基于Scrapy和Kettle的对标城市政策文件库建设
2021-06-16王胜谢元平
王胜 谢元平
(成都市经济发展研究院(成都市经济信息中心)信息技术与应用研究所 四川省成都市 610032)
城市对标管理是一项系统性工作,涉及城市治理、社会发展方方面面,通过开展政策文件分析比较是学习先进城市经验做法,快速找出自身政策短板的有效途径[1,2,3,4]。政策性文件是国家以权威形式发布的,规定一定历史时期内目标、任务及具体措施的文件。《中华人民共和国政府信息公开条例》明确指出“行政法规、规章和规范性文件”属于主动公开的政府信息,当前各级政府门户网站都已按要求开设“文件”、“规划”等栏目提供政策文件、规划文本的查询服务,这为政策性文件的获取提供了保障及有效途径。传统的政策文件收集整理工作主要采取手工方式,效率较低且及时性较差。随着网络爬虫技术的发展,通过互联网直接采集各地政府网站政策文件,将极大提高信息搜集效率,并为政策研究提供更高的及时性。Scrapy 框架是一个较为成熟的开源网络框架,基于该框架已开展了大量研究工作[5,6,7]以及行业应用。武虹等[8]通过采集互联网上国内外科技政策文件,提供了全文检索、统计分析应用;李乔宇等[9]开展了农业信息的爬取应用。Kettle 是一个开源的ETL 工具,提供了图形化的用户页面,非常适合于开展数据清洗、数据整合应用。许皓皓等[10]利用Kettle 对气象数据ETL 流程进行建模实现了气象数据的实时同步和存储;陈亚东等[11]开展了苹果产业数据的整合应用;陈健等[12]开展了医院数据的集成研究;崔记东[13]、程子傲等[14]将Kettle 集成到数据整合、数据交换平台中取得了不错的效果。通过使用开源工具,能够减少开发成本,非常适合与本文所关注的对标城市政策文件库这样的轻量级应用。
本研究基于Scrapy 框架设计网络爬虫,采集17 个对标城市(地区)政府网站下50 多个栏目的政策文件,利用Kettle 设计开发ETL 程序,对采集的原始政策文件进行信息结构化处理、去除重复等数据清洗操作,并通过开发前端查询、检索应用,形成面向成都市的服务于研究咨询行业的对标城市政策文件库应用。
1 需求分析及方案设计
1.1 需求分析
成都是副省级城市、国家中心城市,成都市的对标对象为其他国家中心城市及副省级城市。城市对标工作不仅仅是比较城市之间的经济指标、查找发展差距,还需要深层次分析背后的发展规律。各类政策文件能够较全面的展示各地在经济发展、城市管理、社会治理上的经验做法,为更好的开展城市之间政策对比分析,学习先进经验做法,有必要建立对标城市政策文件库,服务于对标管理工作。
目前在开展城市之间政策对比分析时,主要采用人工搜索方式,不仅效率低下,而且无法起到政策监测目的。随着网络爬虫技术的发展,利用信息技术从各地政府网站自动采集政策文件成为了可能。同时,Scrapy、Kettle 等开源工具的发展,也降低了开发成本,提供了较高的灵活性。
1.2 流程设计
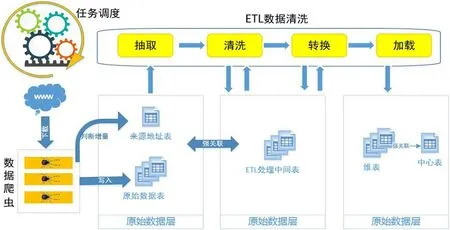
图1:数据获取及清洗流程图

图2:Kettle 中的ETL 过程
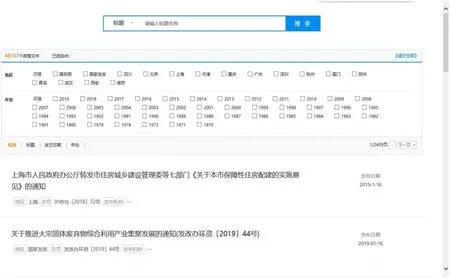
图3:查询检索页面
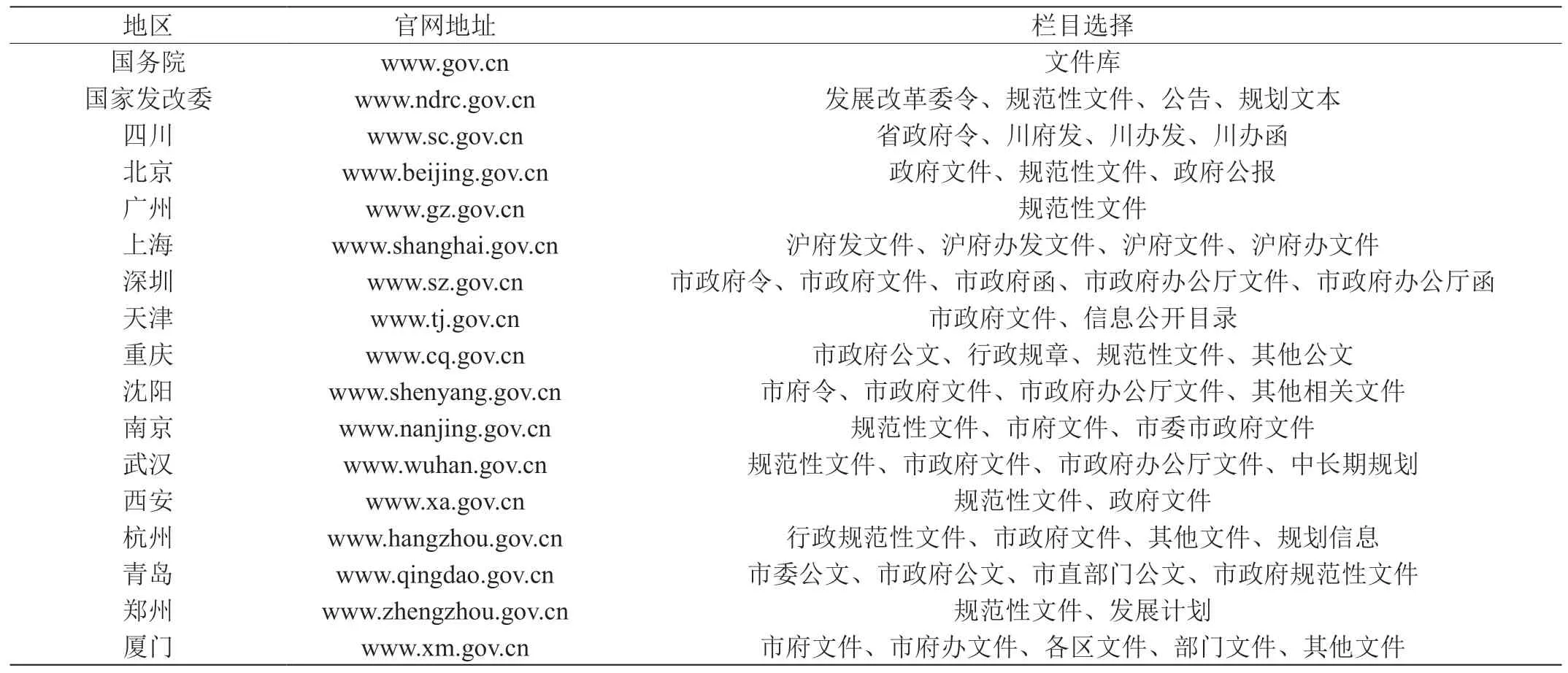
表1:数据源清单

图4:政策文件页面
对标城市政策文件库系统通过网络爬虫采集成都市对标城市政府网站政策文件,通过对采集的信息进行清洗,形成面向研究咨询行业的政策文件查询、检索应用。系统流程见图1。
(1)基于Scrapy 的数据采集系统。包括信息采集、增量抽取、异常处理、日志记录、多任务等功能。Scrapy 是一个开源的网络爬虫框架,本身提供分布式处理、数据持久化、高性能下载等众多功能,通过配合使用phantomjs、webdriver、tesseract、PIL 等其他功能库,基本上能够完成所有类型的网站信息采集任务。
(2)基于Kettle 的ETL 系统。包括数据转换、清洗、ETL 任务调度等功能。Kettle 是一个开源的ETL 功能,提供图形化的开发和运行环境,内置数据关联、过滤、排序、数据运算等基本功能组件,通过组合应用内置的功能组件,能很方便的实现各种数据清洗操作。
2 系统组成
2.1 基于Scrapy的数据采集系统
2.1.1 数据源分析
从成都市城市对标工作的实际需要出发,本文数据源主要为其他国家中心城市以及副省级城市政府网站,并增加国务院、国家发改委、四川省三个政府网站。为从源头做好信息过滤、减小整个政策文件库规模,通过对每个网站政策文件栏目进行分析,重点排除人事任免、项目批复类文件,只选取政策法规、发展计划相关栏目作为每个信息源的具体入口地址。因此整个对标城市政策文件库信息来源为18 个政府网站、超过50 个具体栏目下的所有政策相关数据。数据源清单如表1 所示。
2.1.2 基于Scrapy 的爬虫设计
整个系统的数据采集工作由基于Scrapy 框架开发的网络爬虫来完成。由于每个城市网站的技术实现方式、数据分类、页面布局及附件下载方式都不尽相同,需要对每个网站进行具体分析,为每个网站开发独立的爬虫程序。另外为提高每个爬虫的效率,需要考虑的共性问题还包括:
(1)重复记录的处理。通过维护全局URL 表,判断该页面是否被爬取过,从而减少网络访问量。
(2)初始化及增量的处理。对于每个网站完成一次性初始化爬取工作,并通过每天增量爬取的方式来维持数据完整性。
(3)日志及异常处理。为有效运维系统,需要做好爬虫的详细日志工作,并对程序异常情况进行捕获处理。
2.1.3 基于XPath 的网页信息抽取
政策文件数据主要的属性包括印发日期、发文单位、文号、标题、发布日期等。在本文中,采用基于XPath 的定位方式实现对网页信息的抽取工作。XPath 定位分为绝对路径和相对路径两种,为提高页面的适应性,所有XPath 采用相对路径方式,选择相对固定的元素或属性节点作为信息定位节点。由于网站存在改版、信息发布不规范等原因,基于固定XPath 的抽取规则会出现信息无法定位的问题,引起数据质量问题,需要通过ETL 程序完成对数据的清洗工作。
2.2 基于Kettle的ETL系统
2.2.1 数据分层处理
数据存储选用MySQL 数据库。MySQL 是一个轻量级开源数据库软件,部署方便,并且MySQL 几乎拥有了超大型专业数据库Oracle 提供的大部分功能,能够承载绝大多数的应用。
在数据处理阶段,为使数据结构清晰、数据追踪准确、简化数据处理过程,参考数据仓库设计思想,整个数据存储分为三层:原始数据层、数据整合层、数据应用层。原始数据层用于完整保存爬虫获得的原始数据,同时设计了访问控制机制,过滤已经下载过的地址,降低爬虫工作负载加快数据爬取速度。数据处理层用于ETL清洗过程,在数据清洗过程中产生的中间数据均在处理过程中保持在这一层中。数据应用层用于最终的应用,从最终的应用需求出发设计和存储数据。
2.2.2 基于Kettle 的ETL 设计
如图2 所示,基于Kettle 的ETL 设计主要包括两步:首先通过建立独立的Transformation 模型,实现特定的ETL 功能;其次通过Job 模型将不同的Transformation 模型进行串联或并联,从而实现不同ETL 处理过程的并行及顺序处理。在本文中需要开展的数据清洗处理主要有三类:
(1)关键信息缺失的处理。通过XPath 方式未能抽取关键信息时,需要通过ETL 方式进行数据补充。比如政策文件中的文号信息,可以通过正则表达式“[u4e00-u9fa5]{1,6}(〔|[)[0-9]{4}(〕|])[0-9]{1,4}号”来进行二次定位查找及数据填充。
(2)非关注信息的过滤。虽然在前期我们已通过对网站栏目的选择进行了初步的过滤,但由于各网站栏目设置不同,仍然会存在大量需要过滤的信息,主要是人事任免、项目批复类文件,因此需要通过ETL 程序进行过滤处理。
(3)多源数据融合。这里主要是对重复的数据进行去重处理。有些地方网站会直接转载国务院、国家发改委文件,因此需要进行去重操作。同时为适应爬虫及ETL 程序重复运行可能造成的数据重复,也需要进行去重操作。
2.3 系统调度及展示
任务调度可采用的方式有三种,第一种是直接使用第三方任务调度软件,比如开源调度工具Quartz,Kettle Manager 等,第二种是使用数据清洗工具中的计划,比如Kettle 中Job 上可设置的计划任务,第三种是使用操作系统的计划任务工具。本文在Scrapy 框架中已实现对爬虫的多任务处理,在Kettle 中已通过Job 方式实现对ETL 过程的执行管理,对于调度要求简单,综合考虑最终采用操作系统自带的计划任务工具方式。考虑各地政策文件发布的时间窗,结合爬虫及ETL 过程的运行时间,本文的调度设计为每天7:00和12:00 各执行一次。
通过开发前端展示页面,实现了基于关键词、地区、年份的政策文件查询、检索应用。图3-图4 展示了部分应用页面。
3 系统应用
对标城市政策文件库通过对17 个城市(地区)政府网站政策文件相关栏目进行数据采集,并通过数据清洗,形成查询、检索应用,截止2019年1月,经过清洗有效入库数据48167 条。相关课题组通过筛选与创新创业相关政策文件,开展了双创政策文件的对比分析研究,为政府提供了决策参考建议。
4 结论
对标城市政策文件库系统基于Scrapy 框架设计针对不同政府网站的网络爬虫,利用Kettle 设计开发ETL 程序对数据进行信息结构化、去除重复等清洗操作,并为用户提供了查询、检索应用。系统有效入库政策文件超过48000 条,为成都市开展城市对标工作、城市之间政策对比研究提供了有效的途径。下一步需要重点考虑网站改版带来的风险,研究适应性更强的信息抽取模式及规则,增强爬虫程序的错误处理机制,同时进一步分析数据质量提升数据清洗能力,为更好的开展对标城市政策研究提供支持。
