基于颜色聚类识别苔色的三重注意力网络
2021-06-16王勇
王勇
(合肥云诊信息技术有限公司 安徽省合肥市 230088)
传统的方法容易受光照、拍摄角度等因素的影响;同时,由于舌面苔质分布的特点,往往需要借助于微小的局部差异才能区分不同的类别,而常规的分类网络对这种细微差异响应不敏感。因此,本文提出了一种基于颜色聚类的三重注意力分类网络识别苔色的方法,本方法有以下几个贡献点:
(1)提出基于HSV 颜色空间的苔、质分离方法;
(2)引入通道依赖的注意力机制;
(3)正负样本对抗学习自动关注图像细节;
(4)端到端的训练实现苔色识别和准确定位苔的分布。
1 相关工作
王爱民等取舌面16*16 像素的小块,判断小块的舌色或苔色类别;张衡翔等提出把HSV 颜色空间中极坐标系下的H、S 分量转化为直角坐标系的X、Y 分量,以此作为颜色特征将舌面分割成若干个矩形小块后使用BP 神经网络进行分类;李晓宇等提出了一种DAG 和决策树结合的方法对舌色苔色进行识别;卓力等提出利用滑动窗将舌图像划分为若干个图像子块后对其进行人工标注并借助卷积神经网络完成分类。
针对现有的研究方法,本文设计出一种基于聚类方法的三重注意力网络。其特点是每次输入三张样本图片,这三张样本图片分别是原图和利用聚类算法将原图生成的舌苔子图及舌质子图。本文主要研究的是苔色分类,所以标定原图与舌苔子图为正样本,而舌质子图为负样本;通过正、负样本相互促进的学习方式不仅可以量化苔色类型还可以确定苔的分布情况。
2 网络介绍
2.1 基于HSV颜色空间的聚类方法
2.1.1 HSV 颜色空间
HSV 是根据颜色的直观特性由A.R.SMITH 在1978年创建的一种颜色空间。色调H:用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算;饱和度S:表示颜色接近光谱色的程度,其中光谱色所占的比例愈大,颜色接近光谱色的程度就愈高,饱和度也就愈高,取值范围为0%~100%;明度V:表示颜色明亮的程度,对于光源色,明度值与发光体的光亮度有关,对于物体色,此值和物体的透射比或反射比有关,取值范围为0%(黑)到100%(白)。
HSV 更加面向于用户,是一种比较直观的颜色模型,所以本文选择基于HSV 颜色空间处理舌象图片。
2.1.2 基于HSV 颜色空间的聚类
本文利用Mask-R CNN 网络算法分割出舌体;然后将舌象从RGB 空间转换到HSV 空间,利用高斯滤波对色度直方图进行平滑处理。在HSV 颜色空间下遍历保存舌象图片中所有像素点数值,作为无监督聚类算法的训练集。本文基于K-means++聚类算法完成舌苔、舌质的分离,如表1 所示。
经过实验验证,K-means++的聚类超参数K 最合适取为15,即一张舌象聚类生成15 个子图(图1)。

表1

表2
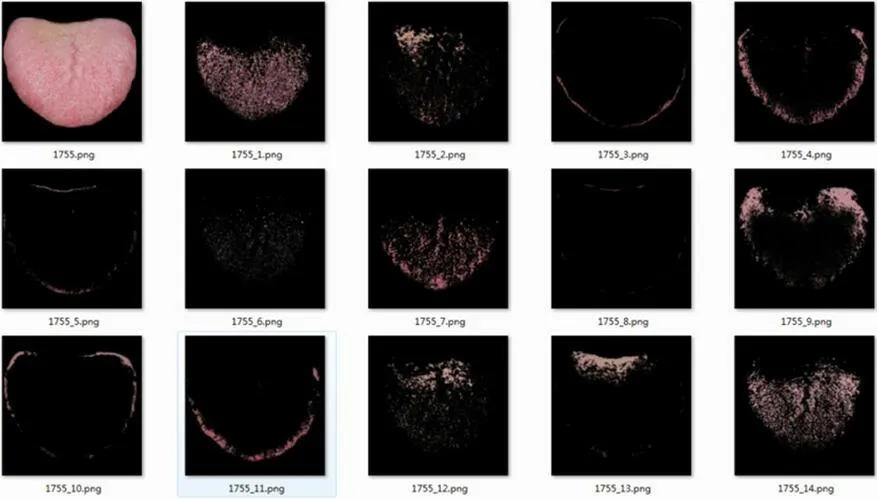
图1:舌象图片及其产生的子图

表3

表4

表5
继续利用直方图相似度合并算法将聚类后生成的子图合并形成舌苔子图和舌质子图,算法描述(表2)和实验结果(图2)。
2.2 基于通道依赖的注意力机制
2.2.1 注意力机制
注意力机制本质则是为了模仿人类观察物品的方式。通常来说,人们在看一张图片的时候,除了从整体把握一幅图片之外,也会更加关注图片的某个局部信息。因此,注意力机制其实包含两个部分:
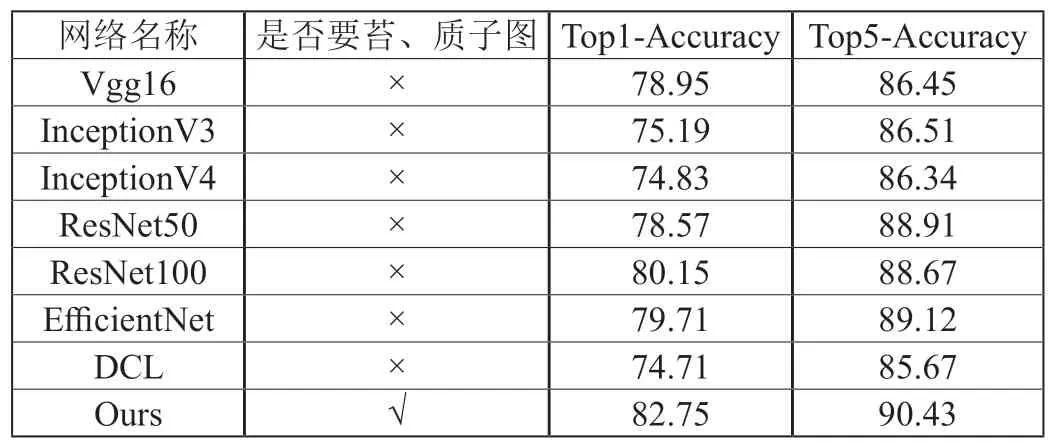
表6:准确度对比(%)

图2
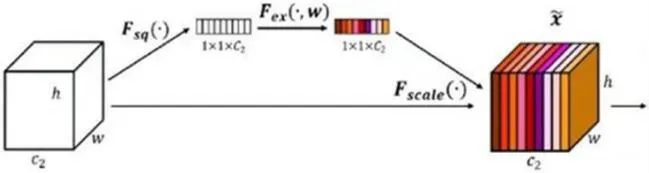
图3

图4
(1)注意力机制需要决定整幅图片中哪个部分需要更加关注;
(2)从关键的部分进行特征提取,得到重要的信息。
2.2.2 基于通道依赖的注意力模块SE-block
SE-block 包括Squeeze(压缩)和Excitation(激活)两部分,此模块是希望显示地建模特征通道之间的相互依赖关系;具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依据这个重要程度去提升有用的特征并抑制当前任务用处不大的特征。结构图如图3,详细解释见表3。
2.3 网络结构
2.3.1 骨干网络模块
图像分类首先需要利用卷积层和池化层对图像中的特征进行提取,本文使用的骨干网络基于ResNet-50,用448*448 大小的图片代替通常所使用的229*229,并在其中嵌入注意力机制Squeeze-Excitation(SE) block 模块。SE-block 的目的是改善网络的表达能力,能够让网络模型对特征进行校准的机制,使网络从全局信息出发有选择性的放大有价值的特征通道并且抑制无用的特征通道。
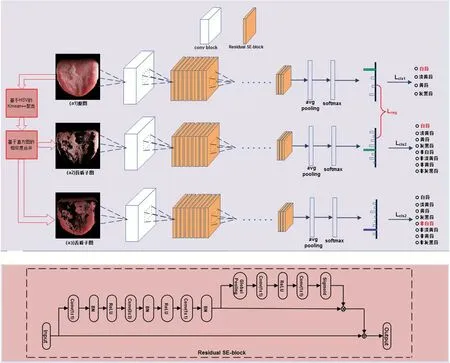
图5
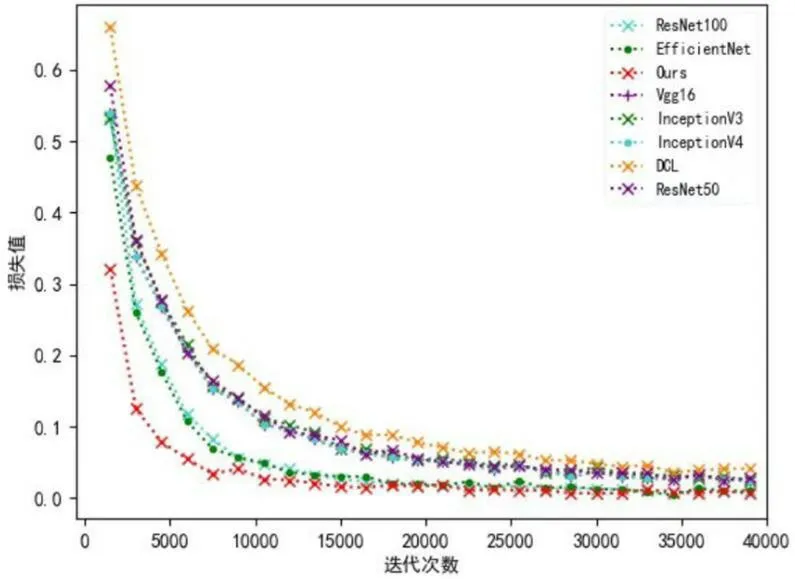
图6
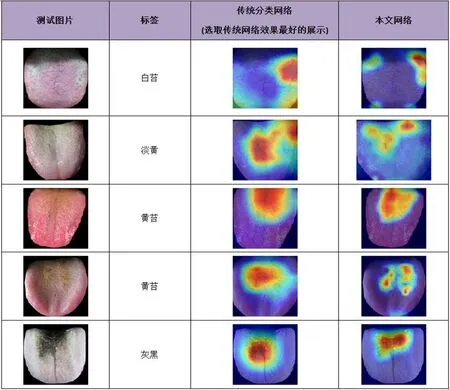
图7
2.3.2 标签预测
网络在训练时需要输入两个正例图片、一个负例图片共三张样本图片,这三张图片来源于同一张舌象图片。如一张淡红舌白苔可以分解为图4 的(a),(b),(c)。
三张样本图均需经过骨干网络提取特征,最后通过全局平均池化转换为3*1*1*2048,其中1*1*2048 是特征图的大小,3 则是样本数;因为本文借签Triplet Net 的样本输入方式,即同时输入三张样本。下面将3*1*1*2048 转换为预测的标签。
苔色在本文中共分为白苔、淡黄、黄、灰黑这4 类标签,图4中的(a)、(b)均为白苔,而图4 中的(c)则代表的是非白苔,之所以称为非白苔,即表示不关心它属于其他哪个类别,只要确定不是白苔即可。为实现端到端的训练,本文对原图的类别标签保持不变但对苔、质子图的类别标签进行扩展。例如苔色类别标签为“白苔”、“淡黄”、“黄”、“灰黑”,扩展后新的标签则变为:“白苔”、“淡黄”、“黄”、“灰黑”、“非白苔”、“非淡黄”、“非黄苔”、“非灰黑苔”共8 类,如果类别标签编号从0 开始,则图4 中的(a)、(b)均表示白苔即标签为:0,图4 中(c)表示非白苔即标签为:4。
经过类别标签的扩展后,上述特征3*1*1*2048 通过全连接后类别标签的one-hot 编码则为:原图[1,0,0,0]、舌苔子图[1,0,0,0,0,0,0,0]、舌质子图[0,0,0,0,1,0,0,0],分别对应着两张白苔样本和一张非白苔样本。
2.3.2 标签预测
结合前文对网络骨干结构和标签扩展的介绍,这里给出整个网络结构图(图5)及模块的实现细节(表4)。
2.4 训练
2.4.1 数据增强
训练阶段,使用裁剪和翻转、亮度、饱和度、旋转操作来扩充数据。首先缩放原始图像,使其短边为512 像素;然后,随机裁剪成448*448 大小的训练样本。
2.4.2 损失函数
本文的损失函数主要包括三部分,两个分类损失分别为Lcls1、Lcls2以及Lreg回归损失,总损失函数则为:
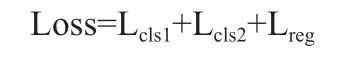
(1)分类损失:本文中原图使用原始类别标签对应分类损失Lcls1,而舌苔和舌质子图使用扩展类别标签对应损失Lcls2。分类损失Lcls1、Lcls2统称为Lcls使用的交叉熵损失函数公式如下:
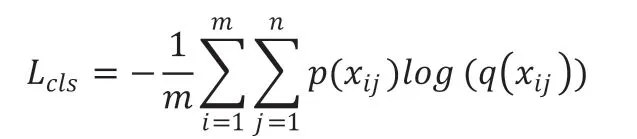
其中,m 表示样本数,n 表示的是分类的类别数,p(xij)表示的是真实标签,q(xij)是预测标签;交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度,可以表示真实标签与预测标签之间的差异。
(2)回归损失:本文将舌象图片进行苔、质分离后产生一张舌苔子图和一张舌质子图,苔色分类时原图与舌苔子图的标签是一致的,同时舌苔子图预测出正确类别的概率应该高于原图,这才符合本文一开始将舌象图片进行苔质分离而让网络更注重细节的初衷,本文设计的回归损失函数公式如下:
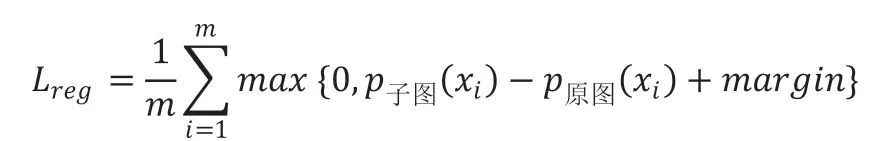
其中,m表示样本数,p子图(xi)表示舌苔子图预测的概率,p原图(xi)表示原图预测的概率,margin 在实验中一般取0.05,起到软间隔的作用。
2.4.3 训练介绍
实验的操作系统为Ubuntu 18.04,GPU 显卡型号为 Nvidia GeForce GTX 2080 Ti(11GB),使用PyTorch 1.4.0 深度学习框架,Python 版本为3.6。训练时batchsize 为32,训练200 个epoch,使用ImageNet 预训练模型初始化网络权重参数 ,同时采用SGD 随机梯度下降算法,momentum 动量为0.9,权重衰减参数设为1e-5;本文学习率采用Warm-up 策略,初始学习率设为0.01,每训练20个epoch 后下调学习率,下调系数因子为0.9。
3 实验
3.1 数据集
本文实验中使用舌象采集仪共采集5000 张舌象图片,并经过安徽中医药大学的教授对舌象图片进行筛选和评审。最终得到有效舌象数据共4860 张,其中白苔1425 张、淡黄苔1563 张、黄苔970 张、灰黑苔830 张。最终训练集4088 张,验证集300 张,测试集400 张。
3.2 性能评估指标
分类问题上,通常用分类准确度来评估网络模型的好坏,根据分类器在测试数据集上的预测或正确或不正确可以分为四种情况,也称为混淆矩阵,如表5。
模型的准确度计算方法如下:
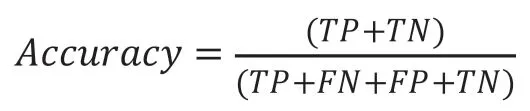
3.3 实验结果与分析
3.3.1 检测精度
为了评估本文方法的有效性,将本文提出的自监督分类网络与目前较流行的传统分类网络Vgg16、InceptionV3、InceptionV4、ResNet50、ResNet101、EfficientNet、DCL 等进行比较。各网络训练得到的Accuracy(表6)和训练损失曲线(图6)。
3.3.2 结果比较
我们展出普通分类网络与本文提出的三重注意力网络在舌苔分布定位上的差异(图7)。
4 结论
本文中,我们提出一种基于颜色聚类的三重注意力分类网络识别苔色的方法,这种方法不仅可以量化苔色类型,同时可以在不需要额外人工标注的前提下准确定位舌苔的分布位置,更符合中医舌诊的要求。通过实验发现我们的方法更容易收敛且具有更高的准确率,同时我们的方法也适用于舌色识别。
