基于词向量和深度学习模型的医疗数据分析方法研究
2021-06-04金玮左嵩许健黄于飞巩清源潘伟华
金玮, 左嵩, 许健, 黄于飞, 巩清源, 潘伟华
(上海交通大学医学院附属新华医院 信息管理部, 上海 200025)
0 引言
随着信息科技的不断进步,电子医学数据量日渐庞大且越来越多样化[1-3],有效地识别、分类电子医疗数据的文本,可以帮助医生提高诊断疾病的效率。而传统医学文本,尤其是大量的医学案例文本,具有众多共同的特征,例如一些专有名词与缩略语等。此时,结合自然语言处理的共同特点,即对一些词语如文本的上下文的连接词、结束语、否定词进行提取特征处理。文中首先将医学词典加入到分词中,并对文本中的词语进行共现性统计。尽可能地保留文本数据的语义信息,改善传统词向量训练法的局限性。其次,使用定长矩阵表示文本数据,使预处理后的数据以矩阵的形式加入到神经网络中。最终通过综合学习对多个神经网络模型进行训练,得到一个优化的整合模型,能够更优地预测疾病。
本文采用两所三级医院的病历档案,包括目前病史、既往病史、诊断依据、医学影像数据,测试数据为CSV格式。反复挑选后,得到2 432个数据。文中将挑选后的数据经过预处理后,按一定比例分别用于训练与测试。
1 预处理
汉语文本不同于拉丁语文本,以汉语特征为单位作为单词。单词之间未有空格,所以需要将整个句子预处理成多个单词,这种预处理技术就是分词技术。近年来,发展的中文分词技术方法主要有以下类别[4-6]:基于分词算法与基于统计的机器学习算法。本文采用一个基于Java实现、包含多种词典的分布式中文分词组件——“Word”工具。该工具能通过模型准确识别各种常见词汇和用户自定义的词库。对于医学文本上下文的分词识别,还需优化以下问题:
(1) 医学术语的提取。本文增加了一些独特的医学词汇,利用Word的自定义词典技术,增加了ICD10标准词汇与完整的医学词典等专业词汇。
(2) 结束语的权重。医疗文本数据中含有大量的结束语文字,虽然频率较高,但对分类预测未有实际意义。本文通过使用[7-8]单词权重调整的方法进行了优化,如式(1)—式(3)。
(1)
(2)
(3)
式中,Fd为调节词权重的因子;N为文件数;i为从1开始的整数文件;λ为经验参数,本文中取值为0.2。根据权重值来处理结束语,调整词的权重可得到式(2),n为调节权重参数,式(2)的前半部分表示在该文档中的出现次数与在所有文件中出现次数的比值,后半部分是根据词汇对文档的重要程度进行调整,起到降低高频词权重的作用。本文采用式(3)来保证语料库中词数的总数保持不变。
(3)否定词的语义处理。本文将否定词保留在数据中,并对这些词进行严格的分离,从而保留这些语义信息,并抽象出不同的语言特征。
2 词向量训练与矩阵定长表示
本文通过GloVe模型[9-11]对分词后的词向量进行训练。通过以Word2Vec模型为基础的文档全局信息,GolVe模型尽可能地统计词的共现性来探索医学文本的语义,这与分词中基于统计的机器学习算法较为相似。
首先计算共生矩阵,单词的协同出现是在一个固定的窗口内建立的。在给定范围后,可以得到一个V×V矩阵,其中V是词汇表的大小。在GloVe模型中,使用与Word2Vec相比的共生矩阵调整损失函数。
文中将Skip-gram模型同样应用于实际训练中,如图1所示。

图1 Skip-Gram模型
其由以下三层结构层组成。
(1) 输入层:根据输入的文本词向量进行统计排序,构建一个单词词汇表,并使用One-hot进行编码;
(2) 隐含层:构建权重矩阵,评估每个词汇表单中各单词出现的概率;
(3) 输出层:使用Softmax分类器求取隐含层的词向量输出概率,概率最大的词向量即是训练结果。
经过词向量训练后,得到词在向量空间V的映射,即医疗文本数据中的每个字di对应一个向量vi。每个病案的结构不一致,描述文本的长度也不同,导致经过分词与词向量训练的每个病历数据的二维矩阵空间宽度不统一,最终引起接下来的网络学习出现偏差。为改善这一问题,则标准化表示所有文本的二维矩阵Mi,以获得统一的宽度。
本文提出使用定长的文本矩阵表示方法,通过对小于长度L的中文分词提高矩阵的维数Wd。对超过长度L的中文分词进行降维,并最终表示成L×L矩阵M。
当Wd
Tanimoto系数可以用来判断两个数据集合的相关程度,在文中其被用来评价词向量的相似度,即可认为是欧几里德距离与余弦相似度的扩展,如式(4)。
(4)
式中,x、y分别表示两个数据集合的特征向量,xi、yi分别是向量中第i维度的元素。T(x,y)的数值在0-1之间,两个集合完全相似为1,未相似为0。即数值越趋向1,则两个向量越相似。
值得关注的是,文本数据中的词向量是按词序排列的。若更改了词向量,则会影响特征提取的准确性。因此选择Tanimoto系数最小的两个相邻向量求取平均值,即可最大限度地保留原始语义信息,同时也可以消除冗余过程。该结果算法如下:

INPUT二维矩阵:Mi=[vT1,vT2,…,vTk]T;Tanimoto系数:tani;最大系数值:t_max.PROCESS1. for i=k+1, …, L2. for j=1, 2, …, L-13. t_max==Max(tani(vj, vj+1), t_max); index=j of t_max4. end for5. vindes=0.5×(vindex+vindes+1)6. reansfer Mi×L to Mi-1 ×L7. end forOUTPUT固定长度矩阵:M'i=[v'T1,v'T2,…,v'TL]T
3 神经网络特征提取
3.1 Yoon模型
Yoon的网络模型[12-13],如图2 所示。

图2 Yoon模型
卷积核的宽度即为训练词向量矩阵的维数;而卷积核在每个通道中的长度各有不同,这代表了词汇文本在整个文档中的接近程度。多个通道以后是一个全局最大池化层,其将对每个过滤器提取的向量特征进行处理。最终将提取的每个通道特征相结合,并对一个完整的句子进行特征提取。后续处理包括了各种预测,这些预测均是基于这一代表句的特征。
本文借鉴了Yoon模型的思想,在该模型采用多个卷积层对不同核大小的矩阵实数进行卷积。其中词向量的维数与每个窗口的长度相同,即为L。在实际中表示的是抽象空间中相邻k个词之间的语义关系,然后提取特征。根据相邻4个字向量之间的关系,该模型采用Relu激活函数,输出层采用Softmax激活函数,最终全局池化层与全连接输出层输出概率值。
3.2 LSTM模型
LSTM模型[14-15]是一种独特的循环神经网络模型,可以避免长期依赖性问题。LSTM保留了沿时间与层的反向传输错误,将误差保持在一个更恒定的水平。并将信息存储在循环网络流之外的“记忆门”中,且设置了“遗忘门”选择性遗忘某些历史信息。
本文将每个LSTM单元的“遗忘门”偏差设为1,输出层激活函数采用软符号激活函数。
4 学习与分类方法
本文提出了一种基于堆叠学习方法的集成学习分类方法,而堆叠是一种经典的学习方法。其首先将原始数据集作为初级学习者进行训练,然后将这些初级学习者的输出作为新的数据集再进行训练,从而得到“元学习者”。文中采用的算法主要有:

INPUT训练集:D=x1,y1 ,x2,y2 ,…,xm,ym ;初次学习算法:L1,L2,…,LT;二次学习方法:L.PROCESS1. for i=1, 2, …, T2. hi=LiD 3. end for4. D'=ϕ5. for i=1,2,…,m6. for i=1, 2, …, T7. zij=hjxi 8. end for9. D'=D'∪zi1,zi2,…,ziT ,yi 10. end for11. h'=LD' OUTPUTHx =h'h1x ,h2x ,…,hTx
文中采用堆叠学习的思想,将数据集随机分成两部分。对上述LSTM改进模型与Yoon改进模型进行了训练,然后将其输出值作为“元学习者”的数据输入,最终得到一个完整的综合模型。
5 实验结果
本文基于实际收集的电子医疗数据集合,通过不同的机器学习分类方法,以逆向文件频率(TF-IDF)作为权重对文档特征进行分类,得到不同学习模型与综合模型下的分类预测性能。文中的实验是基于Win10系统、32 GB内存的工作站系统环境,编程语言为Python。外部框架有:TensorFlow、Python版的TextCNN(用于神经网络模型训练)、Python版的LTP工具(用于词性标注)、Pyhton版的Gensim工具(用于Word2Vec向量表示),所涉及的集中模型实验参数设置如下。
(1) Word2Vec:模型结构为Skip-gram,词向量维度为200,窗口大小为10;
(2) LSTM模型:隐藏节点为256,隐藏层数为2,Batch大小为256,学习率为0.01,训练循环次数为50;
(3) 深度学习:卷积核高度为2、3、4,卷积核的数量为256,Batch大小为256,Dropout为0.5,损失函数为交叉熵。
根据病历档案的2 432个文本数据,按照一定的比例分为训练集与测试集。基于传统机器学习的各类分类器分类性能,如表1所示。

表1 基于传统机器学习方法的分类预测性能
从表1的实验结果可看出,支持向量机(SVM)方法的性能优于其他分类器,但仍未达到较优的准确率,最高也仅有82.9 %。其原因与否定词的处理方法有关,影响了医疗诊断的准确性。
测试结果,如表2所示。
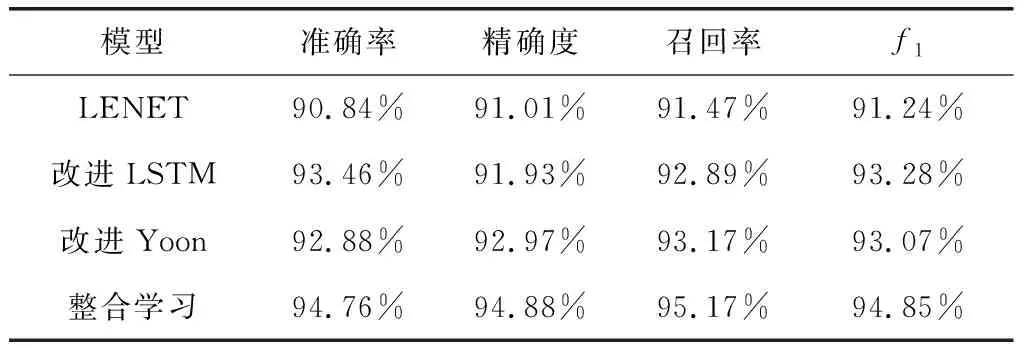
表2 各种模型下的电子病历分类性能指标
尽管两种模型的特点有所不同,采用整合学习模型使LSTM改进模型与Yoon改进模型的优势得到了综合发挥。从结果可以看出,本文提出的综合模型在电子病历数据的分类中,体现出较优的效果,较改进LSTM模型与改进Yoon模型在各参考性能参数中均提高了约1 %;较参考图像[16]处理中提出的LENET分类准确率提高了约4 %。
这两种学习模型各自的优缺点得到了涵盖与补充,并尽可能地扩大了潜在语义信息的保留程度。综合学习模型能够抽象地提取出文本的特征,对分类性能有显著的提高。
6 总结
本文为了提高医疗数据文本的分类预测性能,提出了一种固定长度的二维矩阵文本表示方法。对经过词向量训练预处理后的数据,以固定长度的二维矩阵形式加入到神经网络中,并结合改进的Yoon模型与改进的LSTM模型进行优化。最终,在实际医院数据集上进行实验测试。实验结果数据表明,优化后的整合模型对提高医疗数据文本的识别与分类预测性能有较为显著的成效。
