基于机器学习的深基坑三维土层重建
2021-06-21王朱贺张希瑞
王朱贺,李 楠,张希瑞,苏 想
(1. 北京工商大学 人工智能学院,北京 100048;2. 智慧互通科技有限公司河北省静态交通技术创新中心 河北 张家口 076250)
根据实地采集的有限土层样本数据,利用计算机图形学相关算法,将地下不同土层的空间三维结构进行预测还原并进行实体建模的过程称之为土层三维重建。土层三维重建对地下施工过程的管理具有十分重要的意义。以深基坑挖掘工程为例,技术人员需要通过一系列工程数据来对施工过程中可能存在的风险进行预警。这些数据包括基坑区域内的土层信息、基坑支护结构信息、基坑施工过程中的各类传感器监测信息等。对支护结构的失效预警需要进行相关的数值计算才能完成[1-2]。其中,土层的三维分布信息十分重要,因为需要根据土层实际情况计算土压力,作为支护结构计算的输入载荷,进而得到预警信息。
传统土层建模方法有很多种,如基于边界、高度的三维土层建模[3],基于钻孔信息[4]的插值土层生成等[5]。目前较为常用的插值方法是克里金插值[6],如文献[7]设计了一种三维克里金算法,能较好的反映地质空间的各向异性特征。另外,反距离加权平均插值法同样在三维土层重建中有重要作用,文献[8]对反距离权重插值法和自然邻域插值法展开对比研究,得出反距离权重插值法更加适用于地层缺失严重的层位,能够更好地保留地层缺失的特征的结论。
随着大数据技术的发展和计算机算力的提高,机器学习技术已经被证实在图像[9]和音频[10]领域有着显著的效果。在三维地质建模中,机器学习也有了初步应用,文献[11]从机器学习的角度提出矢量势场解决方案,用隐式建模方法构造地质模型,文献[12]提出GSIS系统进行多参数地质建模,并以北京顺义区工程地质模型和中心城区的地质模型为例进行验证。文献[13]利用支持向量机结合钻孔数据、表面地质图、地质剖面数据等进行土层自动化重建。文献[14]基于堆栈的方法来表示地质表面和地下结构,解决了体数据模型存储数据量大的问题。
总体来说,传统的插值算法虽然在简单、连续的土层上基本能够实现土层重建,但在复杂地形(比如断层、下沉、尖灭)上的表现不佳。另外插值算法受到选取钻孔数目和位置的影响,建模的不确定性大,适用范围比较局限。目前对基于机器学习方法进行土层重建的相关研究还较为初步,且需克服下述问题:1)足量训练数据获取;2)有效特征数据编码;3)高适应性和鲁棒性学习模型。
针对上述问题,设计一种基于机器学习的三维土层重建方法,总体技术路线图如图1所示。其中分为4个主要技术环节,分别为
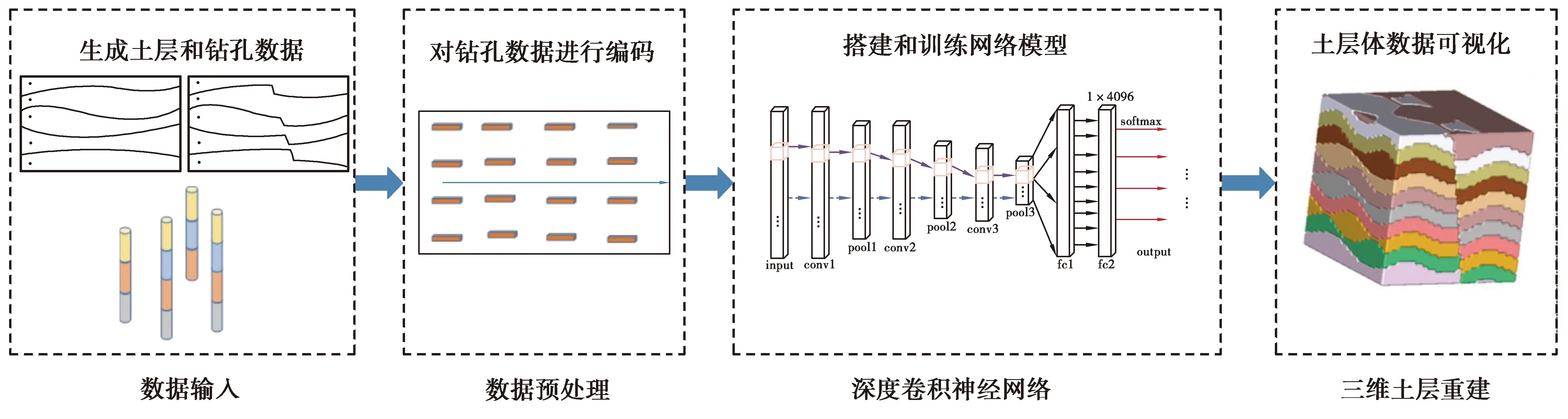
图1 总技术路线图
1)土层样本数据增强算法。针对钻孔数据和土层样本的稀缺,进行了土层和钻孔数据增强算法的设计,以获得足量训练样本数据集;
2)钻孔数据预处理。设计了编码算法,将维度不统一的钻孔数据编码为形式一致的特征图,作为网络模型的输入;
3)设计并搭建卷积神经网络模型,进行土层预测训练;
4)土层体数据可视化。根据模型输出的土层标签提取数据场中等值面,将等值面以内体数据进行聚块,生成土层模型。
1 基于土层生成算法的钻孔数据建模
1.1 钻孔数据建模
钻孔是为了获得地下土层分布情况而向地下打的孔洞,在工程应用中,获取地下三维土层信息的方法,一般采用工程钻探法,系统为了进行土层重建设计了文件存储钻孔数据。
如图2所示,钻孔随机分布在地层中,经过若干土层,一个钻孔的三维结构图中,包括钻孔的高程值、平面坐标、所经过的土层及该土层厚度。钻孔文件中包含土层信息,土层信息有土层标签、土层名称、土层颜色和土层描述。钻孔数据包含:钻孔名称、钻孔高程值、钻孔半径、钻孔经过的土层及土层厚度、钻孔坐标。其中钻孔经过的土层及土层厚度是以列表的形式存储,一个列表中存储一个土层标签和相应的厚度,由于土层存在缺失和断层情况,列表的长度并不是固定的,而是根据土层的情况而定,钻孔经过土层标签与土层数据相关联,每种土层有不同的颜色,以此实现钻孔的可视化。
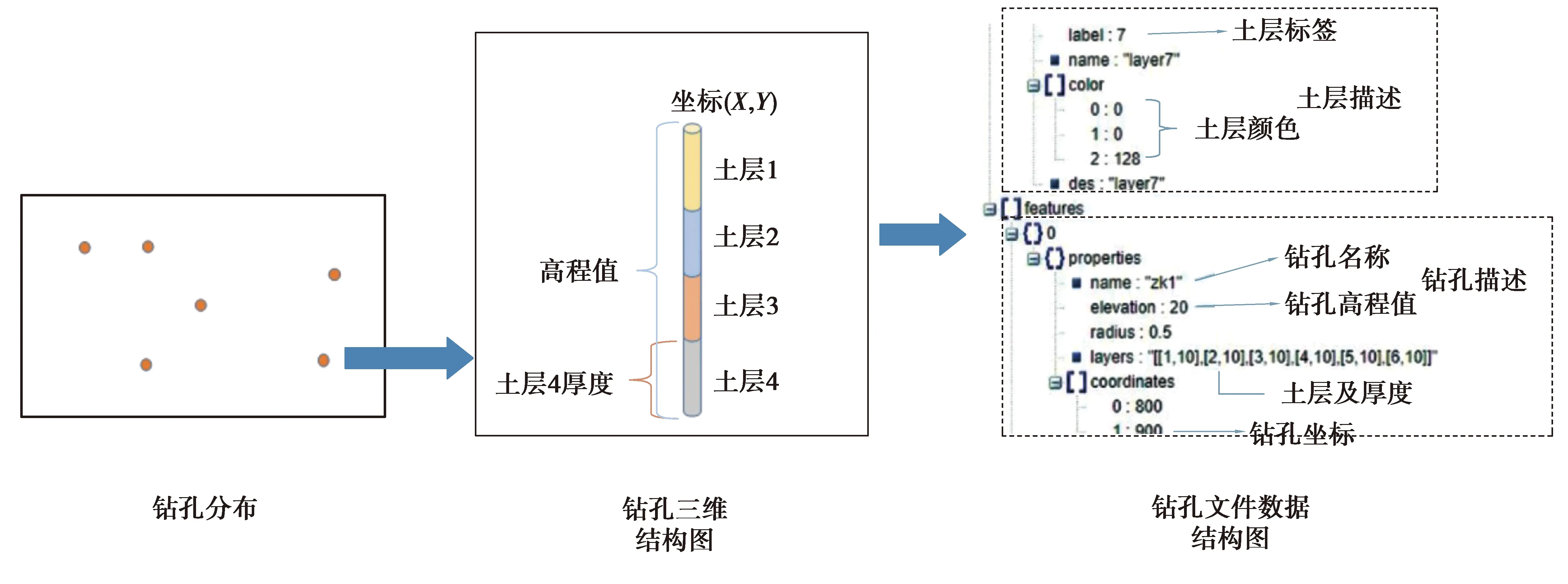
图2 钻孔数据建模示意图
在钻孔文件中,除了图中所示的信息,还包含文件类型、文件生成时间、数据类型等一系列辅助信息。
1.2 土层生成算法
本算法的目的在于模仿实际施工低质环境中典型的土层结构生成仿真数据,增强土层训练数据集的规模。
在实际中很难得知真实土层的分布情况,对土层数据的获得一般是通过少量钻孔数据建模,但由于钻孔数据的稀缺,土层数据也相对较少,因此设计了土层生成算法,模拟地球上真实土层的形成过程,获得三种主要的土层类型数据,分别是连续土层、含缺失土层、含断层土层。
连续土层,土层分布连续,中间没有出现土层缺失和断裂的情况;含缺失土层,由于地壳的运动,在地质中某一层或某几层土出现缺失情况,一般呈倒三角状,其余土层仍呈现连续状态;含断层土层,地壳的部分下沉很容造成这种土层的形成,土层在某个位置具有显著位移的断裂。在连续土层中,2种土壤的交界面也很少出现平面,往往以曲面的形式出现,含缺失土层和含断层土层也都是在连续土层的基础上,经过地质作用形成。
在土层生成算法中,核心是用平滑曲线代替网格直线,获得土层之间的交界面,在交界面之间的网格点被归类为同一种土层,缺失土层是将连续土层的体数据删除一部分,形成“下沉”,断层土层是将连续土层的一部分体数据高度坐标减去一个固定的值,形成一个“断面”,其余部分仍保持连续土层的状态,算法流程图如图3所示。

图3 土层生成算法流程图
土层生成算法主要分为三步:
1)从设计的B样条曲线中,随机选取曲线函数,用曲线代替网格直线,获得相应网格点新的高度坐标,将第一次选取的曲线沿Y轴平移一个网格,获得此位置的体数据,继续平移,直到生成一个曲面。
2)重复步骤1,直到所有的交界曲面全部生成,提取曲面之间包围的体数据进行保存。
3)判断生成什么类型的土层,如果是连续土层,算法结束,如果是缺失土层或断层土层,输入相应的坐标进行缺失或断层处理并保存体数据。
土层体数据为交界曲面之间包围的网格点,以网格点坐标的形式存储。根据土层生成算法生成三种类型的土层,每一种土层都包含该层的所有土层数据,能够实现数据形式化、随机性,确定性,形式化体现在每种土层数据格式都是统一的,随机性体现在每个交界曲面都是随机生成,进而每层土层的形状也是随机的,确定性体现在空间每一个网格点只属于某一种土层。通过模拟地质土层的真实形式,生成的土层数据与真实土层很相似,可以在土层数据上进行后续的实验。
1.3 钻孔生成算法
在土层数据的基础上,进行了钻孔生成算法的设计,在土层的最上层网格点上随机选择钻孔,先确定钻孔的位置,为了便于计算,钻孔的位置都选在了网格点上,在土层的基础上随机生成若干钻孔,通过层之间的交界面坐标计算每层土层在钻孔位置的厚度,计算公式
thinknessi=zi-zi+1,
(1)
其中:thinknessi为土层i在钻孔位置的厚度;zi为钻孔在交界面i所经过的网格点高度坐标值;zi+1为钻孔在交界面i+1所经过的网格点高度坐标值。
钻孔生成算法流程图如图4所示,在土层生成算法中,已经生成了具有一定格式的土层数据,三维网格的划分已经完成,根据土层分界面的网格坐标得到土层的厚度,其中钻孔的高程值直接来自土层的表面网格高度坐标。
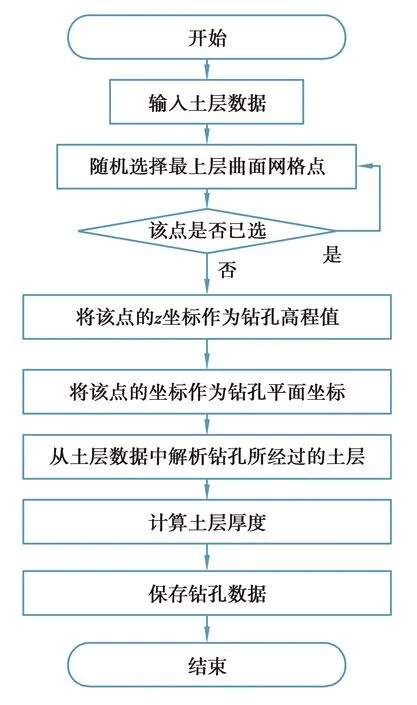
图4 钻孔生成算法流程图
钻孔生成算法分为三步:
1)选择网格点坐标,钻孔的位置全部取在了网格点上,每次取点不可重复。
2)求钻孔的高程值和平面坐标,钻孔高程值为网格点的高度坐标,将选取的网格点的平面坐标作为钻孔坐标。
3)从土层数据中解析钻孔所经过的土层,提取土层的标签,通过公式(1)计算土层的厚度,并保存钻孔数据。
通过钻孔生成算法获得若干个钻孔,每个钻孔都包含4组信息:高程值、坐标、经过的土层和土层厚度。在地层块空间中,包含许多生成的虚拟钻孔,每个钻孔的信息形式都一样,这些钻孔数据是表征土层属性的主要信息,后续的特征提取和数据集制作都是基于钻孔数据来完成的。
2 基于卷积神经网络的土层生成模型
2.1 钻孔特征信息编码
通过土层生成算法和钻孔生成算法能够得到大量的土层和钻孔数据,但是这些信息无法直接作为土层的特征来训练网络,要想进行三维土层重建,需要知道所需建模的土层块中每一体素的属性。对土层进行三维网格划分,把网格点作为样本点,由于土层生成算法的确定性,样本所属土层类别是唯一的,样本的标签也就确定了,接下来需要一些数据来描述这个样本,因此设计了编码方法,将钻孔数据与样本点联系起来,获取样本特征。
具体的编码算法步骤如下:
1)钻孔维度统一。将所有的钻孔维度都统一到一个标准值,由于土层存在缺失和断层的情况,在缺失层选取钻孔的时候,可能会出现钻孔并没有完全经过所有土层的情况,进行钻孔维度统一是为了样本特征维度的统一,否则无法输入神经网络模型。对缺失数据的钻孔进行补零操作,即在钻孔数据的缺失层位置,将土层厚度置为0。
2)计算土层中心点高度。有了土层的厚度之后,还需要土层的空间分布信息,因此用土层中心点坐标来描述这个物理量,钻孔的平面坐标就是土层在钻孔位置的平面坐标,还需要土层中心点的高度数据,土层的厚度是由土层的交界面坐标之差得到的,因此土层中心点高度坐标值由公式(2)得到
(2)
其中:hi是第i层土层的厚度;Zsi是第i层土层在一个钻孔位置处的厚度中心点高度坐标。
3)计算土层中心点到样本点距离。因为距离样本点越远,对样本点的影响越小,选择了k个距离样本点最近的钻孔,然后获得这些钻孔所经过土层的厚度中心坐标,根据欧式距离公式得到所有土层中心点到样本点的距离。
经过3个步骤,生成一个样本的所有特征数据,包含若干个钻孔的信息,每一个钻孔的信息包含5组数据:该钻孔高程值、该钻孔所经过的土层厚度、钻孔平面坐标、每层土层中心点的z坐标、每层土层中心点到样本点的距离。样本的维度由土层种类数目snum和选取的钻孔个数k决定,计算公式
Ds=3(snum+3)k,
(3)
其中:snum是土层数目;k是选取的钻孔个数;Ds为一个样本的维度。
下面以土层数目为3(即snum=3)选取的钻孔个数为2(即k=2)为例,如图5所示,展示编码前的钻孔数据以及编码后的样本特征数据。
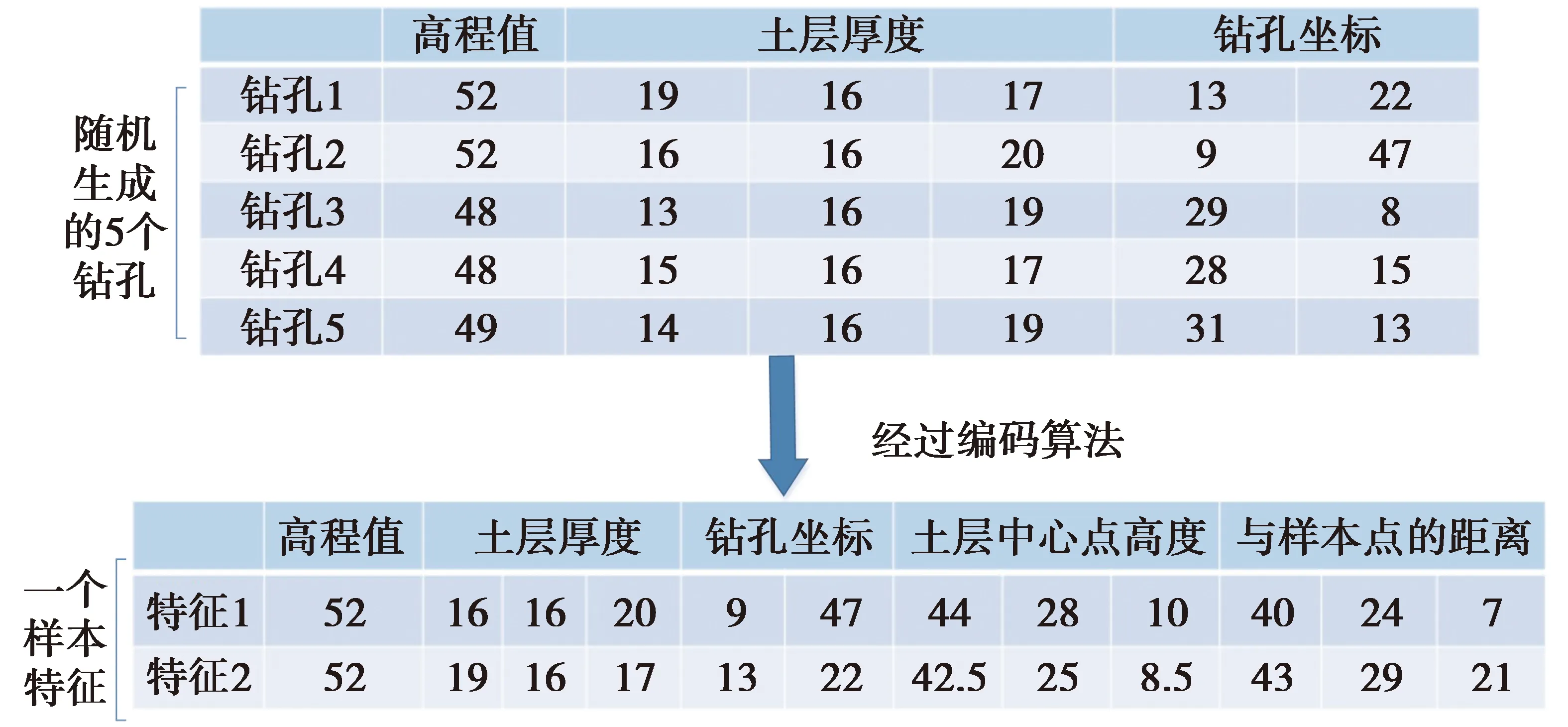
图5 编码算法得到的特征数据
在图5中,上方的表格是随机生成的5个钻孔,其中忽略了钻孔所经过的土层标签这一信息,因为在编码算法中,土层的厚度是按所经过的层依次排列的,将土层标签这一信息转化成了样本空间信息,因此样本特征是跟数据的空间位置有关系。图中下方表格是一个样本的特征数据,其中特征1是由钻孔2编码而来,特征2是由钻孔1编码而来,根据公式(3)得其样本维度为24,即该样本有24个特征数据。
2.2 预测模型的结构
卷积神经网络在计算机视觉等领域表现出了优越的性能[15],在语音和自然语言处理等领域也广泛的应用[16-17],深层卷积在高维度数据的特征提取方面具有显著优势,采用深度卷积神经网络作为基本重建模型结构。
模型的具体结构包含3个卷积层,3个池化层,2个全连接层,最后用Softmax函数输出预测结果。模型可以选择设置用于确定网络架构的超参数,其中激活函数适用了RELU,池化方法采用最大池化。根据不同的土层类别设计了多种模型,以此来适应用户的需求,其中卷积核大小和池化窗口的大小都是动态的,根据土层的类别数和钻孔个数而定。
由于在基坑施工的典型低质环境中,几乎没有超过10种土层的情况,因此以10层为上限设计模型,通过训练多种分辨率的模型,来提升土层预测的效率。研究主要设计训练了2种模型,土层数目分别对应为5和10,将其命名为SNet5和SNet10。如果钻孔采样中土层的类别小于或等于5,则采用SNet5进行土层预测,当土层数目大于5则采用SNet10。
2.3 数据集的构建及训练
分别设计了2种数据集,来训练SNet5和SNet10,并将经过编码算法的钻孔数据作为样本的特征数据。针对不同的地形,制作了不同的数据集,每种数据集的样本量和样本维度都不同,为了确保能在所有土层中都能取到样本,在每个土层中都随机取了若干点。制作了2个数据集,如表1,分别对应模型SNet5和SNet10,数据集的样本量分别是30 000和60 000,如表所示。这些数据集将应用到下面的一些对比分析实验当中,每种数据集训练集占70%,测试集占30%。

表1 数据集样本量和样本维度
在训练时,从数据的输入到数据处理,到三层卷积层的特征提取,最后通过交叉熵函数得到Loss值,Loss值越小且收敛,则神经网络模型收敛且准确度越高。网络模型优化器使用的是Adam优化器,为防止网络过拟合,在每个池化层之后,增加dropout函数,随机减少神经元。对真实值和预测值做交叉熵运算,得到误差,不断地更新权重和偏置参数,使损失值不断减小,模型的性能逐渐提高,迭代次数20 000次,模型在测试集上的表现精度如表2所示。
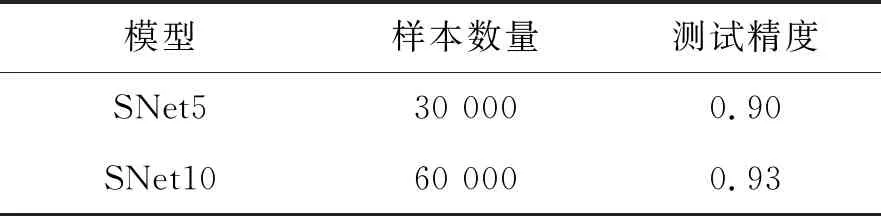
表2 模型在数据集上的测试精度
2.4 土层体数据可视化
网络模型返回的标签是体素的顶点数值,每一块体素代表一个土层结构离散单元。对土层数据可视化的过程可概括为:1)土层结果体数据生成;2)体数据等值面生成;3)等值面围成区域生成土层实体块。其中生成等值面采用Marching Cubes算法,Marching Cubes是三维离散数据场中提取等值面的经典算法,算法主要的思想是将体素的每个顶点进行标记并根据不同的顶点状态组合进行分类 , 如果体素顶点上的值大于或等于该等值面的值,则定义该顶点位于等值面之外,标记为“0”;而如果体素顶点上的值小于该等值面的值,则定义该顶点位于等值面之内,标记为“1”,然后通过线性插值求得立方体各条边上的等值点, 最后用一系列的三角形拟合出该立方体中的等值面[18]。
将训练好的模型进行保存,在对未知土层进行建模的时候,根据用户提供的少量钻孔,对待建模的土块进行三维分网格,通过模型来预测每一个网格点的标签,将钻孔数据进行编码,生成特征图,输入到网络模型中,模型返回样本标签,即体素的顶点数值,然后进行土层体数据可视化,具体流程示意图如图6所示,其中等值面提取方法采用文献[19]中Marching Cubes算法。
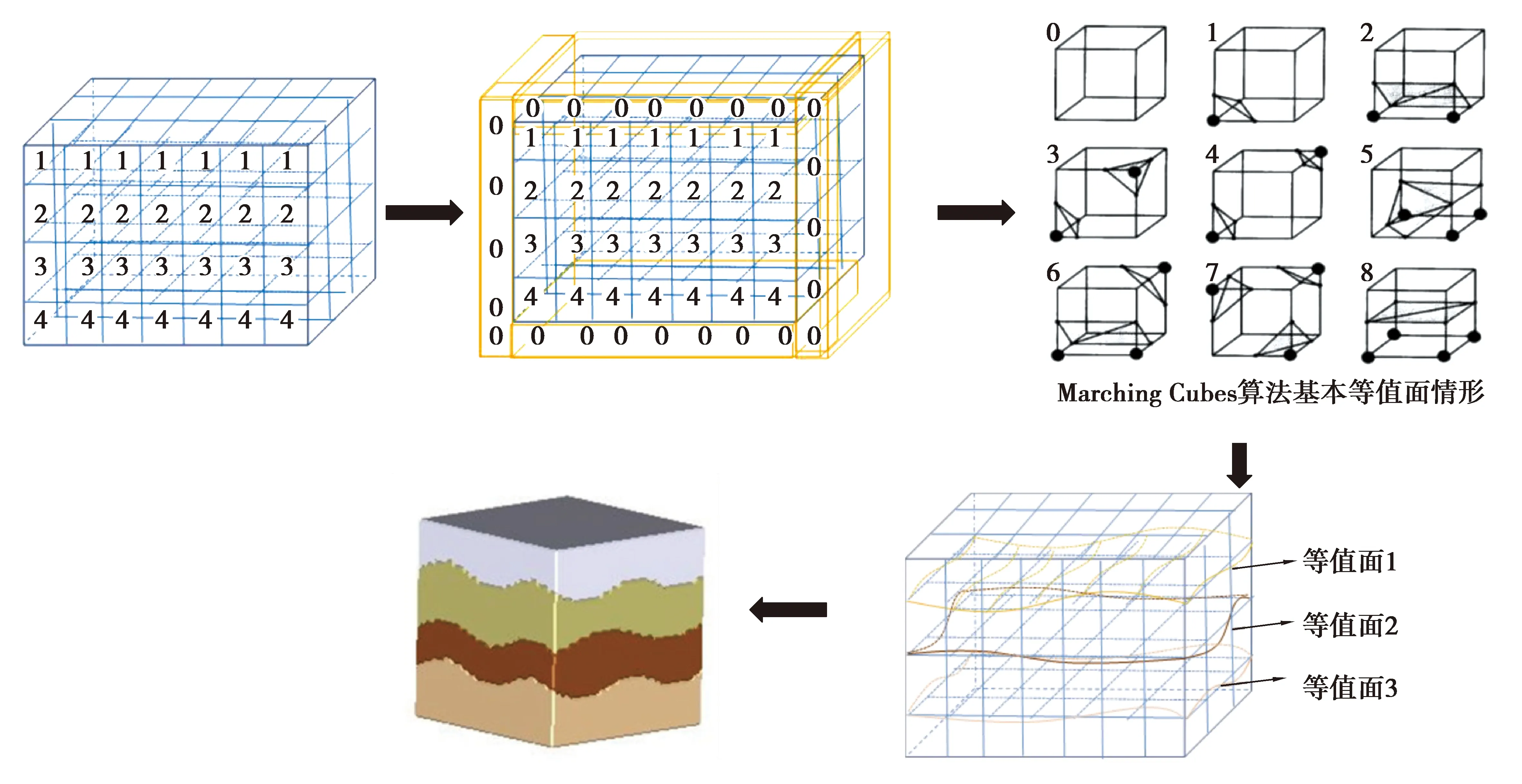
图6 土层数据可视化示意图
土层体数据可视化的过程为:1)将土层结果数据进行预处理,用连续自然数表示不同土层,作为算法输入;2)在土层块周围增添一层值为0的界面层,保证最后生成的等值面封闭;3)根据Marching Cubes算法生成若干等值面;4)将等值面转换为土块三维模型进行可视化。图7是经过模型后所得到的土层体数据绘制的三维土层模型。
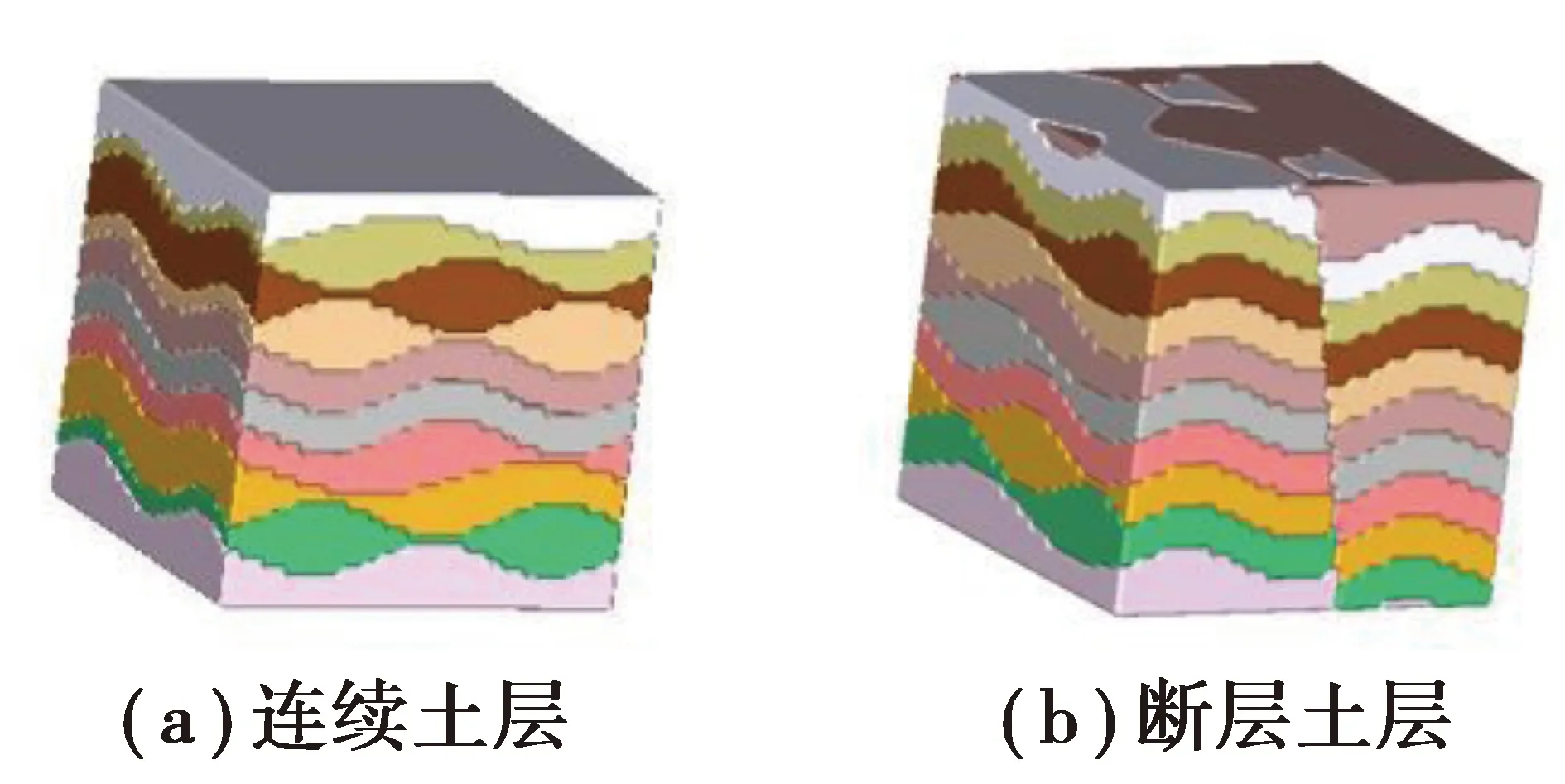
图7 土层模型
3 土层生成实验与结果分析
3.1 钻孔选取数目对结果的影响
设计土层生成算法的过程中,在生成的土层块上随机获取若干钻孔,选择多少个钻孔数据作为一个样本的参考数据会影响到模型的优劣,因为样本维度发生了变化,样本数据也发生了变化。因此,设计一组实验,来寻找最佳钻孔数,根据经验数据分别选取一系列数目的钻孔,网络模型选择SNet5和SNet10,这些钻孔都是距离样本点最近的钻孔,将这些钻孔数据按照前述编码方法进行编码,通过神经网络,分别得到相应的测试集准确率,实验结果如表3。由该表得到的折线图如图8所示。

表3 钻孔选择数目对结果的影响
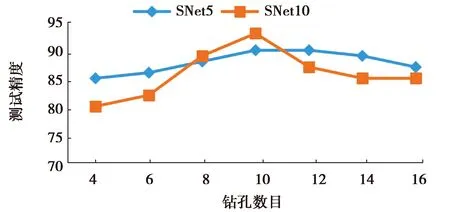
图8 钻孔选择数目对结果的影响
由图8可以看出钻孔数目的选择与模型优劣的关系,当钻孔数目为10时,2个模型都达到了最好的效果,在测试集上的准确率分别为90%和93%。随着钻孔数目的改变,一个样本的维度就发生了变化,对网络模型提取样本特征的能力产生了影响,从而模型的性能也发生了变化。
3.2 钻孔选取方法对结果的影响
在设计编码算法时,加入了权重因子,因为距离样本点越近的钻孔对样本的影响越大,但由于神经网络模型可能具备学习距离特征的能力,这种距离因素是否会影响到样本特征,还需要进一步验证。因此设计了一组实验,选取若干个距离样本点最近的钻孔和随机选取若干个钻孔做对比,网络模型选择SNet5和SNet10,得出模型的准确率分别如表4、5。由以下2表得到的柱状图如图9、10所示。

表4 在模型SNet5上钻孔选取方法对结果的影响

表5 在模型SNet10上钻孔选取方法对结果的影响
在图9、10中,对随机选择钻孔和选择样本点最近的钻孔对模型性能的影响做了对比,可以看出在网络模型SNet5和SNet10上,两种方法都表现出了较好的性能,但是选择离样本点近的钻孔在模型上的表现要更好一些,原因是因为距离样本点较近的钻孔对样本的影响较大,这些近距离的钻孔所携带的信息更能表示一个样本的特征。

图9 在模型SNet5上钻孔选取方法对结果的影响

图10 在模型SNet10上钻孔选取方法对结果的影响
3.3 土层重建实例
针对深圳某深基坑施工项目,运用设计的模型进行三维土层重建。施工单位提供的真实钻孔数据一共80组,部分钻孔三维结构如图11左图,根据钻孔数据判断出此地块一共有7层土层,于是训练一个重建7层土层的模型,用训练好的7分类模型来进行土层重建,得到如图11右图所示的土层模型,具体实的现步骤如下
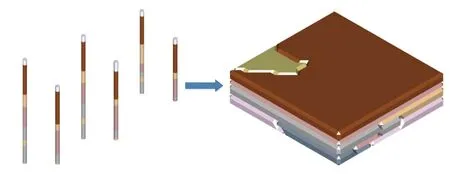
图11 钻孔三维结构与土层模型
1)根据施工要求所需建模的地块大小为(260×250×7),将其分为26×25×7=4 550个体素,每个体素为(10×10×10)的三维网格;
2)将施工单位提供的80组钻孔数据输入编码算法,将网格点做为样本点,获得5 616(27×26×8=5 616)张特征图;
3)将特征图输入到训练好的模型中,得到5 616个土层标签;
4)将土层标签经过数据预处理之后作为Marching Cubes算法的输入数据,提取等值面,进而生成土层模型。
4 结 语
提出了基于机器学习的深基坑三维土层重建方法,在复杂地层上有较好的表现,具体结论如下:
1)提出的数据增强算法能获得大量与真实钻孔数据高度相似的虚拟钻孔数据,有效扩大了训练集规模。
2)针对钻孔数据提出的特征编码算法,能够生成钻孔信息特征图,作为预测模型的有效输入。
3)利用设计的土层预测模型,在简单土层的测试集上精度达到93%,在复杂土层的测试集精度也均达90%以上。
4)设计的土层体数据等值面生成算法,实现了土层块的可视化建模。
未来将主要在现有基础上进行数据增强算法的研究,使数据更加完善、丰富,算法的适应性更强,形成一套更加成熟的土层、钻孔数据自动生成的体系。
