改进生成对抗网络的图像超分辨率重建算法
2021-06-16陈波翁谦叶少珍
陈波, 翁谦, 叶少珍, 2
(1. 福州大学数学与计算机科学学院, 福建 福州 350108; 2. 福州大学智能制造仿真研究院, 福建 福州 350108)
0 引言
图像的超分辨率重建技术指的是将给定的低分辨率图像通过特定的算法恢复成相应的高分辨率图像. 数字图像的超分辨重建技术在现实生活中有着十分广阔的应用前景, 例如在互联网通信、 医疗成像、 遥感成像、 图像视频处理等方面都有着十分重大的意义. 在实际应用中, 受限于成像设备硬件制约、 视频图像传输带宽, 抑或是成像模态本身的技术瓶颈, 并不是每一次都有条件获得边缘锐化、 无块状模糊的大尺寸高清图像. 目前获取高分辨率图像的方法主要分为硬件和软件层面.
硬件层面主要通过提升成像设备质量, 如增大光学相机口径、 增长相机焦距、 减小像元尺寸等, 但这种方式往往会带来制造难度加大、 成本上升、 信噪比降低等问题, 因此仅仅通过提升硬件技术是行不通的, 采用软件方法来获取高分辨率图像才是至关重要的研究方向. 根据不同的重建方法, 常见的超分辨率重建算法可以分为三类: 基于插值的超分辨率重建、 基于重构的超分辨率重建、 基于学习的超分辨率重建.
常见的插值法如文献[1]主要通过图像已知像素点拟合周围未知像素点的值, 该方法简单、 易于理解, 但重建的图像过于平滑, 在图像灰度剧烈变化处产生震荡, 丢失高频信息. 经典的基于学习的超分辨率重建方法如超分辨率卷积神经网络(SRCNN)[2], 使用一个三层的全卷积神经网络, 这三层卷积的结构可以解释为以下步骤: 图像块的提取及特征表示, 特征非线性映射和超分辨率图像的重建, SRCNN生成的图像效果优于传统的插值法, 但其网络结构简单, 在高倍超分辨率重建任务上效果较差.
文献[3]在2016年首次将生成对抗网络(generative adversarial networks, GAN)[3]模型应用于超分辨率重建领域, 并取得了十分优异的效果. 基于GAN的超分辨率重建算法(super-resolution reconstruction generative adversarial network, SRGAN)[4]是目前较为先进的一种基于学习的超分辨率重建算法, SRGAN生成的图像首次在4倍超分辨率重建任务上恢复出了清晰的纹理细节, 网络性能显著优于其他深度学习网络. 但由于GAN训练不稳定, 特征的传播在深层网络中失真情况较严重导致生成的高分辨率图像未能达到最佳, 因此SRGAN仍然有着巨大的提升空间. 本研究提出一种改进的SRGAN模型, 通过改进生成器和判别器的损失函数, 以保证GAN网络训练时的稳定性. 引入信息蒸馏块, 在提取图像浅层特征后, 通过堆叠多个信息蒸馏块增强了特征图在纹理处的有效信息, 一定程度上提升了生成器的生成性能, 从而生成更清晰、 更富细节的高分辨率图像.
1 SRGAN模型原理

图1 SRGAN模型原理图Fig.1 Schematic diagram of SRGAN mode
SRGAN是一种基于GAN模型来对图像进行超分辨重建的算法模型, 由生成器和判别器两个部分组成. 用ISR来表示SRGAN网络重建的超分辨率图像.IHR是一个高分辨率图像,ILR是IHR所对应的低分辨率图像, 由IHR通过降采样得到. 生成器网络用G来表示, 判别器网络用D来表示. SRGAN模型原理图如图1所示.
生成器通过输入ILR生成ISR, 并根据判别器的输出进行梯度调整, 通过最小化损失函数不断优化生成器的生成性能, 以提升ISR分辨率. 判别器本质上是一个二分类器, 正类为IHR, 负类为ISR. 采用交叉熵作为判别损失函数, 输出对应的分类概率, 输出范围为[0, 1]. 生成器的优化目标是使得判别器无法区分IHR和ISR, 判别器的优化目标是能够准确区分IHR和ISR, 二者处于一种博弈状态, 在博弈过程中, 生成器和判别器的性能都会随着训练提升, 最终达到纳什平衡状态.
除了使用GAN进行超分辨率重建之外, 还提出传统的超分辨率任务, 通常使用ISR和IHR的均方根误差(MSE)作为损失函数, 虽然通过这种优化目标可以取得很高的峰值信噪比(peak signal-to-noise ratio, PSNR), 但PSNR是基于像素级图像的差异来定义的, PSNR指标无法完全符合人眼视觉的感官效果. 因此基于MSE优化生成的图像在图像的纹理细节处往往表现的十分平滑, 缺乏高频细节, 生成的图像无法带来良好的视觉效果. 基于此, 提出一种基于视觉感知的损失函数——内容损失. 将ISR和IHR送入预训练好的VGG19[5]网络中进行特征提取, 然后计算提取的两个特征图之间的欧氏距离, 以此作为内容损失来衡量生成图像的视觉质量.
SRGAN虽然在超分辨重建方面具有优异的效果, 但仍存在两方面的问题: 1) SRGAN中生成器使用单层卷积来提取图像特征, 无法充分利用图像的浅层特征, 很大程度上限制了网络的表达能力, 降低了生成网络的生成性能; 2) SRGAN中的生成器和判别器是两种网络模型, 难以使生成器和判别器同时收敛, 导致生成器和判别器收敛于某个局部最优点, 而无法达到最佳性能, 存在训练不稳定的情况. 本研究以SRGAN为研究对象, 针对以上两个问题, 首先, 提出在生成器提取图像特征时, 通过信息蒸馏的方式获取更丰富的浅层图像特征并且消除特征中的冗余信息; 其次, 使用一种非分类器的鉴别器来取代SRGAN中的二分类鉴别器, 保证训练的稳定性并提高生成的图像质量.
2 基于SRGAN图像超分辨率重建改进算法
2.1 基于生成器的改进
2.1.1 去除BN层
在一个网络中使用BN[6]层不仅可以加速收敛, 还有一定的正则化效果, 可以防止模型过拟合. 因此BN在许多的分类任务中被大量使用. 然而对于图像超分辨任务来说, BN层的加入反而会导致训练不稳定, 影响网络输出质量. 这是由于图像在经过BN层后, 其色彩的分布都会被归一化, 破坏了图像原本的对比度信息. 而在图像超分辨网络训练的过程中, 又需要还原这些图像的对比度信息, 加大了训练难度, 所以BN是不适用于图像超分辨任务的. SRGAN使用SRResnet作为生成器, SRResnet中的级联残差块(residual block)[7]使用了大量的BN层, 本研究通过去除这些BN层以期达到减低网络训练难度, 提升网络输出质量的目标.
2.1.2 特征增强
SRResnet通过一层简单的卷积和池化进行特征提取, 这种做法无法充分地利用图像的浅层特征, 使得后续的网络表达能力受限. 因此, 本研究改进了SRGAN生成器的网络结构, 并且在提取图像特征的方式上, 采用了信息蒸馏的方式, 使用一个特征提取模块和多个堆叠的信息蒸馏块(information distillation block, IDB )[8]来对图像特征进行提取和蒸馏.

图2 增强单元网络Fig.2 Network of enhancement unit
特征提取模块从ILR中提取图像浅层特征, 包含两层3×3的卷积, 每层卷积之后连接着一层以Prelu函数[9]作为激活函数的激活层. 信息蒸馏块中包含增强单元和压缩单元两个部分. 增强单元用来增幅图像的浅层特征, 增加了特征通道数, 使特征具有更丰富的信息, 比如图像的细节纹理等, 详见图2. 而后, 将增强单元的输出送入压缩单元, 压缩单元是一层卷积核大小为1×1的卷积层, 用以压缩增强单元输出中的冗余信息, 减少网络的计算量. 在图2中,S代表图像通道之间的分割操作,P为图像通道之间的拼接操作. 增强单元包含两个卷积网络, 每个卷积网络包含三个卷积层, 每个卷积层后连接一个Prelu激活层. 增强单元的输入为特征提取模块提取到的浅层特征F.
F经过第一个三层卷积网络后得到短途(short-path)特征, 短途特征通过图像通道的分割操作后分为两部分: 增强短途路径特征Fboost和保留短途路径特征Fremain. 将第二个卷积网络的三层卷积和激活操作记为C,Fboost将会被送入第二个三层卷积网络得到长途特征.Fremain通过与F进行图像通道拼接, 生成局部短途特征. 将长途特征与局部短途特征融合作为增强单元的输出, 增强单元的输出Foutput可表示为如下公式:
Foutput=C(Fboost)+P(F,Fremain)
(1)
本研究改进后的生成器网络结构如图3所示. 其输入为一张低分辨率图像, 首先通过特征提取模块, 进行两次的卷积和激活操作, 获得提取到的浅层特征. 将提取到的浅层特征送入IDB中进行特征增强, 网络中堆叠了四个IDB, 上一个IDB的输出将作为下一个IDB的输入. 而后将增强过的图像特征输入残差块中, 通过N个残差块进行残差学习, 残差块的输出通过与浅层特征相加, 得到残差学习的结果. 残差学习的结果需要通过亚像素卷积层(sub-pixel convolution layers)[10]来增大特征尺寸, 增加图像分辨率. 每个亚像素卷积层都将特征尺寸放大为原先的两倍, 由于本研究分析的是4倍放大因子下的图像超分辨重建, 所以经过两层亚像素卷积层就可达到四倍放大的效果. 最后输出生成超分辨率图像ISR.

图3 本研究生成器的网络结构Fig.3 The network structure of our generator
2.2 基于判别器的改进
SRGAN中的生成器和判别器是两种网络模型, 可采用一种交替训练的方式来训练这两种模型. 当训练判别器时, 需要固定生成器的参数不进行更新, 以一个固定的生成器性能来训练判别器. 当判别器的性能达到一定程度后, 固定判别器的参数不更新, 以训练生成器. 这种交替训练的方式导致了训练的不稳定性, 即交替训练时, 无法得知何时该停止训练判别器转而训练生成器, 以及何时该停止训练生成器转而去训练判别器. 因此SRGAN在训练过程中经常出现生成器或判别器一方性能达到最佳, 而另一方性能却处于一个很差的状态. 相对判别器是一种解决GAN网络训练不稳定性的有效方法, 因此本研究基于Relativistic GAN[11], 用一种相对平均判别器(relativistic average discriminator, RaD)来替换SRGAN中的二分类判别器, 希望以此解决网络训练不稳定的问题.
SRGAN中的判别器可以被表示为D(x)=σ(C(x)),C(x)为判别器未经过sigmoid层的输出,σ为sigmoid函数, 判别器的输出最终都会通过sigmoid函数映射为一个大小在[0, 1]之间的数, 作为判定一张图像是真实样本的概率. 对应地, 可以将相对平均判别器定义为:
DRa(xr,xf)=σ(C(xr) -Exf[C(xf)])
(2)
其中:xr为参考图像;xf为生成器生成的图像xf=G(ILR), 称为伪造图像;Εxf表示在对一个批次(batch)内的所有伪造图像求均值. 根据相对判别器的定义, 分别修改SRGAN中对应生成器和判别器的损失函数, 因此SRGAN判别器的损失函数可根据平均判别器的定义修改为如下公式:
lRaD=-Exr[lg(DRa(xr,xf))]-Exf[lg(1-DRa(xf,xr))]
(3)
SRGAN中生成器的损失函数由内容损失(content_loss)和对抗性损失(adversarial loss)两部分组成, 通过一定的权重进行加权和得到生成器损失. 其中只有对抗性损失参与了训练过程中的梯度更新, 所以只需要改变对抗性损失的形式即可, SRGAN中原来的对抗损失为:

(4)
根据相对平均判别器的定义将其改为如下形式:
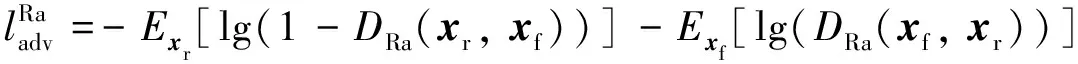
(5)
通过观察公式(4)可以发现, SRGAN中生成器的对抗损失在训练时所需要的梯度信息▽[-lg(D(xf))]来源于判别器对伪造样本xf的输出结果, 因此生成器的梯度信息只受到伪造样本xf变化的影响.而通过公式(5)可以看出, 改进后对抗损失的梯度信息受到参考图像xr和伪造图像xf二者的影响, 生成器从参考图像和伪造图像这二者中都能够得到梯度信息, 在训练过程中不会因为xf的变化而让梯度信息产生很大的波动. 因此使用相对平均判别器能够在很大程度上改善了SRGAN在训练过程中出现训练不稳定的情况.本研究所使用的判别器网络结构如图4所示.

图4 本研究判别器的网络结构Fig.4 The network structure of our discriminator
2.3 数据集及预处理
使用BSD100和SET14图像数据集作为本研究数据集. BSD100和SET14是常用于单图像超分辨率的数据集, 被用于单幅图像超分辨率重构, 即根据低分辨率图像重构出高分辨率图像以获取更多的细节信息.
对每个数据集, 各取40%的图像作为训练集, 其余60%的图像作为测试集. 训练集的图像包含两两对应的高分辨率图像和低分辨率图像. 低分辨率图像在初始的数据集中是不存在的, 需要对数据集的高分辨率数据进行降采样处理, 以得到相应的低分辨率图像. 在训练过程中, 低分辨率图像作为生成器的输入, 经由生成器生成超分辨率图像. 高分辨率图像作为目标图像, 是判别器判别生成的超分辨率图像质量的依据.
图像的降采样算法包括插值降采样法、 高斯金字塔降采样法. 插值降采样法又分为双线性插值法、 三次插值法、 最邻近插值法、 局部像素重采样法. 插值降采样法的一般做法为: 给定降采样后的图像的采样点个数, 然后使用不同的插值方式来对每个采样点进行数值填充就可以得到降采样后的图像. 高斯金字塔是自底向上的, 层数越高图像分辨率越小. 高斯金字塔每层降采样的过程分为两步, 首先对当前层进行高斯模糊, 对模糊后的图像删除当前层的偶数行与列, 即可得到上一层的图像. 因此自底向上, 每经过一层高斯金字塔, 图像经过一次2倍降采样, 采用局部像素重采样法作为本研究的降采样算法.
3 实验结果及性能评价
为了更加全面地对本研究所提方法的性能进行评价和分析, 除了与原始的SRGAN模型做比较之外, 还选择了另外两种常用和经典的超分辨重建方法进行比较, 分别为SRCNN、 Bicubic, 并在BSD100与SET14数据集上进行量化和质化评价.
3.1 量化评价
为了量化评估SRGAN与本研究方法在超分辨率重建任务上的效果, 以PSNR、 SSIM和生成器的内容损失(content loss)作为超分辨重建方法的衡量指标. PSNR基于两幅图像像素间的差异性, 提供了一种衡量两幅图像相似性的客观指标, 广泛应用于超分辨率重建图像质量的评价. SSIM结合图像的亮度、 对比度、 结构评估两幅图像的相似度, 是一种更加符合人类视觉系统的评价指标, 其值越大, 说明两张图像越相似, SSIM最大值为1. 内容损失基于两幅图像特征空间中的差异性, 衡量网络学习特征高层语义和结构信息能力, 网络学习到的高层语义和结构信息越多, 生成的图像越具有清晰的细节纹理, 视觉效果越好. 内容损失是一种反映图像视觉品质的指标, 生成器的内容损失越小, 代表生成器生成的图像具有更多的高频细节, 图像的视觉品质越好.
表1展示了SRGAN与本研究方法在图像超分辨率重建效果上的量化评价, 可以看到本研究方法的PSNR和SSIM指标均高于SRGAN方法. 这是由于采用了预训练的方式, 先基于图像像素空间的均方差值进行网络的优化训练, 取得了较高的PSNR和SSIM指标, 而后在预训练模型上基于特征图的均方差进行训练, 使网络学习到更多的高层语义信息. 所以本研究方法所生成的图像较之SRGAN具有更好的亮度、 对比度和总体图像质量. 此外, 较之SRGAN, 本研究方法所获得的内容损失在BSD100数据集和SET14数据集上分别减小了43.93%和25.09%, 内容损失指标有相当大的提升, 即该方法比SRGAN具有更强的学习特征高层语义和结构信息的能力, 能够生成更加清晰的图像纹理.

表1 图像超分辨率重建效果量化评价
3.2 质化评价
基于BSD100和SET14图像数据集, 使用不同的超分辨重建算法, 在四倍放大因子下进行图像超分辨率重建任务, 并进行质化评价. 如图5所示, 可以看出Bicubic方法重建出的图像分辨率提升有限; 而SRCNN方法重建的图像分辨率有显著提升, 但图像高频细节不足, 密集纹理处显得十分平滑, 图像缺乏真实性. SRGAN方法重建的图像不仅有较好的整体质量, 并且在图像的密集纹理处生成了比较清晰的纹理信息, 但这些纹理信息与参考图像的纹理信息仍有较大区别. 而本研究方法所生成图像在图像密集纹理处更加接近参考图像, 图像的亮度与对比度等方面的生成质量也优于SRGAN.


(a) Bicubic (b) SRCNN (c) SRGAN (d) Ours (e) HR Image图5 不同图像超分辨率重建方法在BSD100数据集上的效果对比Fig.5 Comparison of the effects of different image super-resolution reconstruction methods on the BSD100 data set
如图6所示为各种方法在SET14数据集上的结果对比, 可以看出Bicubic方法生成的图像整体模糊, 几乎看不清图像的纹理细节; 而SRCNN生成图像整体清晰了许多, 可以看出少女胸前佩戴首饰的大致纹理, 但这些纹理质量较差, 无法看清其具体图案. 从SRGAN生成的图像纹理, 能够看出首饰上”双龙戏珠”的纹样, 但几乎无法看出中心圆珠周围还存在着一圈小圆珠. 而本研究方法所生成的图像不仅可以更清晰地看出“双龙戏珠”的纹样, 并且生成了中心圆珠周围的一圈小圆珠, 对比其他几种方法, 该方法生成的图像具有最好的视觉质量.


(a)Bicubic (b) SRCNN (c) SRGAN (d) 本研究方法 (e) HR Image图6 不同图像超分辨率重建方法在SET14数据集上的效果对比Fig.6 Comparison of the effects of different image super-resolution reconstruction methods on the SET14 data set
4 结语
本研究基于SRGAN提出一种改进的图像超分辨率重建算法, 通过生成器网络结构的改进, 增强了图像浅层特征信息, 提升了SRGAN在特征空间中的学习能力, 并且使用相对判别器克服了SRGAN训练不稳定的缺点. 实验结果表明, 该方法取得了更佳的超分辨率重建效果, 在图像的高频细节处能够生成更清晰丰富的纹理.
