基于迭代知识精炼的对偶学习蒙汉机器翻译
2021-06-22侯宏旭乌尼尔贾晓宁李浩然
孙 硕,侯宏旭,乌尼尔,常 鑫,贾晓宁,李浩然
(内蒙古大学计算机学院,内蒙古 呼和浩特 010020)
近年来,基于深度学习的神经机器翻译(NMT)[1-2]发展迅速,主要以交叉熵为训练准则,即最小化机器译文和参考译文的熵值.因此,平行语料的质量及规模决定了模型的最终翻译水平,也成为评判监督学习方法好坏的重要指标.然而,当平行资源规模较小时则会由于数据稀疏导致训练过拟合,无法很好地实现双语映射,交叉熵准则也不能发挥最大作用.
为了缓解NMT模型对双语语料的依赖,研究者们提出缩小建模粒度、反向翻译、迁移学习、多语言训练以及无监督学习等方法.Sennrich等[3]采用细粒度单元的建模方法将单词切分为子词或字符粒度来缓解语料资源匮乏而产生的集外词(OOV)现象,然而粒度的尺寸选择和不同粒度间的对齐关系学习会影响模型的质量.Johnson等[4]提出了谷歌多语种NMT系统,采用迁移学习方法在不改变模型主要结构的情况下,从输入句子最开始处增加一个额外的标记来表示需要翻译到的目标语言,这种方法可以在低资源甚至零资源任务上明显提升翻译性能.Gu等[5]提出元学习机器翻译方法,首先采用许多高资源语言训练一个表现出色的初始参数,然后构建一个所有语言的词汇表,再以初始参数为基础训练低资源语言的翻译模型,在此基础上进一步优化初始参数.Lample等[6]提出一种无监督方法来训练机器翻译模型,在一个初始的翻译模型上利用大规模单语语料实现伪平行语料的扩充,并从扩充后的语料中学习语义的表达和模型的构建.然而伪语料中的数据没有对应标签的正确性指导,导致伪语料包含大量噪声,制约着模型的优化.为了缓解上述问题,He等[7]提出一种新的学习范式,即对偶学习(dual-learning,DL).这种方法利用人工智能任务的对称属性使其获得更有效的反馈或正则化,从而引导和加强在数据量较少情况下的模型学习过程.机器翻译中,DL可以有效地利用源语言或目标语言的单语数据进行学习.通过使用该学习机制,单语数据可起到与平行双语数据相似的作用,使得在模型训练过程中可以显著降低对平行双语数据的要求.
本文采用DL方法结合强化学习方法,在蒙古语-汉语(蒙汉)双语语料资源稀缺的前提下,通过回译方法扩充语料,并对蒙汉NMT建模,实现源语-目标语和目标语-源语两个方向的翻译模型.为了评测译文的质量,使用大规模单语语料构建语言模型来计算模型的置信度奖励以及生成译文的语言模型得分,通过设定奖励阈值来控制模型的收敛,生成最终模型.此外,本文提出一种知识精炼方法训练模型,以缓解通过回译方法得到的大规模伪双语语料中大量“有害”噪声带来的翻译性能下降的问题.为了验证本文方法的有效性,首先通过对蒙古语和汉语的不同预处理操作进行对比实验,采用最优的预处理方法参与模型的训练,之后采用消融学习的方法对本文方法的各个组件进行验证,最后分析了句子长度对翻译质量的影响.
1 模型的构建与训练
图1是本文模型的整体框架示意图.首先采用回译技术对语料扩充,生成大规模伪语料;然后在DL基础上使用大规模单语语料得到目标端语言模型;最后结合奖励机制对译文的流利度和相似度打分,通过最大化总奖励来优化模型.此外,由于扩充双语语料存在大量的噪声,提出一种基于迭代知识精炼的方法来降低“有害”噪声.下面主要介绍回译技术、DL方法以及训练方式等.

r1、r2和rfinal分别为语言模型的流利度奖励、翻译模型的对偶置信度奖励和整体反馈奖励.图1 整体模型框架示意图Fig.1 Illustration of the overall model architecture
1.1 迭代回译
由于蒙汉双语平行语料稀缺,单纯利用双语训练势必会因语义稀疏导致过拟合.传统方法是在训练中采用早停或正则化等方法缓解过拟合问题,但是这两种方法也无法很好拟合目标分布.为此,本文在低资源双语语料的基础上引入回译方法生成大规模伪双语语料,将生成的伪语料和已有的双语语料合成总语料,一起进行接下来的模型训练.
在低资源翻译任务中,回译是利用单语数据提高机器翻译质量的有效方法.具体来说,首先利用已有的双语语料训练一个初始的Tramsformer翻译模型,再用该Transformer模型将大规模的源端单语翻译成目标端的带噪单语(x→Ms→t(x)→y*),同时将带噪目标语言翻译回含有噪声的源端单语(y*→Mt→s(y)→x*),以此类推.
1.2 DL
DL最主要的目的就是根据语言模型的反馈信息来指导翻译模型的参数优化,因此本小节主要介绍所涉及的语言模型奖励和翻译模型奖励如何设定.具体过程如图2所示,首先通过语言模型ELMo(embedding from language model)给两个翻译方向上的NMT模型提供流利度奖励反馈,然后通过提出的DL算法在训练中基于反馈回来的奖励来提升两个翻译模型的性能.
1.2.1 语言模型的奖励
利用语言模型提供流利度奖励的反馈.具体地,先采用单语语料蒙古语语料DMO和汉语语料DZH训练一个蒙古语和一个汉语语言模型,这两个语料分别包含蒙古语句子和汉语句子并且不需要相互对齐.然后分别通过已经训练好的两个语言模型计算蒙古语或汉语目标端句子的流利度的奖励r1:
(1)
其中,P为概率,T为目标端句子,ti为目标端句子的第i个词.
1.2.2 翻译模型的奖励
DL翻译任务包含前向翻译步骤和反向翻译步骤,即可以将句子从蒙古语翻译到汉语,反之亦然.由迭代知识精炼方法训练得到两个初始NMT模型(本文中为基线Transformer或基线RNNSearch),接着采用真实的蒙汉双语语料进行DL.假设真实双语语料中蒙古语语料WMO有NA个句子,汉语语料WZH有NB个句子,两种语料需要对齐.定义P(·|S,θMO-ZH)和P(·|S,θZH-MO)是两个NMT模型对句子S的翻译概率,其中,θMO-ZH和θZH-MO是对应方向上的模型参数.如图2所示,DL过程从WMO或WZH中的句子S开始,定义T作为中间翻译输出,再通过翻译模型将中间翻译T还原回S,将S的对数似然概率作为对偶置信度的奖励r2:
(2)
通过简单的线性组合将由语言模型产生的流利度奖励r1和由翻译模型产生的对偶置信度奖励r2组合作为整体反馈奖励,公式如下:
rfinal=λr1+(1-λ)r2.
(3)
其中λ是超参数.

BOS和EOS分别表示初始状态和终止状态.图2 DL过程(自下而上,从左至右)Fig.2 DL procedure (bottom to top,left to right)
1.3 训 练
本文通过将DL作为蒙汉NMT的主要训练方法来改进翻译模型.为获得初始翻译模型,利用1.1节中的回译技术生成的伪语料和双语语料,一起训练双向机器翻译基准模型.但由于伪数据的质量问题,单纯的联合训练会带来大量的噪声,为精炼模型的训练数据,本文采用迭代知识精炼方法逐步细化模型性能.在每一个训练周期结束时增加一定比例的真实语料并且降低一定比例的伪数据来逐步细化基准翻译模型,直到伪双语语料为0.这样在扩充语料使模型学习到更多语言特征的同时,还减少了由于伪数据的质量问题带来的噪声.
由于整体反馈奖励可以视为S、T、P(·|S,θMO-ZH)和P(·|S,θZH-MO)的函数.因此,本文通过策略梯度方法来优化翻译模型中的参数,从而达到奖励的最大化.在该训练方法中,首先基于P(·|S,θZH-MO)采样出T,接着计算期望奖励E[r]关于参数θMO-ZH和θZH-MO的梯度.根据策略梯度定理得到两个方向上的训练梯度,具体如下:
∇θMO-ZHE[r]=
E[rfinal∇θMO-ZHlogP(T|S;θMO-ZH)],
∇θZH-MOE[r]=
E[(1-λ)∇θZH-MOlogP(S|T;θZH-MO)].
(4)
模型更新:
(5)
考虑到随机采样将会带来非常大的方差,并且会导致机器翻译中出现不合理的结果,本文针对梯度计算,使用束搜索方法来获取更加合理的中间翻译输出,通过贪婪方法产生前K个高概率的中间翻译输出,然后使用束搜索的平均值来近似真实的梯度.
2 实验与分析
2.1 数据集和设置
本文实验数据共计约310万语料(蒙古语和汉语各155万),其中采用内蒙古自治区蒙古文智能信息处理重点实验室提供的各130万蒙汉单语语料来训练两个语言模型,采用第15届全国机器翻译大会(CCMT 2019)提供的近25万的双语平行语料用于翻译模型的训练.CWMT2017dev作为验证集,CWMT2017test作为测试集.为降低模型困惑度,上述数据均删除了长度大于50的句子.本文中采用传统的RNNSearch[1]和最新的Transformer[8]模型作为基线系统.Transformer设置与文献[8]完全相同.失活率(dropout)为0.1,词嵌入维数为512,头数设置为8.编码器和解码器均具有6层堆栈.使用通过平均最近20个检查点获得的单个模型,利用束搜索方法来对目标标记(token)进行采样,其中束大小为4且长度损失α= 0.6.使用Adam算法优化,γ1,t=0.000 2并且γ2,t=0.02,超参数λ=0.005.本文中RNNSearch的编码器-解码器的隐藏层节点和词向量维度均设为512,设置dropout为0,学习率和检查点的设置和Transformer保持一致.考虑到实验的硬环境和模型复杂度,用来构建和训练语言模型的ELMo[9]含2层512个长短时记忆单元,词嵌入维度设置为512.本文以句子级双语互译评估(BLEU)指标[10]作为评测标准.所有模型均在TensorFlow中实现,实验采用单核NVIDIA TITAN X显卡进行训练.当模型对开发集的评估没有任何改善时将停止训练.
2.2 语料预处理结果
本文首先在基线系统上对蒙古语和汉语分别进行不同的预处理操作实验,选取最优的预处理方法训练DL NMT模型.在汉语端分别进行分字、分词、字节对编码(BPE)[3]处理.在蒙古语端,由于蒙古语本身自带天然分隔符,因此单纯采用BPE处理.不同切分方法对翻译性能的影响如表1所示.
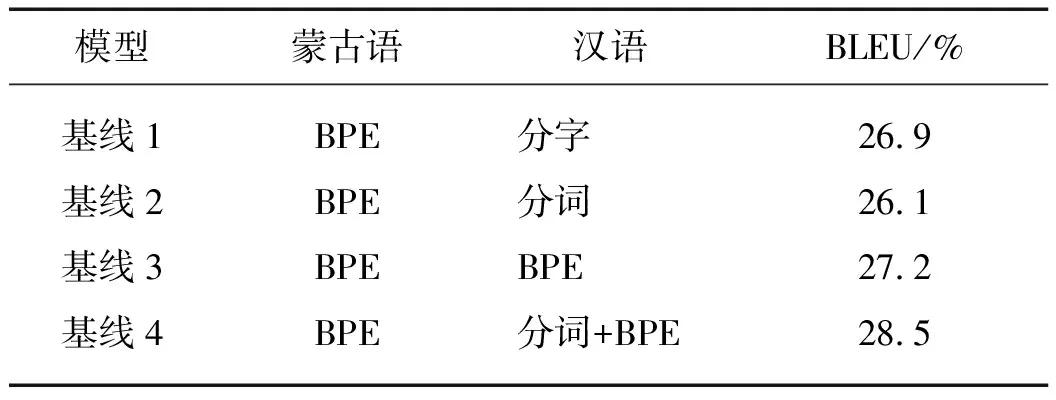
表1 不同预处理方法的BLEU值Tab.1 BLEU values for different pre-processing methods
由表1可知,对蒙古语进行BPE处理,对汉语进行分词+BPE处理时,翻译效果最佳.通过分析发现将汉语分词会产生数据稀疏的问题,影响翻译模型的性能,而分字的形式会导致语料无法保留汉语词所能包含的语义信息.在接下来的实验中,本文均采用基线4的方法对语料进行预处理.
2.3 主要结果和分析
为了验证本文提出的不同组件的有效性,在基线模型RNNSearch和Transformer上做了一系列实验,结果如表2所示.在Transformer上使用回译技术扩充双语语料后在蒙汉翻译的BLEU值相较于未扩充语料提升了0.4个百分点,达到33.8%,在汉蒙翻译的BLEU值提升0.3个百分点,在RNNSearch也显示了同样的趋势,说明在低资源翻译任务上使用数据增强方法扩充语料可以提升翻译质量.DL在本文方法中扮演重要的角色,相较于在传统的RNNSearch,DL使蒙汉翻译的BLEU值提升了1.7个百分点,将DL应用于Transformer提升更多,达2.2个百分点.相较于监督学习需要大规模双语语料的局限性,DL这种半监督学习范式打破了数据稀少的问题;同时相较于无监督学习完全没有对应标签指导的缺陷,DL利用少量双语平行语料来训练翻译模型可以为模型提供正确性指导,以此提升翻译质量.此外,两种模型进一步采用迭代知识精炼方法在蒙汉上分别提升1.0和1.2个百分点,在同时采用回译DL和迭代知识精炼后也分别较基线系统提升2.7和3.4个百分点,分别达到31.2%和36.8%.实验结果表明:如果单纯的扩充语料而不考虑伪数据的噪声问题,虽然也可以提升模型性能,但是效果不明显;采用迭代知识精炼方法精炼模型,减少噪声对模型的影响可以显著提升模型性能.本实验进行了几次典型实验后选取每轮迭代增加0.1%的真实双语语料同时降低0.1%的伪语料来训练模型.

表2 不同模型翻译结果Tab.2 Translation results of different models
2.4 句长影响
为了验证本文方法在长句上的表现,依照Bahadanau等[1]的做法将蒙汉任务的开发集数据和测试集数据按照句子长度进行划分.图3展示了不同的句子长度的BLEU值:当句子长度在10~20时,在Transformer上的BLEU值最高达到38.7%;随着句子长度的进一步扩大,模型的质量则有一定下降,但总体维持在35%左右;在RNNSearch上也表现了同样的趋势.通过上述实验可以看出,利用DL进行训练的Dual-NMT模型无论在翻译性能上还是在不同长度句子的翻译质量上,相比传统的NMT模型都有所提高.上述结果表明,在少资源语料生成的弱翻译器存在先天翻译性能低的条件下,通过大规模单语语料的训练支持能够进一步提升模型的翻译质量.

图3 不同长度的句子的BLEU值Fig.3 BLEU values over different lengths of sentences
3 结 论
本文针对蒙汉双语语料稀缺导致模型过拟合问题,采用一种半监督DL方法对蒙汉神经翻译建模.通过反馈流利度奖励和对偶置信度奖励来不断地优化模型性能.此外,本文还采用回译方法生成大量伪双语语料,一起参与到模型训练中,为减少伪语料中大量有害噪声,提出迭代衰减方法精炼模型.虽然模型能够在一定程度上提高翻译质量,但是依然存在一些未登录、错译和漏译等现象.因此未来的任务可以考虑从模型的重构、弱翻译器的结构、训练参数的优化以及语言模型的结构优化几个方面着手改进蒙汉NMT的翻译性能.充分实现两端语料语义特征的学习和表示,同时在词向量的处理上进一步考虑语言的自身特性和词性特点,以达到预期的翻译效果.
