多模态融合情感分析模型研究
2021-06-16罗径庭王勇王瑛
罗径庭 王勇 王瑛
(广东工业大学计算机学院 广东省广州市 510003)
1 引言
智能机器正成为现代生活中不可或缺的一部分。近年来,这个问题的重要性引起了人们对人机交互领域的更多关注。大家期望改善人与机器之间的关系质量,以使其更加贴近现实,友好,更具有互动性。要大幅增进人机关系,其中最大的影响因素之一就是通过机器识别人类的情感,从而让其做出适当的反馈。言语是人与人之间表达情感的一种普遍交流方式。尽管如此,行为、口音等的复杂性可能会对从语音中识别情感造成困扰。除了语音分析外,还可以利用面部表情的研究来识别人类的情感,将两者加以融合分析的识别效果会更佳。在多模态情感识别领域,前人已经提出了大量计算模型,包括张量融合网络、记忆融合网络、多级注意力循环网络等。传统的多模态情感识别方法通常将单个模态信号建模为独立的向量表示,通过模态融合进行多模态之间相互关联信息的情感建模。但在处理面部模态信息时往往分别对单帧图像进行特征提取,导致连续帧的帧间信息没有充分利用。为解决传统的多模态情感识别系统的问题,本文将面部界标在连续帧上的位移看作一组时间序列,通过离散小波变换(Discrete Wavelet Transform, DWT)[1]提取出视觉特征。DWT 通过将原始信号分为低频和高频分量,即近似分量和细节分量,来揭示隐藏在信号中的信息,将子带系数中收集的信息进行组合形成视觉特征,并与音频特征进行融合构建出最终的特征向量。
2 多模态情感识别系统
人类通过情感表达来进行更有效的交流,这体现在面部运动、语调变化、手或身体运动以及生物信号之中。人类情感状态的分析已被纳入情感计算领域,情感计算是对人类情感系统的研究和开发的过程,该系统由计算机科学、心理学和认知科学交叉形成,它们共同协作来识别、解释、处理和模拟人类情感。情感识别领域的主要挑战之一是缺乏统一的分类系统的协议。每个人的情感行为都是复杂多变的,而情感本身取决于个体的性格特征和内心状态。因此在大多数情况下无法用一套基本情感作为标准来对情感进行分类。心理学家根据这个理论性的问题引入了不同的情感分类模型,既情感是一种离散现象,因此是可区分、可测量且可分离的。前人对不同文化之间的情感的相似性和差异性做了各种研究,提出了六种基本的人类情感,即恐惧、厌恶、愤怒、惊讶、喜悦和悲伤。而基本情感可以用不同的方式组合起来,形成与人类情感相关的全部复杂情感。例如,愤怒和厌恶可以组合起来表示鄙视。在情感识别系统中,特征提取过程的地位至关重要。本研究中提取的特征分为音频特征模态和视觉特征模态这两种不同的模式。并且提出了一种新的视觉特征提取方法,该方法通过分析各个面部界标的位移信号来识别面部表情。本文将连续的跨帧语音界标位移用于视觉特征提取。因为是各种情感所对应的特定界标的位置是不同的,所以生成的位移时间序列将有所不同,可以用作特征提取的原始数据。将界标的运动变化看作一个时间序列,本文就能够采用不同的信号变换来提取特征。在音频模态中,除了韵律特征之外,本文还提取了三种声谱和倒谱的特征类型,即梅尔频率倒谱系数[2],感知线性预测[3],线性预测编码[4]以及第一、第二时间特征导数[5]。情感识别领域的主要挑战之一是缺乏统一的分类系统的协议。每个人的情感行为都是由模棱两可和复杂的情感组合而成,而情感本身取决于性格特征以及人的内心状态。因此,在大多数情况下,无法用一套基本情感作为标准来对情感进行分类。根据这个理论性的问题本文引入了不同的情感分类模型。情感是一类离散的行为,或者是一个更大连续体的一部分。情感是一种离散现象,因此是可分离的。人类普遍文化中的主要情感有六种,包括恐惧,厌恶,愤怒,惊讶,喜悦和悲伤。相比较地,从维度的角度来看,所有情感都具有二维或三维的特征,在大多数模型中这些维度通常是效价和唤醒的。
常见的多模态情感识别的结构由五个主要部分组成,第一部分是将系统创建适当的数据集作为先决条件。该部分的各个阶段包括记录不同人类情感状态下的语音,标记面部并进行跟踪,以及从语音中提取说话声音;识别并提取与情感关联度最高的相关特征;融合音频和视频特征,这些特征可以在提高模型效率方面发挥重要作用。特征向量可能包含多个不相关的特征,使模型变得复杂。而应用降维技术可以提高效率,并降低最终模型的复杂程度。在上述过程进行到最后阶段时,进行情感分类。分类过程中的重要过程是选择适当的视听特征和高效的分类模型,这样才能得出更准确的模型。本文使用了韵律和声谱域特征作为音频特征,包括音量,ZCR,MFCC,LPC 以及一阶和二阶时间导数。除此之外,本文使用界标位移信号的提取方法来提取视觉特征,该方法利用了人脸上特定界标的位移。为了做到这点,采用了信号处理领域中的离散小波变换方法。提取到视听特征后,进行特征融合。我们在两个不同的级别上进行融合,即分为特征级融合和决策级融合。在特征级融合中,将从语音和视频中提取的特征向量组合在一起,用于开发智能情感识别模型。而在决策级融合中,先通过视觉和听觉特征导出相应的个体模型,然后以不同的决策方式得到模型输出组合。在本项研究中,将音频和视觉特征向量混合在一起的特征水平融合方法构成了可用于推导出分类模型的最终特征向量。特征向量可能包含许多无关和无用的特征,一方面增加了模型整体的复杂性,另一方面又降低了模型的精度。所以降维过程有助于简化模型并提高效率。通过应用降维技术减少特征向量维数并提高最终模型的性能。最后一步是分类,将观测值进行分类,即将数据集的特征分配到预定义的类别中。在这项研究中,各种类型的分类技术被归入两个大类来运用,即个体模型类和集成模型类。集成学习法就是基于此原理进行操作,一组分类器的预测组合往往比单个模型预测更好。按照这种思路,先是构建一系列基础学习器,然后以各种方式进行组合,用以提高准确性,减少错误率。本研究中提取的特征将分为音频特征模态和视觉特征模态这两种不同的模式。面部特征提取方法可以分为以下几种:一是几何特征,用于研究面部敏感区域,例如眉毛、嘴巴和嘴唇,可以检测情感。脸部界标之间的距离、角度和面部上特定区域的形状就属于此类示例。二是表达面部丰富的表情纹理变化的外貌特征,例如皮肤的褶皱。然而主要的挑战来自所提出的方法的鲁棒性、环境条件以及由于面部解剖结构的复杂性而引起的个体差异之间的冲突。本文提出的基于界标位移的视觉特征提取方法通过分析各个面部界标的位移信号来识别面部表情,将连续的跨帧语音界标位移用于视觉特征提取。这么做的主要原因是各种情感所对应的特定界标的位置是不同的。所以生成的位移时间序列将有所不同,可以用作特征提取的原始数据。将界标的运动变化看作一个时间序列,我们就能够采用不同的信号变换来提取特征,比如可以使用离散小波变换这个信号处理应用中常用的工具来提取特征。
界标的位移信号可以看作是所提出的视觉提取方法的原始数据。位移信号是根据连续帧中界标位置的变化生成的。假设在二维坐标中将每个界标定义为(x,y),并生成两种不同的信号,一种用于表示沿水平轴位移的界标,另一个用于表示沿垂直轴位移的界标。则信号的总数为2×n,其中n 是界标的数量。
应用数学信号变换可以揭示原始信号中的隐藏信息。在这项研究中,离散小波变换被用来提取视觉特征。由此运用到了DWT系数,即近似值和细节系数。这些系数通过使用快速小波变换算法来算得,该算法运用一系列具有不同截止频率的高通和低通滤波器,将信号分解为不同的子带。每个低通滤波器的输出会被再次过滤,以便进一步分解。 下一步计算统计参数。利用离散小波变换的输出,包含不同层别的近似值和细节系数来形成最终的特征向量。然而,由于子带系数的数量众多,因此放弃使用所有系数,转而使用统计参数,例如均值和标准差。在最后阶段,以不同子带系数的平均值和标准偏差值为基础来构建整体特征向量。为构建好这个向量,使用到了所有与面部的界标相关联的信号。本研究中也使用到了原始信号的均值和标准差。在音频模态的研究案例中,除了韵律特征,即音量和ZCR 之外,还提取了三种声谱和倒谱的特征类型,即梅尔频率倒谱系数(MFCC),感知线性预测(PLP),线性预测编码(LPC)以及第一、第二时间特征导数。MFCC 用来估算人类听觉系统的频率响应,并运用它的非线性频率标尺,即梅尔频率来估算人类听觉系统的灵敏度。PLP 以三种与听觉概念相关的人类心理物理学为基础进行语音建模,这三种物理学分别是临界带声谱分辨率,等响度曲线和强度响度幂律;与MFCC 不同,这种方法是基于Bark 标尺来扭曲声谱。LPC 则以激发源通过线性滤波器的形式来估算语音生成过程;由于人类听觉系统对电极反应相当敏感,因此LPC 认为声道是纯粹的电极模型。
3 实验及结果分析
我们应用不同的分类方法比较不同模型的性能,并且比较了在特征融合前后以及使用降维方法前后的分类模型的性能。本文使用了SAVEE 情感数据集进行测试。由于数据集样本中被试者面部共标记有65 个界标,则x 轴和y 轴上共会生成130 个位移信号。通过使用三级DWT,提取子带系数,分别为cD1、cD2、cD3 和cA3,然后用DWT 系数的均值和标准差以及原始信号形成最终特征向量。本文采用十折交叉验证法测试模型的性能。如前所述,音频特征向量包括ZCR、MFCC、LPC、RASTA-PLP 以及第一和第二时间导数。使用重叠率为25%的汉明窗将每帧的长度控制为20ms,并使用所有语音帧的均值和标准偏差系数来获得音频特征向量。 则最终特征向量的大小为 。为了比较和评估本文提出的模型性能,选用以下几种主流的多模态情感分析方法作为对比,实验结果如表1 所示。MFM(Multimodal Factorization Model):该方法提出了一种全新的视角来学习多模态特征表示,它能够将每种模态信息分解为共享的判别因子和独有的生成因子。MCTN(Multimodal Cyclic Translation Network):该方法基于编码器和解码器结构,学习模态之间的转换关系,并利用循环一致性损失构建多模态特征表示。RMFN(Recurrent Multistage Fusion Network):该模型将跨模态的融合过程分解为多个阶段进行,并使用循环神经网络捕获时序模态内部的信息。CIM-MTL:该方法是基于多任务学习的多模态情感分析模型,它利用情感细粒度的多标签分类任务,辅助提升主任务的性能。MulT:该模型基于多头注意力机制和Transformer结构,学习模态两两之间的转换关系,能够捕捉跨模态的交互关系。
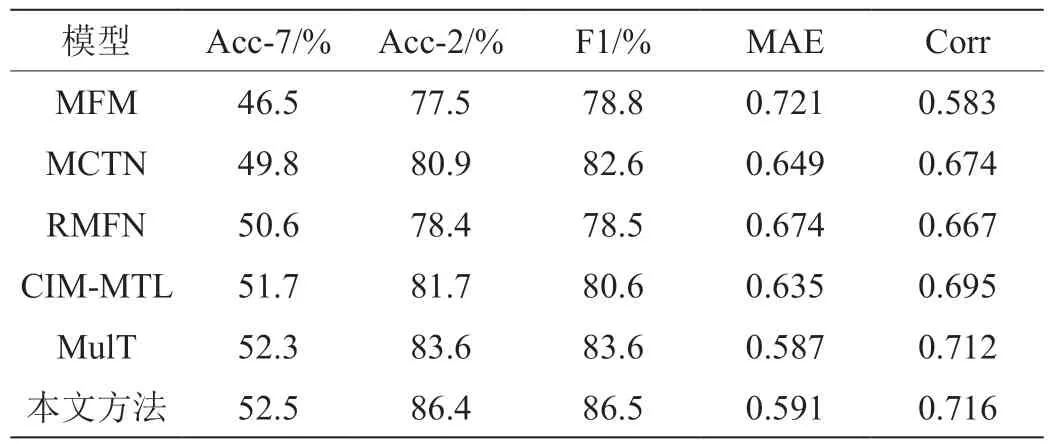
表1: SAVEE 数据集上的实验结果
本文采用七分类准确度(Acc-7)、二分类准确度(Acc-2)、F1 值、平均绝对误差(Mean Absolute Error,MAE)和皮尔逊相关系数(Pearson Correlation,Corr)作为评价指标。根据实验结果可以得出结论,本文方法在SAVEE 数据集上取得了最优的结果。
4 总结
本篇论文介绍了一种多模态情感识别系统。其中音频特征包括过零率、MFCC、LPC、RASTA-PLP 和时间导数。我们提出了一种新颖的视觉特征提取方法,并将其作为识别系统的主要部分。该方法使用跨连续帧的界标随时间变化而产生的时间序列进行特征提取。本文使用位移界标信号的DWT系数来构建最终特征向量。同时,为了降低生成模型的复杂程度,我们应用了各种以关联性为基础的特征选择技术。本研究各项实验结果都是在SAVEE 数据集上运行得出的。实验结果表明,FRNN 分类器在三种数据集上都表现最优。证明了与原始位移信号相关的特征在情感识别过程中起着重要作用,并且它们在选定的特征总数中占了很大一部分比例,如DWT子带特征,研究结果表明将DWT 系数降到较低的层级后,它对模型性能的提高会起到更加重要的作用。此外,在大多数情况下,音频和视觉特征的融合会促使派生模型的性能得到改善。
