触式、成本低、方便快捷的特点[1].同样,人脸表情识别技术由于其高信息量、情感交互的作用,吸引更多研究者的关注.随着计算机技术的不断发展,基于深度学习的人脸表情识别技术正在得到充分挖掘和应用.但是,由于口罩遮挡人脸表情的绝大部分信息,使得戴口罩的人脸表情识别具有高度复杂性,所以戴口罩的人脸表情识别技术的相关研究较少,识别的准确率一直偏低.目前,普遍关于人脸表情识别的研究都集中在无遮挡情况,其中王韦祥等[2]提出改进的双通道卷积神经网络模型,在JAFFE数据集和CK+数据集上均取得不错的识别效果,但是没有考虑到光照、遮挡对识别的影响.李勇等[3]提出一种跨连接的LeNet-5结构,学习低层次特征以弥补表情数据集样本不足带来的问题,但是该结构关注低层次特征而忽略了各层特征的相互关联,导致模型泛化性不好.王建霞等[4]提出一种改进的跨连接VGG[5]网络,将网络中的低层次特征与高层次特征进行融合以提高鲁棒性,并引入Inception网络结构加快收敛速度,在FER2013识别率(无口罩)达到72.76%,但该方法仅考虑了表情的类内差距较大的情况,对于混合表情识别率较差.
本文提出了一种M-Xception网络(Modified Xception Net)模型,实现戴口罩有遮挡的人脸表情识别.该网络简化了Xception冗杂的参数结构,保留残差机制和可分离卷积特征,注重各层特征的关联性,对细微表情信息的提取尤其敏感.同时,为了防止过拟合现象,在全连接层引入了Dropout技术.实验结果表明,改进后的网络能有效提高戴口罩人脸表情识别的准确率,达到更好的分类效果.
1 M-Xception网络模型
1.1 M-Xception网络模型的训练测试框架
Xception[6]网络利用“极致的Inception”模块(Block)以减少网络参数,并结合类似于ResNet[7]的残差机制以保证网络的稳定性.本文在Xception网络基础上,结合戴口罩的人脸表情识别(face emotion recognition with mask,FERM)受限于遮挡的问题,在简化模型的基础上注重细微特征(如眉毛、眼神)的提取,搭建了一个输入尺寸为48×48×1的MXception网络模型,其训练测试框架如图1所示.

图1 M-Xception网络模型的训练测试框架 Fig. 1 Training and testing framework of M-Xception net model
在训练部分,未戴口罩的人脸关键特征点有68个,首先用Face-Mask技术确定鼻子、嘴巴等部位的特征位置,并加上口罩进行特征遮挡处理.对添加口罩遮挡的数据集进行筛选,去除标签丢失、标签错误、非人脸等不符合要求的图片,生成新的数据集FERM.其中与表情相关的特征点为27个,然后将此数据集投入M-Xception网络进行训练.
测试网络结构时,对图片进行预处理后,采用训练好的模型进行测试,得到表情的分类结果.
1.2 M-Xception网络结构
M-Xception网络模型的网络结构(图2)共分为3个部分:Entry flow、Middle flow和Exit flow.
首先,在M-Xception网络结构的Entry flow输入部分,与Xception通过2个stride分别为2、1的卷积层不同,M-Xception网络将输入特征图通过2个stride=1的标准卷积层,目的是在保留原始特征位置信息的同时加深网络深度.
其次,通过2个深度可分离卷积Block代替Xception网络中“极致的Inception”,以减少参数.假设输入特征图大小为M×M,通道数为C(C>1),标准卷积的规格是k×k×C×C′(k取3,C′表示特征图经过卷积后的输出通道数),输出大小为M1×M1,标准卷积如图3(a)所示,则其参数量为

若以上情况使用“极致的Inception”,其结构如图3(b)所示,其参数量为

由于C>1且为整数,所以n1-n2>0,因此在特征提取过程中可知参数量n1>n2.随着层数的增多,“极致的Inception”一般可比标准卷积减少约90%的计算量.本文所使用的深度可分离卷积,其结构如图3(c)所示,与图3(b)相似,区别在于将“极致的Inception”结构中1×1和3×3卷积进行颠倒可得到深度可分离卷积.在上述假设中,参数量为
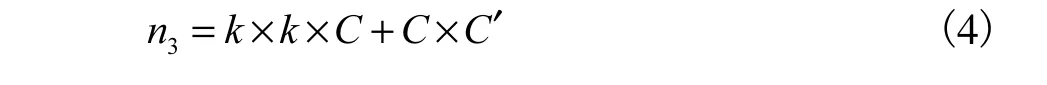
在本文的网络结构中,C′>C(除最后一层分类),故参数量n2>n3.因此,即M-Xception网络放弃使用Xception网络的“极致的Inception”,改用深度可分离卷积模块.

图2 M-Xception网络模型的网络结构Fig. 2 Structure of M-Xception network

图3 标准卷积、“极致的Inception”和深度可分离卷积示意图Fig. 3 Diagrammatic drawing of standard convolution,“extreme Inception” and deep separable convolution
最后,把Xception的Middle flow部分提前1个Block并将重复8次减少至3次,目的是减少参数、简化模型,实验证明对准确率没有影响.经过1个深度可分离卷积Block,进行全局平均池化后通过Softmax[8]完成分类.整个M-Xception网络结构,除了深度分离卷积层dw和pw之间使用线性激活函数(保留信息特征)之外,其他卷积层之间均添加BN[9]层、ReLU[10]激活函数,防止数据发散并增强模型的非线性表达能力.
分别将Xception、M-Xception网络模型在没有口罩遮挡的数据集FER2013上进行训练、测试,结果见表1.M-Xception网络模型具有更加简洁、快速、高效等轻量级的特性.改进前后两种网络模型在FER2013数据集上的准确率均为68%左右,准确率都不高,这是因为FER2013数据集存在标签缺失、错误以及非人脸表情图片等问题,而由人类进行主观识别的准确率也只有(65±5)%左右.因此,后续戴口罩实验先去掉了FER2013数据集的标签缺失、错误以及非人脸表情等图片,再进行Face-Mask口罩遮挡处理,具体实验过程详见2.2节.

表1 Xception网络改进前后对比Tab. 1 The comparison of before and after Xception network improvement
2 实 验
2.1 实验环境
在PC端上的实验以深度学习框架Keras为基础,使用TensorFlow作为其后端,编程语言采用Python 3.6.实验使用的GPU为NVIDIA GeForce RTX 2080 Ti,其显存大小为11GB,CPU为 Intel Xeon CPU E5-2678 v3 六核,其内存大小是62GB,在Windows 10 64位操作系统上进行.
2.2 数据集
有关表情识别的现有开源数据集有CK+、JAFFE、HUMAINE Database、MMI、NVIE和FER2013等.由于FER2013数据集更加符合实际生活场景,由7种表情共35886张人脸表情图片组成,数据规模较大,在全脸未遮挡的情况下,嘴巴动作、双眼、眉毛形态等使人脸的表情信息量较为丰富.佩戴口罩前后的人脸关键点信息如图4所示.利用Dlib[11]的Face-Mask技术,对FER2013无遮挡的表情数据进行戴口罩的遮挡处理,处理前后图片对比如图5所示.

图4 佩戴口罩前后的人脸关键点信息 Fig. 4 Facial key points before and after wearing a mask
由于口罩遮挡,鼻子、嘴巴以及脸上部分轮廓的特征几乎完全损失,导致表情中的微笑与中性、厌恶与生气、恐惧与惊讶的差异较小,使得这些表情在有遮挡的情况下难以区分,因此对数据集进行裁剪处理:第一,去除戴口罩条件下的相似表情类别中的一类,保留中性、悲伤、惊讶、生气表情数据;第二,去除非正脸、模糊、标签丢失、标签错误、非人脸等不合格图片.处理后的数据集使用FER+标签完成数据标注.最后得到3840张戴口罩的4类表情数据作为实验数据集FERM,其表情类别数量分布见表2.

图5 Face-Mask处理前后 Fig. 5 Before and after Face-Mask treatment

表2 4类表情数量分布 Tab. 2 Number distribution of the four types expressions
2.3 图像预处理
为了提高模型的泛化性能,采用框架Keras的ImageDataGenerator()工具进行数据增强,设置图片随机转动角度为10°,图片随机水平、竖直偏移的幅度为0.1,并进行随机缩放和水平翻转,以避免出现过拟合现象.
2.4 实验结果与分析
实验均采用Adam[12]优化器优化损失,epoch为100,batch_size为64,将训练集和验证集的比例设为9﹕1.按照表1所设计的网络模型进行训练,将预处理后的图片输入网络,M-Xception网络模型的实验结果验证集准确率相比较于CNN、mini_Xception和Xception(同等输入规模)网络的戴口罩有遮挡表情识别的平均准确率见表3.由表3可知,M-Xception网络加上Dropout技术的准确率最高,为88.95%,说明本文改进的模型具有更加理想的识别效果.MXception+Dropout网络模型准确率比M-Xception网络模型高,可见Dropout有效地防止了过拟合,提高了验证集准确率.M-Xception网络模型的准确率比Xception网络模型的高,且M-Xception网络模型耗费时间比Xception网络模型的短,表明改进后的模型既节省了模型参数又缩短了训练时间,同时还提高了准确率,进一步证明M-Xception网络模型模型对于较小输入特征具有良好的应用价值.使用MXception+Dropout模型权重在全数据集中进行准确率的测试,得到混淆矩阵如图6所示,结果表明模型的准确率均较高.

表3 不同模型的平均准确率对比 Tab. 3 Comparison of average accuracy of different models

图6 M-Xception+Dropout模型权重下的混淆矩阵Fig. 6 Confusion matrix under the weight of M-Xception+Dropout model
3 结 语
本文提出了一种M-Xception网络模型用于戴口罩人脸表情的识别.在M-Xception网络模型中,通过减少原网络Xception模型网络层数和使用深度可分离卷积,保证了网络的轻量级特性,同时保留Xception模型将低层次特征与高层次特征进行融合的特性,提高网络的特征提取能力,并加入Dropout技术防止过拟合现象,最后采用Softmax分类器对提取的特征进行分类.实验结果表明本文改进的模型可以在戴口罩有遮挡的FERM数据集上达到较高的识别准确率,超过了现有的有遮挡表情识别方法.由于现实生活中表情识别的干扰因素众多(光照、侧脸等),因此如何建立自然场景下人脸有遮挡表情数据集,并进一步分析被遮挡的有限关键点的人脸表情识别,将是后续工作的研究重点.
