基于深度置信网络的红外光谱鉴别汽油掺混
2021-06-08王明吉王秋实
王明吉,梁 涛,李 栋,王 迪,王秋实
(1.东北石油大学 物理与电子工程学院,黑龙江 大庆 163318;2.东北石油大学 土木建筑工程学院,黑龙江 大庆 163318)
引言
随着我国交通大发展的持续深入推进,用户对汽油的需求呈现爆炸式增长。然而,大量不法企业为追求最大限度利润,擅自用化工原料和添加剂兑制、混配“调和汽油”,给消费安全带来了极大的隐患。因此亟需研究对掺混成品油进行快速鉴别的方法。
由于红外光谱分析技术具有检测速度快、效率高、成本低等特点[1],已被广泛应用于成品油分析领域[2]。Veras等人利用主成分分析(principal component analysis,PCA)结合聚类分析的方法对108个柴油样品的原产地进行分类[3];姜黎等人利用主成分分析结合马氏距离的方法比较汽油的2个特征波段建模的分类效果[4];王丽等人利用主成分分析结合模糊聚类实现了对海洋溢油样本的快速分类[5]。然而主成分分析属于线性降维方法,其不能准确提取光谱数据中的非线性特征,导致光谱数据在降维的过程中部分有用信息丢失及鉴别模型精准度下降。鉴于此,本文采用非线性降维方法中的t分布邻域嵌入(t-distributed stochastic neighbor embedding,t-SNE)算法[6]对光谱数据进行降维处理,同时结合深度置信网络方法[7]建立汽油鉴别模型,并与极限学习机鉴别算法[8]进行识别精度对比分析,以解决掺混汽油红外光谱鉴别技术中线性降维方法缺陷和高精度识别模型选择问题。
1 材料与方法
1.1 样品来源与光谱测试
本实验所使用的92#、95#以及98#汽油样品均购置于大庆中石化加油站,掺混汽油样品由92#、95#、98#汽油按照1∶1∶1配制而成,每种样品各50份用于红外光谱测量实验。其中,每种类型取其40份作为训练集,10份作为测试集。
1.2 光谱数据处理
通过实验所采集到的光谱信息不仅包含样本特征信息,还包含外界的干扰因素[9],这些干扰因素会对模型建立造成一定的影响。因此,有必要对原始光谱数据进行预处理[10]。分别采用多元散射校正(multiplication scattering correction,MSC)、标准正态变换(standard normal variate,SNV)以及一阶导数对原始光谱数据进行预处理,从而选择最适合本文的预处理方法。
红外光谱数据通常维度很高,如若将全部光谱数据参与模型构建,将会导致该模型识别效率下降,通常在建立模型之前需对光谱数据进行降维处理,本文采用t分布邻域嵌入(t-distributed stochastic neighbor embedding,t-SNE)算法对光谱数据进行降维[5]。
t-SNE算法具体步骤如下:
a)用条件概率pj|i表示高维空间中邻近数据点xi与xj的相似度,邻近数据点之间的相似度越高,则条件概率pj|i值也就越大,且其服从高斯分布[11],条件概率pj|i计算公式为

式中 σi为高斯分布标准差。
将高维中邻近数据点xi与xj在低维中的映射点记为yi与yj,并计算其相似的条件概率qj|i
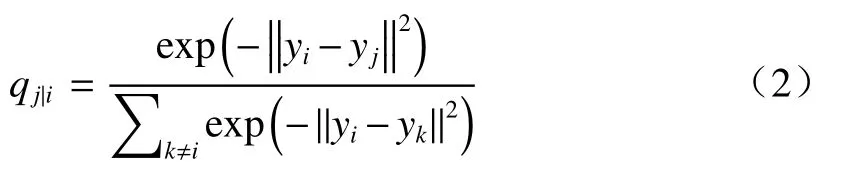
b)pj|i与qj|i分别表示高维空间中数据点xi、xj与低维空间中数据点yi、yj之间的联合概率,如(3)式和(4)式所示:

c)此时新的代价函数C可以表示为

式中:KL为K-L散度(Kullback-Leibler divergence);P与Q分别为高维空间和低维空间中度量点对分布概率分布。
d)在低维空间中,t-SNE算法将使用t分布(student t-distribution)代替高斯分布以表示两个点之间的相似度。t分布在低维空间中使用更注重长尾分布,使同类的样本点在低维空间中相隔距离较近,不同类型的样本点相隔距离较远[12]。t-SNE梯度计算式可以表示为

1.3 基于深度置信网络的汽油种类鉴别方法
1.3.1 数据集处理
数据集中标记的鉴别汽油种类是离散型数据,不能直接参与DBN模型计算,因此在构建DBN模型之前需要利用One-Hot编码进行转换处理。One-Hot编码使用0或1对多个分类或状态进行编码,将每个分类或状态作为独立属性,任意时刻只有其中一个属性有效,将对应的有效属性设置为1[13],4种类型的汽油对应的编码如表1所示。

表1 同类型汽油One-Hot编码Table 1 One-Hot coding of different types of gasoline
1.3.2 深度置信网络鉴别模型
深度置信网络既可以用于非监督学习,也可以用于监督学习,其由多层受限玻尔兹曼机(restricted Boltzmann machines,RBM)组成,通过训练各个神经元之间的权重和偏置,可使整个神经网络以最大概率生成训练数据[14]。DBN一般由3层或3层以上神经元构成,神经元分为显性神经元和隐性神经元。显性神经元接受输入数据,隐性神经元提取数据的特征,其中每一个神经元代表数据向量的一维。与传统方法相比,DBN不仅有多隐层的深度结构,而且通过逐层训练学习以获取特征,能够刻画出数据更丰富的内在信息,使分类和预测更加容易[15]。
DBN模型如图1所示,第一层为输入数据的可见层,输入不同类型汽油光谱特征向量,数据经过2个隐层逐层训练后到达最后Softmax分类器,Softmax分类器输出汽油种类。
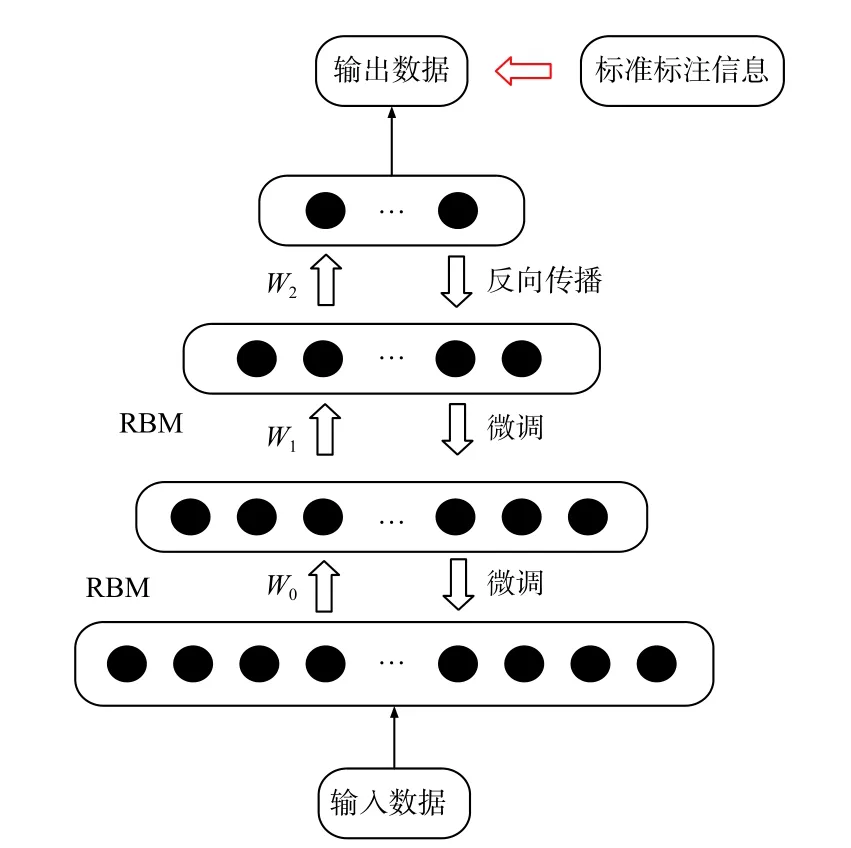
图1 汽油种类鉴别DBN模型Fig.1 DBN model for gasoline types identification
DBN模型中核心部分是RBM,RBM是一种层内无连接、层间全连接的两层神经网络[16],其结构如图2所示。

图2 RBM结构图Fig.2 Structure diagram of RBM
图2中,ai和bj分别为可见层神经元和隐层神经元的偏置值,wij为层间相连的神经元的权值。
RBM中状态(v,h)的能量函数如(7)式所示,其函数值越小,则表示此时的RBM处于理想状态,汽油类型鉴别的错误率也就越低。

此时,RBM的可见层与隐层对应的神经元激活概率可以表示为(8)式和(9)式:

式中,σ为sigmoid激活函数,计算方法如(10)式所示:

为了提高DBN模型的训练速度,Hionton等人提出了通过对比散度算法(CD-K)来构建可见层节点概率分布,其发现当K=1时,即只进行一步Gibbs采用便获得比较好的学习效果[17]。
2 结果与讨论
2.1 透射光谱分析
汽油样品红外光谱图如图3所示,从中可以看出,不同型号汽油样品的红外光谱大致相同,很难用肉眼进行区分。但红外光谱记录物质分子振动情况,而分子振动频率取决于组成原子的质量、化学键以及物质内部结构基团,所以原子的种类和结构基团的组合都可以在红外光谱图上表现出来,即不同物质的吸收谱带也不相同[18]。因此,借助化学计量学的方法可以对不同型号的汽油进行聚类分析。

图3 部分样品原始光谱图Fig.3 Original spectrogram of partial samples
2.2 原始光谱预处理分析
部分汽油样品原始光谱数据经预处理后的光谱图如图4所示。其中,导数处理虽然可以有效地消除基线和其他背景干扰,使某些未分辨开的重叠光谱分辨开,但是会引入噪声,降低信噪比[19]。MSC主要是消除由于颗粒分布不均匀及颗粒大小不同产生的散射对光谱的影响,其认为每条光谱与“理想光谱”都成线性关系,但在大多数情况下这种情形并不存在,而且光散射引起的背景非常复杂,仅靠校正集的平均光谱作为标准光谱是存在误差的[20]。SNV主要用来消除固体颗粒大小、表面散射以及光程变化对光谱的影响,但是假设乘法效应在整个光谱范围内是均匀的,并不一定能实现[21]。因此,本文所选择的3种预处理方法都有各自优劣之处,需要进一步分析来选择最适合本文的预处理方法。
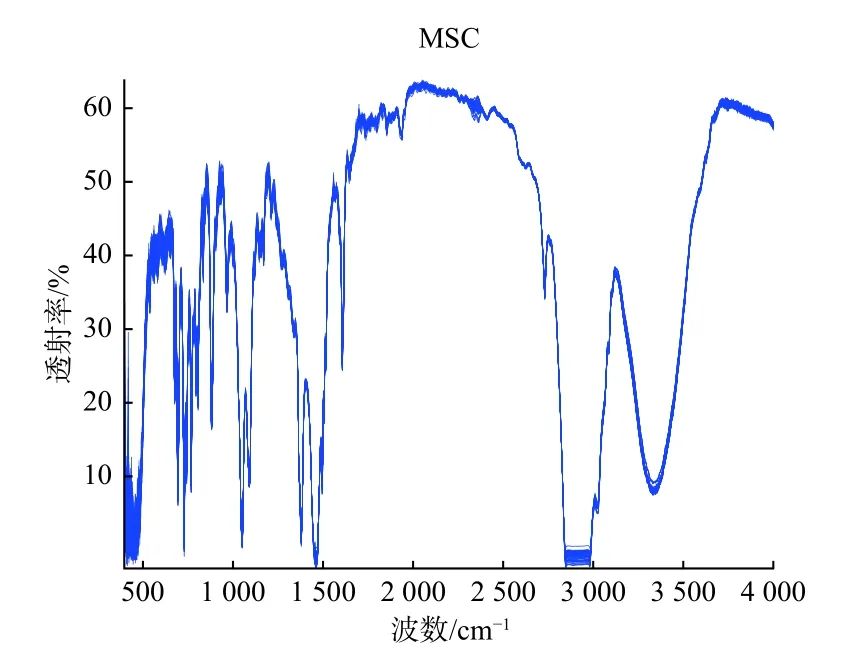
图4 预处理后光谱图Fig.4 Spectrogram after preprocessing
为确定最适合本文的预处理方法,将MSC、SNV和一阶导数预处理后的光谱数据利用t-SNE算法进行数据降维并将前3个特征向量进行可视化处理,最终得出的结论为经MSC预处理后的4种汽油光谱特征数据不仅各自聚集在一起,而且还互不相交,能够很好地将这4种汽油区分开。因此选择多元散射校正作为建模前的原始光谱数据预处理方法。
2.3 光谱数据降维方法比较及分析
为验证所选择的t-SNE算法具有一定的优越性,因此将PCA算法与t-SNE算法提取到的汽油光谱特征进行特征可视化图以比较分类效果。
选择累积贡献率超过90%的前10个特征代表汽油光谱特征,即将汽油红外光谱数据维度降至10维,将其前3个特征向量进行可视化,结果如图5所示。

图5 PCA特征可视化图Fig.5 Diagram of PCA feature visualization
由图5可以看出,经PCA算法提取的汽油光谱特征数据分类效果比较差,这是因为汽油的红外光谱中含有非线性特征信息,而PCA属于线性降维方法,不能准确提取红外光谱数据中的非线性特征信息,从而导致光谱数据在降维的过程中部分有用信息丢失,造成模型鉴别精准度下降。
2.4 DBN模型的建立及对比分析
DBN模型中的迭代次数和网络深度会对模型预测精准度产生较大的影响,以模型最终的预测精准度为判断标准来确定其参数。
DBN结构主要分为输入层、隐含层和输出层,其网络深度主要体现在隐含层数量上。又因为t-SNE将汽油样品光谱数据降维至5维,因此将输出层节点数设置为5,输出层神经元的个数需要根据成品油分类数量决定,需要将92#、95#、98#以及掺混成品油区分开,因此输出层神经元的节点数设置为4。为了确定最合适的模型迭代次数,分别将迭代次数设置为50、60、70、80、90、100、110、120、130、140、150和160进行模型构建,当迭代次数为100时,DBN网络模型的识别准确度最高,而其他迭代次数的识别准确度都低于迭代次数为100时的识别准确度,将DBN网络模型的迭代次数设置为100。为了确定模型的最佳隐含层数量,分别建立1至4层隐含层的DBN网络模型,以比较不同隐含层数对模型预测精准度影响。当隐含层数设置为1时,DBN网络模型的识别准确度仅为75%,当隐含层数量增加到2时,DBN模型的识别准确度相较一个隐含层时有较大的提升,识别准确度已到达92.5%,然而继续增加网络模型的隐含层数时,其模型识别度开始降低。因此,所建立的DBN网络模型的隐含层数量为2。因此,构建一个结构为5-10-20-4的DBN网络模型对4种类型汽油样本进行特征学习和分类。
为了进一步验证分类算法有效性,分别利用深度置信网络算法与极限学习机算法建立汽油鉴别模型并比较这两种模型在测试集中的鉴别精准度。ELM模型的识别精准度为80%,而DBN模型的识别精准度为92.5%。由此可见,DBN 模型分类效果更加良好。这是由于采用非线性算法t-SNE对光谱数据进行降维处理,降低了数据在降维过程中有用信息丢失的可能性,再者DBN模型拥有更深层次的网络学习结构,训练网络时采用反向传播微调方法,使得训练后的网络具有更好的识别能力,因而汽油种类鉴别精准度更高。
3 结论
本文提出了一种t-SNE和DBN二者相结合的汽油种类鉴别方法。在对汽油原始光谱数据进行多元散射校正预处理后,利用t-SNE算法对预处理后的光谱数据进行降维以提取光谱特征信息,最后将光谱特征信息作为DBN网络的输入并构建汽油种类鉴别模型,通过在MATLAB上进行测试,最终的实验结果表明优选的方法具有更好的鉴别效果。
