运用Dropout-LSTM模型的新冠肺炎趋势预测
2021-06-19杨文艺
王 瑞,闫 方,逯 静,杨文艺
(河南理工大学计算机科学与技术学院 河南焦作 454000)
疫情在全球多点爆发并蔓延,已成为全球性流行病,给各国人民的健康带来巨大威胁。通过各地一系列防控措施,如勤洗手、公众场合戴口罩、外出需出示健康码和通行大数据等,我国疫情得到较好的控制,但是国外疫情仍然比较严峻,因此利用新冠肺炎历史数据预测疫情发展趋势对制定合理的干预防控措施有重要意义。
文献[1-3]从多个角度为抗击疫情提供了有力的学术支持。现有方法可分为统计学方法、动力学方法和机器学习方法。统计学方法适合在信息不完整的情况下使用,该方法通过部分样本的情况预测总体趋势,而部分样本与总体传播趋势具有较大差异性[4],因此该方法的预测误差较大,无法准确体现疫情传播的趋势变化。动力学方法的经典数学模型为SIR(susceptible infected recovered)模型[5-6]和SEIR(susceptible-exposed-infected-removed)模型[7-8]。动力学方法对疫情早期传播趋势有较好的预测,但是无法对开放式流动环境下的病毒传播做出准确估计,也无法使假设的疾病传播能力及治愈概率的常数与实际状况相符,因此无法对疫情趋势做长期准确的分析[9]。
随着新冠肺炎数据增多,机器学习展现出了极大的优越性。文献[10]在有限的数据下,通过最小二乘准则和梯度下降算法对数据进行非线性回归来预测新冠肺炎确诊人数趋势,但此方法需要人为添加时间特征保证预测准确度。为解决上述问题,文献[11-13]运用自回归积分滑动平均模型(autoregressive integrated moving average model,ARIMA)对新冠肺炎疫情发展状况进行了预测,此模型对数据的时序性要求高,不需要人为添加时间特征,但是非线性拟合能力不强,随着数据量增加,预测效果下降。为解决上述问题,文献[14]建立了基于深度学习的长短期记忆模型(long short-term memory,LSTM),通过Python实现了模型的拟合和预测,此方法在一定程度上提高了短期新冠肺炎预测的准确度,但是有以下不足:1)未做到对新冠肺炎发展趋势较为准确的长期预测;2)LSTM神经网络对数据量需求较大,文中未提供一个简单的数据采集方法;3)未考虑深层神经网络中由于参数多和模型复杂而带来的过拟合问题。
LSTM神经网络在趋势预测中有许多改进机制,大致分为两类:1)针对LSTM神经网络自身进行改进;2)引入其他方法改进LSTM算法。文献[15]针对LSTM神经网络自身改进,网络训练时,将输出反馈回输入端,使其二次训练达到提高泛化能力的目的。文献[16]利用卷积神经网络(convolutional neural network,CNN)提取挖掘相邻路口交通流量的空间关联性,通过LSTM模型挖掘交通流量的时序特征,将提取的时空特征进行特征融合,实现短期流量预测。文献[17]引入集合经验模态分解(ensemble empirical mode decomposition,EEMD),构建多层级LSTM预测模型提升模型预测准确率。本文提出的Dropout-LSTM模型属于第二种改进方法。新冠肺炎历史数据为时序性数据,而LSTM神经网络擅长处理时序性数据,可根据实验效果调整具体预测的天数,达到对新冠肺炎发展趋势预测的目的。
由于新冠肺炎历史数据较多,传统的人工搜集方法不再适用,因此本文使用网络爬虫技术从腾讯新闻网站中获取相关数据供本次研究使用。考虑到新冠肺炎历史数据之间有很强的时序性,故本文使用擅长处理时序性数据的LSTM神经网络作为基本模型对疫情趋势进行预测。该模型与ARIMA模型相比有更强的非线性拟合能力,且不需要人为添加时间特征,可最大限度地挖掘时序数据之间的非线性关系。针对LSTM神经网络,新冠肺炎数据量较小,为避免在多层网络训练时出现过拟合问题,本文构建多层LSTM神经网络,并引入Dropout技术按随机概率让神经元失活。最后使用国内累计确诊、现有确诊和累计治愈人数验证此方法的准确性。
1 新冠肺炎历史数据获取
针对2020年1月13日−2020年9月12日的244条数据,传统的人工搜集方法效率低且容易由于主观原因导致收集的数据与真实值不符。为避免以上问题,本文采用基于Python语言的网络爬虫技术[18]获取新冠肺炎历史数据,并将其保存至CSV文件,以供后期实验使用。具体流程如图1所示。
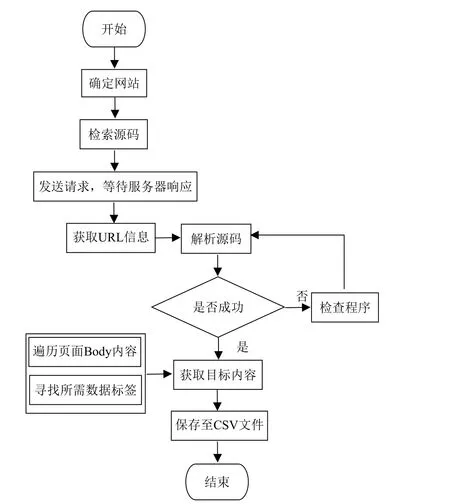
图1 获取新冠肺炎历史数据流程图
具体步骤为:
1) 确定需要爬取数据的网址:https://view.inews.qq.com/g2/getOnsInfo?name=disease_other,在网页空白处,点击F12查看目标网站源码,找到数据接口;
2)向服务器发送请求,等待响应。若响应成功,可获得URL的信息,并保存响应结果,以便后续对数据处理;若响应失败,需检查程序,重新发送请求;
3)对源码进行解析,若解析成功,在遍历源码Body的基础上寻找目标内容的标签,如:日期、累计确诊、新增确诊和累计治愈等,对目标内容进行获取并保存至CSV文件;若解析失败,则需检查程序,重新解析源码。
2 LSTM模型
每日更新的新冠肺炎历史数据属于时序性数据,根据神经网络的特征,本文选择擅长处理时序性数据的LSTM神经网络作为基本模型对新冠肺炎发展趋势进行预测,可最大限度地挖掘数据时序性与非线性之间的关系。
2.1 LSTM模型简介
LSTM神经网络[19]属于循环神经网络(recurrent neural networks,RNN)。RNN在处理序列信息中有良好的性能,但是当历史数据和预测数据的位置间隔不断增大时,梯度越传越弱,上一层的网络权重无法更新,丧失从历史数据中学习信息的能力,即梯度消失问题。
LSTM神经网络能够解决RNN的梯度消失问题,是因为该网络中放置了遗忘门ft、输入门it和输出门ot[20]。可根据式(1)~(6)判断该数据是否符合算法认证,符合认证的数据留下,不符合的数据则通过遗忘门遗忘,因此LSTM神经网络能在更长的时序数据中有更好的表现[21]。LSTM神经网络标准结构如图2所示。

图2 LSTM网络结构
2.2 LSTM记忆单元更新
1)遗忘门
遗忘门负责对t时刻的输入xt选择性忘记,通过计算ft控制上一单元候选状态Ct−1中的数据保留或忘记。若ft为1,表示保留上一单元的数据;若ft为0,表示忘记上一单元的数据:
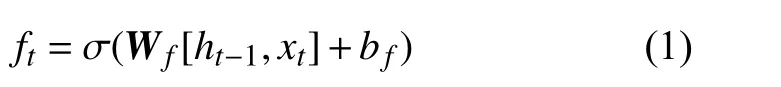
式中,σ为sigmoid激活函数;W f为上一单元隐藏层的输出ht−1和 当前输入数据xt相乘的权重矩阵;bf为遗忘门的偏置。
2)输入门
输入门it负 责对t时刻的输入有选择性地记忆。
当前输入内容由式(2)得到,σ用来控制需要更新的输入值,而输入的门控信号由式(3)控制,tanh用来控制当前记忆单元候选状态:

式中,W it为 输入门it在t时 刻的输入xt的权重矩阵;W c为 新生成信息在t时 刻的权重矩阵;bi、bc为输入数据和新生成信息在当前单元的偏置。
传递给t+1时 刻的状态Ct由两部分组成:式(1)得到的遗忘门ft的输出与上一时刻t−1候 选状态Ct−1之积;式(2)得到的输入门it的 输出与t时刻候选状态C˜t之积。此过程旨在抛弃当前单元中无用信息,保留有用信息:

3)输出门
输出门ot通过sigmoid激活函数控制得到初始输出,接着使用tanh层将传递给下一时刻t+1的状态Ct缩放至(−1,1)上,最后与初始输出相乘得到最终输出结果:

式中,Wot为输出门ot的权重矩阵;bo为偏置。
3 Dropout技术
新冠肺炎历史数据量的大小是相对的,即对传统的人工搜集方法来说,新冠肺炎历史数据量较大,搜集较为麻烦;但是对于网络规模较大的LSTM神经网络来说,新冠肺炎历史数据量较小,较小的数据量输入较复杂的LSTM神经网络容易出现过拟合现象,即在训练集上精确率很高,在测试集中精确率却较低。在数据没有过拟合的前提下,调参很容易实现更高程度的拟合,但是会出现过拟合问题,无论如何调参,测试集的准确度依然不高。过拟合问题严重影响了模型的预测精度,为解决模型在训练时出现的过拟合问题,提高模型的训练精确度,本文引入Dropout技术。
Dropout是一种防止过拟合技术,分为权重Dropout和神经元Dropout。权重Dropout选择神经层权重矩阵中的部分权重使之失活,而神经元Dropout则是选择神经层中部分神经元使之失活[22]。图3为神经网络运用Dropout技术前后对比,图3a为标准神经网络,图3b为运用Dropout技术后的神经网络。

图3 运用Dropout技术前后对比
本文选择神经元Dropout技术按照概率把部分神经元的激活值设置为0,随机使其失活,虚线部分表示失活后的神经元无法参与网络训练,这样可减弱神经元节点间的联结,提高模型泛化能力,减轻过拟合问题。
Dropout技术在测试集上不需要使用。因为在测试阶段并不期望输出结果是随机的,若在测试阶段使用Dropout技术可能会导致预测值产生随机变化(因为Dropout使节点随机失活),预测值会受到干扰。
4 Dropout-LSTM模型
4.1 Dropout-LSTM模型微观层面
如图4所示,x为LSTM神经网络输入信息,y为输出信息,每个矩形代表一个LSTM神经元。Dropout技术应用于LSTM神经网络,必须置放于网络的非循环部分,否则信息会随着循环丢失。这是因为:若把Dropout技术设置在隐藏状态上,即图中实线部分,每经一次循环,剩余信息便会以概率P丢失,也就是对式(6)ht随机进行置0操作。若序列较长,循环次数较多,到最后信息早已丢失。把Dropout技术设置在输入信息x上,那么Dropout技术造成的信息丢失与循环次数无关,只与网络层数相关。

图4 Dropout-LSTM模型微观图
同一层神经元不同时刻之间的信息传递不使用Dropout技术,而在同一时刻层与层之间的神经元传递信息时使用,将其神经元按照一定概率P随机置0,使其失活。如图中粗线部分所示:t−2时刻的输入xt−2先传入第一层LSTM神经网络,此过程使用Dropout技术,信息从第一层的t−2时刻传到t时刻不进行Dropout技术;接着从第一层的t时刻向第二层神经网络传递信息时使用Dropout技术。
4.2 Dropout-LSTM模型宏观层面
LSTM神经网络实施Dropout技术宏观结构如图5所示,x0,x1,···,x243为输入数据。虚线圆表示采用Dropout技术后随机失活的神经元,虚线箭头表示失活后的神经元不传递信息。
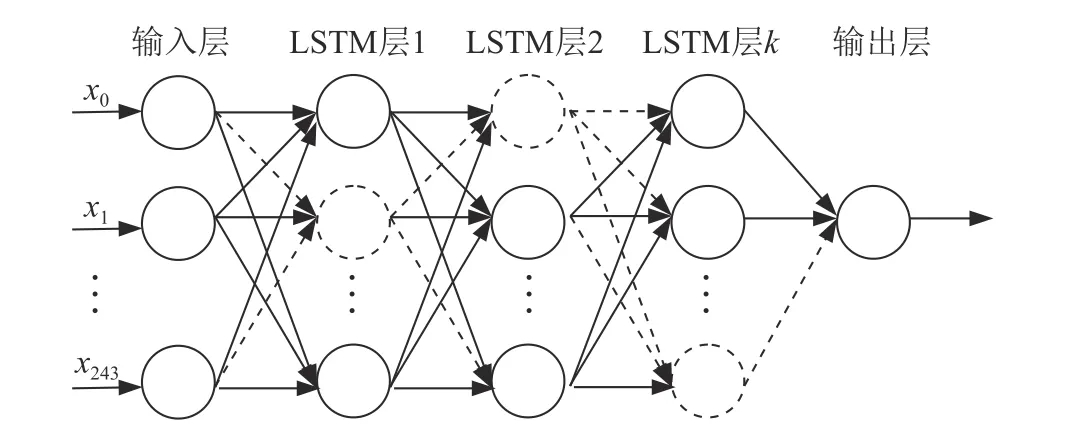
图5 Dropout-LSTM模型宏观图
加入Dropout技术的LSTM神经网络具体工作步骤为:
1)设定随机概率P,使网络中的每一层神经元按照随机概率P失活,但是不删除这些失活的神经元,停止工作的神经元不参与网络训练中的正向传播,输入神经元和输出神经元保持不变;
2)将信息x输入Dropout-LSTM模型进行从输入层到输出层的正向传播,计算并存储神经网络的中间变量;沿着从输出层到输入层的顺序根据损失函数进行反向传播,计算并存储神经网络的中间变量和梯度参数;在未失活的神经元上更新相关参数;
3)恢复失活神经元,此时刚恢复活性的神经元保持原样,而未失活的神经元参数经过上一轮过程已更新,重复步骤1)~2)。
通过随机忽略隐藏层神经元,可避免LSTM神经网络过度依赖某些局部特征,一定程度上降低了迭代过程中的过拟合现象。
5 实验过程
5.1 实验环境
在Windows8.1系统中使用Pycharm,Python3.6为实验平台,运用Tensorflow深度学习框架所提供的LSTM 神经网络用于仿真实验。
5.2 实验数据及其预处理
5.2.1实验数据说明
实验数据均由网络爬虫技术在腾讯网站获取。日期范围为2020年1月13日−2020年9月12日,共计244条数据,将其按照训练集214条数据、测试集30条数据划分,针对国内累计确诊、现有确诊、累计治愈人数进行预测。
5.2.2实验数据预处理
1)数据提取、划分:在爬取到的新冠肺炎历史数据CSV文件中提取出来日期和累计确诊两列,将累计确诊列以矩阵形式表示:

2)数据归一化处理:为缩短模型训练时间,加速loss下降,对训练数据和测试数据分别进行归一化处理,这样可以最大程度保留数据特征,更好拟合新冠肺炎数据之间的非线性关系。本文采用最大最小归一化方法对数据进行处理:

式中,x代 表样本数据;xmax、xmin分别代表训练数据或测试数据中的最大值和最小值。设归一化处理后的训练集和测试集为Xntrain和Xntest,对现有确诊和累计治愈数据做同样处理。
5.3 LSTM模型参数
本文提出的模型由1个输入层、多个隐藏层和1个输出层组成。上一个隐藏层的输出作为下一个隐藏层的输入,输入层与隐藏层共同实现输入数据特征的提取,最后一个隐藏层的输出为一维列向量,经线性回归即得到处理后的预测值[23]。经反复实验,最终超参数设置如下:激活函数为Linear、迭代次数为15000,隐藏层为100,Dropout为0.05,学习率为0.0001,优化器为Adam。
5.4 实验流程
目前缺乏利用深度学习对新冠肺炎发展趋势预测的研究,这是因为:1)深度学习对数据量要求较高,利用传统手工搜集方法不易获取相关数据;2)训练过程中易出现过拟合问题,严重影响预测精度。在已有的LSTM神经网络用于新冠肺炎预测的研究中,有以下不足:1)未提供简单的数据获取方法;2)LSTM层过少,不能充分挖掘时序数据之间的非线性关系;3)未考虑过拟合问题给实验结果带来的影响。针对以上问题,本文利用网络爬虫技术获取新冠肺炎历史数据组成实验数据集;在网络层上构建层次更深的LSTM新冠肺炎发展趋势预测模型;在每个LSTM单元构成的隐含层中的非循环部分采用Dropout技术对神经元进行随机概率失活,有效避免LSTM神经网络中的过拟合问题。本文实验流程图如图6所示。

图6 运用LSTM的全国累计确诊预测流程
6 实验结果分析
6.1 实验评价指标
本文预测评价指标采用平均绝对百分误差(mean absolute percentage error,MAPE)、平均绝对误差(mean absolute error,MAE)和均方根误差(root mean square error,RMSE)衡量:
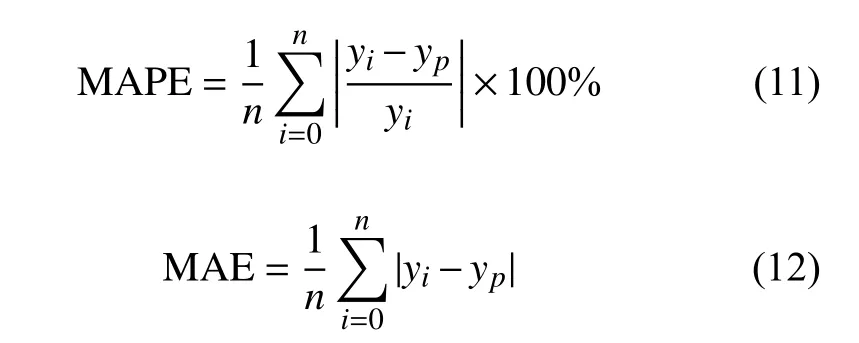

式中,yi表示真实值;yp表示预测值;n表示待预测的新冠肺炎天数,即30。
6.2 模型预测结果
为证明本模型(Dropout-LSTM模型)的普遍适用性与优越性,运用ARIMA模型、LSTM模型分别对2020年8月14日−2020年9月12日的国内累计确诊、现有确诊和累计治愈数据进行预测,并与Dropout-LSTM模型预测结果进行对比。Dropout-LSTM模型预测值和误差如表1所示,3种模型的可视化对比如图7所示。

表1 全国新冠肺炎发展趋势预测
误差为预测值与真实值之差。误差为负,代表预测值小于真实值;误差为正,代表预测值大于真实值。本文针对30天的数据进行预测,当预测日期后移时,将预测日期之前的数据加进来。若仅用当前数据去预测未来两个月甚至更久,从表3可看出误差有恶化趋势,选择适当的预测天数和日渐增多的数据量可解决误差趋势恶化问题。
若仅预测30天的数据,恶化程度是可控的,误差会固定在一定区间,对基数较大的累计确诊数和累计治愈,数据误差区间为[−25,−5]和[−43,8],基数较小的现有确诊误差仅为[−4,2]。随着新冠肺炎数据量增多,神经网络预测也会更加准确。
由图7可明显看出,累计确诊和累计治愈真实值总体呈上升趋势,现有确诊真实值呈下降趋势。

图7 新冠肺炎预测效果
对3组数据分别进行预测时,ARIMA模型预测曲线与真实值曲线差别均较大,拟合效果较差。这是因为ARIMA模型网络结构较简单,非线性拟合能力较弱。LSTM模型拟合效果次之,这是因为虽然LSTM神经网络对时序数据有较好的拟合能力,但是出现了过拟合问题,无论如何调参,测试集的准确度依然不高。Dropout-LSTM模型预测曲线与真实值曲线最接近,尤其是在现有确诊预测中,几乎与真实值曲线重合,这是因为添加Dropout技术后解决了LSTM神经网络中的过拟合问题,从而提高了准确度。
6.3 评价指标对比
为进一步说明Dropout-LSTM模型具有较高的拟合能力,采用ARIMA模型、LSTM模型和Dropout-LSTM模型对3组数据分别进行预测,表2对其MAPE、MAE和RMSE进行了对比。
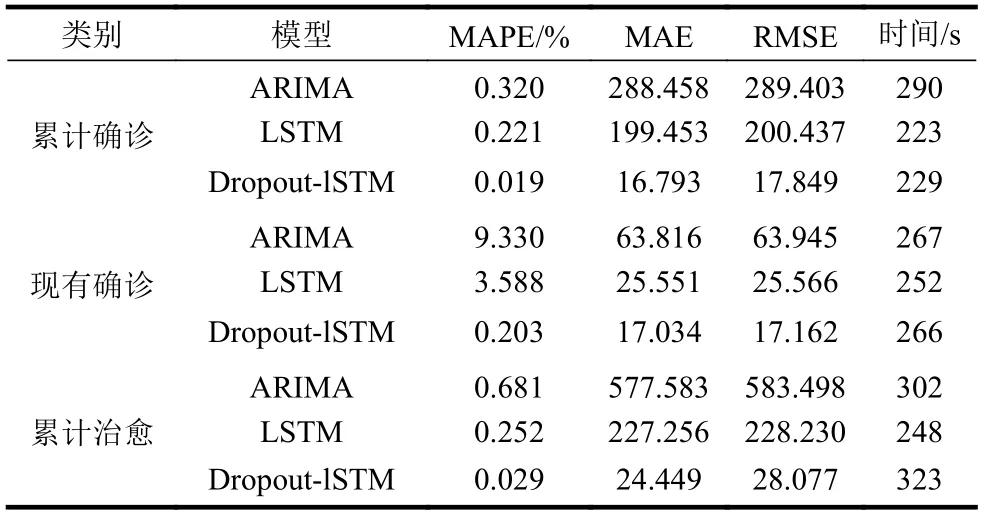
表2 评价指标对比
从模型角度看,Dropout-LSTM模型的MAPE、MAE和RMSE在3组数据中均有明显下降,说明误差降低,准确率提高,排除了只对一组数据有较好预测效果的可能。这是因为Dropout技术使神经元按照一定概率失活,神经网络不会偏向于某一个节点,从而使每一个节点的权重不会过大,减轻了LSTM神经网络的过拟合现象,提高了预测准确度。从时间角度看,LSTM模型训练时间最短,这是因为LSTM神经网络共享参数,节省了训练时间;而Dropout-LSTM模型比LSTM模型训练时间长,这是因为神经元按照随机概率失活后,神经网络结构变得更“粗糙”,为使曲线更平滑地到达理想值,收敛到全局最优,增加了训练时间。
虽然向LSTM模型中接入Dropout技术增加了网络训练时间,但是随着数据量增多,需要的网络层数、训练轮数会相应减少,过拟合问题也会减轻,使网络训练在可接受的时间内完成。
7 结束语
本文提出的运用Dropout-LSTM模型预测新冠肺炎发展趋势的方法,通过网络爬虫技术获取新冠肺炎数据用于实验,解决了人工搜集方法的不足,提高了数据收集速度;构建层数更多的LSTM神经网络用于国内累计确诊、现有确诊和累计治愈的预测,在此基础上引入Dropout技术对神经元进行随机概率失活,有效避免了神经网络过拟合问题,充分挖掘了数据的时序性与非线性关系。通过全国累计确诊、现有确诊和累计治愈人数验证了运用Dropout-LSTM模型对新冠肺炎趋势预测是完全可行的,并且准确度较高。
