基于Logistic模型的公司债券信用风险评估
2021-06-15洪宇廷
洪宇廷


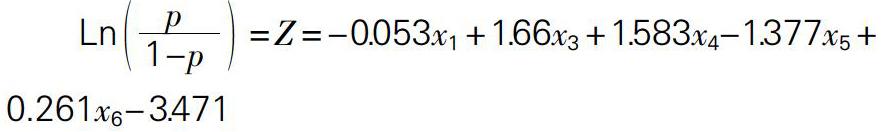
【摘 要】随着金融市场不断发展与变化,公司债券作为公司筹集资金的重要方式之一,面临着越来越多的风险,对公司债券发行方的债券信用风险进行研究能够帮助投资者更好地甄选优质债权,降低买到垃圾债券的概率。文章以上海证券交易所5 372只债券为样本库,随机抽取376组数据,以公司财务指标为依据,共选取10个指标,经过正向纳入和反向剔除之后,以资产负债率、流动比率、速动比率、总资产周转率、净资产收益率5个指标为依据,建立Logistic逐次回归模型,对债券发行主体的债券信用风险进行评估。
【关键词】Logistic模型;信用评价模型;财务指标;逐步回归
【中图分类号】F275;F832.51【文献标识码】A 【文章编号】1674-0688(2021)03-0152-03
1 文献综述
关于信用风险评价的方法主要为以下几种,分别是Logistic回归模型、BP神经网络、决策树、层次分析等[1]。中国债券市场于2014年3月4日首次出现债券违约时间。债券市场对信用风险长期以来的弱化,使投资者产生了错误的判断。据Wind数据库统计,截至2017年我国违约债券数量为78只,涉及未偿还金融达到393亿元。2018年受金融去杠杆与供给侧结构性改革、宏观经济GDP增速下行、債券集中挤兑等多方面因素的影响,累计违约债券已达120只之多,违约余额高达1176.51亿元,信用风险大幅扩大。我国金融市场经过不断发展与完善,信用风险问题日渐严重。Gurdip(2006)研究发现影响债券信用风险的重要因素之一就是企业财务绩效,财务杠杆比率每提高1个百分点,信用风险溢价就会提高5到10个百分点[2]。SpencerMartin(2002)分别基于短期利率和公司特有的财务困境指标,对公司债券信用风险评价模型进行了构建。研究表明,短期利率对债券利差的影响最明显[3]。
2 数据预处理
2.1 数据来源
本文选取上海证券交易所截至2019年12月20日的全部5 372只公司债券。源数据包包括正常交易债券5 154只,连续停牌、盘中停牌和暂停上市债券101只,数据不全债券117只。源数据在剔除数据不全与离差较大的债券之后,余下64只连续停牌、盘中停牌和暂停上市的债券,4 143只正常上市的股票。
根据有关研究表明,当正常客户的数据比违约客户多出3~5倍时,回归分析更有效,模型更准确。因此,本文从4 143只正常股票中随机抽取312只正常债券作为建模样本数据。通过Choice金融终端获取了样本数据的各项财务指标,从中选取了10种指标数据用于构建模型,分别为资产负债率x1、权益乘数x2、流动比率x3、流动比率x4、总资产周转率x5、净资产收益率x6、股东权益x7、净利润/利润总额x8、投入资本回报率x9、注册资本x10。被解释变量以债权是否正常上市为区分标准,设为y,其中正常上市的债券记为1,连续停牌,盘中停牌和暂停上市的债券记为0。
2.2 数据处理
数据处理包括数据清理和数据转换两个步骤,主要目的是处理不一致、不完整的数据。为提高模型准确性,删除离差较大的数据[4]。文中采用上海证券交易所的公司债数据对发债公司信息审核比较严格,数据比较完整,因此不需要填补某些空白值,只需删除债券名、发债主体评级信用等级及证券代码等无关变量,提高回归准确性。
3 回归模型的构建
3.1 建立模型
Logistic模型作为一种多变量统计分析方法,主要研究二分类变量或多分类变量的观测结果数据与解释变量之间的相对关系。因变量可以是二分非线性差分方程类的,也可以是多分类的,但二分类更常用,也更加容易解释,所以实际中最常用的就是二分类的[4]。
本文模型回归的基本思想是假设y表示公司债券未来是否正常上市,y=1表示公司债券未来正常上市,y=0表示公司债券未来出现连续停牌、盘中停牌或者暂停上市的现象,用“1”和“0”作为被解释变量的取值进行回归。
模型的具体定义如下:假设存在N个自变量,记为x1,x2,…,n;在n个自变量的共同作用下出现因变量取1,即公司债券正常上市交易的概率,记为p={y=1|x1,x2,…,xn},则回归模型如下:
其中,β0为截距项或常数项,β1,β2,…,βn为权重向量。那么,违约概率:
3.2 实证检验
运用Stata软件,将处理完成的数据输入进行正向纳入和反向淘汰的回归分析。逐步回归法的基本思路是将变量逐个引入模型,在每引入一个解释变量之后都要进行一次显著性检验,如果新加入的解释变量导致原来引入的变量变得不再显著时,则将原来引入的变量删除,保证每次引入新变量时,回归方程中只包含显著性变量。将这个过程反复进行,直到既没有显著的解释变量加入回归方程,又没有非显著的解释变量要从解释变量中删除时,得到最优的解释变量集,由于本文选取的变量较多,运用逐步回归法进行回归分析可以有效解决变量之间的多重共线性问题。为排除方法不同而出现差异的可能性,本文分别使用正向纳入和反向剔除两种方法对数据进行分析,分析结果见表1。
正向纳入法的基本思路为首先对各变量分别进行回归分析,然后判断各变量的显著性。模型零假设为某回归系数与零没有显著的差异,相关的解释变量与Logistic p之间不存在显著的线性关系。如果P值小于设定的5%则应该拒绝零假设,认为该解释变量与Logistic p具有显著的线性关系,将其保留在方程之中。由上述回归结果可以看出,经过多次回归后,最终留在回归模型里的变量为x1,x3,x4,x5,x6,而其余5项指标与Logistic p在5%的置信水平下并不具有显著的线性关系,故而将这5个变量从模型中提出。求得的Logistic回归方程如下:
表2为通过反向剔除法得到的实证结果,反向剔除法与正向纳入法正好相反,它先将各个变量全部纳入回归方程之中,然后检验各变量的显著程度,将最不显著的变量剔除,然后余下的变量继续进行回归,再将新一轮回归中最不显著的变量剔除,直至全部变量都显著时,得到最终的回归模型,同正向纳入法一样,反向剔除法同样可以排除个变量之间存在共线性的问题,使回归得到的结果更为准确。由表2可知,正向纳入法和反向剔除法的回归分析结果完全一样,从而排除了方法选择上的误差。
4 结论与建议
本文基于金融终端Choice平台上借款人真实数据,根据中国公司债券的基本风险特征,从发债主体公司的各项财务指标出发建立了公司债券投资的发债主体公司信用风险评估体系。引入了在稳定性方面具有比较优势的Logistic回归模型,得出影响发债主体公司信用风险的主要因素是资产负债率、流动比率、速动比率、总资产周转率、净资产收益率5项指标,可以为公司债券交易平台和债券投资者在判断发债主体公司未来的违约风险时提供一定的参考。
基于上述实证结果,结合中国公司債券市场实际情况,提出以下两点建议:?譹?訛发债主体公司外部。信用评级是投资者在购买公司债券时重要的参考目标,现有的各评级平台之间可以建立统一、规范的信用评分系统,减少各平台的信息收集成本,减少信息不对称,帮助债券投资者更有效的获得债券发行主体的信用信息,更好地规避风险。?譺?訛债券评级公司之间。各债券评级公司可以建立信息共享平台,将各平台收集的信息共享,减少各平台的信息采集成本。
参 考 文 献
[1]舒方媛,赵公民,武勇杰.P2P网贷借款人违约风险影响因素研究——基于Logistic模型的实证分析[J].湖北农业科学,2019(4):103-107.
[2]Gurdip Bakshi,Dilip Madan,Frank Xiaoling Zhang.Investigating the Role of Systematic and Firm-Specific Factors in Default Risk:Lessons from Empirically Evaluating Credit Risk Models[J].The Journal of Business,2006(4):54-56.
[3]PierreCollin-Dufresne,Robert S Goldstein,J Spen-cer Martin.The Determinants of Credit Spread Ch-anges[J].The Journal of Finance,2002(6):23-26.
[4]刘元鹏,田国忠,白芳.基于信用债违约概率模型评估债券业务的风险研究[J].中国证券期货,2019(5):69-74.
