组合导航辅助的激光雷达-相机实时语义建图∗
2021-06-16张乐翔刘天弋张提升牛小骥
张乐翔刘天弋张提升牛小骥
(武汉大学卫星导航定位技术研究中心,湖北 武汉430079)
机器人为了执行一些复杂的任务,需要能够利用环境中语义信息,构建包含语义信息的地图称为语义地图。当前大多数激光雷达语义建图都是使用64线或者128线激光雷达[1-2],然而64线和128线激光雷达价格过于昂贵,以Velodyne的产品为例,每台高达几十万甚至上百万人民币。16线激光雷达则相对便宜得多,单台采购价只有两三万人民币,然而16线激光雷达由于其点云过于稀疏,难以提取其点云的语义特征。普通光学相机价格低廉且具有丰富的纹理数据,前人研究图像语义信息提取也比较成熟[3-5],但其无法提供和激光雷达测距相当水平的高精度深度信息。因此,用图像来辅助稀疏点云进行语义信息提取并构建语义地图既可以保证地图品质也可以降低成本。
文章[6]提出了一种相机辅助单线激光雷达语义建图的方法,其只对二维点云进行聚类并与目标检测框相匹配,该方法并不适用于多线激光雷达获得的三维点云,且其不能实时生成语义点云地图,限制了机器人根据实时的语义信息进行导航定位。文章[7]中提出了一种激光雷达-相机融合的方法,先将点云聚类并投影到图像上,并根据聚类点云框和图像目标检测框的比例关系,来判断点云和图像是否成功匹配。该方法比较适合在开阔场景下使用,但当目标检测框出现偏差以及目标物体前方有局部遮挡或后方有杂乱背景时则容易出现误提取。
本文提出了一种组合导航辅助的激光雷达-相机语义建图方案,利用GNSS/INS组合导航提供的位置和姿态信息辅助点云运动补偿、异步采样的点云-图像配准以及构建地图,使得16线激光雷达-相机系统能够在保持较低成本的前提下准确、鲁棒地提取出点云所对应的语义信息并实时构建语义地图,为移动机器人利用语义信息进行导航和执行任务奠定基础。
1 系统设计
本文的移动机器人平台是基于ROS(Robot Operating System)架构,以各个模块/传感器为节点,采用ROS消息的形式通信。
该机器人硬件平台由英伟达公司生产的核心处理器Jetson AGX Xavier、自主研制的组合导航模块[8]、Velodyne公司生产的VLP-16激光雷达、AVT Mako G-131彩色相机以及Autolabor底盘组成。VLP-16激光雷达内部的激光发射器和接收器根据设定的扫描频率在水平方向旋转,旋转速度5 Hz~20 Hz,其水平视场(FOV)为360°,垂直视场为30°,测量距离范围可以达到100 m。本文选取10 Hz扫描速率,对应的水平角分辨率为0.2°,垂直角分辨率为2°。AVT相机为分辨率1280×1204的RGB相机,其最高帧率可达62 Hz,镜头焦距为4 mm。为了与激光雷达扫描速率相一致,选取相机帧率为10 Hz。
核心处理器Xavier可通过串口接收机器人底盘的里程计编码数据和自研组合导航模块的GNSS(Global Navigation Satellite System)、IMU(Inertial Measurement Unit)数据,并通过4G网络接收GNSS信号差分改正信号进行RTK(Real-time kinematic,实时动态)定位。VLP-16激光雷达和AVT相机则通过千兆网线将图像和点云数据传输至处理器Xavier进行融合。机器人系统数据传输结构如图1所示。
多个传感器之间时间和空间关系是多传感器融合系统设计必须考虑的因素。本文利用组合导航模块输出的PPS(秒脉冲)来修正单片机本地晶振误差漂移,并用单片机触发其他传感器采集或接收其他传感器采集返回脉冲信号,从而将多个传感器信号时间统一到卫星时钟基准下,确保其时间的一致性[8]。由于时间差异会导致所处的空间位置不同,对系统时间同步精度的要求主要取决于载体的速度,在机器人系统中其速度约为2 m/s,故时间同步精度在毫秒量级即可。对于VLP-16激光雷达,其有PPS接口,输入PPS后可在激光数据对应的头文件中解码获取卫星时间系统下的点云采集时刻;对于相机,其在曝光时硬件会返回一个触发脉冲,用组合导航模块中卫星时钟基准下的单片机记录触发曝光脉冲时刻及曝光结束脉冲返回时刻。单片机记录延时是微秒量级的,其记录的时间的延时对于测量数据可以近似为无影响,由于本文实验中相机曝光时长很短,在毫秒级别,因此将相机曝光中间时刻作为相机曝光时刻。

图1 机器人系统数据传输结构
关于激光雷达、相机和组合导航系统间的空间标定,主要是要求解激光雷达、相机和IMU的外参,包括旋转矩阵和平移向量。本文使用Autoware自动驾驶平台的标定工具[9-10]来标定16线激光雷达和相机;激光和IMU的标定本文使用了文献[11]的方法;相机和IMU间的标定本文使用了Kalibr标定工具[12]。
为了能够利用语义信息进行导航和实时执行任务,需要保证语义信息提取和建图的实时性。本文在设计结构上采取了实时方案,如图2所示。程序分为传感器采集模块、定位定姿模块和激光雷达-相机融合模块,保障了各个模块工作的独立性和运行效率。将不同的传感器用不同的线程采集数据并放入全局缓冲区,从缓冲区中按时间顺序将同一时刻的GNSS、IMU、里程计数据输入实时组合导航线程中进行融合定位解算,并将融合定位结果和缓冲区中的点云、图像输入到激光雷达-相机融合线程中进行融合。
在融合模块中,为了在结构上减少算法耗时,将点云处理和图像处理用独立的两个线程进行,如图3所示。虽然激光雷达和相机的采集频率同为10 Hz,但其开始采样的时刻却不能保证是同一时刻,故需要将点云对图像进行配准,使点云和图像为同一时刻的数据才能进行融合。而点云在采集过程中由于载体运动导致畸变,需要对点云进行矫正。在图像数据到来后,将运动补偿后的点云从其采样时刻转换到图像数据采集时刻,并对投影到图像部分的点云进行快速地面分割和点云聚类;同时,对图像数据进行畸变校正和目标检测;最后再将这两个线程的输出结果融合,输出带语义信息的点云簇。
本文的设计结构可以避免某些模块因突发情况计算耗时过长而导致传感器数据丢失或数据处理失败,保证多传感器融合的实时性和鲁棒性。

图2 系统算法结构图

图3 点云-图像融合算法结构图
2 关键技术
2.1 点云-图像配准
受机器人载体运动特性影响,在进行点云、图像融合时会面临两个问题:①激光雷达采样间隔内扫描得到的一帧点云存在一定程度的运动畸变[13];②点云和图像的采样时间不一致会导致点云不能准确地投影到图像上。为了解决上述问题,本文提出了一种在不同采集时刻下基于组合导航辅助的点云-图像精确配准方法。
组合导航算法输出位置为IMU在当地导航坐标系(N系)下的纬度、经度和高程,先将其转换成以起始点为原点的站心系(L系)位置和姿态,表示为:
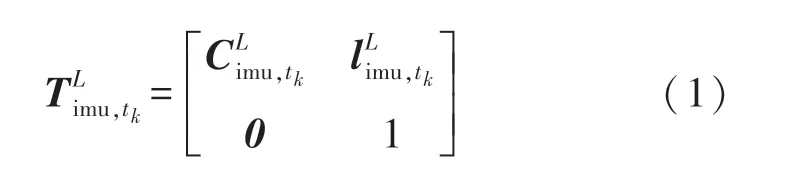

更新点云Plidar,tn转换到tk时刻的激光雷达处

为了保持符号的简洁,在不引起歧义的情况下,以后不区别齐次坐标与普通坐标符号,默认使用的是符合运算法则的那一种。则式(3)可以简写为
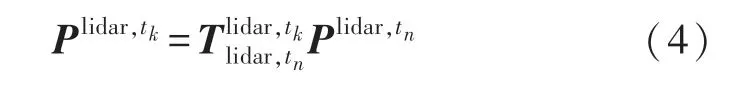
接收一帧点云数据是一个持续的过程,故在本文中将先接收到的点云转换到当前点云帧起始时刻tstart,待全部数据到来之后再将其转换到当前点云帧结束时刻tend,如图4所示。

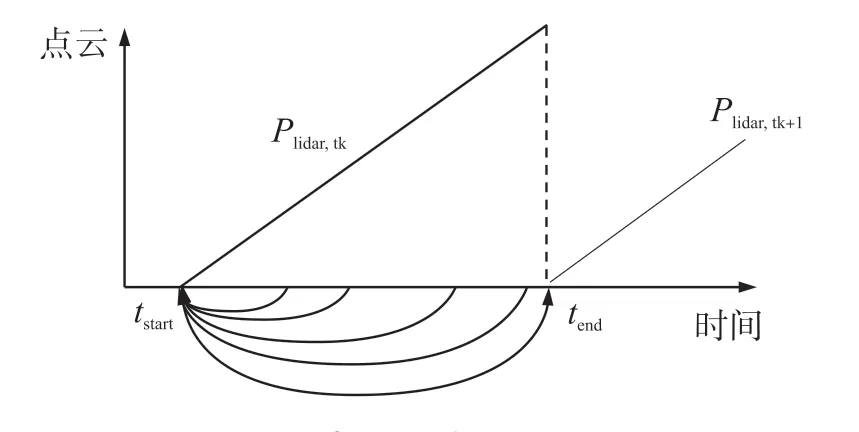
图4 点云运动补偿原理
同时,由于机器人载体运动的特性以及点云、图像之间采样时刻的不一致,会导致点云投影到图像出现一定的偏差,特别是在机器人速度较快时,影响尤为明显。譬如机器人以90°/s的角速度急转弯时,点云-图像配准角度误差最大可达9°。令点云、图像采样时刻分别为tl和tc,将组合导航位姿线性内插得到对应时刻的和,则

再将点云投影到图像上,即可完成点云-图像的精确配准。

式中:u、v为点云投影在图像上的像素坐标,K为相机的内参数矩阵,由相机内参标定得到。
2.2 目标语义点云提取
目标语义点云提取是语义建图的难点,本文提出的语义点云思路如图5所示。

图5 点云语义信息提取原理图
首先,将原始图像数据和原始点云数据根据上述方法进行精确配准得到像素坐标表示的点云,如图6(a)。其次,使用RANSAC算法对配准好的点云进行快速的地面分割[14],将非地面点云进行聚类,排除离散点干扰,如图6(b)。再次,利用YOLOv3神经网络[5]获取图像中目标检测框的像素坐标,如图6(c)。最后,筛选出检测框内的带有目标语义信息的点云,如图6(d)。

图6 点云语义提取步骤
利用VLP-16激光雷达的特性本文采用Igor Bogoslavskyi等人提出的快速分割算法[15],对除去地面的点云分割聚类,其原理如图7所示。

图7 点云快速分割算法原理

式中:d1为较长的激光束,d2为较短的激光束,α为两条激光束间夹角,对于Velodyne16线激光雷达在其采样频率为10 Hz时,垂直方向夹角为2°,水平方向夹角为0.2°。若计算得到的β角度大于一定阈值,我们则认为其不是同一个类别的物体。
从目标检测框中提取对应目标的语义点云存在以下三个难点:①目标检测框一般比目标物体更大,所以不单单包含目标语义点云还会包含其背景的点云,如图8(a);②图像目标检测结果以及激光雷达和相机的外参标定存在一定程度上的误差,导致检测框不能完全包含目标物体的全部点云,如图8(b);③被检测物体前方有部分遮挡,如图8(c)。

图8 难以提取语义点云的情况
图8中距离较近的点云对应为图8(a)、图8(b)中行人和图8(c)中电线杆,较远的点云对应图8(a)、图8(b)中房屋和图8(c)中行人,而我们需要的只是类别为行人的点云,必须排除其他物体点云的干扰。为了准确提取目标的语义点云即需要排除背景点云和前方障碍物点云的干扰,并把检测框外的目标点云恢复,本文提出了一种从图像目标检测框中提取出对应语义信息点云簇的方法,分为背景点云去除、框内点云判断和语义点云生长三个步骤。
第一步背景点云去除目的为去除聚类后背景点云对检测框内点云提取的干扰,如图8。将上述分割好且带有不同类别标签和像素坐标的点云Pl中的每个点根据是否在某个特定语义的目标检测框内外分类,令pli∈Pl,若pli在目标检测框内则将其存入代表语义目标点云的Pi,否则存入代表背景点云的Po。对背景点云Po针对其类别对应的点云点数进行排序,将背景点云Po中点数最多的numback个类别的标签存在Lo中,其中numback为

式中:numlabel为点云聚类得到的总类别数,numbox为当前帧点云对应的目标检测框个数,s为一根据实际环境决定的固定常数,本文中取5。
第二步框内点云判断是为了找到检测框对应的语义点云聚类的类别。对语义目标点云Pi按点云点数对其类别进行排序,得到该目标检测框中点数前二的标签lmax1、lmax2且保证lmax1、lmax2∉Lo。计算得到lmax1、lmax2对应的点云点数nmax1、nmax2和平均距离dmax1、dmax2,根据点数和距离判断得到最优的类别标签lres。
第三步点云生长是为了恢复出检测框外的语义点云,从而完整地提取该语义信息对应的语义点云。从Pl中提取出所有标签为lres的点云,即可完整的恢复出该目标检测框语义信息对应的点云Pres。其伪代码如图9所示。

图9 目标检测框提取点云伪代码
3 实验
在校园环境基于机器人平台采集数据,并在嵌入式处理器Jetson AGX Xavier上对本文方法进行测试。Xavier为8核ARM v8.2、64位的CPU,包含64个Tensor核的512核Volta GPU。以下测试结果如未特殊说明,则均为上述条件和场景下进行的。为了验证语义点云提取的准确性和语义建图的实时性和建图效果,进行了如下实验测试。
3.1 语义点云提取评估
在移动机器人平台上进行测试评估,数据一语义目标均为静止情况,数据二部分语义目标有遮挡情况,如图8(c),数据三语义目标也是运动的情况。定义语义点云类别提取成功率为正确提取目标检测框中点云类别次数占该目标检测框出现总次数的百分比,表1给出了三组数据中语义点云类别提取成功率。

表1 目标检测框中语义点云类别提取成功率
由此可见,在语义目标有遮挡情况下本文方法相较于论文[7]方法优势明显,其他情况时也有所改善,总体来看行人和汽车语义点云类别提取成功率分别提高了11.30%和2.38%,均达到90%以上。
表2给出了在进行点云-图像配准和目标语义点云提取改进前后的语义点云提取准确率对比。在图像目标检测的结果为正确的前提下,令从目标检测框中正确提取得到的语义点云数为Numac,激光雷达扫到目标物体的真实点云数为Numobj,即单帧点云语义目标提取准确率为Numseg/Numobj的百分比。值得注意的是,若出现检测框中点云被错误提取,则计Numac为0。
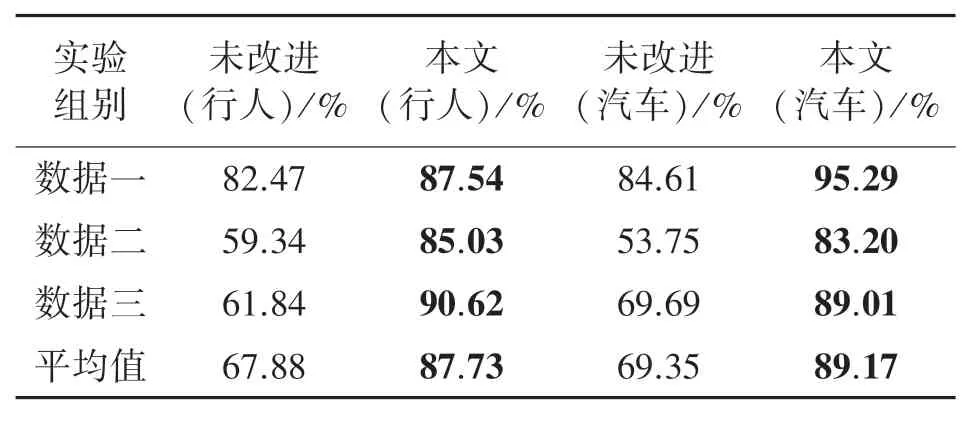
表2 语义点云提取准确率
表2可以看出,语义点云提取准确率在数据二和数据三得到较大改善,总体准确率提高了约20%,均达到85%以上。其准确率提高的原因为对检测框内语义类别提取和点云-图像配准更加准确,具体场景如图10所示。

图10 语义点云提取结果图
图10右边表示的为当目标检测结果不够准确和有较多背景干扰的情况;左边表示的为前方有障碍物干扰的情况。对于这几种特殊情况,本文提出的方法能很好的提取目标语义点云。
3.2 实时性测试
分别在电脑和嵌入式处理器Xavier测试算法耗时,电脑配置为4核3.4G Hz i5-7500 CPU,NVIDIA GeForce GTX 1050的GPU。整体算法耗时如图11所示。

图11 算法耗时测试
各个模块及总耗时如表3所示。其中组合导航部分包括GNSS、INS以及里程计的融合定位定姿,点云运动补偿部分包含点云运动畸变补偿和点云时刻投影到图像时刻,点云预处理部分包含点云投影成图像、点云地面分割以及聚类,融合建图部分包含从目标检测框中提取语义点云和构建语义地图。总耗时为从接收到点云开始到生成语义点云地图所花费的时间,其中包含了各个模块处理时间、各个传感器数据时序不一致导致的等待时间以及数据传输的时间。
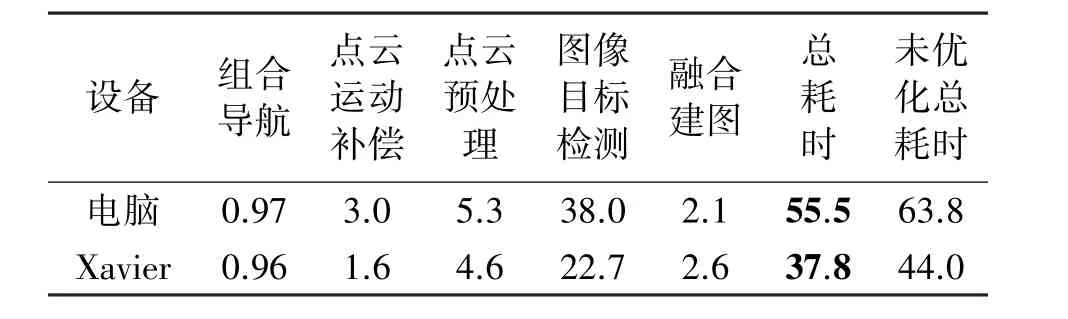
表3 各个模块用时 单位:ms
由于本文采用了图2、图3的算法设计模式,可以在进行图像数据处理的同时进行点图配准和地面分割、点云聚类等点云处理,对于电脑来说提速13.0%,对Xavier处理器来说提速14.1%。在图11中有少数情况处理耗时超过100 ms,但由于模块间缓冲区的设计可以保证数据不会丢失。该结果表明本文所设计的语义建图算法无论在电脑还是嵌入式处理器Xavier上都能保证在激光雷达采集周期内计算完成。
3.3 移动机器人语义建图
为了验证语义建图的性能,本文在开阔环境下进行实时语义建图,如图12所示。

图12 语义建图测试场地
图13和图14表示改进前后语义建图的整体效果对比,图15、图16分别代表图13、图14中处的具体场景对比效果,上方为改进前的效果,下方为改进后的效果,箭头指向为改进效果比较明显的部分。处表示的为地面点云,、处表示的是行人,处表示的是汽车。

图13 改进前移动机器人平台实时语义建图效果

图14 改进后移动机器人平台实时语义建图效果

图15 改进前后处语义建图效果对比

图16 改进前后处语义建图效果对比
对比图13~图16可以发现在处改进后对行人的语义点云提取准确率明显提高。结果表明,在进行点云-图像配准和目标语义点云提取改进后,语义点云提取的准确率得到提高,构建的语义地图更加准确。
4 结论
本文提出了一种成本低、鲁棒性强、实时性好的激光雷达-相机实时语义建图的方案。该方案通过组合导航的位姿信息将16线稀疏激光点云和相机图像配准融合,准确地从目标检测框中提取语义点云,并在移动机器人平台上实时构建点云地图。实验结果表明,本文提出的方法能很好的融合稀疏点云和相机图像,在移动载体上对复杂环境下行人和汽车的点云类别提取成功率分别提高了12.51%和2.38%,均达到90%以上;改进后点云提取准确率提高了约20%,均达到85%以上,使系统语义点云提取的鲁棒性得到提高。在电脑和嵌入式处理器Xavier上耗时分别为55.5 ms和37.8 ms,均能达到10 Hz频率的实时处理。
本文提出的方法可以应用于剔除建图中动态物体,包括周围的车辆、行人以及控制机器人建图的操作人员等;也可以利用语义信息进行导航定位,或在场景中搜寻某个特定语义目标执行特定任务。本文提出的低成本、鲁棒性强、实时性好的语义建图方案为机器人根据语义点云来进行导航定位和实施多种智能任务奠定了基础。
