一种基于改进词袋模型的视觉SLAM算法
2021-06-18张光耀倪益华吕艳倪忠进黄通交
张光耀,倪益华,吕艳,倪忠进,黄通交
(浙江农林大学 工程学院,浙江 杭州 310000)
0 引 言
随着移动机器人技术发展,同时定位与建图(simultaneous localization and mapping,SLAM)受到越来越多的关注。SLAM按传感器种类分为激光SLAM与视觉SLAM两大类[1]。激光SLAM目前较为成熟,已进入商业应用阶段。但由于激光雷达价格高、体积大、安装复杂等原因,使激光SLAM应用受到很大限制。视觉SLAM因视觉摄像头价格低、机器视觉技术飞速发展而成为研究热点。
2007年,A.J.Davisin等[2]提出了第一个视觉SLAM:MonoSLAM,其前端为Shi-Tomasi特征提取,后端为扩展卡尔曼滤波优化算法,该方法存在计算量大、精度低、实用性差等问题;J.Stückler等[3]2012年提出了DVO SLAM,其前端为稠密的视觉里程计,后端采用g2o算法框架,回环检测是对关键帧的遍历特征检测,构建的地图为点云地图,但其精度不高,在TUM数据集上平均精度仅0.416 m[4],且地图为点云地图,不能直接用于后续导航等,实用性低;M.Labbe等[5]2014年提出了RTABMAP,其前端为SIFT特征,后端为图优化,回环检测基于词袋模型,输出地图为点云地图。该方法计算量仍较大,精度不高,在TUM数据集上平均精度为0.22 m[4],地图为点云地图,实用性差;R.Mur-Artal等[6]2015年提出了ORB-SLAM,其前端为ORB特征,后端为图优化,回环检测基于词袋模型,输出地图为点云地图,该方法计算量较小,精度不高,地图为稀疏点云地图,实用性差。总而言之,精度较低、实用性较差是目前大部分视觉SLAM存在的共同问题。
针对这些问题,可以在回环检测和构建地图部分进行改进。回环检测是消除误差的一个重要环节。J.Sivic等[7]提出了词袋模型,它是将提取到的图像特征进行离散化处理,并统计不同特征出现的频率以描述机器人周围的环境。该方法计算量巨大、匹配速度慢、相似度计算能力较低、效果较差;D.Niser等[8]针对词袋模型计算量大、匹配速度慢等问题,对词袋模型进行改进,增加了树形结构,提高了特征聚类速度,减少了计算量,提高了匹配速度,但仍存在相似度计算能力较低的问题;C.Cadena等[9]通过将词袋模型与双目相机结合的方法进行回环检测,该方法在当时效果良好,但仍存在相似度计算能力不强的问题;C.Gong等[10]采用递归贝叶斯方法进行回环检测,该方法效果一般;罗顺心等[11]将SSD神经网络用于回环检测,效果较好,但其效果和训练样本关系密切。地图构建部分是SLAM输出信息的体现。视觉SLAM中,常见的地图形式为点云地图。点云地图规模庞大,包含很多无用信息,且无法被用于导航,实用性较差。八叉树地图将地图信息进行压缩,大大减小了规模,且可以记录一个空间点是否被占据的信息,能用于导航等,实用性较高。
本文基于以上研究,对词袋模型进行改进,增加节点距离,以期提高相似度计算能力,将改进后的词袋模型用于回环检测,以减少累计误差,提高精度,且通过八叉树模型将点云图变成可用于导航的八叉树地图,提高实用性。
1 算法框架
本文提出的RGB-D SLAM算法框架如图1所示。首先,提取ORB特征点并匹配,结合深度信息通过PnP算法估计相机位姿,对图像进行筛选,得到关键帧并完成帧与帧之间的配准;其次,通过改进的词袋模型进行回环检测,结合图优化得到相机全局最优位姿,再通过去外点滤波器与体素滤波器减少点云规模;最后,通过octree转化,生成八叉树地图。
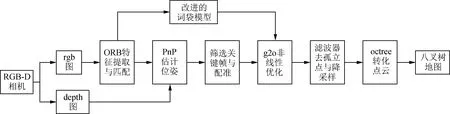
图1 RGB-D SLAM算法框架
2 算法流程
2.1 特征提取与匹配
每一帧640像素×480像素图像产生约30万个空间点[12],若直接使用整帧图像点,会因数据规模过大而导致算法速度变慢、实时性减弱。因此,需要提取点特征,以减小计算量。
采用oriented fast and rotated brief(ORB)特征点。ORB特征点通过Oriented FAST检测特征与Steer BRIEF描述,能保证特征点具有良好的旋转不变性与尺度不变性[13]。且ORB特征点具有提取速度快、匹配能力较好等优点。
点特征提取后,采用快速近似最近邻(fast library for approximate nearest neighbors,FLANN)算法,结合随机抽样一致性算法进行匹配。快速近似最近邻适用于高维数据的匹配[14]。随机抽样一致性算法(random sample consensus,RANSAC)基于迭代的思想,在每次迭代过程中随机从三维坐标点对中小规模采样,计算出变换模型,然后比较全局与该模型,得到满足该模型的内点集合,重新求变换模型[15-16]。随机抽样一致性算法用于剔除误匹配点。
2.2 位姿估计与优化
完成相邻帧间的匹配后,需要求解相邻帧间的变换矩阵。该变换矩阵T由一个旋转矩阵R和平移矩阵t组成,即
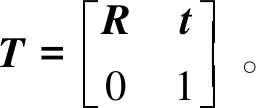
(1)
深度相机所输出的图像中,一帧图像的特征点三维坐标可以直接由depth图确定。在这种情况下,Perspective-n-Point(PnP)算法只需3对点就可以计算相机的运动,大大减小了计算量。故本文采用PnP算法计算变换矩阵T。
随时间推移,算法产生的误差不断堆积,这就需要回环检测减少堆积的误差。本文提出一种改进的词袋模型,其算法流程如下。
(1)随机选取n个中心点,且确定一个阈值。
(2)对每一个特征,计算它与各个中心点间的距离,取最小的作为该特征的类。
(3)计算每个类新的中心点。
(4)迭代(2)、(3)步,直到每个特征与它的类中心点的距离小于阈值。
(5)设置节点权重,并计算Ddistance。
词典生成后,使用K叉树表达,如图2所示,步骤如下。
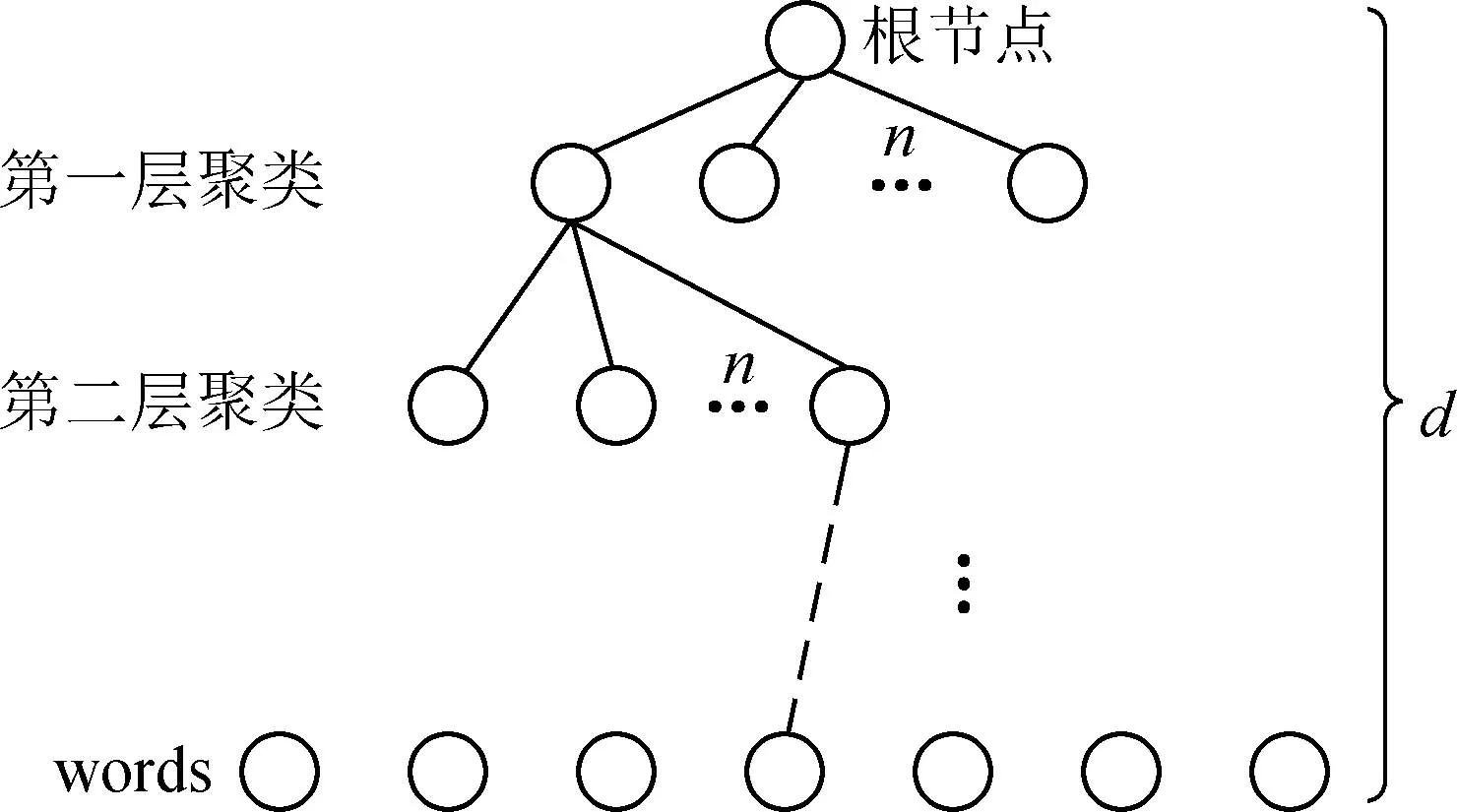
图2 K叉树
(1)对根节点用上述聚类方法将特征聚成n类,得到第一层。
(2)对每一层的n个节点,再聚类成n类,得到下一层。
(3)重复(2),最后得到叶子层,即words。
使用Term Frequency-Inverse Document Frequency(TF-IDF)计算节点权重,即
(2)
式中:ηi为某叶子节点wi的权重;ni为wi中的特
征数量;n为所有特征数量。
选择权重最大的两个节点ai与bi,计算两个节点间的距离,即
(3)
节点权重与节点距离Ddistance组合,形成词袋模型(Bag-of-Words),即
Bag-of-words={(w1,η1),(w2,η2),…,(wn,ηn),Ddistance}≜v。
(4)
使用L1范数形式计算相似度s,即
(5)
式中:s(vA-vB)为图像A与B的相似度;Ai为图像A的Bag-of-Words中节点;Bi为图像B的Bag-of-Words中节点。
2.3 位姿图优化
采用图优化的方法对整个位姿图进行优化。图优化方法中,图的定义是点和边的集合,点代表优化变量,边代表误差项[17]。在SLAM问题中,位置图的点是每个时刻相机的位置,边是不同时刻相机的位置变换关系。本文使用g2o求解位姿图。该方法将位姿图优化问题转化为非线性最小二乘法问题。在SLAM问题中,求解相机最优位姿x*。如式(6)所示,目标函数F(x)定义为
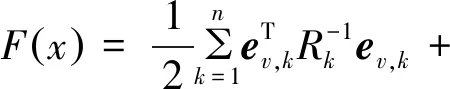
(6)
(7)
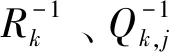
(8)
式中:xk为k时刻所处的位置;uk为k时刻传感器的输入;zk,j为k时刻j路标的观测值;yj为路标j。
2)课程服务于在校学生、中山及周边通信企业,以岗位需求和职业发展为导向,注重职业能力培养,参考通信工程师职业资格标准,以运营商商用设备为基础,以真实工作任务和工作过程为载体,并结合知识的认知规律和学生的学习特点构建基于工作过程系统化的教学任务。
2.4 八叉树地图
采用统计滤波器方法去除孤立点,再使用体素滤波器降采样处理庞大的点云数据。考虑到后续导航等需求,选择将处理后的点云存入octree提供的点云结构中,通过转化,输出八叉树地图。八叉树,如图3所示,是很多体素表达空间三维模型,将体素不断均分成8个小体素,直到最小的体素满足要求的精度[18]。在八叉树地图中,每个节点都存储了该节点是否被占据的概率,P(n)为节点n的占据概率,取[0,1],使用概率对数值logit(n)描述,即

图3 八叉树示意图
(9)
其反变换为
(10)
由式(9)可知,logit(n)从-∞到+∞时,P(n)从0到1。当不断观测到节点n被占据时,logit(n)增加1,反之则减小1,再求出P(n)。对于t时刻,节点n的观测数据为z,概率对数值为logit(n|z1:t),t+1时刻为
logit(n|z1:t+1)=logit(n|z1:t-1)+
logit(n|zt),
(11)
则相应的概率形式为
(12)
式中,P(n)为节点n的先验概率,通常取0.5。选择合适的阈值,当节点所对应的概率大于阈值时,认为该节点为占据状态,反之,则为是空闲状态。
3 结果与分析
使用传统的词袋模型与改进的词袋模型进行相似度对比实验,传统的词袋模型即DBoW2库,该库已集成引言中提及的词袋模型成果。通过kinect v1相机在数控车床实验室拍摄12 000张图像,做成数据集,然后使用该数据集对词袋字典进行训练,图4(a)所示为训练的图像。改进的词袋模型训练生成K=10,L=8,单词数4 704 257的字典;原始的词袋模型训练生成K=10,L=8,单词数4 015 782的字典。然后对如图4(b)所示的5张图像进行相似度计算,相似度取[0,1],完全一样时的相似度为1,完全不同时的相似度为0,结果如表1~2所示。

图4 训练与实验图像

表1 传统的词袋模型实验结果
由表1~2实验结果可知,传统的词袋模型中,图像2和5的相似度高达0.575 98,图像3和6的相似度高达0.349 599,改进后的词袋模型中,图像2和5的相似度为0.423 769,图像3和6的相似度为0.308 652,均有显著下降,说明改进的词袋模型相似度计算精度更高、效果更好,表明改进的词袋模型有较好的实际应用价值。
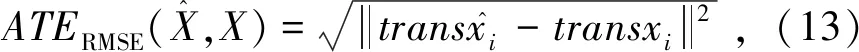
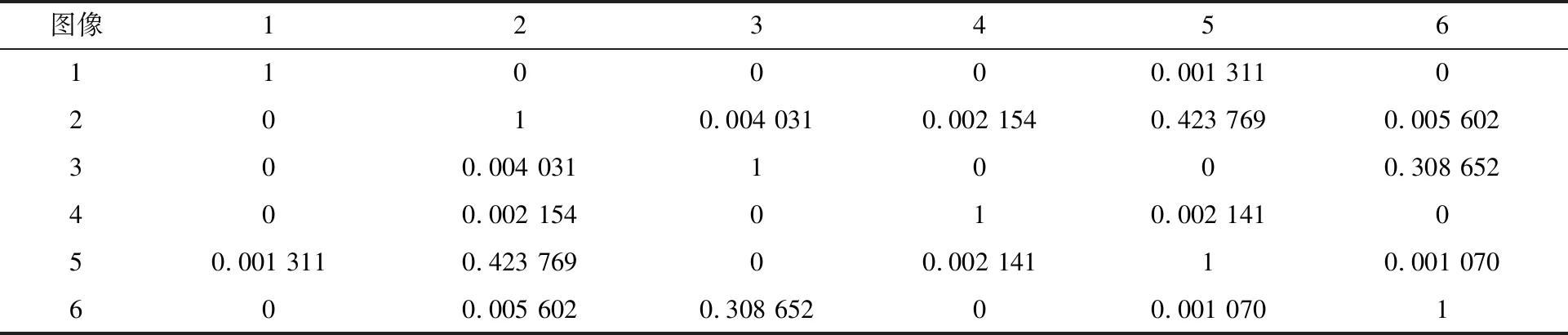
表2 改进的词袋模型实验结果
rgbd_dataset_freiburg1_xyz数据集的实验结果如表3和图5所示,平均每帧处理时间为0.066 s。

表3 rgbd_dataset_freiburg1_xyz位姿估计(部分)
图5中的蓝色曲线为本文算法估计出的轨迹,红色曲线为数据集自带的标准轨迹。由图5可知,本文算法对于该数据集表现良好,误差较小,由表3数据可以求得ATERMSE,为0.076 7 m。
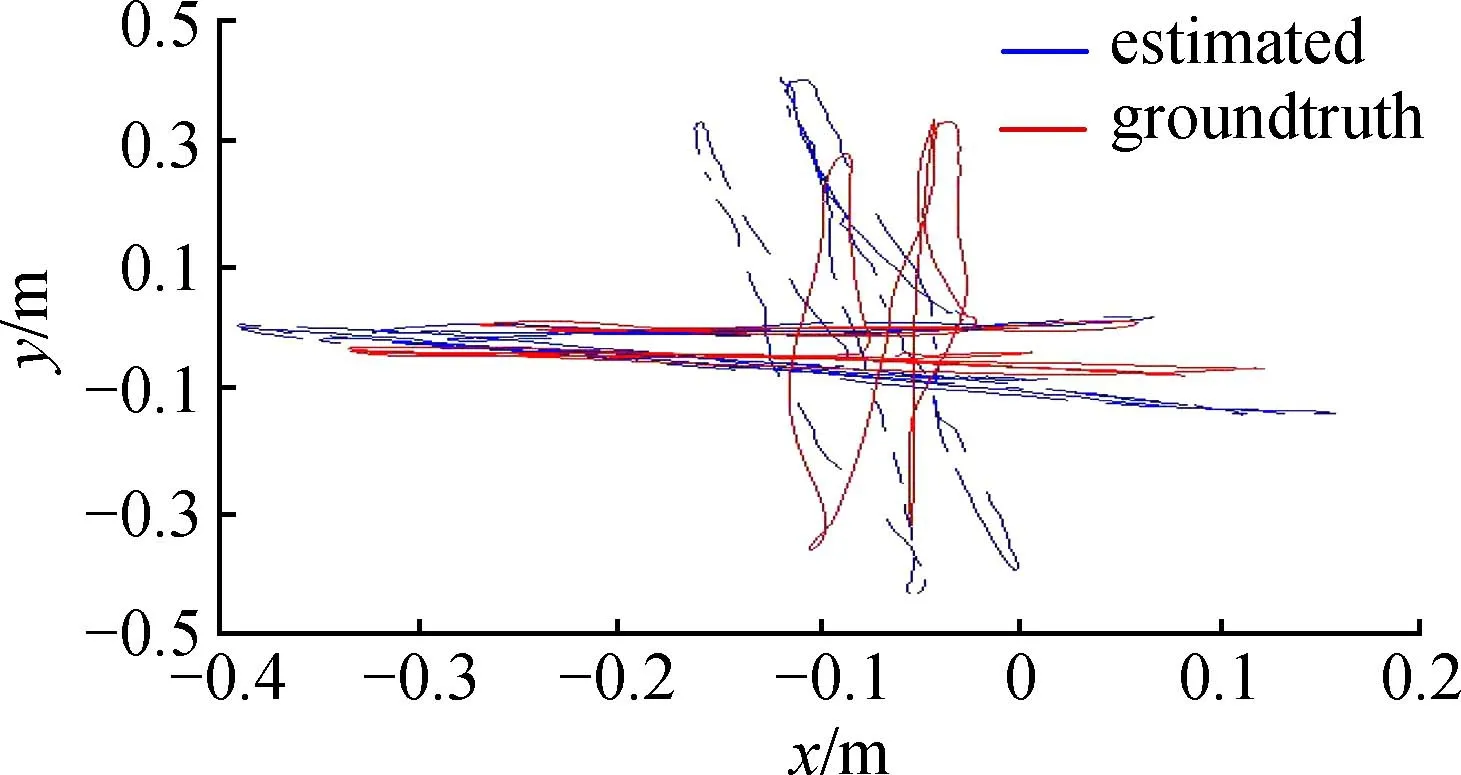
图5 xyz数据集估计轨迹与标准轨迹对比
rgbd_dataset_freiburg1_desk数据集的实验结果如表4、图6所示,平均每帧的处理时间为0.118 s。
图6中,蓝色曲线为本文算法的估计轨迹,红色曲线为数据集自带的标准轨迹。由图6可知,本文算法对该数据集表现一般,由表4数据可以求得ATERMSE,为0.261 3 m。
表4 rgbd_dataset_freiburg1_desk位姿估计(部分)
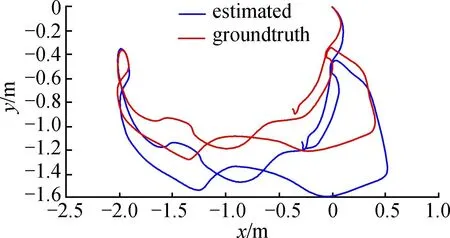
图6 desk数据集估计轨迹与标准轨迹对比
rgbd_dataset_freiburg1_360数据集的实验结果表5和图7所示,平均每帧图像实际处理时间为0.050 s。
图7中,蓝色曲线为本文算法计算出的估计轨迹,红色曲线为数据集自带的标准轨迹。由图7可知,本文算法在周围环境有回环存在的情况下,表现良好,能与标准轨迹基本一致。由表5数据可求ATERMSE,为0.091 3 m。
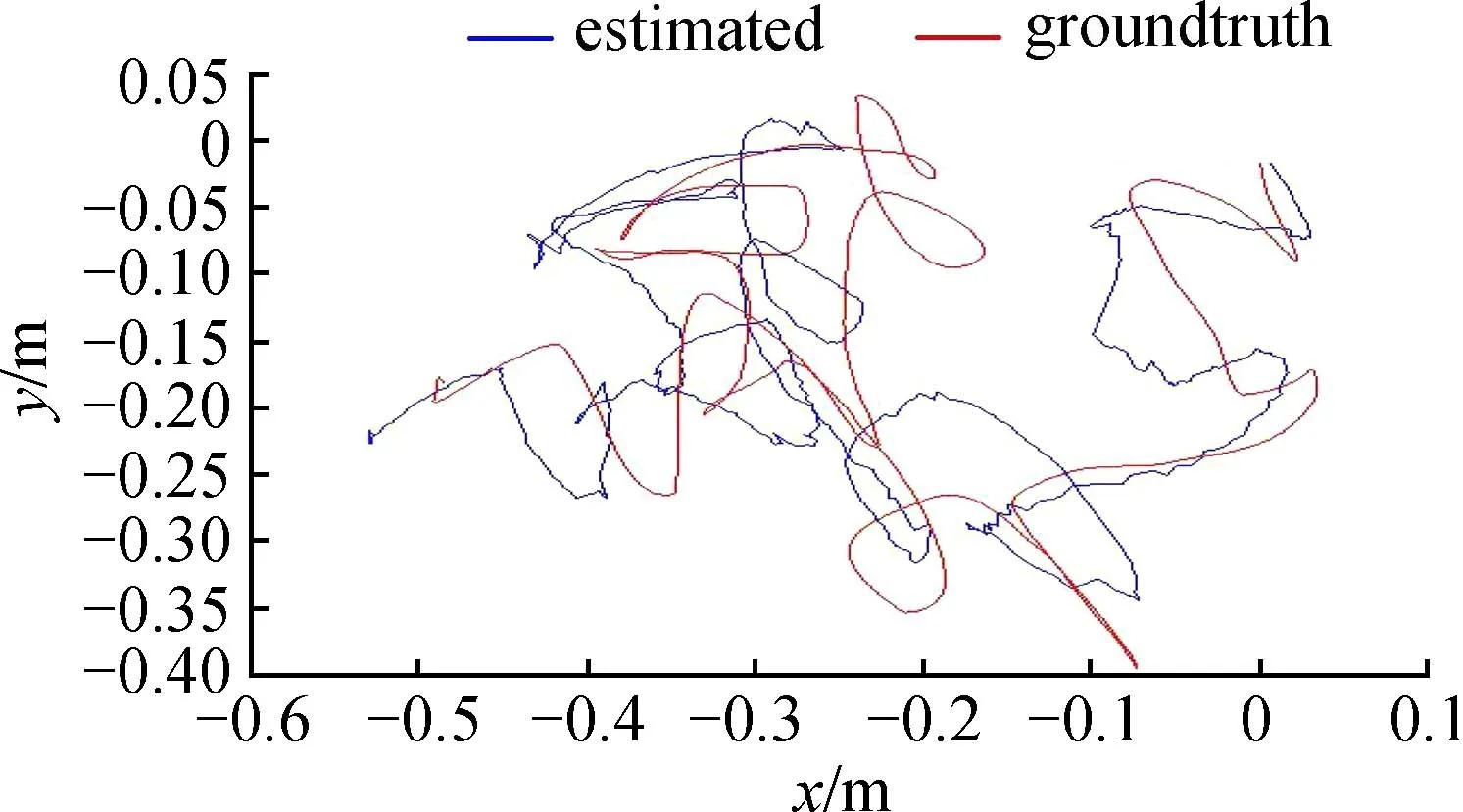
图7 360数据集估计轨迹与标准轨迹对比
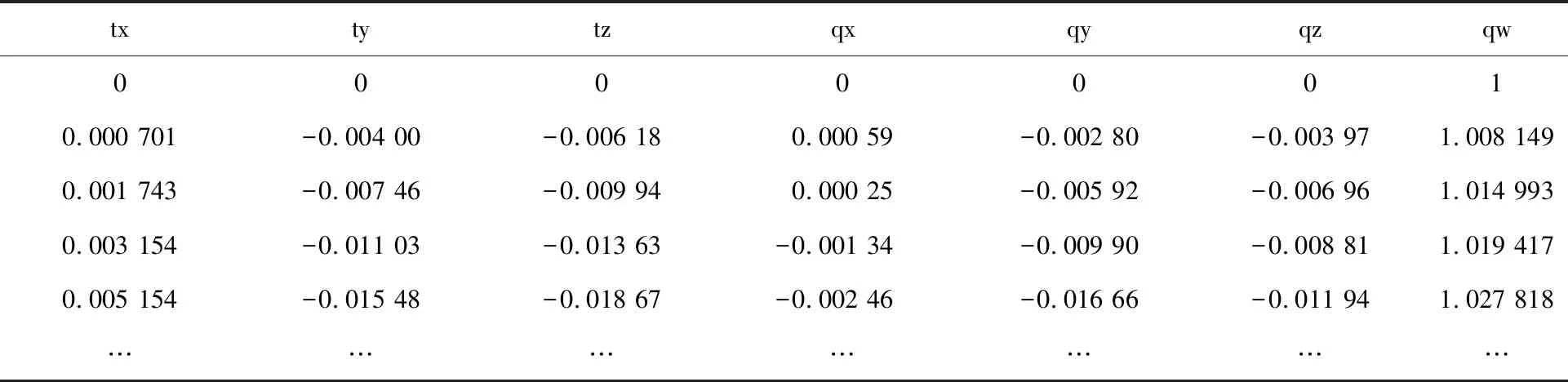
表5 rgbd_dataset_freiburg1_360位姿估计(部分)
结合这3个数据集的仿真实验数据,综合分析可知,本文算法在相机运动较慢或者环境存在回环的情况下,效果良好,误差较小,为0.076 7 m和0.091 3 m;在相机运动较快的情况下,效果较差,误差较大,为0.261 3 m。
与使用传统词袋模型的本文算法和开源算法DVO SLAM、LSD-SLAM进行对比实验,结果如表6所示。
由表6分析可知,本文算法在周围环境有回环时,精度比两种开源算法和本文使用原始词袋模型算法高,表现好;在相机运动较慢时,精度比LSD-SLAM高,比DVO SLAM低,表现较好;在相机运动较快时,精度比两种开源算法低,表现差。
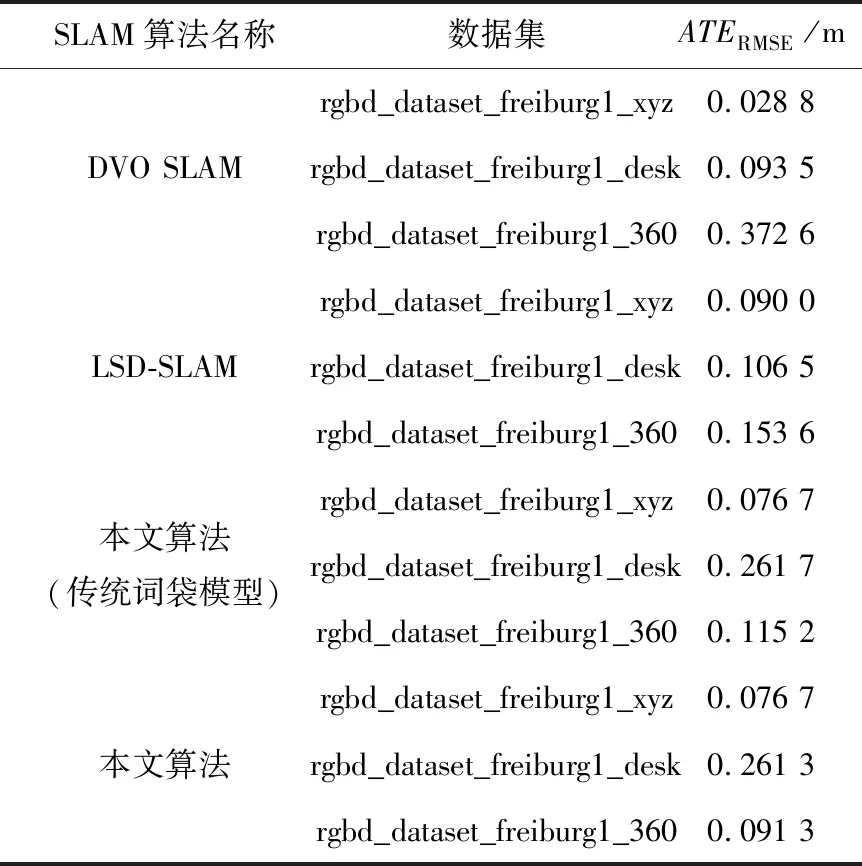
表6 不同算法实验结果对比
在数控车床实验室进行测试。实验室环境如图8所示,实验设备为Kinect V1相机、I5-7300 CPU笔记本电脑。实地测试结果如图9所示。图9(a)为本文算法所输出的数控车床实验室室内环境八叉树地图,图9(b)为相机的估计轨迹。由图9可知,本文的算法实用性较高,能满足后续的导航要求。

图8 数控车床实验室室内环境
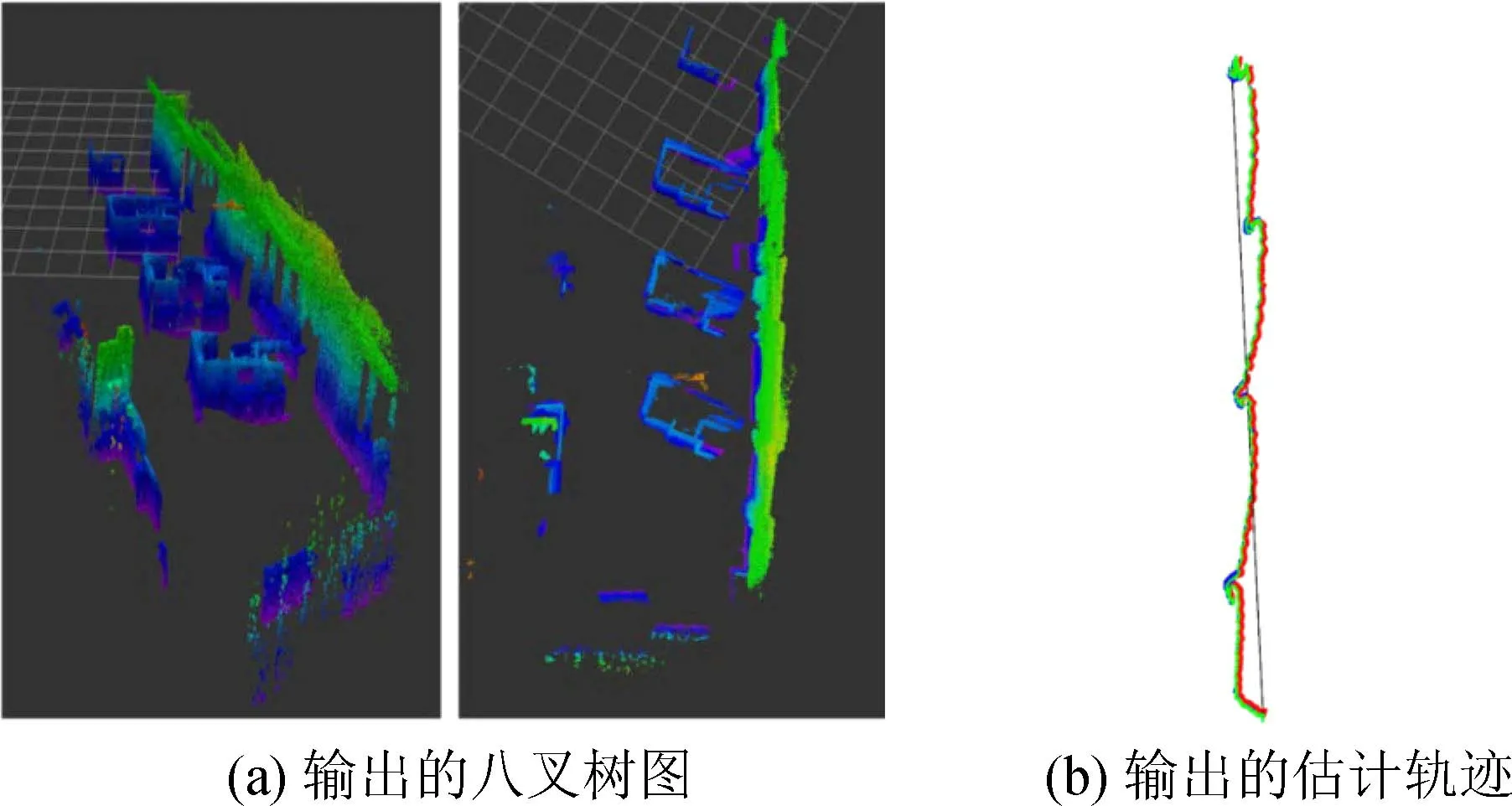
图9 数控车床实验室实验结果
4 结 语
针对室内环境下视觉SLAM精度不高和实用性较差等问题,对传统词袋模型进行改进,增加了一个节点距离,提出了一种基于改进词袋模型的室内无源自然信标RGB-D SLAM算法,并进行了传统词袋模型与改进词袋模型的对比实验、基于TUM数据集的精度实验和实地测试。词袋模型的对比实验结果显示,改进的词袋模型在相似度计算上更优。精度实验结果显示本文算法在环境有回环和相机运动较慢的情况下表现较好,对室内环境适应性好。实地测试结果显示本文算法实用性较高,为后续的导航奠定了较好的基础,但当相机运动较快时,本文算法表现一般,误差较大,因此,需要进一步探究。
