生成式对抗网络的土壤有机质高光谱估测模型
2021-06-10何少芳沈陆明谢红霞
何少芳, 沈陆明, 谢红霞
1. 湖南农业大学信息与智能科学技术学院, 湖南 长沙 410128 2. 湖南农业大学资源环境学院, 湖南 长沙 410128
引 言
土壤中含碳有机物总称为有机质, 它是诊断和评价土壤肥力的核心指标。 传统的土壤有机质含量测定方法为室内化学测定法, 该方法具有精度高的优点, 但具有测定周期长且费时费力的缺点。 目前用于估测土壤性状指标的主要技术手段是高光谱遥感, 它具有分辨率高、 波段多且连续的特点, 能够对一定范围内的地物进行准确识别。 近年来, 对土壤有机质高光谱估算模型的研究, 已经由简单的一元线性模型逐渐发展成多元线性模型和非线性模型, 以及多种建模方法的耦合使用。 线性方法主要包括多元逐步回归(stepwise multiple linear regression, SMLR)、 主成分回归(principal component regression, PCR)和偏最小二乘回归(partial least squares regression, PLSR)。 徐夕博等[1]在主成分变换的基础上提取光谱特征, 对光谱信息的来源分类进行差别分析, 建立了基于主成分分析的多元逐步回归和神经网络预测模型。 李阳等[2]以新疆南部地区的荒漠土壤为研究对象, 使用主成分回归分析、 偏最小二乘回归分析和支持向量机回归分析方法建立并筛选出最佳反演模型。 由于土壤高光谱数据信息错综复杂且彼此关联, SMLR并不适合于变量间存在共线性问题, 而PCR较好地解决了自变量间存在的信息重叠问题, 能避免估测模型的过度拟合, 但忽略了因变量的作用。 非线性方法主要有神经网络(artificial neural network, ANN)、 随机森林(random forest regression, RFR)、 支持向量机(support vector machines, SVM)和局部加权回归(locally weighted regression, LWR)等。 包青岭等[3]采用小波变换与数学变换进行光谱数据预处理, 结合灰色关联分析与随机森林预测分类模型对各小波分解特征光谱进行重要性分析, 最后基于最优特征光谱建立多元线性预测模型并进行分析。 为探讨分数阶微分联合支持向量机分类-随机森林模型改善高光谱监测荒漠土壤有机质含量的效果, 张智韬等[4]建立不同分数阶微分的随机森林模型, 并以不同土质中的最佳模型进行组合, 构建新的联合支持向量机分类-随机森林模型。 国佳欣等[5]对土壤光谱进行了包含分数阶导数在内的3种数学变换方法, 将经过P=0.01显著性检验的波段用于模型的构建, 选用偏最小二乘回归和BP神经网络(back propagation neural network, BPNN)建立土壤有机质含量预测模型, 结果表明PLSR-BP复合模型预测精度优于单一模型。 LWR是从光谱库中选取光谱特征相近的样本建立局部模型, 土壤光谱数据越全面, 基于大样本土壤光谱数据的局部模型预测效果就越好。 从LWR的应用研究可看出, 在大样本和大尺度区域上它能发挥更好的作用, 但建模的重要前提是构建大样本土壤光谱数据库。 为了更准确地监测大面积土壤的有机质含量, 在已有的估测模型基础上, 从拓展样本数据集的角度探索提高土壤有机质高光谱估测模型预测能力的方法很有必要。
在机器学习领域, 高质量数据集的合成一直以来是一个非常重要且充满挑战性的问题, 合成的高质量数据可用于改善模型, 尤其是深度学习模型的训练过程[6]。 Goodfellow等[7]提出一种新型生成模型-生成式对抗网络(generative adversarial network, GAN), 开创性地使用对抗训练机制对2个神经网络进行训练, 并利用随机梯度下降(stochastic gradient descent, SGD)实现优化。 深度卷积GAN[8](deep convolutional generative adversarial networks, DCGAN)是对GAN的第一个重要改进, 它将深度卷积和批标准化层引入GAN网络结构中, 在几种不同的数据集上都取得了令人信服的实验结果。 GAN自提出后立即受到人工智能学术界和工业界的高度关注和广泛研究[9-11]。 基于零和博弈的GAN可通过无监督学习获得数据分布, 并生成较逼真的数据, 在图像生成、 视频生成等领域都获得了成功的应用。
已有的土壤有机质含量估测模型, 大多通过优选有机质敏感波段并结合线性或非线性回归算法提高模型稳健性[12-13], 较少涉及从拓展建模样本空间角度提升模型性能。 本工作以湖南省长沙市稻田土样为研究对象, 探索精度和稳定性更优的土壤有机质高光谱估测模型。 考虑到有限的标签数据仅能反馈有限的信息, 在少量带标签样本环境下训练出来的回归模型往往难以得到理想的预测性能, 在LWR的应用原理和GAN在图像生成等领域成功应用的启发下, 以239份样本数据作为GAN的输入, 生成与输入数据真伪难辨的等量伪数据, 并将其与原始数据建模集合并构成增强建模集。 为了充分评价基于GAN的土壤有机质高光谱估测模型对精度提升效果的显著性, 在增强建模集上设置4个观测点(对应增强建模集中含随机选择的50, 100, 150和239个生成样本), 动态构建交叉验证岭回归(ridge cross validation, RCV)、 偏最小二乘回归和BP神经网络土壤有机质含量估测模型, 并在同一测试集上实施模型评估。
1 数据获取
1.1 研究区域概况
选取湖南省长沙市和株洲市及周边(东经112.608—114.067, 北纬27.536—28.514)的大田水稻种植土壤作为研究对象, 研究区域地势平坦, 土壤排水良好, pH值在4.5与9.0之间, 研究区域概况如表1所示(CS代表长沙, ZZ代表株洲)。 每个采样点的土壤剖面(深度为0~130 cm)分为5~7个发生层, 每个发生层对应不同的土壤层次深度并命名区分。
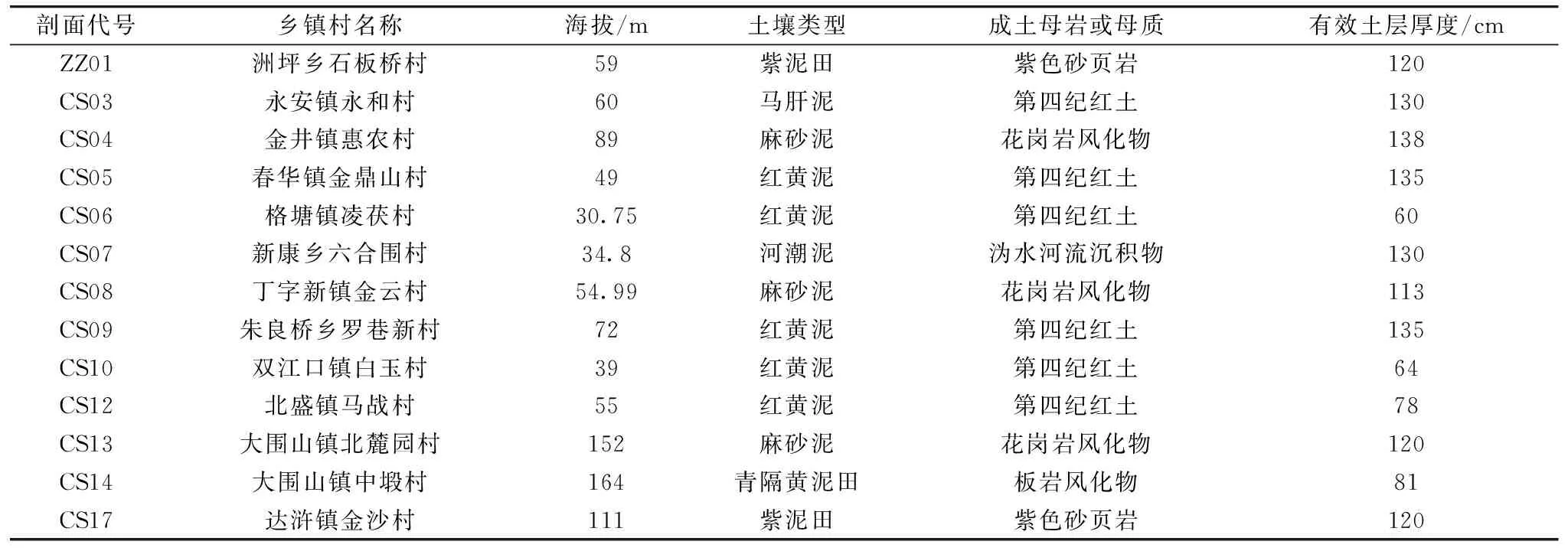
表1 研究区域概况
1.2 样本采集与光谱测定
在研究区域内选择51个剖面对应的水稻田中随机、 均匀采集土壤样本, 同步使用手持GPS定位仪进行定位, 共采集239份土壤样本。 经过实验室风干、 磨细处理后, 每份土壤样本分为2份, 一份用于光谱数据采集, 一份用于理化性质分析。
光谱数据采集使用可见光-近红外光谱仪(ASD Vis-NIR), 波长范围350~2 500 nm, 采样间隔350~1 000 nm内为1.4 nm和1 000~2 500 nm内为2.0 nm, 重采样间隔为1 nm。 239份土样高光谱均在室内测定。
土壤样本的有机质含量测定使用重铬酸钾-外加热法, 每份样本均经过2次测定后取平均值。 239份土样中, 完成有机质含量测定的土样79份, 另160份土样的有机质含量通过预测获得, 所使用的预测模型为79份土样的高光谱和有机质含量拟合的交叉验证岭回归。 从79份土样中随机划分出25%(20个样本)作为测试集, 不参与后续模型拟合, 仅用于模型评估的独立实验; 余下59份样本与160份样本合并构成建模集。 土样的有机质含量统计特征如表2所示。

表2 土壤有机质含量统计特征
2 生成式对抗网络与建模方法
2.1 生成式对抗网络
生成式对抗网络(GAN)的思想来源于博弈论中二元零和博弈, 其基本框架(如图1所示)主要包括两个重要组成部分: 判别器和生成器。 生成器以一个来自常见概率分布的随机噪声矢量z为输入, 生成的伪数据G(z)为输出; 判别器的输入有两种: 真实数据x和生成器生成的数据G(z), 输出为判别结果, 可以是一个标量, 用于表示输入是真实数据的概率, 也可以是1或0(若判别器认为输入的是真实数据, 则输出判别结果1, 反之为0)。 判别器与生成器是一对互相对抗训练的模型, 由于判别器是一个二分类模型, 在给定生成器的情况下, 用于判断和监视判别器学习效果的目标函数J(D)可用交叉熵。 判别器与生成器进行二元零和博弈, 因而生成器的目标函数J(G)满足J(G)=-J(D)。 利用随机梯度下降法SGD对GAN进行优化, 优化问题可描述为式(1)中的极大极小博弈问题, 其中,E表示求期望,G和D分别表示生成器与判别器的可微函数,x是真实数据样本,z是随机噪声矢量,G(z)为生成器生成的数据。 当判别器无法正确区分输入数据来源于真实数据x还是生成数据G(z)时, 模型达到最优。
minGmaxDV(D,G)=Ex~pdata(x)[log(x)]+
Ez~pz(z)[log(1-D(G(z)))]
(1)

图1 GAN网络模型基本框架
针对GAN训练过程中容易出现的梯度消失、 模式崩溃和过拟合等影响模型性能的问题, 已有相关研究工作提出了针对具体训练问题的技巧和解决方案[8-11, 14]。 GAN生成样本的质量评价主要依赖于主观判断, 而常用的客观评价指标(如平均对数似然、 核密度估计等)互不依赖且分别适用于不同类型的生成模型[9], 统一、 公认的生成数据质量客观评价标准仍然缺乏。
2.2 模型构建
基于GAN的土壤有机质含量估测模型是回归算法与GAN的结合, 模型流程见图2。
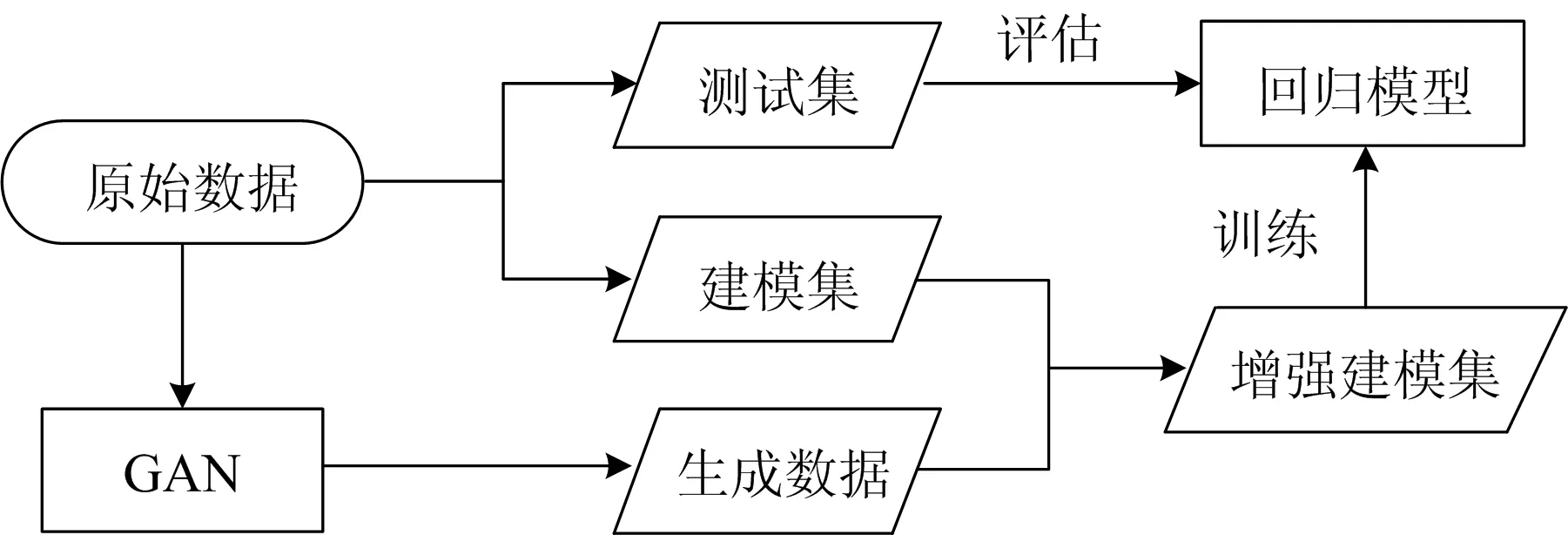
图2 基于GAN的土壤有机质估测模型流程
模型的输入(GAN的输入)是含239个样本的原始数据。 测试集中含20个样本, 建模集含有219个样本。 首先, 通过GAN训练生成等量伪数据, 它们与建模集合并构成增强建模集; 然后, 在增强建模集上构建回归模型; 最后, 利用测试集评估模型。 该模型流程有三点需说明: (1)针对GAN训练过程不稳定问题, 设置前150轮为预训练; (2)由于生成数据质量没有公认评价标准, 采取即时评估策略, 即在每轮GAN正式训练中, 以本轮获得的增强建模集的光谱数据为自变量、 归一化的有机质含量为因变量拟合回归模型, 然后在测试集上计算该模型的精度, 以分析生成数据的有效性; (3)为探讨生成数据数量与估测模型精度提升效果之间的关系, 在各轮正式训练中设置增强建模集的4个观测点(分别对应增强建模集中含随机选择的50, 100, 150和239个生成样本), 分别评估回归模型的决定系数和均方根误差。 总的来说, 提出的模型与一般估测模型的区别主要体现在两方面: 一方面, 用于拟合回归模型的数据集不同, 一般估测模型在建模集上训练, 而本模型是在由建模集与GAN生成数据构成的增强建模集上训练; 另一方面, 不同于一般估测模型的静态性, 本模型具有动态特征, 随着GAN多轮正式训练, 它将依据正式训练轮次和增强建模集的观测点数, 动态构建(轮次数×观测点数)个估测模型。
光谱波长范围是350~2 500 nm, 波段长度为2 151, 将土壤有机质含量进行标准化处理后, 输入GAN的参考数据大小为239行2 152列。 由于卷积神经网络(convolutional neural network, CNN)比MLP具有更好的抽象能力, 参考深度卷积GAN (DCGAN)在Fashion MNIST数据集上的实现来构建GAN的判别器和生成器, 结合输入数据及硬件实现条件设置网络内部结构和参数, 软件中的建模操作可通过Tensorflow2.0平台keras库的序列模型(Sequential)实现。 考虑到内存仅有16GB, 无GPU加速, 生成器的网络结构设置3个反卷积层, 判别器含2个卷积层。 生成器的输入是一个长度为2 152的随机矢量(注意8×269=2 152), 序列模型中添加的各层依次是: 神经元个数为8×264×64=137 728的密集层、 批标准化层、 激活层、 重塑型层(使原长度为137 728的数据转换为8行269列64个通道的数据)、 32个神经元的反卷积层、 批标准化层、 激活层、 16个神经元的反卷积层、 批标准化层、 激活层、 只含一个神经元的反卷积层, 输出为8行269列1个通道的数据。 判别器的输入数据大小与生成器的输出一致, 序列模型中添加的各层依次是: 64个神经元的卷积层、 激活层、 丢弃层、 128个神经元的卷积层、 激活层、 丢弃层、 平坦层、 1个神经元的密集层, 输出为判别结果。 反卷积与卷积所使用的卷积核都为(5, 5), 激活函数选择“LeakyReLU”。
模型训练前, 需设置的超参数有训练轮次、 用于验证GAN训练效果的随机矢量长度和个数, 其值分别是300, 2 152和239; 前150轮视为预训练, 后150轮为正式训练。 由于构建的判别器相当于一个卷积神经网络分类器, 损失函数选择二分类交叉熵。 生成器和判别器的优化器都选择“Adam”。 在每一轮训练中, 将依据批次大小(本文设置为10)完成输入数据集(参考数据)上若干次对抗训练; 在每一次对抗训练中, 依据判别器对参考样本和生成样本的判别结果, 计算生成器损失和判别器损失, 并获得生成器梯度和判别器梯度, 进而应用梯度优化生成器和判别器。 生成器中增加了批标准化层改善网络, 避免生成数据与参照数据过于相似。 由于本文的GAN网络结构参考DCGAN在Fashion MNIST数据集上的训练来构建, 实质上是DCGAN的精简版, 因而, GAN模型性能可参考文献[8]。
图2中的回归模型选择交叉验证岭回归RCV、 偏最小二乘回归PLSR和BP神经网络, 兼顾线性方法和非线性方法。 岭回归是一种用于共线性数据分析的有偏估计回归法, 是改良的最小二乘估计法, 通过在代价函数后加上一个参数的约束项防止过拟合, 而带内置参数交叉验证岭回归类似网格搜索, 结合交叉验证对模型评分, 在指定范围内自动搜索和确定约束项的最佳系数。 BP神经网络[15]是一种多层前馈神经网络, 具有自学习能力, 在训练时, 数据依次经过输入层、 隐含层和输出层, 比较输出值与期望值之间的误差, 并通过误差反向传播来调整优化网络层之间的权值。 依据选择的回归方法, 提出的模型对应简称为GAN-RCV, GAN-PLSR和GAN-BPNN。
3 实验结果和模型评价
采用Python3.7编程实现基于GAN生成数据的土壤有机质高光谱估测模型, 实验平台为PyCharm社区版和Tensorflow 2.0, Windows10 Pro操作系统, 处理器为Intel(R) Core(TM) i3-4170 CPU ® 3.7 GHz(64位操作系统, 基于x64的处理器), 安装内存16.0GB, 无GPU。
模型稳定性与预测精度评价指标采用决定系数(determination coefficient,R2)和均方根误差(root mean square error, RMSE),R2越大、 RMSE越小, 模型预测精度越高稳定性越好。
本工作侧重于研究GAN生成数据对土壤有机质含量估测模型精度和稳定性提升的有效性, 因而, 回归算法中参数的选择和设置不失一般性, 交叉验证岭回归中参数取值的范围设置为0.1~10, 步长为0.2; BP神经网络训练300轮次, 隐含层中含3个全连接层(即64-32-16), 激活函数都选择“relu”, 优化器是“Adam”, 损失函数为均方差, 验证集占比20%。 GAN训练300轮, 在后150轮正式训练中, 每轮对抗训练完成后都对GAN生成数据质量加以评估。 以第3个观测点(从生成样本中随机选择150个样本与建模集合并构成增强建模集)为例, 将提出的模型与建模集上拟合的模型在相同测试集上进行评估和对比。 建模集上拟合的模型分别记为Ori-RCV, Ori-PLSR和Ori-BPNN, 它们与第3观测点上构建的GAN-RCV, GAN-PLSR和GAN-BPNN在测试集上的精度如表3所示。 由表3可知, 建模集上拟合的3个回归模型中, Ori-RCV表现最佳, 然而, GAN-RCV, GAN-PLSR和GAN-BPNN获得了更高的决定系数和更低的均方根误差, 具有更佳的精度和稳定性, 表现为: GAN-RCV的最大R2比Ori-RCV提高了7.2%, 对应RMSE值降低了18.9%, 对比Ori-PLSR, GAN-PLSR的最大R2提高了20.6%, 对应RMSE降低了29.5%, 与Ori-BPNN相比, GAN-BPNN的最大R2提高了30.8%, 相应RMSE降低了44.50%。 提出的模型中, GAN-BPNN表现最佳, 且模型性能提升效果最显著, 它在正式训练过程中的模型精度如图3所示, 其中, 红色与蓝色分别代表拟合于建模集与增强建模集第3观测点的回归模型评估结果。 从图3中容易看出, 尽管GAN训练过程不稳定, 每轮训练中动态构建的模型精度上下波动, 但提升效果异常显著。

图3 GAN-BPNN训练过程中的R2和RMSE

表3 估测模型性能对比
平均决定系数(均方根误差)是模型正式训练中各轮决定系数(均方根误差)之和除以轮数。 估测模型在每轮正式训练的4个观测点(对应增强建模集中含随机选择的50, 100, 150和239个生成样本)上拟合, 并在测试集上评估, 获得的平均决定系数和均方根误差如表4所示。 从表中可看出, 4个观测点上构建的估测模型性能均优于建模集上拟合的估测模型, 其中, GAN-RCV性能最稳定, 不同观测点上模型精度差异不大, 相对地, GAN-PLSR和GAN-BPNN对加入的生成样本数量更敏感。 总的来说, 随着生成样本数量增加, 平均决定系数呈先升后降趋势(平均均方根误差先降后升), 这表明加入生成数据拓展样本建模集有益于提高估测模型的预测能力, 且当生成样本数量增多并达到一定值时, 提升效果显著增强并达到最大, 而增加更多生成数据时, 模型提升效果显著性减小。 造成这种现象的主要原因在于过多的生成样本会稀释因变量的全部变异通过回归模型由自变量解释的能力, 从而降低了估测模型在测试集上的精度。

表4 各观测点上模型的平均决定系数与均方根误差
4 结 论
以改善土壤有机质高光谱估测模型精度和稳定性为目的, 从拓展样本数据建模集的角度出发, 利用深度学习算法中GAN具有合成高质量数据的能力, 提出基于GAN的土壤有机质高光谱估测模型GAN-RCV, GAN-PLSR和GAN-BPNN。 模型以少量样本数据为输入, 经过预训练后每轮都生成了与输入数据集等量的新数据。
虽然GAN的学习能力与可塑性强, 但突出的问题是训练过程不稳定, 且缺乏公认的生成数据质量的客观评价标准, 因此, 本文采用即时评估方式评价生成数据质量, 即在GAN正式训练中, 每轮训练完成后都通过评估模型GAN-RCV, GAN-PLSR和GAN-BPNN在相同测试集上的精度和稳定性来验证生成数据的质量, 相对来说, 就是利用GAN生成高质量数据的能力拓展样本数据建模集, 以提高土壤有机质高光谱估测模型的预测性能。 参考建模集上估测模型的精度, 对比分析GAN-RCV, GAN-PLSR和GAN-BPNN在训练过程中的R2和RMSE, 不难得到: 提出的模型具有更优的精度和稳定性, 其中, GAN-BPNN表现最佳; GAN-RCV的模型提升效果受增强建模集中生成样本的数量影响较小, 而GAN-PLSR和GAN-BPNN受影响较大; 增强建模集上设置的4个观测点中, 第3个观测点构建的模型性能改善效果最显著。 值得一提的是本模型是全谱模型, 并未涉及光谱数据预处理和特征波段选择, 这意味着模型精度和稳定性还有一定的提升空间。 此外, GAN属于深度学习范畴, 模型训练对硬件要求较高, 对比建模集上构建的土壤有机质估测模型Ori-RCV, Ori-PLSR和Ori-BPNN, 提出的模型因GAN训练耗时相对较长, 然而, 在有限数据样本条件下, 以牺牲计算效率为代价获取更高的模型性能亦是可取的。
猜你喜欢
杂志排行

光谱学与光谱分析的其它文章
- Synthesis, Structural, Spectroscopic Characterization and Biological Properties of the Zn(Ⅱ), Cu(Ⅱ), Ni(Ⅱ), Co(Ⅱ), and Mn(Ⅱ) Complexes With the Widely Used Herbicide 2,4-Dichlorophenoxyacetic Acid
- Spectroscopic Investigations for the Six New Synthesized Complexes of Fluoroquinolones and Quinolones Drugs With Nickel(Ⅱ) Metal Ion: Infrared and Electronic Spectroscopy
- 激光诱导击穿光谱在疾病诊断中的应用前景
- 沸水浸提-电感耦合等离子体发射光谱法测定土壤中的有效硼
- Tb3+掺杂锂铝硅酸盐玻璃的光致发光和辐照致发光
- 典型光谱吸收模型对静止轨道毫米波辐射分析