基于企业知识库的智能问答技术与应用
2021-06-16张颖沈辰楠杜秀兰阎晓强
张颖 沈辰楠 杜秀兰 阎晓强
(中国市政工程华北设计研究总院有限公司 天津市 300074)
1 前言
近年来,随着企业管理水平不断提升,员工对企业各规章制度和办事流程不了解会使工作寸步难行。通过研究基于知识库的智能问答相关技术,将企业的各个环节集成起来,共享信息和资源,同时利用现代的技术手段不断提高生产效能和质量,增强企业的市场竞争力。
智能问答系统[1]的概念最早提出于20 世纪60年代,并在此后不断发展。国外在智能问答系统领域取得了一系列研究成果,而国内问答系统的研究起步较晚,1970年后才开始基于汉语的中文问答系统的研究。近年来,智能问答系统取得了很大的发展和进步,已经有很多智能问答系统产品问世,然而这些领域都各自相对独立并且采用了不同的方法,且这些方法都有着各自的瓶颈,所以如何根据企业自身情况寻找合适的理论和算法构建出符合企业实际需求的智能问答系统就变得尤为重要。企业智能问答系统的目标是提供一个及时解决员工各种需求问题的平台,员工在日常工作中一旦不了解办事流程或需要查询任何资料,可以通过使用该问答系统及时得到解答。同时系统还需提供一个管理平台供运营和管理人员使用,负责系统的日常维护和问题管理。本系统应具有较高的问题解决率和回答准确率,在智能问答部分,员工以自然语言的方式输入问题时,系统应通过相关自然语言技术最大程度匹配到最佳答案,并为用户推荐相关问题。
2 系统构建设计
2.1 系统整体架构
企业智能问答系统的目标是提供一个及时解决员工各种需求问题的平台,员工在日常工作中一旦不了解办事流程或需要查询任何资料,可以通过使用该问答系统及时得到解答。同时系统还需提供一个管理平台供运营和管理人员使用,负责系统的日常维护和问题管理。本系统应具有较高的问题解决率和回答准确率,在智能问答部分,员工以自然语言的方式输入问题时,系统应通过相关自然语言技术最大程度匹配到最佳答案,并为用户推荐相关问题。根据以上需求,智能问答系统整体设计架构如图1 所示,该架构需解决的关键问题有如下三个,企业知识库的构建、自然语言处理以及语义相似度匹配算法选取。
2.2 知识库的建立
本平台中知识库中的知识来源分为两类:一类是通过各种途径收集的日常工作中经常遇到的问题以及解决方案,这些问题和解决方案都是经过专业人员审核后归入知识库;另一类是日常工作中相关人员实时发布的消息、制度、新闻、附件、通知等,实时发布后即刻归入知识库。根据工作要求,这两类知识分别存储于不同的服务器,通过数据库连通形成了跨服务器的方式将不同类型的知识以及不同出处的知识汇集在一起,形成多领域、多平台的知识库。
为了解决知识库内容有限,不能包含工作中所有的问题,本平台设计了一个开放性的人机对话窗口,使用者或者管理员可以随时将遇到的问题输入到平台中,其他管理员(或专家)可以对提出的新问题进行解答和补充。由此可以增强本平台的适应能力和学习能力,随着时间的推移,知识库中的知识会越来越丰富,不仅可以提高平台解答问题的能力,对于以后数据的使用提供更多的可能性。
2.3 分词算法的实现
中文分词[2]是中文文本处理的一个基础步骤,也是人-机自然语言交互的基础模块,在进行自然语言处理时,通常需要先进行分词,Jieba 分词是现在非常流行且开源的分词器。Jieba 分词算法首先将停用词去掉,在通过基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG), 再采用了动态规划查找最大概率路径,找出基于词频的最大切分组合。本平台所采用的Jieba 分词原理如下:
2.3.1 去掉通用词
Jieba 分词自带的h_stop_words.txt 中包含常用且无意义的词,例如的、地、在。要、我以及一些特殊符号、数字等,用户可以可根据自己的需求将一些常用写无意义的词放置到h_stop_words.txt中,即可在程序运行时将其去掉。
2.3.2 前缀词典的构造
Jieba 分词自带dict.txt 词典,这个词典中包括词条、词条出现的次数和词性。当程序运行的时候,它会加载统计词典生成前缀词典,它是在统计词典中出现的每一个词的每一个前缀提取出来,统计词频,如果某个前缀词在统计词典中没有出现,词频统计为0,如果这个前缀词已经统计过,则不再重复。
2.3.3 有向无环图(DAG)
以每个字所在的位置为键值key,相应划分的末尾位置构成的列表为value,基于以上构建的键值对,可以构成这个文本对应的有向无环图,并在有向无环图中找出概率最大的路径,即每一个词出现的概率等于该词在前缀里的词频除以所有词的词频之和。如果词频为0 或是不存在,当做词频为1 来处理,概率最大的词为最终的分词结果。
2.4 匹配算法的实现

图1:智能问答系统整体架构
本平台采用的匹配算法是向量空间余弦相似度[3](Cosine Similarity)算法。向量空间余弦相似度计算是指将两个不同的文本或语句映射到向量空间中,形成文本中文字和向量数据的映射关系,通过计算不同向量之间的差异大小来计算文本的相似度。具体方法如下:
(1)分词
例如:
句子A:我今天要去电影院看电影;
句子B:我今天要去看电影;
通过上一节讲解的Jieba 分词方法,对句子A 和B 进行停用词删选及分词,结果如下:
句子A:今天 去 电影院 看 电影
句子B:今天 去 看 电影
(2)列出所有词
今天 去 电影院 看 电影
(3)计算词频
句子A:今天1 去1 电影院1 看1 电影1
句子B:今天1 去1 电影院0 看1 电影1
(4)写出词频向量
句子A:[1 1 1 1 1]
句子B:[1 1 0 1 1]
(5)计算相似度
计算两个向量的相似度是通过计算两个向量的余弦值进行判断。假设向量a(x1,y1)和向量b(x2,y2),则向量a 和向量b 的夹角余弦值计算公式为:
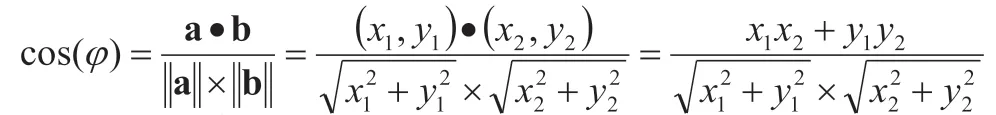
在根据相似度的值进行排序,并设定阈值,将大于阈值的10条信息显示在界面上。
3 系统开发实现
3.1 开发工具及环境
通过软件工程标准开发方案,采用基于MVC 设计模式的Struts2 Web 应用框架,以WebWork 为核心,采用拦截器的机制来处理用户的请求。运用Tomcat 8.5 运行环境、基于MyEclipse 8.5 开发环境进行的系统开发,前端采用HTML5、JSP、JavaScript、jQuery 等开发语言,后端采用JAVA 语言进行开发,并将所有的数据存储于SQL Server2008 数据库中。

图2:系统首页图
3.2 系统功能介绍
企业智能问答系统主要包括主界面、搜索查询界面、信息分类界面以及其他附属界面。
系统首页为用户进入系统后所看到的页面,主要包括搜索查询以及聊天窗口、知识分类相关链接、热搜问题链接、常用网上服务链接等,系统首页如图2 所示。
用户通过左侧搜索查询界面将想要提问的问题进行输入,并将搜索出的相关信息显示在此页面,达到及时搜索及时显示的目的,同时模拟了人-机的聊天模式。搜索查询页面主要包括提问窗口以及聊天界面两部分。
右侧信息分类部分包括了各个部门的门户网站以及各个部门发布的相关信息,用户可在此部分快速浏览到各个部门发布的相关信息,帮助用户更加快速的了解各部门发布的制度、规范等。知识信息分类包括各部门门户网站平台入口链接以及知识信息汇总界面两部分
为方便用户进行权限申请等其他操作,本平台将一些工作中常用的表单连接放在此处。用户可通过右侧常用链接进行新问题的提问以及公司内部网上权限的申请。
3.3 系统创新点
(1)自然语言处理与应用领域相结合。该项目应用于市政设计企业,知识库内容不仅涵盖了企业日常管理中关于财务、人事、物资、质量、经营、档案等相关内容,还包含了生产设计中关于给水排水、热力、暖通、海绵城市等市政行业专业领域内容,具有鲜明行业特色,将行业特色词汇加入自然语言处理过程中,大大提高系统的实用性。
(2)平台知识库构建与云概念相结合。该系统并非独立平台,是依托于企业已有的管理平台而使用,智能管控范围不仅限于平台本地知识库,可跨服务器跨平台获取企业所积累的相关知识信息,丰富全面,避免重复录入,同时可在平台间跳转获取答案,灵活直观。
4 结束语
随着企业管理水平的不断提升,员工对企业各规章制度和办事流程不了解会使工作寸步难行,本文通过Javaweb 技术、Jieba 分词方法和余弦相似度方法搭建智能问答系统,将企业的各种规章制度、办事流程、新闻、相关专业知识等信息集成在一个系统中,并通过数据库连通的方法将不同服务器中的数据进行整合,形成多领域、多平台的知识库。并打造智能人-机界面,用户在前端界面输入自然语言,智能问答系统可通过界面中的智能助手同样以自然语言的形式将匹配度高的答案显示在界面中,并提供多种常用链接入口,提高用户的办公效率,加强企业的信息化发展,降低管理者的工作负担。
