基于区块自适应特征融合的图像实时语义分割
2021-06-20黄庭鸿聂卓赟王庆国晏来成郭东生
黄庭鸿 聂卓赟 王庆国 李 帅 晏来成 郭东生
图像语义分割(Semantic segmentation)是一种重要的智能感知方法,在无人驾驶、医疗图像识别等方面有重要的应用价值.图像语义分割是将图像中不同物体的像素区域分开,并对每一块区域的类别进行标注.
针对这类问题,早期以常规图像处理方法为主[1-2],即通过阈值优化、分水岭算法等常规方法进行图像区域分割,再结合几何形状、纹理等特征对区域进行分类标注.随着统计学和智能化方法的应用,概率图模型[3]、机器学习[4]等方法逐渐用于图像语义识别.这类方法适用于特定场景的识别分类,例如:车牌识别、细胞分割等,但应用场景较为简单,难以适用于复杂场景.近些年,深度卷积神经网络(Convolutional neural networks,CNN)[5]逐渐在图像语义分割中得到应用,大幅度提升语义分割算法的准确性和普适性.因此,基于深度学习的语义分割方法受到国内外学者的广泛关注.最初,Long等[6]针对CNN 中输出维度下降的问题,采用转置卷积[7]、双线性插值(Bilinear interpolation)[8]方法扩大CNN 网络的输出维度,实现了图像的像素级分类.进一步,文献[9-11] 在此基础上引入轻量卷积神经网络,提出了一种快速语义分割模型,大幅度降低全卷积网络的运算量,实现了在嵌入式设备上进行实时语义分割.
然而图像经过CNN 模型处理后,其维度与分辨率下降,导致图像局部细节无法准确分割.针对该问题,研究者提出前后子特征融合(Context embedding)方法[12-14],其中最具代表性的是跳跃连接结构SkipNet 模型[6].该方法将CNN 网络的深层与浅层特征进行融合,使得输出中融入浅层的细节特征,改善输出精度.但是文献[15] 指出,卷积层的局部感受野(Receptive field)[16]与分割物体的面积相匹配才能取得良好的预测准确度,而卷积层的感受野随着网络深度的改变而不同.因此,CNN 中的卷积层对物体具有不同的预测准确度,然而SkipNet进行特征融合时,对特征图直接求和得到输出,这样对输入特征的无差别叠加,忽视不同特征层的分割特点,导致模型精度降低.
在街景识别等语义分割任务中,由于透视等原因导致不同区域中物体面积的差异,为避免感受野与局部的场景物体失配问题,针对SkipNet 模型,本文提出一种区块自适应特征融合(Block adaptive feature fusion,BAFF)方法.BAFF 具有如下特点:1)对输入的特征图进行分块,每个区块赋予不同的权重并进行加权融合,这样处理可以防止图像区域差异导致的局部感受野与物体失配问题;2)构建权值计算网络,通过训练该网络,计算出每个区块的权重,从而对不同卷积层进行自适应权重分配;3)采用通道分离形式进行卷积,使得网络在准确度提高的同时降低了网络的参数量与运算量,从而提高网络的运行速度.BAFF 结构如图1 所示,图1(a)表示BAFF 方法中的区块加权操作,图1(b)表示本文提出的BAFF 特征融合方法,图1(c)表示常规SkipNet 的特征融合方法.
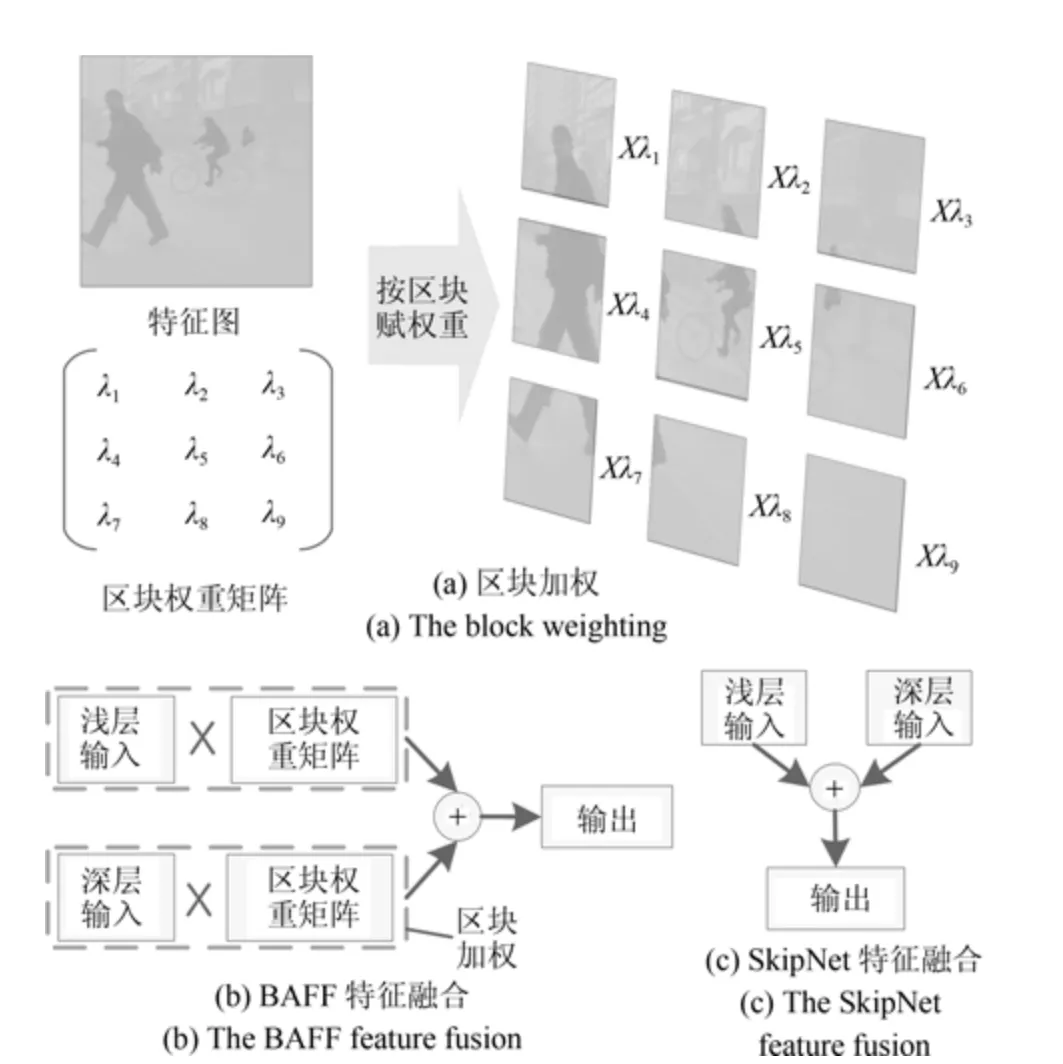
图1 区块特征融合与SkipNet 叠加融合对比图Fig.1 The comparison chart of block feature fusion and SkipNet additive fusion
1 相关研究
1.1 基于深度学习的实时语义分割网络
深度学习(Deep learning,DL)[5]是由Hinton首次提出,当前在各个领域有着广泛的应用.DL 通过多层神经网络,逐层提取对象特征,并输出对象的抽象高层信息,具有极其优异的学习能力.CNN 是典型的DL 模型,主要应用于图像处理领域.CNN利用图像的空间局部关联性,使用卷积进行特征提取,大大减少参数量与运算量.目前CNN 主要由卷积–池化层(Convolution-pooling)组合而成,并插入BN 层(Batch normalization)[17]增强网络性能.
为了提高CNN 运行速度,近些年有研究者提出深度可分离卷积(Depthwise separable convolution,DSC)[18]方法.DSC 网络对输入的特征图逐个采用卷积进行运算,再由1×1 卷积将特征映射到输出层,该方法运行速度快,可以搭建实时性较好的CNN 网络.文献[19] 提出的MobileNet-v2 模型就是基于DSC 搭建的一种实时网络,将其应用于语义分割,可大幅减少模型的运算量.
由于CNN 网络输出的维度下降,仅能识别物体大致类别,还需进一步对维度还原才可能实现像素级语义分割.目前有两类维度还原方法,一种是编码解码结构[20],另一种是基于膨胀卷积[21]的模型.相较于后者,编码解码结构压缩了卷积层维度,因而运算量较少,更适用于实时语义分割,其结构如图2所示.其中编码结构由CNN 网络组成用于特征提取,解码结构由转置卷积组成用于维度还原,而跳跃连接结构则是融合前后文特征改善网络精度.文献[14] 基于该结构,采用轻量卷积网络作为编码结构模型,使用基于SkipNet 的解码结构,大幅提高了网络的运行速度,实现了实时语义分割.

图2 编码—解码结构Fig.2 The structure chart of encoding-decoding
1.2 不同感受野下的语义分割特征
在CNN 网络中,卷积层用于提取图像特征,而不同卷积层的特征表达能力有所差异.本文结合CNN 网络的局部感受野,分析卷积层的分割特点,以探讨特征图的融合方法.由于CNN 网络采用局部连接方式,其输出的神经元只与输入层的部分区域相关联.该部分关联区域称作感受野,可知输出神经元的信息均来自感受野区域的图像.对于语义分割来说,感受野区域越大,则输出包含的整体信息越多,分割越体现整体性;相反感受野越小,输出越体现局部性.
由文献[16] 可知感受野由卷积层深度、卷积核大小、卷积步长决定.本文抽取MobileNet-v2 中第5、第8、第20 层的输出进行实验(感受野大小分别为27×27、59×59、475×475),其呈现如图3 所示结果.可以发现深层的分割结果趋向于整体性,可以很好地分割大面积物体,而浅层的分割结果则趋于局部性,捕捉细节能力更强.

图3 不同卷积层的语义分割测试Fig.3 The test of semantic segmentation for different convolution layer
2 基于BAFF 的语义分割
本文采用的语义分割模型如图4 所示,其中编码结构采用了轻量卷积神经网络MobileNet-v2,解码结构则在常规的跳跃连接结构上搭建,并引入一种BAFF 特征融合算法(BAFF-SkipNet),以提高语义分割模型的精度.

图4 基于BAFF 的语义分割网络结构Fig.4 The structure chart of the semantic segmentation network based on BAFF
2.1 加权原理分析
由前文可知,不同特征层反映物体的整体特征和细节特征存在差异.在特征融合过程中,将不同特征进行加权处理,可以突出并保留不同感受野下的图像特征.
首先,为了能够描述这种差异特性,本文在固定感受野下,针对同一物体缩放得到不同大小图像进行测试.测试样本如图5(a)所示,使用CCN 网络对该组图像进行预测,输出车辆区域的概率平均值,得到图5(b)和图5(c)所示结果.可以发现测试结果为单峰值函数分布形式,本文采用高斯函数对其进行拟合
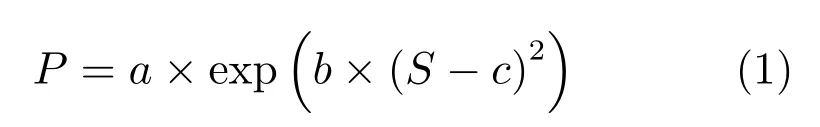
式中,S 表示物体面积,P 表示网络输出,a、b 与c由网络层的输出通过拟合确定,且c 与网络局部感受野正相关.
然后,考虑不同卷积层的特征差异,采用形状和峰值中心不同的高斯曲线对卷积层特性进行描述.实验发现:对于感受野较小情况(CNN 浅层输出),峰值中心靠近物体尺寸较小的部分(如图5(b)对应MobileNet 第8 层测试图所示),而对于感受野较大情况(CNN 深层输出),峰值中心靠近物体较大的部分(如图5(c)对应MobileNet 第20 层测试图所示).
进一步,对第8 层和第20 层进行加权融合,此时加权过程可以描述成两类高斯曲线的互补叠加,有

式中,S 表示物体面积,a1,b1,c1表示第8 层输出曲线拟合的参数,a2,b2,c2表示第20 层输出曲线拟合的参数,λ 表示加权值,对于不同权重其输出曲线如图5(d)表示.
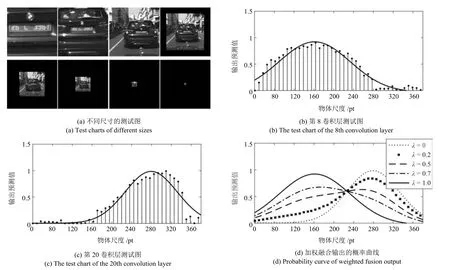
图5 CNN 预测精度与物体大小关系Fig.5 The relation between the precision of CNN prediction and the size of objects
在式(2)中,λ 的权值起到对图像特征区域的增强作用.例如,当λ=0.5 时,两个输入特征无差别叠加,相当于常规SkipNet 特征融合;当λ <0.5 时,浅层特征(小面积物体)能够得到增强;当λ >0.5时,深层特征(大面积物体)能够得到增强.
最后,考虑实际图像存在场景透视现象(即物体在图像中大小与空间距离相关),同一物体在图像中所占面积可能存在较大差异.而CNN 中给定卷积层的感受野大小是固定的,为了对局部区域的感受野大小进行调整,以匹配该区域的物体面积,本文对特征图进行分区块,然后对各个区块单独进行加权融合.
针对车辆识别的区块加权如图6 所示.可以发现,近处的汽车面积较大而远处的汽车面积较小.常规SkipNet 叠加融合方式,显然不能同时保留近景、远景物体特征,导致两类特征图叠加后产生大量噪声;而本文提出的分区块加权融合方法,能够较好地处理这类情况,改善特征图的融合效果.

图6 区块加权融合效果Fig.6 The effect of block weighted fusion
2.2 BAFF-SkipNet
通过上述分析可知,图像特征的区块加权融合,能够有效保留不同感受野下的图像特征,而权值计算则成为实现BAFF 的关键问题.文献[22] 针对卷积层特征图也进行了赋权操作,并采用全连接网络对权值进行计算,但该方法仅用于单卷积层的特征增强,不适用于特征融合中双卷积层融合的权重计算.本文借鉴该文献的权值计算方法,实现特征图区块权的自适应调节.
2.2.1 区块权重矩阵计算网络
权重计算层的输入为两个待融合的卷积层,其中每个卷积层共l 个(l 为语义类别数)大小为w×h的特征图.针对每组中对应的两个特征图进行信息整合:首先,将两个特征图堆叠成w×h×2 大小的三维矩阵块;然后,采用3×3×2 的卷积核对每个三维矩阵块进行卷积,这样处理就将两个输入特征图整合成一个特征图进行输出.为了表示这一特征整合过程,定义算子1 如下.

算子1.设两个输入矩阵为Ia与Ib,大小为κ× ι,o 表示输出矩阵,则输入信息的整合过程可表达为式中,w1与b1表示相对于输入Ia的权重与偏置,w2与b2表示相对于输入Ib的权重与偏置,函数σ(x)=1/(1+e-x)表示sigmoid 激活函数,* 表示卷积操作[23].
结合识别精度和运算量两类指标,选取适当大小的区块进行赋权.本文以8×8 大小的区块为例讨论其实现:1)采用维数为4×4 且步长为4 的卷积核压缩特征维度;2)使用维数为2×2 且步长为2的卷积核进行卷积使特征达到所需维度;3)使用sigmoid 函数,将输出权重映射到0 到1 之间,这样就得到区块权重矩阵.
需要说明的是,本文采用深度分离卷积进行运算,以此保证各类别间运算的独立性.这与常规的卷积是不同的.
2.2.2 分区块加权融合
由于权值矩阵的维度往往比特征图小.为此,在加权过程中需要提升权值矩阵维度,才能进行加权运算.本文采用双线性插值法(Bilinear interpolation)[8]对权重矩阵维度进行放大,该方法在提升权重矩阵维度的同时,还增加了升维矩阵中不同权重间边界的平滑性.区块加权融合的算子定义如下.
算子2.设两个输入矩阵为Ia与Ib,输出矩阵为o,大小为κ×ι,有

式中,° 表示哈达玛积,即矩阵对应元素相乘,λ 为扩张维度后的权重矩阵,大小为κ×ι.1κ×ι表示元素均为1、大小为κ×ι 的常数矩阵.
2.3 数学模型推理与参数更新
基于以上分析,结合算子1和算子2,推导BAFF 的计算过程.设置两个输入卷积层,每个卷积层共l 个特征图.假设每层特征图维度大小为w×h.第1 个卷积层记作za,zja表示该卷积层中第j 个特征图(0 ≤j ≤l);第2 个卷积层记作zb,zjb表示该卷积层中第j 个特征图.oj表示输出层中第j 个特征图.则BAFF 的计算过程可表示为

式中,up(x)表示双线性插值的上采样函数[8],° 表示哈达玛积.表示第1 个隐藏层中第j 个特征图的权重与偏置,以此类推分别表示各层中第j 个特征图的卷积核与偏置,oj表示输出层中第j 个特征图,该式中为权重矩阵,对上采样得到扩维后的权重矩阵将与输入加权得到融合后的输出oj.
进一步,考虑式(5)中的权值与偏置参数的训练.根据文献[24] 中卷积神经网络的反向传播算法,对本文BAFF 算法的参数进行更新.为了方便描述,定义下采样函数和矩阵180°旋转函数,统一采用A表示输入矩阵.
定义1.假设A 为大小为M × N 的输入矩阵,其元素为art,对矩阵A 进行不重叠分块,每块大小为m × n,则下采样得到的输出矩阵大小为(M/m)× (N/n),输出矩阵可表达为(dij)(M/m)×(N/n),其中dij表示输出矩阵中下标为ij 的元素,(M/m),(N/n)∈Z,下采样函数定义为
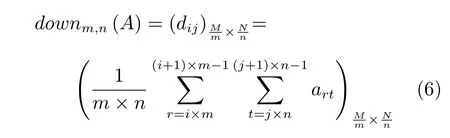
式中,0 ≤i ≤(Mm)-1,0 ≤j ≤(Nn)-1.
定义2.假设A 为输入矩阵,其大小为M×N.旋转180°后输出矩阵大小保持不变,输出矩阵表达为(dij)M×N,则旋转函数定义为
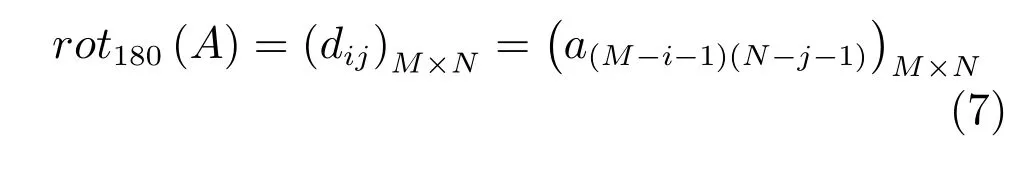
式中,0 ≤i ≤M-1,0 ≤j ≤N-1.
在实现反向传播算法时,从模型输出端依次反向计算各层输出的残差.根据链式求导算法,BAFF各层的残差计算如式(8)所示.
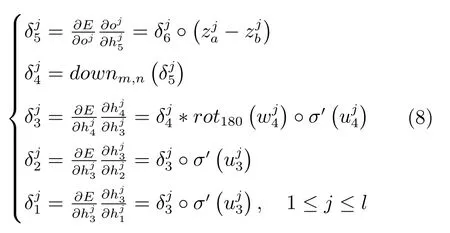
在式(8)的计算中,残差偏导的计算涉及到三类处理方式,包括有常规的链式求导操作如和的计算;利用下采样式(6)得到该公式对应至中插值公式的逆形式,在反向传播中传递插值公式两端的残差;由卷积层残差的反向传递公式计算得到.
然后,结合各层残差值计算权重与偏置梯度
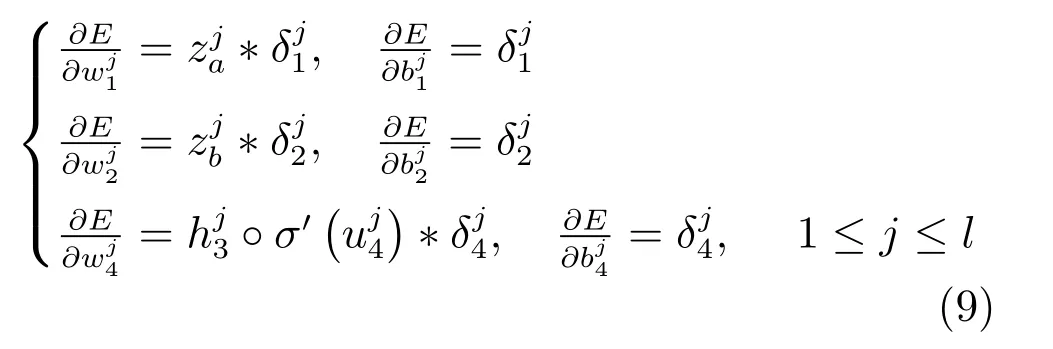
由式(5)可得隐藏层与权重、偏置的运算关系,式(8)得到各隐藏层的偏导,根据链式求导法则,可得到各层中权重和偏置的梯度,即得到式(9).以上处理方法在文献[25] 中有详细介绍.
最后,计算权重和偏置数值并更新.设置η 为学习率,根据梯度下降法,得到更新后的参数如式(10),计算参数并由式(11)更新
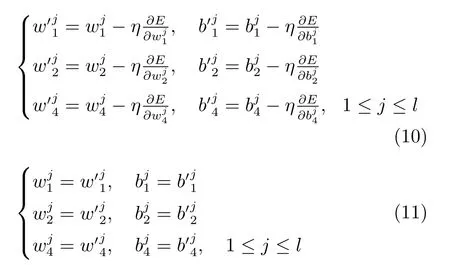
式(10)主要采用常规的梯度下降算法对新的参数进行计算,该算法具有良好的收敛性能,在一定的训练次数下,能够确保模型的准确性.
本文提出的BAFF 参数更新方法如算法1 所示.
算法1.BAFF-BP


3 实验与分析
仿真实验平台配置为至强八核处理器2.60 HZ,显卡为NVIDIA Titan XP,16 GB 内存,使用Cityscapes[26]街景数据集,该数据集可用于测试实验的共19 类街景物体和1 类背景(即l=20),本文采用该数据集中5 000 幅精细标注的图片,其中3 475 幅用于训练模型,1 525 幅用于测试准确度,运行环境为Tensorflow 1.4.
3.1 模型训练
模型训练共两个阶段:第1 个阶段是对编码层训练;第2 个阶段是对解码层与BAFF 模块进行训练.
第1 个阶段训练目的是使编码层模型输出不同深度的分割图,为解码层各阶段输入提供相应的特征图.该阶段操作如下:首先,使用1×1 卷积将编码层的输出映射至类别概率图;然后,使用双线性插值对映射后的卷积层进行维度放大;最后,计算总的损失函数并训练模型.因为本文编码层采用MobileNet-V2,选取编码层中维度为输入图像1/32、1/16、1/8 大小的特征图进行训练,即第5、第8、第20 卷积层,设这三层中第j 个类别概率特征图为设置yj为第j 个类别的期望输出,根据交叉熵公式得到损失函数为
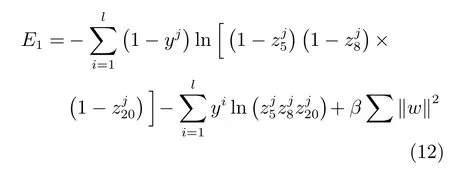
式中,l 为类别数,0 ≤j ≤l-1,β 为L2 范数的增益系数.
第2 阶段目的是对解码结构进行训练,将编码层的3 个卷积层输出进行特征融合并逐步扩展卷积层维度,输出更加精细的分割图.令^oj为网络输出层的第j 个特征图,整体损失函数为
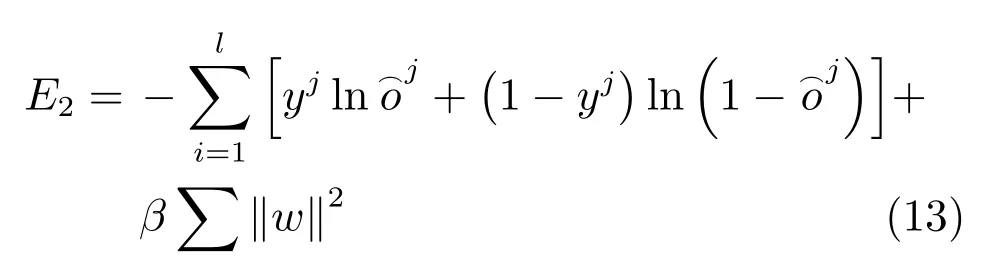
式中,l 为类别数,0 ≤j ≤l-1,β 为L2 范数的增益系数.
选取CityScapes 数据集进行模型训练,设置批次数为5,初始学习率为10-2,L2 范数的增益参数设置为10-4,每批样本加入噪声增加样本的多样性,其训练过程如图7 所示.
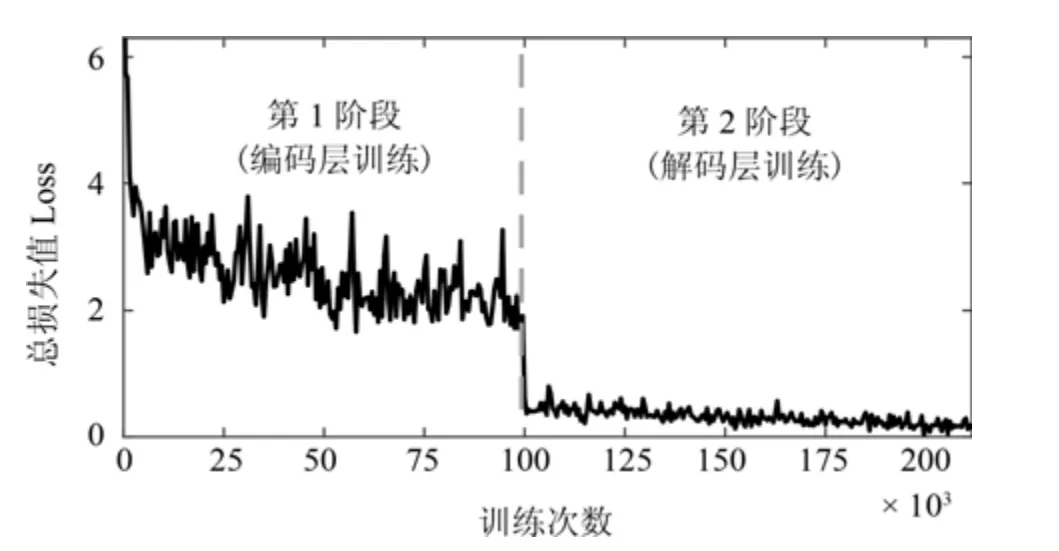
图7 模型训练损失值的变化Fig.7 The loss of value during the model training
3.2 模型性能分析
为了评价语义分割模型的准确性,本文选用均交并比(Mean intersection over union,MIoU)[27]表示分割物体的精度,其计算式如式(14)所示,该值越高代表分割效果越好.
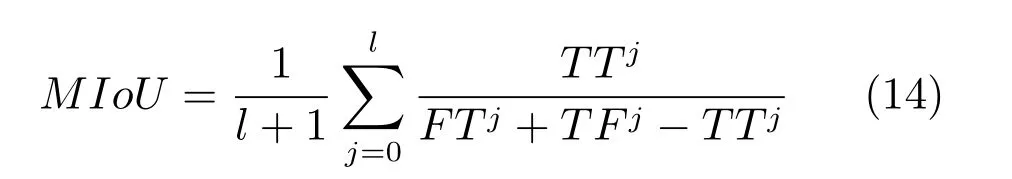
式中,l 为类别数,0 ≤j ≤l-1,TTj表示第j 个类别中预测正确的样本数,TFj与FTj分别表示第j个类别中的真假与假真样本数,即预测错误的样本.
为了对整体模型进行分析,本文从模型的时间复杂度(浮点运算量)和空间复杂度(参数总量)上分析.在实时语义分割中,其一个重要的指标就是网络的预测速度,如果时间复杂度过高,则会导致模型训练和预测耗费大量时间,无法做到快速的实时预测,因此时间复杂度决定了模型的训练与预测时间.对于网络的空间复杂度,其决定了模型的参数数量.模型的参数越多,模型所需的内存资源就越多,同时训练所需的数据量就越大,导致模型训练更容易出现过拟合,使得网络的预测精度下降.
根据文献[19],本文模型的时间复杂度和空间复杂度计算分别为
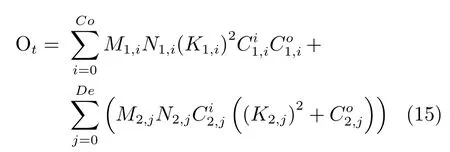

式中,Co 表示模型中常规卷积的数量,在第i 个常规卷积层中,M1,i与N1,i表示输出特征图的长度与宽度,K1,i表示卷积核维数,表示卷积层输入的通道数,表示卷积层输出的通道数.De 表示模型中深度分离卷积的数量,在第j 个深度分离卷积层中,M2,j与N2,j表示输出特征图的长度与宽度,K2,j表示卷积核维数,表示卷积层输入的通道数,表示卷积层输出的通道数.
3.3 总体性能分析与比较
3.3.1 BAFF 特征融合分析
本文提出的BAFF 方法,通过自适应加权可以很好地改善网络对不同物体的分割精度.为了验证BAFF 特征融合的性能,本文抽取特征融合后的特征图进行分析.以客车与卡车类别为例,特征融合后的特征图如图8 所示.可以发现常规SkipNet 方法不能很好地识别出物体,而BAFF 方法则可以较好地分割出物体.
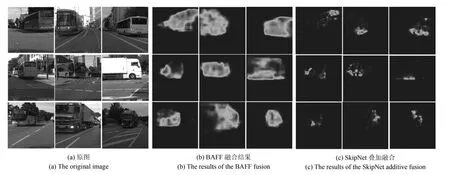
图8 特征融合的显著图Fig.8 The salient region of the feature fusion
进一步,从语义分割预测精度上进行分析,采用MIoU 表示语义分割精度,整体模型如图4 所示,将其与常规SkipNet 方法进行比较.在CityScapes 数据集上训练两种模型各24 000 次,实验平台如第3节所述.得到图9 所示的实验结果,可以发现,相对于常规SkipNet 方法,本文方法对物体分割精度的提升较大,主要体现在特征复杂的种类上,例如:rider (骑车人),mbike (摩托车),train (火车),wall (墙),fence (围栏)等,其原因在于本文提出的BAFF 方法能够自适应地融合浅层和深层特征.

图9 模型精确度对比图Fig.9 The comparison chart of model accuracy
最后,本文从时间复杂度与空间复杂度上对比该两种方法,根据实验,得到如表1 所示结果.可以发现,相比于常规SkipNet 方法,BAFF-SkipNet 的精度提升了3.7%,而带来的运算量(时间复杂度)增长却只有0.001%,参数量(空间复杂度)只增加了0.002% .因此BAFF 可以在几乎不带来计算量增长的情况下,有效地提高网络模型精度,具有很高的运算效率.
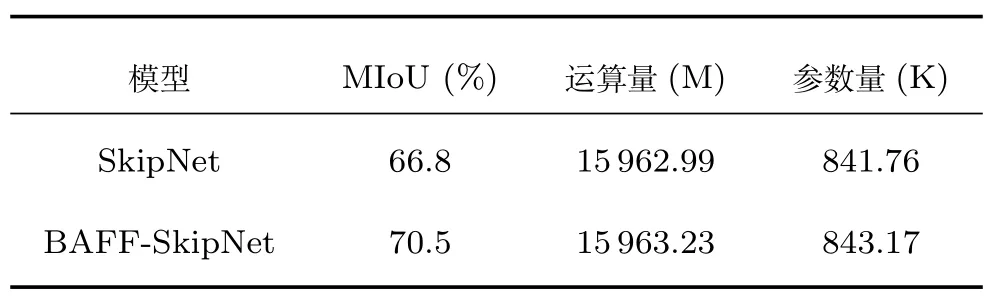
表1 加入BAFF 前后的模型复杂度对比Table 1 Comparisons of model complexity before and after adding BAFF
3.3.2 整体模型分析
为了验证本文方法的有效性,实验将基于BAFF 的图像语义分割网络(即MobileNet-BAFFSkipNet)与文献[28-30] 的方法进行对比,统一采用MIoU 来衡量语义分割精度,各模型的训练与测试统一采用CityScapes 进行,其训练与测试的数据量、实验的硬件平台如第3 节开头所述,训练次数均为24 000 次.
对比各个模型的精确度,得到表2 所示结果,表2 分别列出各个类别的精确度,其中本文模型在墙(wall)、围栏(fence)、摩托车(mbike)、自行车(bike)上具有较高精确度.
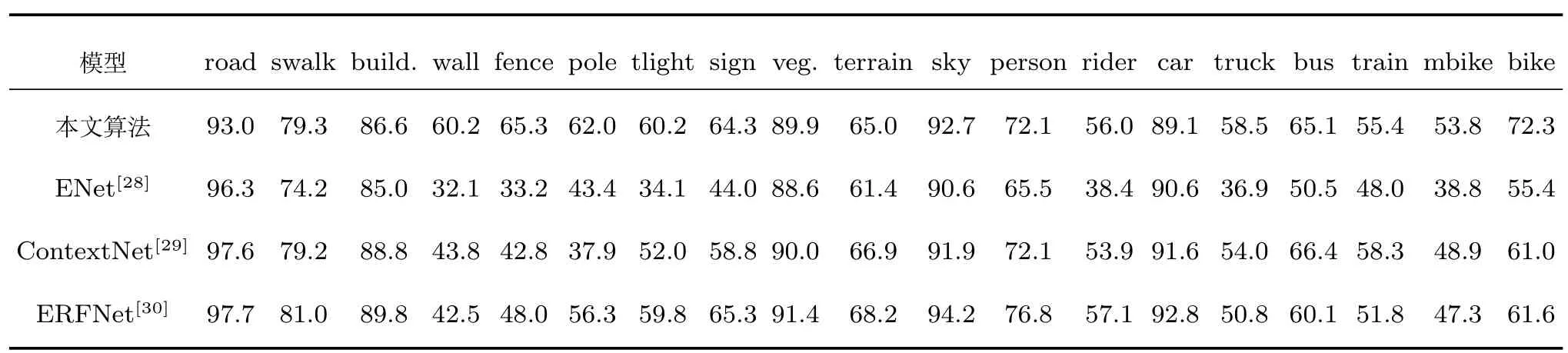
表2 语义分割各类别精度对比(%)Table 2 Semantic segmentation accuracy comparison of different types (%)
进一步,从模型复杂度与空间复杂度上进行分析,得到表3 所示结果,从实验比较结果可以发现,本文模型在参数量较少的条件下,具有很高的分割精度,同时模型的运算时间也相对较小.可见,本文模型在图像分割的快速性和准确性之间做到了很好的平衡,是一种性能优良的实时语义分割算法.

表3 实时语义分割模型精度对比Table 3 Accuracy comparison of real-time semantic segmentation models
图10 中,选取了6 幅街景较为复杂的图像作为测试,并与文献[28-29] 方法的语义分割效果比较.可以看到,本文方法能够清晰地分割图像中的一些细长物体,如方框(1)和(3)所示的细杆;较好地区分密集的行人,如方框(2)和(4)所示的人群;识别交通标志,如方框(5)所示的交通标志;识别大型物体,如方框(6)所示的围栏.在对比实验中可以看到,文献[28-29] 方法在语义分割与识别过程中,虽然能够很好地识别道路、人行道等特征简单的类别,但在识别特征复杂物体时,容易受到其他混杂场景的干扰,且分割的细节不够清晰.可见,本文提出的BAFF 方法具有良好的图像语义分割能力和识别能力.

图10 语义分割效果图对比Fig.10 Semantic segmentation effect contract graph
4 结论
本文提出了一种基于BAFF 的图像语义分割网络,具有识别精度高、模型运算量小的特点,可以应用于实时性要求高的图像语义分割系统.与当前主要的实时语义分割网络比较,本文方法具有以下特点:首先,引入一种分区块的自适应特征融合机制,显著提高了图像语义分割的精度,提升复杂环境下的鲁棒性.其次,引入权重计算网络,对区块权重进行自适应计算,且网络的计算量非常小,能够保证模型计算的快速性和实时性.考虑到常规的编码–解码网络结构属于一类黑箱模型,模型内部计算参数缺乏明确的物理含义.本文提出的BAFF 所实现的特征加权属于一类可解释的网络模型,更适合实际应用和操作.采用神经网络进行动态加权融合可以用于解决信息融合问题,在本文基础上,下一步工作拟将神经网络动态加权融合的思想与传统控制问题、互补滤波问题进行结合开展研究,以提高其他类似系统的精确和实用性.
