Activiti 工作流框架在OA 系统中的应用
2021-06-11杨光
杨光
(西安庆安航空电子有限公司信息开发室,陕西西安 710077)
现代企业的办公自动化OA 系统具有复杂的流程审签业务,以公文审签为例,起草人员编写公文,部门负责人审核,公司领导批准后,公文会下发到各个部门和员工。若审批人员不同意,则可以驳回流程,在起草人员修改后重新发起流程,进入审批状态。
在传统的工作流中,任务的指派人员角色单一,只能按照人员或角色指派任务。随着人员或角色的复杂度的逐步提高,单一指派任务的方式已经不能完全满足系统的需要。文中在任务单一指派的基础上,提出了重构人员身份数据表的方法,可以将任务同时按人员或角色指派,提高了系统的灵活性。
1 Activiti的技术特点
1.1 工作流引擎ProcessEngine
工作流引擎ProcessEngine 类是Activiti 框架的核心类,通过它可以获得Activiti 所需的所有Service类,以及生成流程运行时的各种实例、数据、监控以及管理流程的正常运行[1]。
官方API 提供了多种获取ProcessEngine 的方法,这里使用名为activiti.cfg.xml 的配置文件来获取,如图1 所示[2]。

图1 工作流引擎的配置文件activiti.cfg.xml
1.2 各Service类
通过ProcessEngine 对象可以生成各个Service类,各类的作用如表1 所示。

表1 各Service类及作用
1.3 BPMN
业务流程建模与标注(Business Process Model and Notation,BPMN)是描述流程的基本符号,包括图元组合成一个业务流程图(Business Process Diagram)的方式[3],如图2 所示。
图2 描述流程的基本符号
IDE 安装Activiti 插件后,可以提供绘制流程的简单方法,绘制的流程图是后缀名为bpmn 的文件,这类文件本质上是一个xml格式的文件[4]。
在xml 格式文件中,包含代表各类元素的标签。IDE 提供绘制流程图的方式,可以自动生成xml 格式的文件。流程图中各个基本符号的属性都可以转换为xml文件中的各类标签和标签的属性[5]。
1.4 数据库
Activiti 的后台有数据库的支持,所有的表名都以act_开头,表名的第二部分是表示表用途的两个字母标识,用途与服务的API 对应[6]。
2 数据库的二次开发
2.1 数据库
Activiti 的组织机构表包括act_id_group(用户组信息表)、act_id_info(用户扩展信息表)、act_id_membership(用户与用户组对应信息表)、act_id_user(用户信息表)。
鉴于OA 系统部门、人员、角色关系的复杂性,这4 张表不能完全满足OA 系统对用户、人员、部门、角色关系的要求,因此需要调整表的结构或者重新设计表。部门表可以使用act_id_group 表,并补充相应字段。用户表可以使用act_id_user,再增加人员表person_info,与用户表建立关联关系。act_id_membership 可以作为人员-部门-角色表,通过补充人员id、部门id、角色code、角色名称等字段,可以体现人员所在部门及人员在该部门的角色。通过这种方式,可以很好地对Activiti 组织机构表进行重构,以满足OA 系统复杂的用户、人员、部门、角色、权限等要求[8]。
2.2 二次开发后的兼容性
进行数据库的二次开发以后,由于没有破坏原有的数据表结构,因此在流程中可以使用调整后的数据库结构进行处理,包括流程变量、个人任务、组任务。所以二次开发可以完全兼容原数据库及方法。
3 业务描述和流程图绘制
3.1 业务描述
在OA 系统进行文件分发时,首先由起草人编写文件,编写完成后,部门负责人进行审核。如果部门负责人及后续的公司领导均审批通过,则根据公文的分发范围进行分发;如果审批不通过,则直接退回到起草人阶段重新编写。
3.2 流程图绘制
使用Eclipse 的Activiti 插件绘制公文审签流程图,如图3 所示。
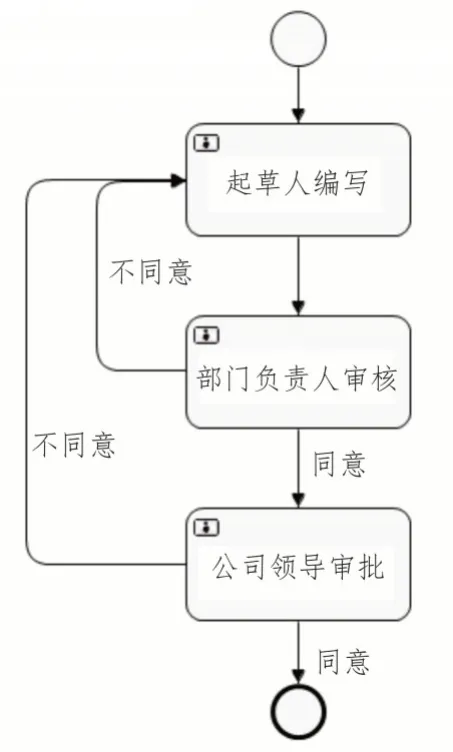
图3 公文审签流程图
为了满足OA 系统越来越复杂的人员和角色设计,文中提出了可以分别按照人员和角色分配任务的方法。
在部门负责人审核任务中,由于起草人分属不同的部门,所以部门负责人是变量,设置属性中的Assignee 为变量${deptLeaderId},且部门负责人是单人。在起草人编写任务完成时,根据该人员查询所在部门的负责人id,将流程变量设置为部门负责人id,下一步的任务处理人即为部门负责人,如图4所示。
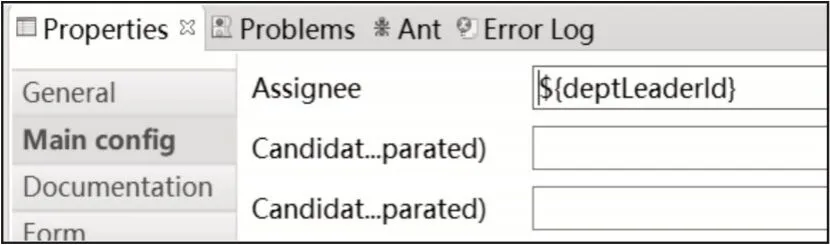
图4 部门负责人审核任务的属性
在公司领导审批任务中,审批人为公司领导的角色,与流程发起人无关。因此,可以直接将公司领导审批任务的属性Candidate groups 设置为company Leader 角色,如图5 所示。
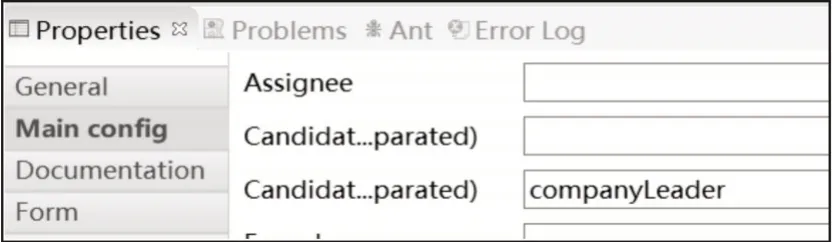
图5 公司领导审批任务的属性
4 关键代码设计
4.1 部署流程定义
首先使用Spring 框架注入流程引擎Process Engine 的实例,其次通过流程引擎创建仓库Service,并通过仓库Service 创建部署对象[9]。通过部署对象可以加载流程图,并为流程图指定名称,如图6所示。

图6 部署流程定义
4.2 启动流程实例
通过runtimeService 启动流程实例,流程实例启动后会生成流程实例id(processInstanceId),该数据会伴随流程执行的整个过程,如图7 所示。

图7 启动流程实例
4.3 任务的完成
完成任务有多种方法,其中之一是使用taskService的complete 方法。如图8 所示,首先可以查询出任务的id,其次使用taskService 的complete 方法,传入参数任务id,即可将任务完成。完成任务后,观察数据库可以发现,历史表中会出现该任务的信息,而正在执行的表中该任务会消失。

图8 任务完成
4.4 待办和已办的列表查询
对于待办和已办列表的查询,文中提出了同时根据人员id 和角色id 查询,合并查询结果集的方法。
以待办列表的查询为例,若人员id为“RY00001”,需要查询该人员的待办列表,则按照以下步骤,如图9 所示。
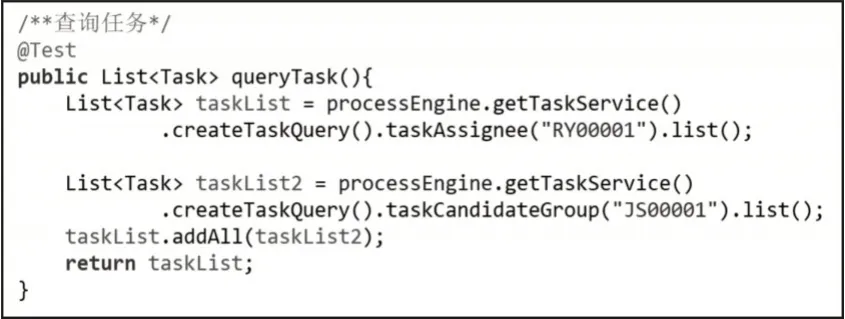
图9 查询任务
1)使用processEngine.getTaskService().createTask Query().taskAssignee("RY00001").list()语句获得个人任务taskList1。
2)根据人员的id 可以查询其所属的角色,角色的id 为"JS00001",使用processEngine.getTaskService().createTaskQuery().taskCandidateGroup("JS00001").list()语句获得个人任务taskList2。
3)使用List 的addAll 方法,将个人任务1 与个人任务2 合并,即可得到该人员的任务,taskList=taskList1.addAll(taskList2)。
4.5 任务列表的性能优化
使用上述方法查询人员的任务列表时,由于需要将2 个以上的List 合并,且无法根据分页进行查询,所以任务数量会增加,从而导致数据重组的速率下降,影响系统性能[10]。经过实验得出,当一个人员具有3 个角色,且个人任务为7 条,第一个角色的任务为4 条,第二个角色的任务为6 条,第三个角色的任务为3 条,将3 类任务进行合并,并进行数据重组时,查询耗时为4 718 ms,已经超过了用户的可忍受等待时间,影响了用户的体验,如图10 所示。
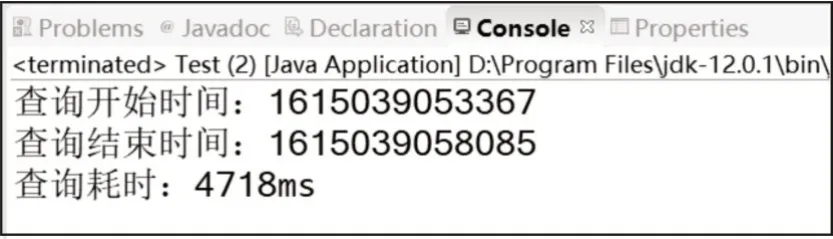
图10 任务列表查询时间
使用面向切面的编程SpringAOP 以及非关系型数据库Redis 可以有效地解决这个问题[11],具体如下所示:
1)使用SpringAOP 面向切面编程,每次用户完成任务时,使用后置增强获取人员id。利用切面来完成获取人员id并将人员的任务存入Redis缓存。利用SpringAOP 的目的是使得将任务存入Redis 的操作与业务进行解耦。首先定义切面类TaskAspect,在切面类中定义切面的增强类型是后置增强@After,后置增强的方法是*com.*.taskExecute(..)。
在该方法中,查询出该人员的待办和已办任务列表,并将其序列化为JSON 字符串[12]。
2)使用Java 调用Redis 的API,将该人员的待办和已办任务列表的JSON 字符串存入Redis 中。其中,key 可以是人员的id+任务类型(已办和待办),value 可以是任务列表的JSON 字符串。
3)每次查询人员的待办和已办任务列表时,直接从Redis 中取值,并反序列化为任务列表[13-14]。
由于Redis 是非关系型数据库,适合于作为缓存,读取速度快,因此,从Redis 取值查询人员的待办和已办列表时,可以有效降低查询时间[15-20]。
实验表明,使用Redis 作为缓存,在相同的查询条件下,可以将任务的查询时间从4 718 ms 降低至43 ms,如图11 所示。
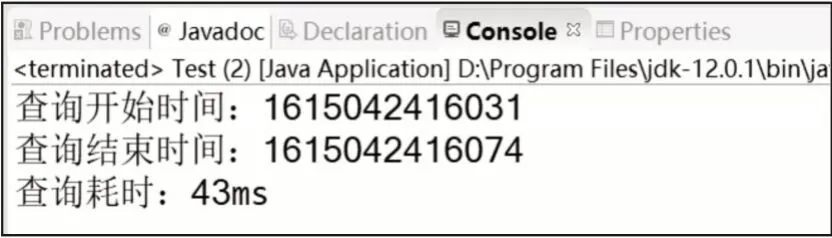
图11 从Redis缓存中查询任务列表时间
4)使用Redis 缓存任务列表的JSON 字符串的方法,可以有效降低查询已办和待办任务列表的时间。然而,这样会引入另一个问题,当用户发起流程或者处理流程时,由于需要将用户的已办和待办任务列表全部查出,并序列化为JSON 字符串,存入Redis,因此当用户的任务列表数据量过大时,查询和转换的时间也会增加,这样导致用户点击发起流程按钮或点击审批流程按钮时,会产生长时间的等待,如图12所示。

图12 用户操作时将任务列表缓存入Redis的时间
实验表明,在相同的条件下,当用户操作时,直接将任务列表缓存入Redis,会导致用户的等待时间为3 209 ms,带来了不良的操作体验。
针对出现的此问题,文中提出了如下解决方式:
首先修改用户操作后将任务列表缓存入Redis的方式,从同步修改为异步。当用户操作时,仍然使用SpringAOP 面向切面编程,此时将执行操作的用户id 及操作类型存入Redis 缓存。由于获取用户id及操作类型的耗时极短,因此用户发起流程和完成任务的操作需要极短的时间,操作后会在Redis 中形成操作用户的队列。
操作用户的队列采用“FIFO+定时任务”的方式,每隔1 s 从Redis 中取出任务列表有变化的用户id,将该用户对应的任务列表查询出来,并序列化后存入Redis 缓存。通过这种方式,将查询任务列表的时间放在了后台,提升了用户的体验。
以SpringBoot 的定时任务为例来说明定时任务的实现方法。
首先在SpringBoot 的启动类上增加@Enable Scheduling 的注解,用来启动定时任务;之后,在需要执行定时任务方法的类上增加注解@Component,纳入容器进行管理;通过cron 表达式可以定义多种形式的定时任务,每隔1 s 执行一次,在需要执行定时任务的方法上增加注解@Scheduled(cron="*/1 * * ** ?")。这个定时任务的方法所完成的功能就是从Redis 中取出任务列表有变化的用户id 队列的队头,并且将该用户的任务列表查询出来,序列化后存入Redis,最后将该用户从队列中删除。通过这种方式,可以将用户操作时等待的时间转化为后台执行程序的时间,提高用户的体验。
实验表明,在相同条件下,使用异步的方式,可以将用户操作等待时间从3 209 ms 降低为36 ms,性能提高了两个数量级,如图13 所示。
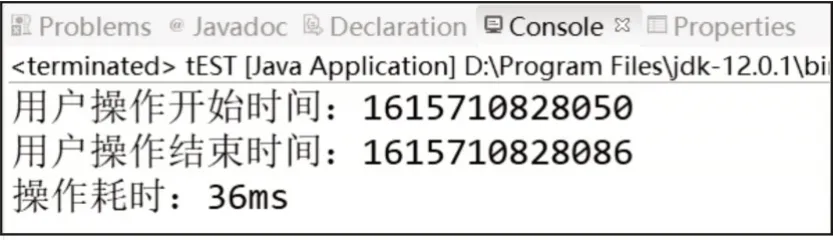
图13 用户操作时将用户id缓存入Redis的时间
5 结论
文中研究了Activiti 工作流框架在OA 系统中的应用,提出了重构人员身份数据表的方法和同时根据人员和角色进行工作流的流转方法,并优化了待办和已办任务列表的查询。通过这些研究,可以使得复杂信息化系统中的工作流配置更加灵活,同时使得待办和已办任务列表的查询效率大幅提高。该研究对于构建大型流程信息化系统具有一定的实际意义。
