基于深度学习的命名实体识别研究综述
2021-06-11何玉洁史英杰宋丽娟
何玉洁,杜 方,史英杰,宋丽娟
1.宁夏大学 信息工程学院,银川750000 2.北京服装学院 信息工程学院,北京100029
命名实体识别(Named Entity Recognition,NER)是自然语言处理的一项基本任务[1]。主要是将非结构化文本中的人名、地名、机构名和具有特定意义的实体抽取出来并加以归类,进而组织成半结构化或结构化的信息,再利用其他技术对文本实现分析和理解目的。这对于文本的结构化起着至关重要的作用。命名实体识别技术在信息抽取、信息检索、问答系统等多种自然语言处理技术领域有着广泛的应用。命名实体识别研究历史最早可以追溯到1991年,Rau[2]在第七届IEEE人工智能应用会议上发表了“抽取和识别公司名称”的有关研究文章,陆续出现一些有关名词识别的研究。1996年,“命名实体(Named Entity,NE)”一词首次用于第六届信息理解会议(MUC-6)[3],会议将命名实体评测作为信息抽取的一个子任务。随后出现了一系列信息抽取的国际评测会议,诸如CONLL、IEER-99、ACE等,这些评测会议对命名实体识别的发展有极大的推动作用。
命名实体识别的主要技术主要有三类:基于规则和字典的方法、基于统计机器学习的方法、基于深度学习的方法。(1)基于规则和字典的方法是命名实体识别中最早使用的方法。基于规则的方法要构造大量的规则集,规则集的构建大多采用语言学专家手工构造的规则模板。基于词典的方法需要建立命名实体词典,命名实体识别的过程就是在字典或专业领域知识库中查找的过程。早期的命名实体识别任务大多采用基于规则和词典的方法实现。Grishma等人[4]利用一些专门的名称字典,包括所有国家的名称、主要城市的名称和公司名称等开发了一种基于规则的命名实体识别系统。由谢菲尔德大学自然语言处理研究小组开发的GATE项目中的ANNIE[5]系统就是基于规则方法的英文信息抽取系统。Collins等人[6]提出的DL-CoTrain(DL代表决策列表,术语Co-train取自于Blum和Mitchell[7])方法,先将决策列表设置成种子规则集,再对该集合进行无监督的训练迭代得到更多的规则,最终将规则集用于命名实体的分类。基于手工规则的方法虽然在小数据集上可达到较高的准确率,但面对大量的数据集以及全新领域,这种方式变得不再可取,旧的规则不适用于新命名实体识别词汇,新的规则库和词典的建立需要花费大量的时间及人力,并且这些规则往往依赖于具体语言。如应用于英语的规则难以应用于阿拉伯语,难以涵盖所有的语言,规则之间常有冲突,有较大的局限性。因此这种方法逐渐被后来的基于统计的机器学习方法所替代。(2)基于统计的机器学习方法是利用人工标注的语料进行有监督训练,然后利用训练好的机器学习模型实现预测。基于统计机器学习的模型有隐马尔可夫模型(Hidden Markov Models,HMM)、最大熵模型(Maximum Entropy Models,MEM)、决策树(Decision Trees)、支持向量机(Support Vector Machines,SVM)和条件随机场(Conditional Random Fields,CRF)等。Bikel[8]在1999年提出了基于隐马尔可夫模型的IdentiFinderTM系统,识别和分类名称、日期、时间和数值等实体,在英语和西班牙语等多语言上都获得了较好的成绩。Isozaki[9]将SVM应用在命名实体识别问题上,在CRL数据(该数据集基于Mainichi Newspape1994年的CD-ROMs[10])上F值(F值是统计学中用来衡量模型精确度的一种指标。现被广泛应用在自然语言处理领域,比如命名实体识别、分类等,用来衡量算法的性能)达到了90.3%。Yamada等人[11]针对日文提出了第一个基于SVM的命名实体识别系统,他的系统是Kudo的分块系统(Kudo and Matsumoto,2001)[12]的扩展,该分块系统在CONLL-2000任务中取得了最好的结果。Lin和Tsai等人[13]将最大熵方法与基于词典匹配和规则相结合,用来识别文本中的生物实体。先手动制定规则,再将制定好的规则输入到最大熵模型框架中,提高了系统的准确率与召回率。基于统计机器学习的方法与之前的方法相比,效果上有了明显的提高,但是也需要具有专业领域知识的人进行大量人工标注,人工和时间的成本很高。(3)随着深度学习的兴起,使用深度学习方法解决命名实体识别问题成为了研究热点。该类方法的优势在于神经网络模型可以自动学习句子特征,无需复杂的特征工程。本文着重在第2章介绍基于深度学习的命名实体识别研究进展。
1 基于深度学习的命名实体识别方法
深度学习是深层神经网络的简称[14]。近些年来,深度学习不仅在计算机视觉、图像处理等方面取得了巨大的成功,而且在自然语言处理领域也取得了很大的进展。基于深度学习的NER模型已经成为主流。深度学习模型对外部输入数据进行逐层特征提取,通过非线性激活函数从数据中学习复杂的特征,完成多层神经网络的训练和预测任务。目前,在命名实体识别领域中最流行的深度学习模型是卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)。
1.1 基于卷积神经网络的命名实体识别方法
卷积神经网络(CNN)是一种深度前馈神经网络。Collobert等人[15]提出了基于窗口的(window approach)和基于句子的(sentence approach)两种方法来进行NER,这两种结构的主要区别在于window approach仅使用当前预测词的上下文窗口进行输入,然后使用传统的NN结构;而sentence approach是以整个句子作为当前预测词的输入,加入了句子中相对位置特征来区分句子中的每个词,然后使用了一层卷积神经网络结构,利用卷积获取上下文并将提取的局部特征向量来构造全局特征向量,该方法虽然可从大量未标记数据中进行特征学习,但其无法解决远程依赖的问题。Santos等人[16]通过整合字符级CNN来扩展了这个模型,实验结果证明,对于葡萄牙语和西班牙语NER都有明显效果。Yao等人[17]提出一种基于CNN的生物医学命名实体识别模型,使用skip-gram神经网络模型,该模型虽然不是最快的,但更适合于像医学文献中稀有词的训练。Strubell等人[18]提出了迭代卷积神经网络(Iterated Dilated Convolutional Neural Network,ID-CNN),IDCNN扩张的卷积、有效输入宽度可以随深度呈指数增长,比传统的神经网络具有更好的上下文和结构化预测能力。Wu等人[19]构建了一种针对中文电子病历命名体识别的深度神经网络,实验结果表明其模型优于其他CRF模型。Gui等人[20]提出目标保持对抗神经网络(Target Preserved Adversarial Neural Network,TPANN),使用大量其他领域注释数据、领域内未标记数据和少量标记领域内数据解决社交媒体领域缺乏大规模标记数据集问题。Yang等人[21]采用与文献[22]相同的结构,使用具有最大池的一层CNN来捕获字符级表示,获取每个词的上下文表示后,在最后的预测层使用基于Softmax和CRF的结构。以上命名实体方法都是在卷积神经网络的基础上进行改进从而达到不同效果,其识别方法的基本原理和核心公式见表1。
1.2 基于循环神经网络的命名实体识别方法
循环神经网络(RNN)是一类以序列数据为输入,所有节点(循环单元)按链式连接的递归神经网络。RNN的变体长短期记忆模型(Long Short-Term Memory,LSTM)和门控循环单元(Gated Recurrent Unit,GRU)都在数据建模方面取得了显著的成就。Huang等人[23]首次将双向LSTM-CRF(简称BILSTM-CRF)模型应用于自然语言处理(Natural Language Processing,NLP)基准序列标记数据集,如图1所示。由于采用了双向LSTM组件,该模型可以捕捉到当前时刻t的过去和未来的特征,但该方法需要大量的特征工程。实验结果表明BILSTM-CRF是稳健的,且对于词嵌入的依赖较少,即它不需要依靠嵌入词就可以产生精确的标注性能。
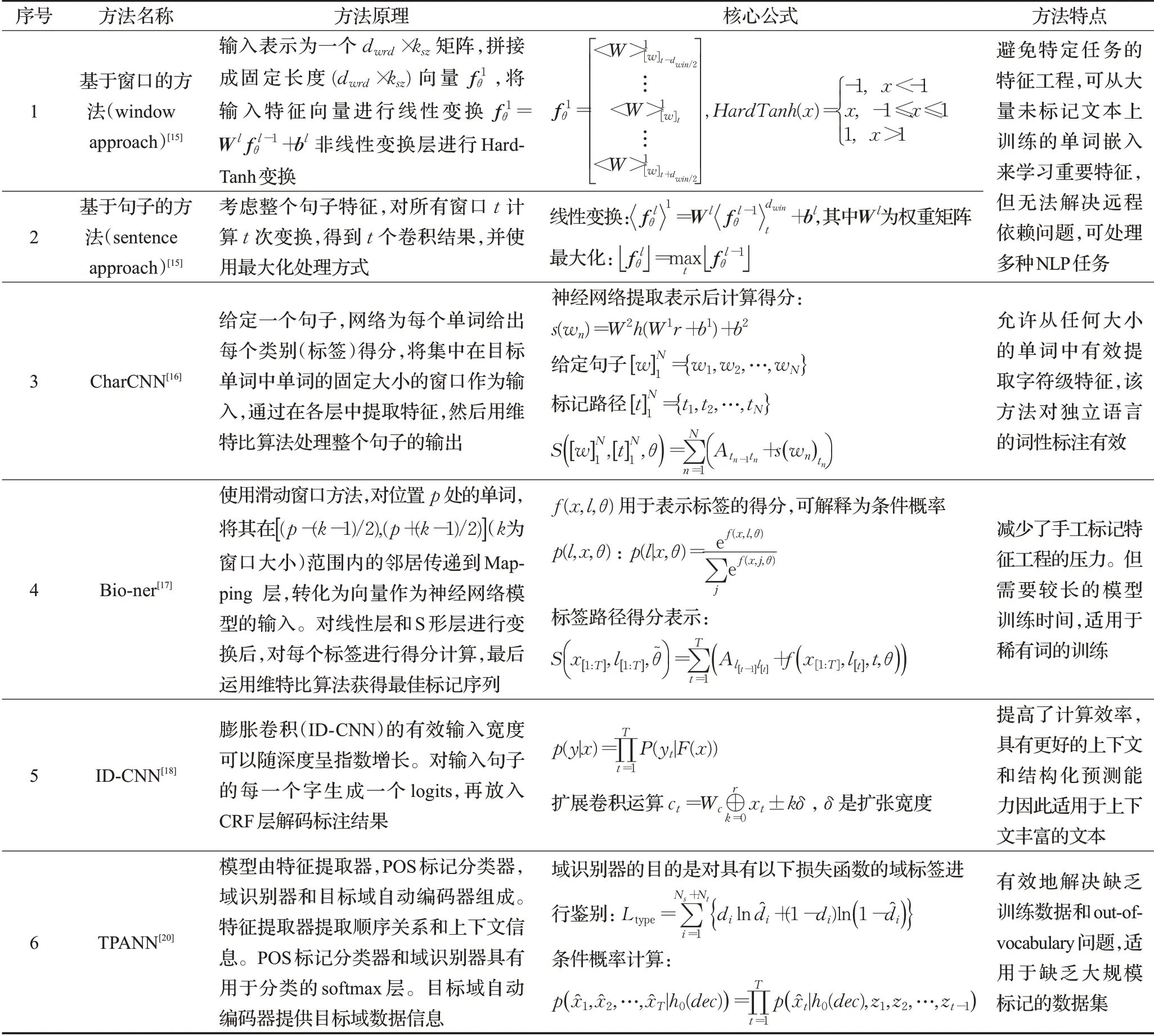
表1 基于卷积神经网络命名实体识别方法原理及公式

图1 基于循环神经网络的命名实体识别模型图
Chiu等人[24]受到Collobert等人[15]的工作启发提出了一种新颖的神经网络结构,该架构使用混合双向LSTM和CNN架构自动检测字和字符级特征,从而消除了对大多数特征工程的需求。该模型在CONLL2003数据集上获得了90.91%的F值。Yang等人[25]提出一种用于序列标记的深层次递归神经网络,在字符和单词级别上使用GRU来编码形态和上下文信息,并应用CRF字段层来预测标签。该模型在CONLL2003英语NER取得91.20%的F值。Ma等人[22]通过使用双向LSTM、CNN和CRF的组合,使模型能够从词和字符级表示中学习,实现真正意义上的端到端,无需特征工程或数据预处理,可适用于各种序列标记任务。Zhang等人[26]提出了一种用于中文NER的网格LSTM模型,该模型能够将单词本身的含义加入基于词向量的模型中,以此避免了中文分词错误所带来的影响,在MSRA语料上达到了93.18%的F值,但对于中文汉字的多义性,该方法还有一定的局限性。Rei[27]提出了一种神经序列标记体系结构,使用海量无标注语料库训练了一个双向LSTM语言模型,每个LSTM将来自前一时间的隐藏状态与来自当前步骤的单词嵌入一起作为输入,并输出新的隐藏状态。实验结果表明,在少量标注数据上,该语言模型能够大幅提高NER的效果。Cui等人[28]提出了一个hierarchically-refined representation的模型,该模型的第二层LSTM输入包含两方面的信息,一个是上一层的输出,另外一个来自于label信息,这样除了文本特征外,上层网络还可以学到label之间的关系。基于循环神经网络的结构可以保存前后时刻的状态信息,因此该网络衍生出了多种不同的命名实体识别方法,其方法原理和公式见表2。

表2 基于循环神经网络命名实体识别方法原理及公式
1.3 基于Transformer的命名实体识别方法
2017年,Transformer模型的提出成为近几年NLP领域最有影响力的工作。Transformer模型由Vaswani等人[29]提出,其模型架构和大多数神经网络序列模型架构一样采用了encode-decode结构。Transformer模型摒弃了递归和卷积操作,完全依赖于注意力(attention)机制,通过多头自注意力(Multi-headed self-attention)机制来构建编码层和解码层。其编码器(encoder)由6个编码块(block)组成,每个块由自注意力机制和前馈神经网络组成,解码器(decoder)由6个解码块组成,每个块由自注意力机制,encoder-decoder attention以及前馈神经网络组成。与已有的模型相比,RNN通过逐步递归获得全局特征,CNN只能获取局部特征,通过堆叠多层卷积来增大感受野,而Transformer模型通过参数矩阵映射,进行Attention操作,并将该过程重复多次,最后将结果拼接起来,就能一步到位获取全局特征。其模型结构图如图2所示[29]。

图2 Transformer模型图
Yan等人[30]针对Transformer无法捕获方向信息及相对位置等问题对模型做出改进,提出了TENER(Transformer Encoder for NER)模型,设计了带有方向与相对位置信息的atteniton机制。该模型在MSRA中文语料上F值达到92.74%,在英文数据集OntoNotes5.0上F值达到88.43%。Google在2018年提出了采用双向Transformer网络结构来进行预训练的语言模型BERT[31](Bidirectional Encoder Representations from Transformers),成功地在当年11项NLP任务中取得了令人瞩目的成绩,成为目前最好的突破性技术之一。因此越来越多的研究者也开始将BERT引入命名实体识别任务。
杨飘等人[32]在中文命名实体识别任务上引入BERT预训练模型,提出了BERT-BIGRU-CRF网络结构,该模型在MSRA中文语料上可以获得较好的效果,并且超过了Zhang等人[26]提出的网格LSTM,F值达到95.43%,比网格LSTM高出2.25%。但该方法的参数量更大,所需的训练时间也更长。Souza等人[33]结合BERT的迁移能力和CRF的结构化预测,将BERT-CRF架构用于葡萄牙语的NER任务,采用基于微调的迁移学习方法,将所有权值在训练过程中联合更新,通过使交叉熵损失最小化来对模型进行优化。该模型的效果比之前最先进的(BiLSTM-CRF+FlairBBP)[34]模型表现更好。实验在只包含人、组织、位置、值和日期五类实体的情况下,F值提高了1%,在包含十类实体(位置、人员、组织、值、日期、标题、事物、事件、抽象和其他)的情况下F值提高了4%。Symeonidou等人[35]提出基于Transformer的BioBERT(Biomedical Named Entity Recognition BERT)模型,并利用迁移学习方法帮助完成生物医学信息提取任务。BioBERT模型善于捕捉上下文信息,有助于模型性能的提高。Khan等人[36]提出了一种多任务Transformer模型对生物医学进行命名实体识别。将使用包含不同槽类型的多个数据集训练一个槽标记器视为一个多任务学习问题,通过Transformer模型的编码器捕获输入表示的上下文信息,并生成共享的上下文嵌入向量。最后,对于每个任务/数据集生成一个特定的任务表示。该方法在时间和内存方面的效率和效果都有提升。Yu等人[37]将视觉信息融入到NER中,提出了一个基于Transformer的多模态架构,将标准Transformer层与跨通道注意机制结合起来,分别为每个输入单词生成图像感知的单词表示和单词感知的视觉表示。检测命名实体并识别给定的<句子,图像>对的命名实体类型。以上方法的原理及公式见表3。
1.4 其他的命名实体识别方法
近年来在基于深度学习的命名实体识别研究上,除了基于卷积神经网络和循环神经网络的方法外,还涌现了一些新的方法。Zhou等人[38]针对表示差异和资源不平衡问题提出了双对抗迁移网络(Dual Adversarial Transfer Network,DATNET),主要面向资源匮乏的NER,大量的实验证明了DATNET相对于其他模型的优越性,并在CONLL NER数据集上实现了最新的性能。Lee等人[39]通过将训练过的人工神经网络(Artificial Neural Networks,ANNs)参数转移到另一个有限人工标记的数据集,改善了在两个不同数据集上实体识别的最新结果。证明了迁移学习对于少量标签的目标数据集的有效性。Rei等人[40]在BILSTM-CRF模型结构基础上,重点改进了词向量与字符向量的拼接。使用attention机制将原始的字符向量和词向量拼接改进为权重求和,使用两层传统神经网络隐层来学习attention的权值,这样就使得模型可以动态地利用词向量和字符向量信息。实验结果表明比原始的拼接方法效果更好。Yang等人[41]提出了一种基于深层次递归神经网络的迁移学习方法,该方法在源任务和目标任务之间共享隐藏的特征表示和部分模型参数。实验结果表明,当目标任务标签较少且与源任务更相关时,该方法可以显著提高目标任务的性能。Yoon等人[42]提出一个新型的NER模型CollaboNet,由多个BILSTM-CRF模型组成,将每个BILSTM-CRF模型作为一个单任务模型。每个单任务模型都在特定的数据集上进行训练,并且每个单任务模型都只识别特定的实体类型,这些单个单任务模型互相发送信息,将自身所学到的知识转移到其他单任务模型上,从而获得更准确的预测。Akbik等人[43]动态地构建了上下文embedding的“内存”,存储每个词生成的word embedding,并应用一个池操作来提取每个单词的全局表示。这样使得词的embedding不仅与当前的句子有关,还有文档中的前文有关。该方法可以有效解决在未指定的上下文中嵌入罕见字符的问题。在CONLL2003英语数据集上达到了最高F值93.18%,德语达到88.27%。Ju等人[44]为解决文本内部嵌套实体识别问题,提出一种新的神经网络模型来识别嵌套实体,通过动态叠加平面NER层来识别嵌套实体。模型将当前平面NER层中的LSTM层输出合并起来,并随后将它们提供给下一个平面NER层,这就允许模型以由内到外的方式,通过充分利用在相应的内部实体中的编码信息来提取外部实体。该动态模型在嵌套NER上的性能优于之前的基于特征系统。其方法、原理及公式见表4。

表3 基于Transformer命名实体识别方法原理及公式
1.5 基于深度学习的命名实体识别方法对比
本节对基于深度学习的三大主流方法:基于卷积神经网络、基于循环神经网络和基于Transformer模型进行了对比。总的来说,三种方法的主要差别在于:(1)卷积神经网络和Transformer模型可以并行运行,训练时间相对于循环神经网络要短;(2)卷积神经网络主要注重局部特征,而循环神经网络更注重全局特征;(3)卷积神经网络输入元素之间相互独立,难以考虑上下文信息,循环神经网络能够预测长距离特征,善于发现和利用数据中的长期依赖性,可有效利用过去特征和未来特征,Transformer模型通过attention机制可更好地捕获长距离依赖关系。表5从方法特点、优点、缺点这几个方面对相关方法进行了归纳总结。

表4 其他命名实体识别方法原理及公式

表5 基于深度学习的命名实体识别方法对比
2 基于深度学习的命名实体识别应用领域
随着NER技术的不断成熟,目前基于深度学习的命名实体识别已逐渐应用到多个应用领域并取得了不错的效果。命名实体识别主要应用于生物医学领域[17,42,45-59]、社交媒体[20,60-75]、地理实体识别[76-79]、军事领域[80-84]、商品名称实体识别[85-87]、化学实体识别[88-90]等。表6总结了一些应用领域的代表方法及其贡献。
2.1 生物医学领域
生物医学领域为目前的研究热点,生物医学文本的快速增长使得信息提取成为生物医学研究的重要基础。大量的生物医学知识主要以非结构化的形式存在于各种形式的文本中,将命名实体识别应用于生物医学领域对生物医学研究具有重要的应用价值。由于生物医学数据的庞大以及其存在的词表外问题,传统的方法不能达到高效的识别性能,因此,专家们开始将基于深度学习的命名实体识别方法应用到生物医学领域。基于深度学习的方法可以减少特征工程的依赖[45,47]。Gridach等人[45]第一个使用深度神经网络结合条件随机场提取生物医学文本中基因、蛋白质等生物医学命名实体。通过使用LSTM和CRF的组合,消除了大多数特征工程任务的需要,超越了以前传统方法,同时减少了词表外问题,这对复杂的医学文本来说是至关重要的。
基于深度学习的方法往往需要高质量的标记数据,这对医学NER来说是一个难题,为了解决该问题,学者们研究了如何使用未标记的文本数据来提高NER模型的性能[17,51,53,56]。Yao等人[17]基于未标记的生物医学文本数据,利用CNN对文本信息中所含的蛋白质、基因、疾病和病毒等4类名称进行了实体识别,并在生物医学文本中用特定标签标记。该方法在GENIA数据集上F值达到71%。Fries等人[51]建立了SWELLSHARK生物医学命名实体识别(NER)系统的框架,不需要手工标记数据。该方法将像词典这样的生物医学资源通过一个生成模型自动生成大规模的标记数据集。该架构可以在更短的时间内自动构建大规模的训练集。Sachan等人[56]在未标记的数据上训练了一个双向语言模型(Bidirectional Language Model,BiLM),并将其权重转移到与BiLM架构相同的NER模型的“预训练”中,通过语言模型的权重来初始化NER模型,使NER模型具有更好的初始化参数,然后用Adam优化器来微调预训练模型。实验表明,NER模型权重的这种预处理对于优化器来说是一种很好的初始化方法,与随机初始化的模型相比,预训练的模型需要更少的训练数据。在模型微调期间,预处理模型也收敛得更快。为解决数据缺乏和实体类型错误分类的问题,Yoon等人[42]提出了利用多个NER模型的组合的CollaboNet。在CollaboNet中,在不同数据集上训练的模型相互连接,这样目标模型就可以从其他合作者模型中获得信息,以减少误报。
近年来,基于深度学习的方法被广泛应用到生物医学命名实体识别中,并取得了不错的结果。但深度学习方法往往需要大量的训练数据,数据的缺乏会影响性能。生物医学命名实体识别数据集是稀缺资源,每个数据集只覆盖实体类型的一小部分。此外,许多生物实体具有多义性,这也是生物医学命名实体识别的主要障碍之一。
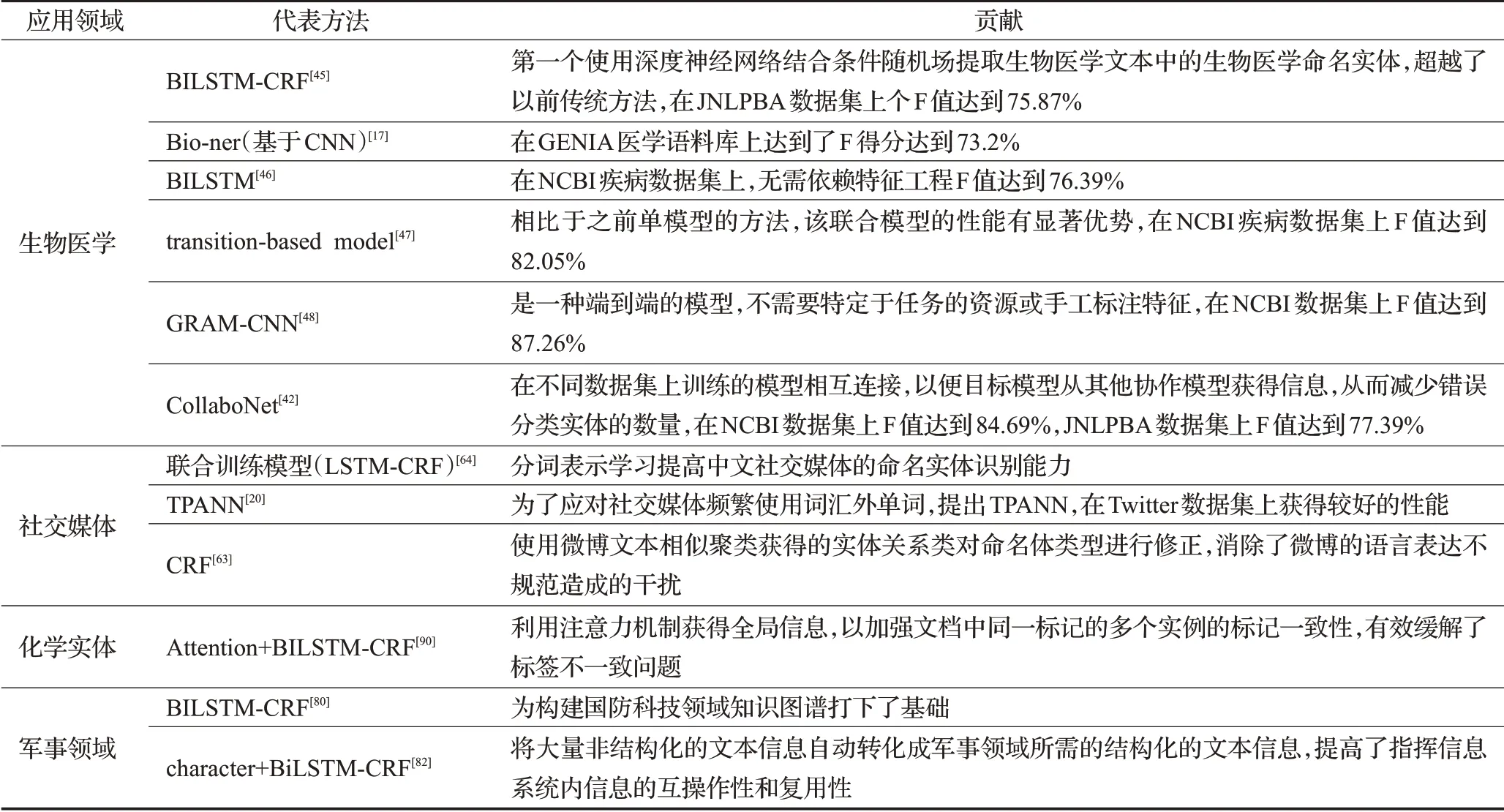
表6 各应用领域的代表方法及其贡献
2.2 社交媒体领域
产生大量数据信息的社交媒体也是命名实体识别的一个重要应用领域。随着新媒体的发展,来自网络新闻传播的信息要远多于传统新闻媒体,因此,在社交媒体上进行命名实体识别任务可挖掘更有价值的信息,可在此基础上实现对社交平台上不同的数据流进行分析,如检测事件、热点话题等。但由于其多样性,社交媒体数据往往含有不恰当的语法结构和大量非正式缩略语。这也促使研究者们提出了多个有效的识别方法。
Twitter作为互联网上访问量最大的十个网站之一,其产生的大量数据信息成为NER领域的研究热点[60-62,66,68,73-74]。Li等人[62]提出了一个无监督NER系统,称为TwiNER。利用从维基百科和网络语料库中获得的全局上下文,使用动态编程算法将推文划分为有效的片段(短语)。每个这样的推文片段都是一个候选命名实体。然后通过一个随机游走模型(Random Walk Model)计算每个片段成为命名实体的概率。实验结果表明在目标数据集上,其效果优于LBJ-NER[91]模型。Tran等人[74,92]针对Twitter数据多样性问题,利用主动学习和机器学习结合的方法,降低了标注数据成本,扩大训练数据的覆盖领域,提高了识别效果。Aguilar等人[93]提出一个多任务神经网络,采用了通用的命名实体分割的次要任务和细粒度命名实体分类的主要任务,从单词和字符序列中学习特征表示。方法对社交媒体中的公司、创意、团队、位置、人名、产品等信息进行了识别,实验结果反映出最难识别的是创意这类实体,识别准确率最高的是人名。
随着NER在英文社交媒体上取得了不错成果,很多学者对中文社交媒体也展开了研究[63-64,69-71]。Peng等人[64]提出了一种允许联合训练学习表示的集成模型,在中文社交媒体新浪微博文本中识别人名、组织和位置等实体。He等人[70]提出了一个统一的模型,可以从域外语料库和域内未标注文本中学习。统一模型包含两个主要功能,一个用于跨领域学习,另一个用于半监督学习。跨领域学习功能可以基于领域相似性学习领域外的信息,半监督学习功能可以通过自我训练来学习领域内未标注的信息。在中国社交媒体上,这两种学习功能都优于NER的现有方法。目前,由于社交媒体往往是更新速度最快,新词汇出现最多的领域,且其中含有很多不完整文本信息以及用户生成的大量噪声文本,使得该领域命名实体识别任务变得更加困难和富有挑战性。
2.3 化学领域
化学物质对各个生命系统的影响使其成为生物医学和临床医学应用中一类重要实体,因此化学实体的识别对生物医学、化工产业等领域都有重要的意义。在文献中,化学品的命名方式多种多样,有缩略语、新化学品命名名称、化学符号、化学元素、化学公式等,这样复杂的数据集给化学实体识别带来了挑战。Tchoua等人[94]针对这些问题,使用主动学习来有效地从专家那里获取更多的专业标记的训练数据,从而提高模型性能。Luo等人[90]利用Attention+BILSTM+CRF方法对文档中所包含的化学实体进行识别。为进一步挖掘化学与疾病之间相互作用信息打下了基础。通过引入文档级注意机制,使模型能够关注同一标记在文档中多个实例之间的标记一致性。Leaman等人[88]开发了一个tmChem系统,主要用于识别出生物医学或者化学文献中所包含的化学实体。通过使用模型组合的方法,将不同标记、特征集、参数的CRF模型进行组合来提高识别效果。化学命名实体识别的相关工作较少,但其对挖掘生物医学文本有着基础性的作用,例如生物治疗、药物与药物之间的相互作用研究等。
2.4 其他领域
命名实体识别技术在其他应用领域也都取得了不错的结果。陈钰枫等人[95]基于汉英双语命名实体的识别与对齐特性,提出了一种双语命名实体交互式对齐模型。通过双语实体的对齐信息使两种语言特性互补、对实体识别结果进行修正,为实体识别提供边界和类别的判断信息,从而提供识别的准确率。冯鸾鸾等人[80]在BILSTM+CRF的基础上采用深度学习与传统语言学特征相结合的方法对国防科技领域军事文本中的技术和术语进行了识别。为构建国防科技领域知识图谱打下了基础。李玉森等人[76]将命名实体识别的相关技术应用于基于文本的地理空间知识挖掘技术,不仅能够丰富地理信息系统(Geographic Information System,GIS)的信息来源,而且能够提升GIS的表达能力和可理解性。Gaio等人[77]提出一种基于知识的方法对文本地理信息中的空间实体进行标注,从而更好地分析空间信息、消除地方歧义。对于网络情报分析工作来说,命名实体识别是构建网络安全图谱的基础,由于网络安全领域标签数据稀缺,Li[96]等人在BILSTM基础上提出对抗主动学习框架来有效地选择信息样本进行进一步的标注,对模型进行再训练,从文本网络威胁情报中识别关键威胁相关要素。NER在各领域得到了大量的应用,对多个领域都有着积极的作用。图3为命名实体识别应用领域比例图。
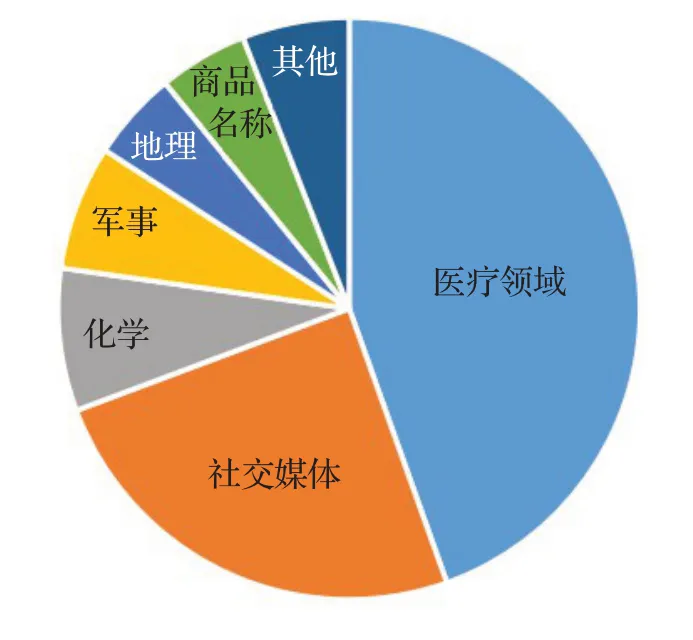
图3 命名实体识别应用领域比例图
3 基于深度学习的命名实体识别评测方法及数据集
3.1 评测方法
命名实体识别评测基本指标有三项,分别为正确率(Precision)、召回率(Recall)和F值(F-score)。
准确率反映了NER系统识别正确实体的能力,其计算公式为:

召回率反映了NER系统识别语料库中所有实体的能力,其计算公式为:

F值是一个综合评价指标,是准确率和召回率的平均值,其公式为:

F值是综合准确率和召回率指标的评估指标,用于综合反映整体的指标,是目前使用最为广泛的评测标准。
3.2 数据集介绍
CONLL2003是经典的命名实体识别任务数据集之一。主要提供了两种欧洲语言:英语和德语,共有1 393篇英语新闻文章和909篇德语新闻文章。所有的英语语料都来自于路透社语料库(Result corpus),该语料库由路透社的新闻报道组成。德语数据的文本信息都来自于ECI多语言文本语料库(ECI Multilingual Text Corpus),这个语料库由多种语言的文本组成,CONLL2003中所含的德语数据是从德国报纸Frankfurter Rundshau上提取的。CONLL2003中,实体被标注为四种类型地名(Location,LOC)、组织机构名(Organisation,ORG)、人名(Person,PER)、其他(Miscellaneous,MISC)。
MSRA-NER[97]数据集由微软研究院发布,其目标是命名实体识别,是指识别文本中具有特定意义的实体,共有五万多条中文命名实体识别标注数据,主要包括人名、地名、机构名等。MUC-6[3]数据库语料主要取自于新闻语料,包含318条带注释的《华尔街日报》文章。MUC-7语料库的数据主要有纽约时报新闻服务社提供,约158 000篇文章。
CoNLL2002西班牙语NER共享任务数据集,包含273 000的训练数据集和53 000的测试数据集。OntoNotes 5.0[98]由1 745 000英语、900 000中文和300 000阿拉伯语文本数据组成,OntoNotes 5.0[99]的数据来源也多种多样,有电话对话、新闻通讯社、广播新闻、广播对话和博客。实体被标注为地名(Location,LOC)、组织机构名(Organisation,ORG)、人名(Person,PER)等18个类别。不同方法在数据集上的评测效果见表7。

表7 不同方法在数据集上的评测效果
表7中,主要总结了不同方法在CONLL2003、MSRA、OntoNotes 5.0等三个数据集上不同的评测效果。图4为基于卷积神经网络和基于循环神经网络在三个数据集上的评测效果展示。从图5(a)和(b)可看出Akbik等人[100]所提出的Character-level LM-BILSTM-CRF模型在CONLL2003(German)和OntoNotes 5.0数据集上都取得了最先进的F值。该模型将句子作为字符序列输入到预先训练好的双向字符语言模型中,利用从语言模型中选择隐藏状态生成在下游序列标记任务有效的word-level embeddings,word-level embeddings由前向LSTM中该词最后一个字母的隐藏状态和反向LSTM中该词第一个字母的隐藏状态拼接组成,以此来兼顾上下文信息,达到更好的效果。虽然基于RNN的模型在NER任务上已成为主流,但从图5(a)可以看出只用ID-CNN在CONLL-2003(ENGLISH)数据集上也取得了不错的效果,Strubell等人[18]通过扩张卷积弥补了CNN表示受网络有效输入宽度限制的不足。而且从图5(b)也可以看出,RNN与CNN结合的BILSTM-CNN、BRNN-CNN、CNN-LSTM模型在OntoNotes 5.0数据集上也都取得较好的结果。在中文命名实体识别上,图5(c)中杨飘等人[32]的BERT-BIGRU-CRF网络结构在MSRA中文语料上F值达到了最先进的效果。该模型主要加入了BERT预训练语言模型,BERT采用双向Transformer作为编码器,而且还提出了“Masked”语言模型和“下一个句子预测”两个任务,分别捕捉词级别和句子级别的表示,并进行联合训练,从而提升了识别效果。图5(d)为三种方法在CONLL2003和OntoNotes 5.0数据集上的效果对比图,从图5(d)看出相同的方法在CONLL2003数据集上的效果要好于在OntoNotes 5.0数据集上。ID-CNN模型虽然在OntoNotes 5.0数据集效果要好于BILSTM-CNN模型,但在CONLL2003数据集上却相反,因此对于不同的数据集应选用合适的方法才能取得更好的效果。通过对以上方法的比较发现CNN与RNN的结合以及对于输入表示方法的改进会改善命名实体识别的效果,所以未来研究可以考虑将RNN与CNN结合或改进输入表示的方法从而提高命名实体识别的效果。

图4 评测效果图
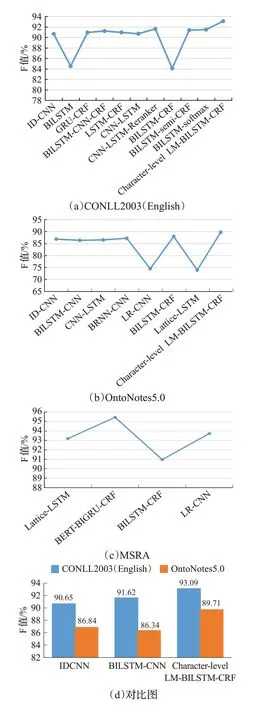
图5 数据分析效果图
4 总结和未来发展
4.1 现有工作总结
基于深度学习的命名实体识别目前已经取得了较大的成功,已成为自然语言处理领域中一项重要的基础性技术,在很多公开数据集上都达到了很好的性能。但仍存在以下一些问题:
(1)边界词的识别问题
词语边界的识别错误是影响识别效果的主要因素之一,正确的识别实体边界可以进一步提高实体的识别效果。
(2)专业领域词汇的识别问题
专业领域命名实体的产生往往以该领域知识为依据,兼顾其语言规律特性,有些领域的实体不仅存在词表外问题,而且有些实体是一词多义,这使得识别难度大大增加,导致在许多专业领域无法实现较高的识别性能。基于该问题,虽然很多研究人员发现字符级输入表示的模型识别效果要好于词表示,但还是会有一些罕见词汇无法识别。
(3)针对训练(标注)数据缺乏的深入设计
采用深度学习方法进行命名实体识别时,一般需要大规模的标注数据。虽然基于卷积神经网络和循环神经网络在多个NER任务上都取得了不错的结果,但因为在模型训练中,可用于模型训练的数据往往是有限的,有一些标准数据集只包括一种或两种类型标注,不包括其他类型,还有一种情况是在有限的训练数据中每种类型实体的数据只占标注数据总量的一小部分。这就造成训练数据的缺乏从而影响模型的学习效果。针对这些问题,逐渐涌现出了一些新的方法,如联合训练模型、迁移学习、多任务学习等,这些方法虽然解决了标注数据缺乏的问题,但往往都需要大量的内存和时间。因此如何在减少数据注释工作的同时减低成本、提高模型性能还值得学者们继续研究和探索。
(4)性能的进一步提升
随着模型的改进,命名实体识别方法的性能得到了提升,在公开数据集上的F值已由80%左右提升至90%以上,并且有极个别的方法突破了95%。虽然不同的数据集对于方法存在一定影响,但总体来讲,命名实体识别方法的性能仍有较大的提升空间,特别是在特定的应用领域。例如在生物医学领域,已有方法的F值大都低于90%;文献[100,105,108]等方法在德文上的表现均远低于其在英文上的表现。多模型的结合、针对数据的设计以及专业知识的嵌入对方法的性能提高将起到积极的作用。
4.2 未来研究工作
就现阶段的命名实体识别研究工作取得的成绩和存在的问题来说,未来还可以通过以下几个方面对NER展开研究:
(1)左边界词的检测。左边界词的识别很大程度上影响整个实体的识别,其中可能包括多个词,因此,一旦第一个单词被错误地标记,随后的单词标记正确率也将受到很大影响。尤其是对于中文实体的识别任务,词语之间没有间隔符,会因为分词或词汇列表外单词的影响,难以识别实体边界,导致实体识别错误。目前,主流的中文命名实体识别模型大多都是采用序列标注的方法,将实体边界与实体类别在同一模型中一起标注,而忽略了边界词识别的重要性,有研究表明,实体边界识别错误是影响识别效果的主要因素之一[113],边界词的识别可显著地提高实体识别效果。因此,接下来可以在加强实体边界检测方向上进行研究,提高实体识别的准确率,如可使用B-I-E的标记方案来加强边界词的检测。
(2)专业知识的深度结合。结合特定专业知识来提高NER性能,在生物医学、化学、社交媒体等领域,因为其数据的复杂性及不规范性,在进行命名实体识别任务时经常会遇到难以准确识别词汇列表外单词的问题。对于一些在词汇列表外的单词和低频词需要结合专业领域的知识来进行数据标记,可通过领域专家介入、人机协同等方式进一步强化专业词汇和规则,使命名实体识别应用到更多的场景中。
(3)主动学习。基于深度学习的命名实体识别在训练过程中往往都需要大量的注释数据,但注释数据量大耗时,而且还需要专业领域的专家进行注释。因此数据标注问题在NER模型训练中成为了一个难题。主动学习可以通过一定的算法查询最有用的未标记数据,并交由专家进行标记,然后用查询到的数据训练模型从而提高模型的精确度。在文献[74,92,94,96]等研究中都解决了一些特殊领域因专业标记数据缺失而导致模型性能较差的问题,证实了将主动学习与深度学习相结合的有效性。因此,在深度学习的基础上引入主动学习,未来可作为解决数据标注问题的一种解决方案。
(4)多任务学习。多任务学习涉及多个相关的任务同时并行学习,梯度同时反向传播,多个任务通过底层的共享表示来互相帮助学习,提升主任务泛化效果。多任务学习的一个基本前提是,不同的数据集要有语义和语法上的相似性,这些相似性可以帮助训练一个更优化的模型。相比单一数据集训练,它有助于减少模型过拟合,还可以解决训练数据缺乏问题。因此NER的深度多任务学习也是未来的一个发展方向,通过考虑不同任务之间的关系,多任务学习算法有望比单独学习每任务的算法取得更好的结果,Ruder等人[112]已经在实验中得到了证实。
(5)多模态网络融合。通过多模态NER网络融合文本信息和视觉信息,利用关联图像更好地识别文本中包含的命名实体。在某些领域中往往存在很多多义词,这时候就需要依赖于其语境和实体关联图像。额外的视觉语境可能会引导每个单词学习更好的单词表征。另一方面,由于每个视觉块通常与几个输入词密切相关,结合视觉块表示可以潜在地使其相关词的预测更加准确。
(6)应用领域的扩展与深入研究。目前的方法虽然取得了一定的成绩,但在具体应用领域的性能表现还有待于进一步提升。借鉴强化学习的思路,将专业知识和规则引入奖励机制、采用人机协同的方法以及将多种网络进行有机结合等思路有可能取得新的突破。同时将NER应用在更多的学科领域,为多领域的研究提供帮助,使命名实体识别更有价值,这也是研究NER的目的和意义所在。
