激光点云解算可配置阵列设计与实现
2021-06-11朱运维贺文静李传荣
朱运维,胡 坚,贺文静,李传荣
(1.中国科学院空天信息创新研究院,北京 100094;2.中国科学院定量遥感信息技术重点实验室,北京 100094;3.中国科学院大学,北京 100049)
激光雷达(Light Detection and Ranging,LiDAR)技术能够通过快速获取和实时处理形成高精度地表多维信息,在国土资源调查、地形测量、林业、灾害评估等方面具有广泛应用[1-2]。LiDAR 系统获取的测距数据需要经过点云解算才能形成三维点云[3-5],因此点云解算[1]是LiDAR 实时处理系统中的关键处理环节。点云解算包括激光雷达测距值及对应姿态数据的处理,涉及大量的双精度浮点数据的矩阵计算[6-7],具有计算量大,处理算法复杂的特点,给点云解算实时处理带来了难度。
随着超大规模集成电路技术的迅速发展,片上系统(System on a Chip,SoC)被广泛应用于计算机、电子通信和军工等领域[8-9]。SoC 技术通过处理器、存储器、各种控制接口和互联总线的集成,进一步减小了系统体积,并减少了系统中芯片之间的延迟,进而提高了系统效率[10-12]。利用FPGA 对系统进行硬件加速,能进一步提升系统的运算性能。
FPGA系统设计一般采取以具体应用为主导的设计方法,设计产品也往往只能满足单一使用场景[13-14]。数据输入特性的改变会使系统消耗资源和布线情况发生明显变化,重新设计会增加系统开发成本和周期。文中面向激光点云解算应用,设计了基于可配置阵列的架构,提高了可配置路由支持系统的灵活可配置性;算法单元运用流水线计算和并行阵列的策略,在一定程度上降低了系统与数据输入的耦合性,不仅提升系统计算性能,而且支持灵活重构。
1 激光点云解算原理
点云解算利用激光雷达系统输出的观测目标测距数据,联合激光雷达扫描时刻的位置姿态信息、测距数据,采用阵列推扫式机载激光雷达三维点云解算模型,具体地将激光扫描坐标系下获取的测距值通过激光扫描坐标系、IMU 坐标系、导航投影坐标系以及地心坐标系的坐标转换,获得每个激光脚点精确的三维空间坐标,如图1 所示。解算过程需要利用动态检校参数进行校正处理,以提高处理精度;同时,需进行粗差剔除操作,目的是降低目标误判概率和设备误差的影响。

图1 点云解算算法处理流程
2 可配置阵列架构设计与实现
2.1 可配置阵列架构设计
为实现点云解算的实时处理和面向不同观测载荷的灵活处理,文中设计了基于可重构阵列的点云解算FPGA 系统架构。点云解算FPGA 系统需要完成数据的路由发送和计算处理,具体架构包括数据处理模块、路由模块以及控制模块。其中,数据处理模块使用路由缓存以及计算单元的阵列形式,保证数据的灵活实时处理;路由模块发送LiDAR 距离姿态数据,通过配置路由使系统具有灵活性;控制模块监控系统的流水运行状态。图2 所示为点云解算FPGA 可重构阵列的总体设计结构。
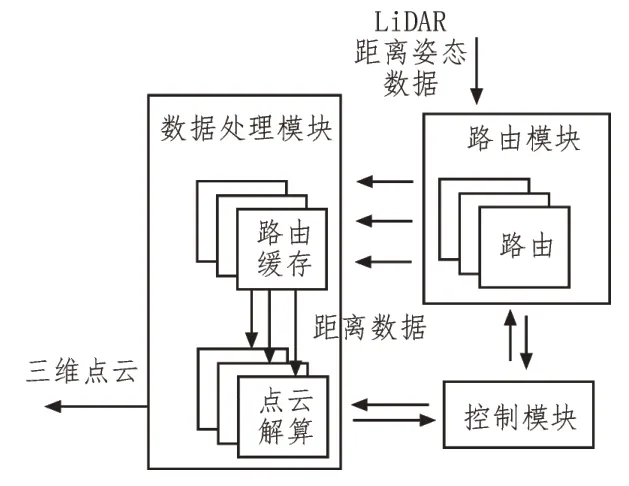
图2 点云解算FPGA可重构阵列结构
点云解算算法处理流程复杂、运算量大,其单流向数据处理的特点可以通过流水线设计实现算法的高效处理;而且点云解算在不同观测载荷下数据获取多变,也适合使用并行阵列进一步开发。因此,文中采用基于AXI-4 协议的高速传输方式,采用流水线和并行阵列混合的设计方式。
2.2 点云解算处理模块设计
处理模块设计是算法在FPGA 实现的重要步骤,其结构包含算法处理单元和数据缓存单元两个部分。复杂算法的流水实现需要进行算法的单元分割,从而将复杂的算法简化,为阵列和流水线的独立实现奠定基础。文中将点云解算分为激光雷达测距值及其姿态数据解算、矩阵变换和高斯投影3个算法,并对每个算法模块进行流水线设计,独立验证算法的正确性。
算法处理模块使用流水线设计方法,将算法的组合逻辑进一步系统地分割,在各个分级之间插入寄存器,将复杂操作分解为能并行的简单操作,以提高数据吞吐率。
假设在T循环内完成对每个激光雷达点元的处理,共需处理N个点元,在流水线设计前所需时钟T1=N×T,流水线设计所需时钟T2=(N-1)×T0+T,流水线效率提升倍数如下:
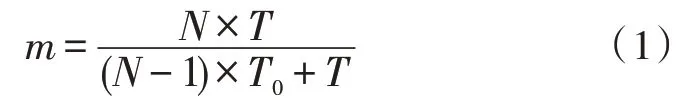
点云解算流水线设计示意图如图3 所示。
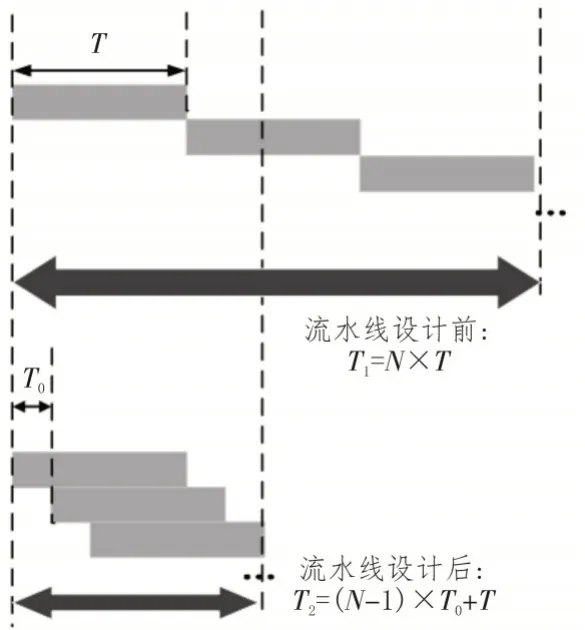
图3 点云解算流水线设计示意图
Xilinx HLS 开发环境提供了两种流水线指令:①unroll 和pipeline,unroll 指令会完全展开算法以达到最大并行,造成资源过度使用;②pipeline 优化指令中的迭代间隔约束因子(Initiation Interval,II)表示流水线发起间隔的周期数。通过改变迭代间隔约束因子得到不同性能的流水线,同时考虑开发板资源可使用量,并结合点云解算具有按描行存储处理数据的特点,采用基于AXI-4 协议的DMA 传输方式。AXI-4 是基于VALID/READY 的握手机制数据传输协议,传输端使用VALID 标明地址/控制信号、数据有效,目的端使用READY 标明其能够接受信息,读和写数据通道独立,支持低成本的直接存储器访问DMA 传输。同时,该协议基于开始地址的猝发式传输,具有广泛的IP 可扩展性,为阵列并行电路设计的控制设计提供基础。整合算法模块时,为实现不同时序的衔接,需要设计数据缓存。点云解算中矩阵变换通过坐标系转换的运算输出坐标为(x,y,z),将高程值z直接输出;高斯投影只对其中的x,y坐标进行投影操作。利用AXI-4 协议数据有效信号实现了矩阵变换和高斯投影间数据的正确缓存。
2.3 可配置路由设计
文中路由结构由实现数据分配的FIFO 缓存区构成。通过实现数据分配,基于AXI-4 协议设计控制逻辑,使路由实现手动配置;路由单元配合控制单元监控数据传输和处理进度,最终使系统能够通过可配置路由实现灵活的数据处理。
结合FPGA 内部存储资源充足、访问速度快以及激光雷达系统具有按扫描行处理数据的特点,使用FPGA 内部的存储类资源BRAM 和查找表LUT 建立基于先入先出队列(First Input First Output,FIFO)的数据缓存区,并对AXI-4 协议进行扩展,使数据顺序写入读出。以三阵列对应路由为例,在初始计数器cnt 自增的情况下,将待处理数据Input 按照扫描行写入对应阵列的缓存buffer,缓存完成时缓存计数器buffercnt进行自增。缓存计数器自增至三且AXI-4协议中的Input_valid 信号置低时,表示所有扫描行数据完成缓存,此时拉高calStart 信号启动并行计算,控制过程如图4 所示。
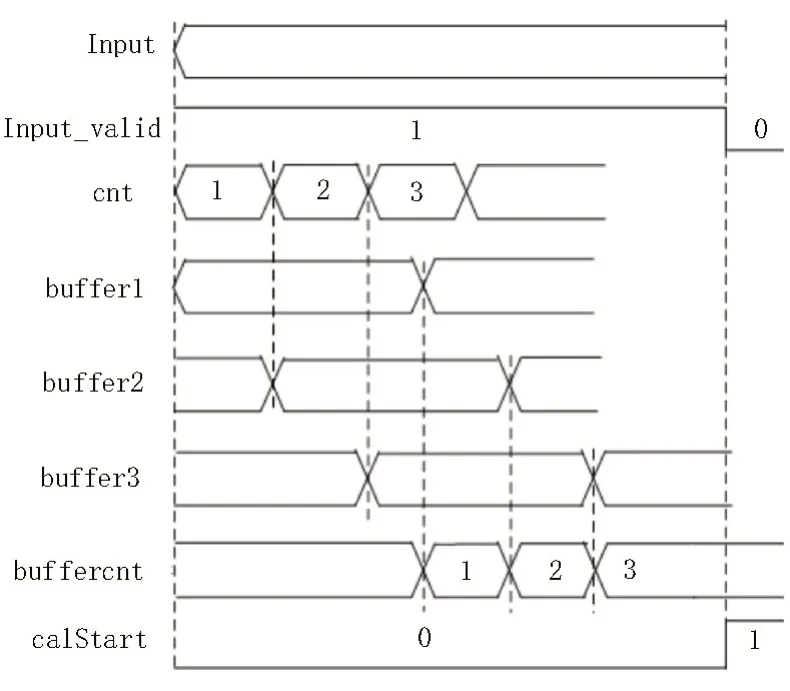
图4 FIFO数据缓存控制时序图
在阵列配置方面,文中利用AXI-4 协议在阵列顶层模块中手动修改配置,支持不同数目的单元并行计算,对应不同观测载荷的数据获取。顶层模块声明了可配置路由和可整体增减的单元两部分定义,包括阵列数目和输入数据缓存区、基于AXI-4 的处理单元和控制接口及计算部分。重配置时修改阵列数目num,添加对应路由缓存区buffer 的定义;处理单元和控制接口以及计算部分实现一次独立的处理,根据阵列数目可整体增减,体现AXI-4 协议的IP扩展性。伪代码如下:


配置过程采用静态可重构系统的设计方法[15-16],在一次配置完成后手动修改路由配置参数,完成重新固化,再烧写比特流运行,大大缩短设计周期。
3 性能分析
实验采用Xilinx 公司的Kintex-7开发板,其核心芯片为XC7K420T,实验时FPGA 时钟频率为100 MHz。
实验具体从流水线、路由与系统性能3 个方面进行分析。流水线性能包括迭代间隔因子对流水线资源消耗和时耗的影响;在路由与系统性能方面,比较了不同实现方式的系统总时耗以及对应的路由单元资源消耗。
3.1 流水线性能
文中设计在算法分割上将点云解算分为LiDAR测距值及其姿态数据解算、矩阵变换和高斯投影3 个功能模块,分别设计了3 个算法处理单元并采用流水线处理来提升处理效率。流水线迭代间隔因子影响流水线性能,实验分析了在处理一行360 个点元的情况下,迭代间隔因子对流水线的时钟周期和资源消耗的影响。以矩阵变换算法为例,资源消耗综合结果包括4 类硬件资源:存储资源BRAM、专用计算块DSP、触发器FF 和查找表LUT,如表1 所示。
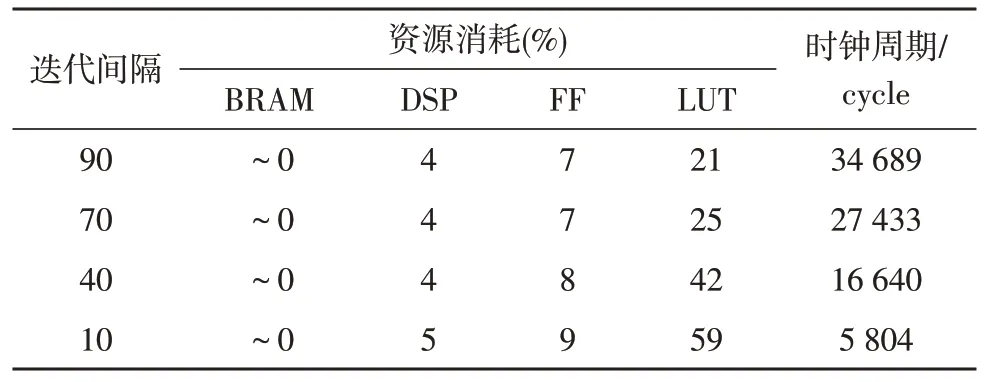
表1 矩阵变换硬件资源消耗和时钟周期
从表1 可知,随着迭代间隔因子的降低,流水线效率明显提高,但4 类硬件资源消耗逐渐增加;文中设计的可重构阵列实现并行处理既要提高处理效率,又需要避免并行实现时产生布线拥挤的情况,选取II=70 作为矩阵变换模块的最终迭代间隔因子,进行流水线性能控制。
3.2 可配置路由与系统性能
LiDAR 数据具有按扫描行获取并处理的特点,对应的每个处理单元以行为单位处理数据。文中针对两种不同LiDAR 数据处理场景分别设计实验:当扫描频率变化时通过配置路由并使用独立单元、双单元和三单元处理LiDAR 数据,验证数据并行处理的高效性;LiDAR 每行获取数据的幅宽也会变化,对应模拟3 种每行点元数不同的LiDAR 数据并使用不同的实现方式处理,验证该设计能够在一定程度上降低系统与数据的耦合性,提高系统可扩展性。
1)实验在可配置路由的基础上,通过不同数目单元并行处理验证处理效率。以每行处理120 像元数据为例,选取6.6 s 扫描的数据,行频100 Hz,数据行数为666 行,每行数据量为480 Byte,每行对应的载荷位置数据量为56 B,总数据量为348 kB。通过不同的实现方式,仿真实现了666 包数据并行计算输出数据的结果。表2 给出了独立单元、双单元和三单元的点云解算处理时耗对比,不同实现方式对应的路由资源消耗如表3 所示。

表2 像元数120的点云解算时耗对比
由表2 可知,文中设计的双单元和三单元处理666 行数据时用时分别为52.47 ms 和34.98 ms,对应实际获取数据时间为6.6 s 的扫描数据,满足激光雷达扫描频率每行120 个点元数据的实时处理需求;从时钟周期上,双单元和三单元的并行加速效率为1.62 倍和2.43 倍。由表3 可知,不同实现方式的数据分配过程不同,对应路由的BRAM 资源变化接近线性关系,表明系统通过路由灵活配置和并行单元的实现方式提升了处理效率。
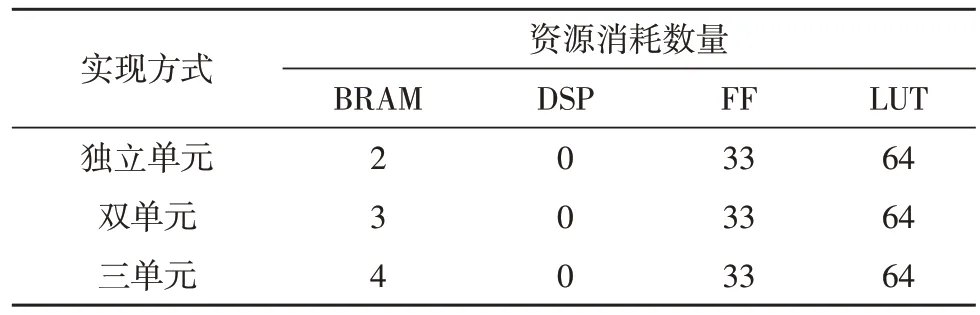
表3 路由资源消耗对比
2)不同LiDAR 载荷的每行扫描幅宽往往不同,为了验证文中设计处理不同扫描幅宽数据的高效性与灵活性,分别模拟了3 种LiDAR 数据,像元数分别为120、240、360,LiDAR 行频均为100 Hz,选取时间为6.6 s 的扫描数据。根据数据处理规模,分别通过独立单元、双单元和三单元的阵列方式实现,对应的系统总资源消耗与时耗分别如表4 和表5 所示。
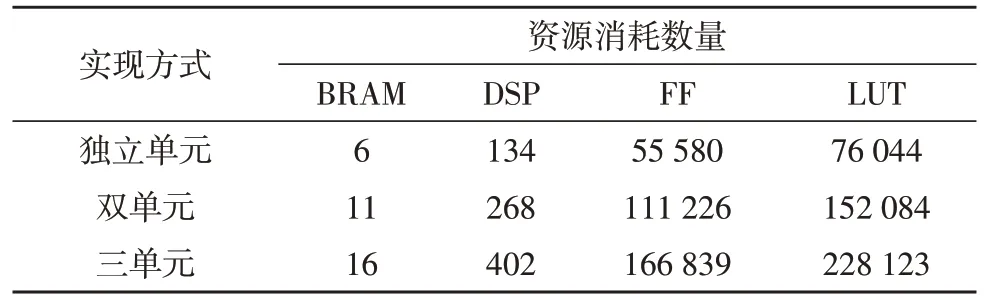
表4 系统总资源消耗对比
由表4 可知,系统通过不同实现方式处理不同规模数据,对应的总资源消耗接近线性关系;在表5中,文中通过并行单元设计处理666 行3 种特性的数据用时分别为85.01 ms、104.90 ms、114.94 ms,满足激光雷达扫描频率下每行数据的实时处理需求,表明该设计方法能够通过简单的参数配置进行系统资源重构,灵活高效地实现不同LiDAR 数据的处理。
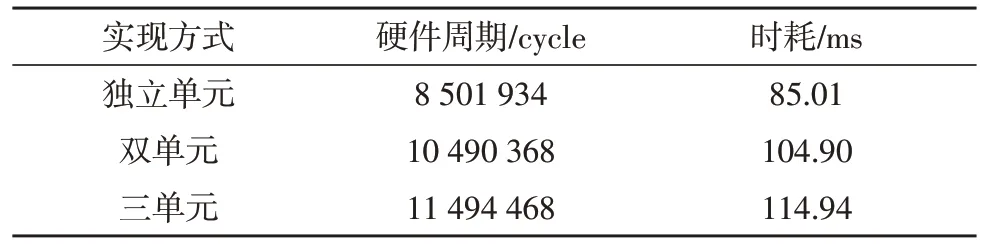
表5 不同数据规模点云解算系统性能对比
4 结论
文中采用基于可配置阵列的设计方法,设计并实现了激光点云解算的FPGA 系统。在Xilinx 公司的Kintex-7 开发板上通过流水线设计和并行阵列设计处理单元,以及利用AXI-4 协议设计可配置路由的方法,实现了灵活配置的点云解算FPGA 多阵列处理设计。实验结果表明,文中的激光点云解算FPGA 多阵列设计能够满足平台的实时性处理以及不同观测载荷的点云解算任务处理需求,降低了系统与输入数据间耦合性,为车载、航空、卫星等实时处理平台应用提供了一种适应不同数据率且资源可配置的FPGA 并行处理架构设计思路,在同类型载荷FPGA 实时处理系统开发中能减少因数据获取速率变化导致FPGA 系统的额外设计,为遥感数据实时并行处理提供了支持。
