K-Means和KNN日志异常检测方法*
2021-06-16乌旭东容晓峰仲姝锜
乌旭东,容晓峰,仲姝锜
(西安工业大学 英特尔嵌入式技术联合实验室,西安 710021)
日志是一种半结构化的数据,记录着系统运行的关键行为,在系统出错的情况下可以通过查找日志来定位故障,与日俱增的日志数据规模和网络安全问题使网络管理者面临严峻的挑战[1]。近年来,异常检测作为数据挖掘的一个分支正受到越来越多的关注,异常检测是指从数据中找出不符合预期的数据模式的过程[2]。日志数据的异常检测行为从本质上讲可以看作为分类问题,即从大量存在异常日志行为的数据中区分出正常行为和异常行为,并在异常行为中判断出具体的攻击方式[3]。当服务器运行时,日志会记录并生成用户访问的过程,可以通过日志中的信息来查找异常用户的信息。因此,分析日志成为检测用户异常行为的最有效方法之一[4-6]。
随着大数据的快速发展,基于日志的异常检测方法分为三大类:基于模型的技术、基于邻近度的技术和基于密度的技术。基于模型的技术建立了一个数据模型,该模型不能完美拟合的对象则为异常对象。将异常和正常对象定义为两个不同的类,使用分类技术建立两个类的模型。分类技术中训练集很重要,由于异常相对稀少,所以无法检测可能会出现的新异常[7]。文献[8]提出了一个新的基于Apache Hive的数据存储和分析架构来处理大量的Hadoop日志数据,使用平均移动和3-sigma技术设计并实现了三种异常检测方法,分别为基本法、线性权重法和指数权重法,在一个名称结点和四个数据结点的Hadoop平台下评估了提出的方法的有效性。文献[9]提出了一种不需要任何特定应用知识在非结构化系统日志中进行异常检测的技术,包括一种从自由文本消息中提取日志密钥的方法,在Hadoop平台下实验的误报率约为13%。文献[10]通过源代码匹配日志的格式,找出相关变量,通过词袋模型提取对应日志变量的特征,使用这些特征通过主成分分析方法降维,根据主成分分析的最大可分性检测异常的日志文件,使用决策树可视化该结果。文献[11]使用随机索引为代表的操作序列,根据其上下文为每个日志中的操作特征化,使用支持向量机关联序列到故障或无故障的类别上,以此来预测系统故障。文献[12]应用文本挖掘技术将日志文件中的消息分类为常见情况,通过考虑日志消息的时间特性来提高分类准确性,并利用可视化工具来评估和验证用于系统管理的有效的时间模式。基于邻近度的技术考虑对象之间的邻近性度量,例如“距离”。 文献[13]提出了一种日志文件异常检测方法,动态地从示例文件中的某些模式产生规则,并能够学习新类型的攻击,同时尽量减少人类行为的需要,采用Hadoop平台,提供分布式存储和分布式数据处理来支持并行处理加快执行速度。文献[14]使用数据挖掘方法来分析Web日志文件获取有关用户的更多信息,描述了日志文件格式、类型和内容,并提供了Web使用挖掘过程的概述。文献[15]提取源代码中的一组日志语句并生成可到达性图,表示了日志语句的可到达关系,通过将有关日志语句的信息与信息检索技术相结合创建日志消息,并根据这些消息的执行单元对其分组跟踪,提出了一种基于概率后缀树的检测算法,组织并区分序列所具有的显著统计特性,在CloudStack测试平台和Hadoop生产系统上试验,结果与其他四种检测异常的算法相比,能够有效地检测运行异常。由于在现实情况下异常点较少,文献[16]提出一种基于隔离的异常检测算法,创建了隔离树可快速收敛但需要二次抽样才可达到高精度。基于密度的技术认为低密度区域对象是异常点。文献[17]提出了一种局部离群点检测算法,时间复杂度较高且不适用于大规模数据集和高维数据集的离群点检测。文献[18]提出了一种基于密度的检测算法,该算法引入了局部离群因子(Local Outlier Factor,LOF),并通过数据的 LOF 值的大小来判断该数据是否异常,此类算法只适用于静态的数据检测,一旦数据量发生了波动,就需要重新计算所有数据的 LOF 值,算法适应性较差,不适合动态数据的检测过程。文献[19]假设数据样本服从一元高斯分布,将距离均值两倍或三倍方差以外的测试样本判断为异常。
在大量日志中,异常日志仅仅是一小部分,人工筛选成本高而且效率低,标记每条日志为正常或异常则更加困难。因此,文中拟提出一种无监督学习和有监督学习结合的异常检测方法,以求在保持较高精确率的同时,具有较高的召回率。
1 检测方法
Web日志是网站分析和网站数据仓库的数据基础来源,目前常见的Web日志格式主要为两类,一类是Apache的NCSA(National Center for Supercomputing Applications)日志格式,另一类是IIS(Internet Information Services)的W3C(World Wide Web Consortium)日志格式。本文采用Apache的NCSA日志格式,常见的NCSA日志格式包含访问主机、标识符、授权用户、日期时间、请求、状态码、传输字节数、来源页面和用户代理,示例为
222.X.X.X [27/Oct/2019:14:50:28+0800]“GET /my/ HTTP/1.1” 303 440 “Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/71.0.3578.98 Safari/537.36”
检测过程如下:
① 对源日志进行词的切分,考虑到上下文的联系,运用GloVe方法对日志进行向量化,构建单词的词向量;
② 运用K-Means方法进行聚类,得到分类后将分类标签追加到词向量的末尾;
③ 在测试日志上运用窗口为10,步长为5的滑动窗口每次取10条日志,运用GloVe方法进行向量化得到无标签的向量组;
④ 利用K-近邻(K-nearest Neighbors,KNN)方法检测每个向量所属的类别和其对应的概率,根据概率和确定向量组所属的类别。
1.1 向量模板构建
由于日志的数据量大、异常出现的情况少,对每条日志都进行标注显然是不可行的。日志一般由访问主机、请求、状态码、传输字节数、来源页面和用户代理等组成,其表示出来的语义由每个单词组成,那么每个单词和其所在的日志所表达的意思就存在包含的关系,明白一条日志的语义不仅与其中的一个单词有关,还涉及到每个单词与其前后的联系。潜在语义分析(Latent Semantic Analysis,LSA)的复杂度高、计算代价大,而且所有单词权重一致,Word 2vec不能充分利用语料,为了保留每个单词和单词与上下文的联系,采用GloVe方法[20]将日志映射为向量。单词映射后的词向量示例:
POST -0.195 446 -0.574 467 -0.470 006
0.429 785 0.130 880 -0.439 768 0.209 260
-0.093 765 0.216 039 0.662 611 0.005 264
0.467 367 -0.430 639 -0.561 740 -0.195 026
0.382 339 -0.738 498 1.108 774 0.005 039
-0.290 427 0.423 914 0.717 930 -0.402 835
-0.599 006 0.704 752 -0.237 082 0.177 782
0.116 570 0.605 918 0.336 175 1.160 042
0.641 670 1.163 572 -0.247 168 -1.088 245
0.662 692 0.633 095 -0.070 681 -0.451 162
-0.541 639 -0.225 370 -0.868 071 -0.364 506
0.273 865 0.478 514 -0.686 345 1.153 848
-0.483 402 -0.055 478 -0.264 137
利用全局矩阵分解和局部上下文窗口兼顾较长范围的全局信息和短距离的单词上下文信息,保留了每条日志中的每个单词的语义信息,其模型目标函数为
(1)
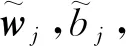
(2)
其中x为式(1)中的Xij,根据文献[20]可知,α取3/4,xmax取100时效果最好。
通过GloVe对单词进行映射,将日志分为单词和其对应的向量,去掉单词内容仅留下向量,得到K-means算法所需要输入的符合标准的数据。
1.2 K-means聚类
将得到的向量数据集输入K-means聚类算法,输入K值即可得到分类的向量结果。将向量数据分类主要是为了给数据标记,作为训练数据输入。实验过程中给出一组无标签数据集:
(3)
将数据集分为k个类C=C1,C2,…,Ck,损失函数为
(4)
每个类中的中心点为
(5)
K-Means算法使用贪心策略[21-22]求得一个近似解,步骤如下:
① 在样本中选择k个点充当中心点;② 计算所有点到中心点的距离dist((xi),uj),把样本点划入最近的类中x(i)属于u(near);③ 根据样本点重新计算簇中心;④ 重复②③。
实验使用K-Means聚类将向量映射到空间中形成不同的簇类,以不同的颜色区分,如图1所示,聚类完成后将得到的分类标签添加到向量数据集中作为训练数据。

图1 聚类结果
1.3 KNN异常检测
实验以滑动窗口的方式选取测试日志,窗口大小为10,步长为5。对其进行向量化,对每一条向量都进行预测,得到其所属类别Ci和概率Pi,分别累加得到最后的概率和为
(6)
选出概率最大的一类作为其所属分类,其核心代码为
S:source tagged data/输入带标签的数据;
T:test vector data/输入测试向量数据;
W:windows size/输入窗口大小。
for each vector in W/累加向量概率,取最大值作为结果:
p(vector)+= p(vector);
if p(vector) > result;
result= p(vector)。
计算步骤如下:
① 计算测试数据与各个训练数据之间的距离;
② 按照距离的递增关系进行排序;
③ 选取距离最小的K个点;
④ 确定前K个点所在类别的出现频率;
⑤ 返回前K个点中出现频率最高的类别作为测试数据的预测分类。
对单词的词向量分类后的结果示例为
Your input is:[‘0.018 071’‘-0.035 667’
‘0.010 582’‘0.029 942’‘0.018 918’
‘0.063 902’‘0.004 891’‘-0.021 608’
‘0.042 474’‘0.023 72’‘-0.040 775’
‘-0.012 949’‘-0.036 745’‘0.030 719’
‘-0.006 368’‘0.057 134’‘0.015 395’
‘0.068 345’‘0.018 37’‘-0.001 688’
‘0.023 931’‘0.044 815’‘-0.011 621’
‘-0.003 934’‘0.017 733’‘-0.015 501’
‘0.040 929’‘0.001 506’‘-0.054 238’
‘-0.047 16’‘-0.034 344’‘-0.010 893’
‘-0.024 657’‘0.030 823’‘0.024 507’
‘-0.008 823’‘-0.055 855’‘-0.017 933’
‘0.054 512’‘-0.033 674’‘-0.023 098’
‘-0.077 288’‘-0.072 619’‘-0.021 143’
‘0.045 811’‘-0.004 346’‘0.024 517’
‘-0.034 229’‘0.056 217’‘0.023 467’]
and classified to class:1
2 实验及结果
2.1 实验环境及数据集
为验证文中方法的有效性,实验环境在服务器上配置,处理器为Intel Xeon(R) CPU E5-2620 v3@2.40 GHz×24,32GRAM,操作系统为Ubuntu 18.04.2 LTS(64位)。实验数据集来自于某高校Model平台Apache服务器上的Web访问日志,共33 649条记录。
2.2 评价标准
由于日志数据量较大,且正常日志多异常日志少,因此利用混淆矩阵来检测模型的准确性。规定“1”为正类,代表异常;“0”为负类,代表合法。混淆矩阵是一个包含两个维度(“实际”和“预测”)的表格和两个维度的“类别”集合。其中,行代表预测数据,列代表实际数据,见表1。

表1 混淆矩阵
表1中,TP为正确肯定,指实际为正例,预测也为正例;FN为错误否定(漏报),指实际为正例,预测为负例;FP 为错误肯定(误报),指实际为负例,预测为正例;TN为正确否定,指实际为负例,预测也为负例。
2.3 模型整体性能评价
对日志数据进行向量化,利用GloVe方法把日志映射为50维向量,得到的结果是每个单词及其对应的向量。将得到的向量进行K-means聚类,聚类完成后进行标记,得到一组带有标签的向量数据,将其作为训练数据。取新的一组日志数据,同样利用GloVe方法对其进行向量化,得到一组无标签的向量,将这组无标签的向量作为测试数据。将训练数据和测试数据输入KNN算法中,即可得到测试数据中向量的所属分类。
实验中,通过修改算法中的K值来观测算法对于不同的参数表现出的不同性能。修改一次K值会出现一次结果,对这些结果进行分析,不同K值的检测结果见表2,同时对精确率、召回率和F1值作曲线对比,如图2所示。

表2 不同K值的性能
从表2可以看出,随着K值从2逐渐增大到5,损失函数先减小后增大,并且当K值为2和3时能取到最低0.050,对应的精确率、召回率和F1值取到最大。
从图2可以看出,随着K值从2逐渐增大到5,精确率、召回率和F1值先增大后减小,并且当K值为2和3时能取到最高,分别为0.92,0.96,0.93。
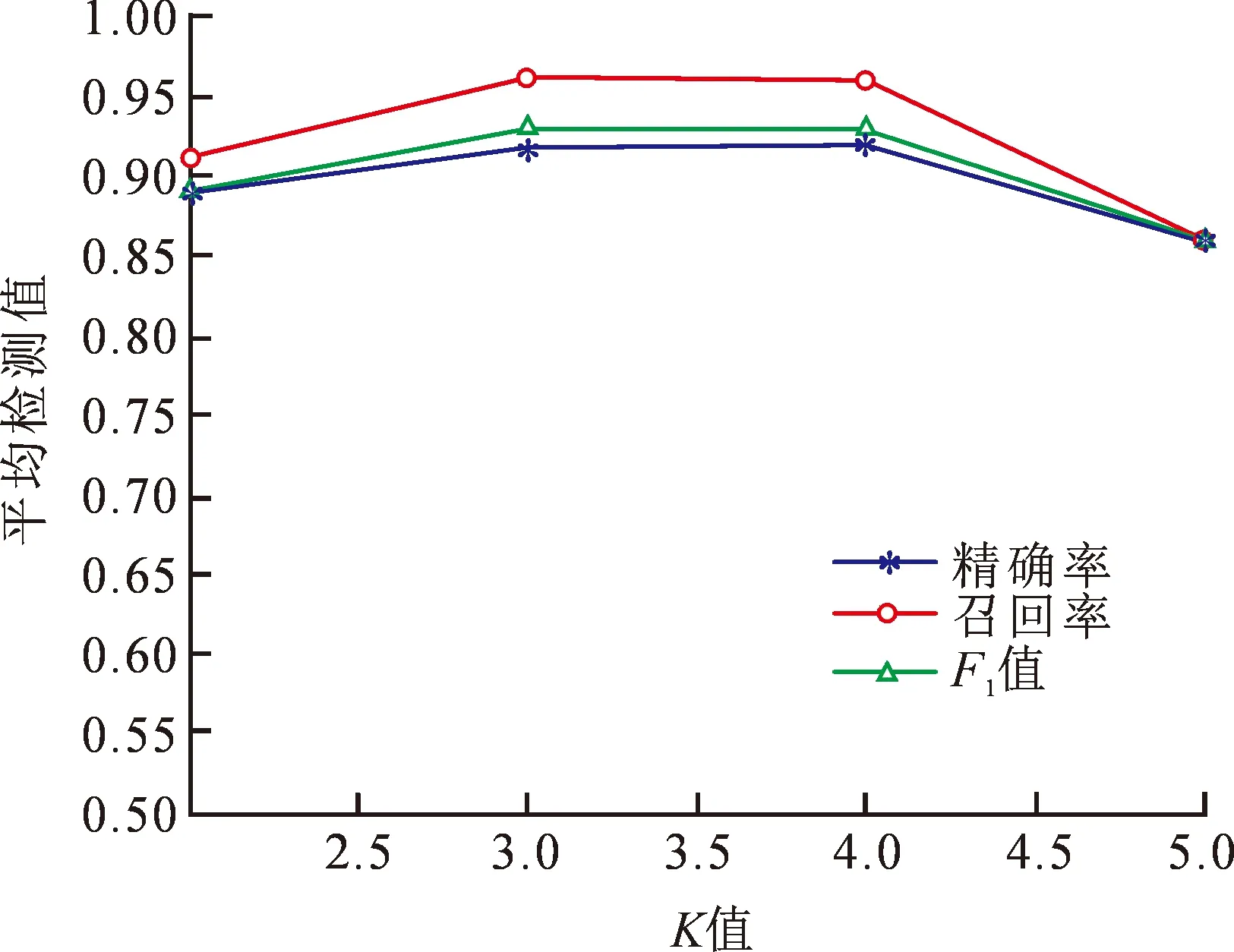
图2 不同K值的性能
将文中方法和Proposed,Logistic,Decision Tree,SVM和Random Forest等5种不同方法的异常检测性能做比较,取精确率、召回率和F1值,结果如图3所示。
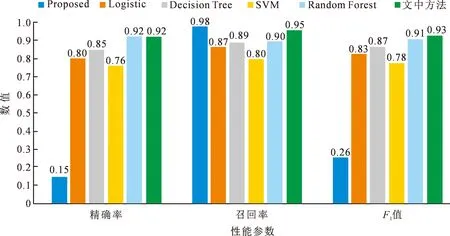
图3 不同方法性能比较
3 结 论
本文提出了一种K-Means和KNN结合的日志异常检测方法。利用GloVe方法对日志用向量表示,用K-means方法将得到的向量分类并标记,用滑动窗口取测试日志切片,将测试日志向量化,用KNN方法对测试日志对应的向量进行预测,得到了预测分类结果。
结果表明,随着K值从2逐渐增大到5,损失函数先减小后增大,并且当K值为3和4时能取到最低为0.05,对应的精确率、召回率和F1值取到最大,分别为0.92,0.96,0.93。文中方法和现有其他5种方法相比,在精确率相同的条件下有更高的召回率。
