关联分析在图书兴趣推荐中的应用
2021-06-16周智谦邱松
周智谦,邱松
(武汉城市职业学院设备处,湖北武汉,430070)
0 引言
世间万物都是有联系的,这种联系也称为相关性或者关联性(association rule),关联分析(association analysis)是指如果两个或多个事物之间存在一定的关联,那么其中一个事物就能通过其他事物进行预测,目的是为了挖掘隐藏在数据间的相互关系。本文以我校学生近两年的图书借阅事务标识和项目集合数据作为分析对象,通过分析事务背后深层次地相互影响的关系即关联关系,通过关联分析达到寻找图书借阅的联系和规律,发现它们之间的关联关系的目的。事物的相关性或关联性是指当一个事物变化时,另一个事物随着发生变化;或一个事物出现,导致另一个事物出现。
相关性又分为正相关和负相关,正相关是指两个变量变动方向相同,自变量由大到小或由小到大变化时,因变量同样由大到小或由小到大变化,即其数据曲线的切线斜率始终大于零;负相关是指自变量的变化导致因变量反向变化,即其数据曲线的切线斜率始终小于零。
关联分析是数据挖掘相关应用中的一个重要课题方向,已经在各行业中广泛研究和使用。数据挖掘可以完成数据总结、分类、回归分析、聚类分析和关联分析的工作,其中通过关联规则挖掘可发现大量数据中项集之间有趣的相互关联规则,关联分析包括简单关联规则和时序关联规则。以简单关联规则举例来说,分析发现在同一个专业的读者中有相当比例同时借阅程序语言、算法语言(TP312)、软件工具(TP311.561)与图形图像识别(TP391.41)的,这种规律即为一种简单关联规则。
1 数据挖掘
信息社会的特征是数据泛滥但知识相对匮乏,以我校18-19 年图书借阅数据为例,总借阅数为59302 条,包含的信息有借阅时间、书籍题名、读者姓名、读者条码、年级组、院系、索书号,随着时间的推移数据积累地越来越多,借阅信息作为借还书的重要数据在图书借阅系统中使用,如果不对数据库进行技术统计分析,这些借阅信息不能很好帮助我们理解这些数据,比如无法发现借阅数据之间的关系和规则,无法依据现有数据预测未来趋势,就将形成数据泛滥和知识相对匮乏的情况。
■1.1 数据挖掘的定义
数据挖掘是一个利用各种方法,从海量的有噪声的凌乱数据中,提取隐含和潜在的对决策有用的信息和模式的过程[1]。
1995 年在加拿大蒙特利尔的第一届知识发现和数据挖掘国际会议上提出数据挖掘(date mining)概念。数据库中的数据被称为“矿石”,数据挖掘就是在矿石中开采“知识”(黄金)。在计算机科学领域提出的知识发现KDD(Knowledge Discovery in Database)则是在数据库中发现知识,KDD 的过程为建立数据源、提取数据、数据预处理、模型搭建、模型评估、可视化、应用等。
以我校某工科类学院近两年图书借阅信息作分析,对海量数据通过查询和抽取来获得了之前没有获得的有用信息或规则,该院系共718 人有借阅记录,其中借阅1 本人数为238,占总人数的33.1%;借阅2 本人数为152,占总人数的21.1%;借阅3 本人数为97,占总人数的13.5%;借阅4 本人数为56,占总人数的7.8%;借阅5 本人数为97,占总人数的4.4%。借阅量从1 本至12 本的人数约占总人数的95%;完全借阅I 类文学种类书籍人数为15 人;仅借一本图书的238 人中有18%借阅与专业相关,40%借阅文学类书籍;文学类占总借阅量的52.9%,专业相关的占27.6%,而哲学、历史、艺术、数理科学、经济、天文等借阅量普遍在1%上下,从侧面反映了工科学生的求知欲局限于本专业之内。
但是随着对数据挖掘的应用与实践不断深入,对数据的简单查询和抽取已经不能合理描述模型,必须借助于统计学、机器学等其他学科,对数据的预处理和对生成模型的评估是数据挖掘的基础。
■1.2 数据挖掘方法论
数据挖掘方法论是数据挖掘实施的总体指导方案,目前有三个经典的数据挖掘方法论,它们分别是CRISP-DM方法论、SEMMA 方法论和Tom Khabaza 挖掘9 律,其中CRISP-DM(Cross-Industry Standard Process for Data Mining)方法论由SPSS 和Daimler-Benz 公司联合制定,是跨行业数据挖掘标准。本课题基于Clementine 数据挖掘,使用了该方法论,它以数据为核心,其数据挖掘是以自然迭代为规律,整体呈现螺旋式数据探索过程,其对应的六个阶段分别是:(1)业务理解(business understanding)、(2)数据理解(data understanding)、(3)数据准备(data preparation)、(4)模型搭建(modeling)、(5)模型评估(evaluation)、(6)模型发布(deployment)。
■1.3 数据准备工作
本次数据挖掘的目的是对图书借阅信息做关联分析,找到数据背后的隐藏关系;清洗数据共59302 条,剔除系统生成空白借阅信息22 条;清除划归至系部的教师借阅信息900 余条,因文学类占全校总借阅量超过62%,与其他门类书籍有较强的关联性,故需清除所有文学(I)类信息;因为无法产生关联项,删除个人名下只借阅一本的信息;研究侧重对象是工科学生,对于跨学科的哲学、文史、经济等大类,只对大类关联分析,将书籍所属学科按领域合并;共2466 种书籍,为减小项目集合数量,提高关联性,如Tp312 为程序语言、算法语言,此类有多个分支,比如JAVA 表示为TP312JA、C++表示为TP312C++、VC 表示为TP312VC 等,故将所有分支汇集成TP312 这个大类,最终得到47 种不重复种类;在做书籍大类关联分析的基础上,进一步分析某一工科专业学生的专业书籍关联情况,共梳理出T 类(工业技术)种63 子类。
2 基于Clementine 的关联分析
Clementine 提供了基于Apriori 和GRI 的算法,其中Apriori 算法是一种经典的关联规数据挖据算法,它利用频繁项集性质的先验知识,通过逐层搜索迭代的布尔型关联规则从事务数据库或关系数据库中发现同时满足最小支持度和置信度的频繁项目集[2]。
■2.1 关联规则的定义
简单关联分析的对象是事务(Transaction),它由事务标识(TID)和项目集合(X)组成,一个事务标识对应一个事务。
事务标识从001 起始,事务总量T=4;TN79、TN309、TP311.12、TP316.81、TP36 为变量名,取值1 代表借阅,0 代表没有借阅。
■2.2 描述简单关联规则的三个测量值
一般使用支持度(Support)和置信度(Confidence)两个测度指标来描述关联规则的属性。
(1)置信度(C)
所谓置信度,就是对简单关联规则准确度的反映,它表示选择A 后,B 出现的概率。算法公式为:
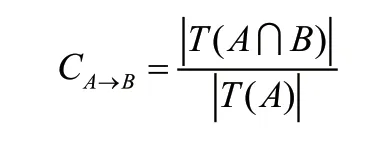
(2)支持度(S)
支持度是指同时选择A 和B 的概率,或者说是选择组合的次数占总事务标识条目的比例。算法公式为:
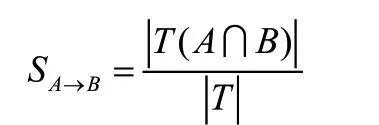
(3)提升度(L)
提升度是置信度与后项支持度的比值,意义是先选择A对再次选择B 的提升作用,用来判断选择组合方式是否具有现实意义,也即是组合选择AB 的次数多于单独选择B 的次数,说明组合方式有效。算法公式为:
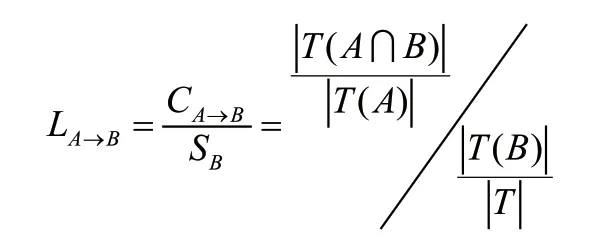
理想关联规则的置信度(C)和支持度(S)越大越好,并且提升度要大于1。如果置信度高但支持度低,说明规则可信度好但是规则应用机会少;如果支持度高但是置信度低,则说明规则可信度低。故理想的关联规则是在众多的关联规则中较好的一类,在设计模型时,可以对置信度和支持度的阈值做限制以筛选出理想关联规则。
■2.3 Apriori 算法
(1)确定频繁项集。以表1 为例,首先由用户指定最小支持度阈值为0.5,通过单个项目集合依次向多个项目集合迭代,事务总量T=4。通过第一次迭代的计算,分别计算出项集C1 中A 至E 的支持度:A=0.5 B=0.75 C=0.75 D=0.25 E=0.75,因此频繁项集L1 为A,B,C,E;第二次迭代项集C2为AB,AC,AE,BC,BE,CE,支持度分别为0.25,0.5,0.25,0.5,0.75,0.5,因此频繁项集L2 为AC,BC,BE,CE;第三次迭代项集C3 为ABC,ACE,BCE,支持度分别为0.25,0.25,0.5,因此频繁项集L3 为BCE。

表1 事实表示例
(2)产生简单关联规则。在高于支持度阈值的前提下,根据用户指定的置信度阈值来确定理想规则集合。对于第三次迭代产生的频繁项L3 而言,需要计算BC 出现时E 出现的概率,即置信度CBC→E=0.5/0.5=1,此时置信度最大;计算BE 出现时C 出现的概率,即置信度CBE→C=0.5/0.75=0.67;计算CE 出现时B 出现的概率,即置信度CCE→B=0.5/0.75=0.67。可见,如果设置置信度为1,则产生的简单关联规则是(BC)→(E);若设置置信度为0.6,则产生的简单关联规则将是(BC)→(E)、(BE)→(C)和(CE)→(B)。
3 模型建立及结论
使用Clementine 对某学院同一专业借阅的图书进行分析。在分析前,首先对数据进行准备工作,同一人名下借阅同种类型、多本图书计一本,样本中总人数为85 人,清洗掉只借一本的10 人,得到借阅至少两本的可进行关联分析的人数为75,书籍借阅种类共计46 种;将数据库中的事务类型表转换成事实表,得到事务总量T 为75,项目为46。
通过Var.file 节点读入数据,将Moedling 中的Apriori节点放入,在字段的后项和前项中引入所有需要分析的项目。为能选出理想模型,设置最低支持度阈值为10%,最小规则置信度设置为50%,分析结果如下表2 所示。

表2 Apriori关联分析结果
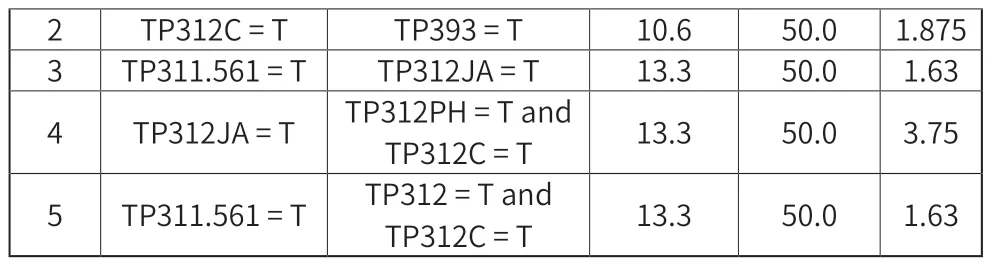
其中1 号规则的含义是:借阅TP393(计算机网络)同时会借阅TP312C(程序语言、算法语言,C 语言),支持度和置信度都大于设定阈值,提升度(L)>1,说明规则具有现实意义,组合方式有效。4 号规则的含义是借阅TP312PH(程序语言、算法语言,PHP 语言)和TP312C(C 语言)的同时会借阅TP312JA(JAVA 语言),并且它的提升度(L)是最高的,说明实际指导意义相对最大。
简单规则的分析结果可应用于优化图书馆书籍的收纳分类和图书兴趣推荐方面。将同一大类书籍按照借阅的关联规则合理规划摆放区域,可方便读者一并借阅;通过优化借阅路径,在摆放专业相关分类书籍的同时,覆盖一部分交叉学科书籍,有助于学生补充综合性知识,使学生能获得多元的理论基础和视角。
