命名数据网络中基于内容类型的隔跳概率缓存机制
2021-06-04张玉军
郭 江 王 淼 张玉军
1(中国科学院计算技术研究所 北京 100190) 2(中国科学院大学 北京 100049)
随着互联网规模和业务类型的爆炸式增长,主流应用模式从主机互联和计算资源共享逐步转变为信息获取服务,例如视频分发、文件下载等[1].以TCP/IP为基础的互联网采用以IP地址为中心的端到端通信模式,导致网络上存在大量数据的重复传输,造成骨干网络的流量激增.这种通信模式与互联网主流应用的不匹配,导致现有互联网在扩展性、动态性、安全可控性等方面面临严峻的挑战[2].为解决TCP/IP体系结构存在的问题,全新的信息中心网络(information-centric networking, ICN)[3]设计思想被提出,其中命名数据网络(named data networking, NDN)[4-5]是最受关注的ICN方案之一.NDN网络以内容本身为中心,采用用户请求驱动通信模式,依据内容名字进行路由与转发,并提供基于内嵌的网络化缓存机制,这种设计使得网络节点(例如路由节点)被赋予存储功能,可直接向用户提供信息与服务,实现用户对内容的高速获取,有效降低网络带宽的占用,减轻内容发布者的响应负担,从而极大缓解网络流量爆炸性增长问题.
现有NDN对网络化缓存的设计相对简单,只注重缓存基本功能的实现,缺乏对性能方面的考虑.NDN采用泛在缓存机制(leave copy everywhere, LCE)[6],即内容发送至用户的传输路径上所有路由节点都无差别地对内容进行缓存.这种机制简单、易于部署,但存在2个问题,使得缓存性能较低:
1) 冗余缓存,泛在缓存导致内容传输路径上各节点重复缓存相同内容副本,这种逐跳缓存使得网内缓存内容的同质化,特别在缓存容量有限的条件下,降低整个网络的缓存利用率.已有研究表明[7]:在某些场景下,沿路径的随机缓存机制(即在内容发送的下行路径上随机选择一个节点对内容进行缓存)甚至都比LCE机制能获得更好的性能提升.
2) 内容缓存无差别对待,LCE机制对于所有的内容都执行相同的缓存决策,缺乏针对内容类型的差异化缓存服务需求考虑,难以提高缓存性能.
为了解决泛在缓存中的冗余缓存等问题,研究者们提出了各种优化缓存方法[7-14].现有工作[7-10,12-13]主要从单一因素考虑缓存,难以在网络化缓存系统中做出合理的缓存决策,例如网络拓扑结构、热度内容感知、基于概率性选择.尽管工作[11]结合网络拓扑和内容热度2个方面综合考虑缓存决策,但忽略内容业务类型重要影响因素.
上述缓存优化方案无法准确地降低冗余缓存,其根本原因主要有2个:1)现有网络化缓存机制不能识别内容的业务类型,无法区分哪些内容是否需要缓存服务;2)基于单一信息的策略难以实现精确缓存,从信息论角度看,信息越少则变量的熵值越大,即不确定性越大.因此,本文综合考虑网络拓扑和内容类型,提出了一种命名数据网络中基于内容类型的隔跳概率缓存机制(content type based jumping probability caching mechanism in NDN, CTJP).该机制允许沿途路由节点首先执行隔跳待定缓存策略,使得内容副本存储在沿途非连续节点,有效地减少冗余缓存;然后,执行基于内容类型的概率缓存策略,即根据内容不同的业务特征,将缓存内容划分为4种类型:收到内容包的路由节点根据内容类型和请求聚合度计算缓存概率;分别提供无缓存、网络边缘缓存、网络次边缘缓存以及网络核心缓存;减少冗余缓存;提升用户获取内容的效率.实验结果表明,与典型缓存方案相比,CTJP机制能够降低缓存冗余,同时实现用户对内容的高效获取.
1 相关工作
1.1 NDN背景
NDN网络包括用户(user)、内容发布者(content provider)和路由器(router)3类实体,其数据传输主要包括2种类型:兴趣包(interest)和数据包(data).兴趣包是由用户发送的数据请求包,其中包括请求的内容名称(contentName)等;数据包是由发布者或路由器根据用户的请求返回的内容,其中包括内容名称(contentName)、内容本身(content)等.NDN网络中单个节点通信流程如图1所示.每个实体包含3种数据结构,分别是内容存储(content store, CS)、待定兴趣表(pending interest table, PIT)和转发信息库(forwarding information base, FIB).CS用于存储接收到的数据包,对于后续相同的内容请求从本地响应数据包,有利于减少对于发布者的访问次数,提升内容分发的传输效率;PIT记录待转发兴趣包的内容名称以及接入接口,并且汇聚相同的兴趣包在一个表项中;FIB依靠路由协议生成,记录兴趣包转发下一跳接口.
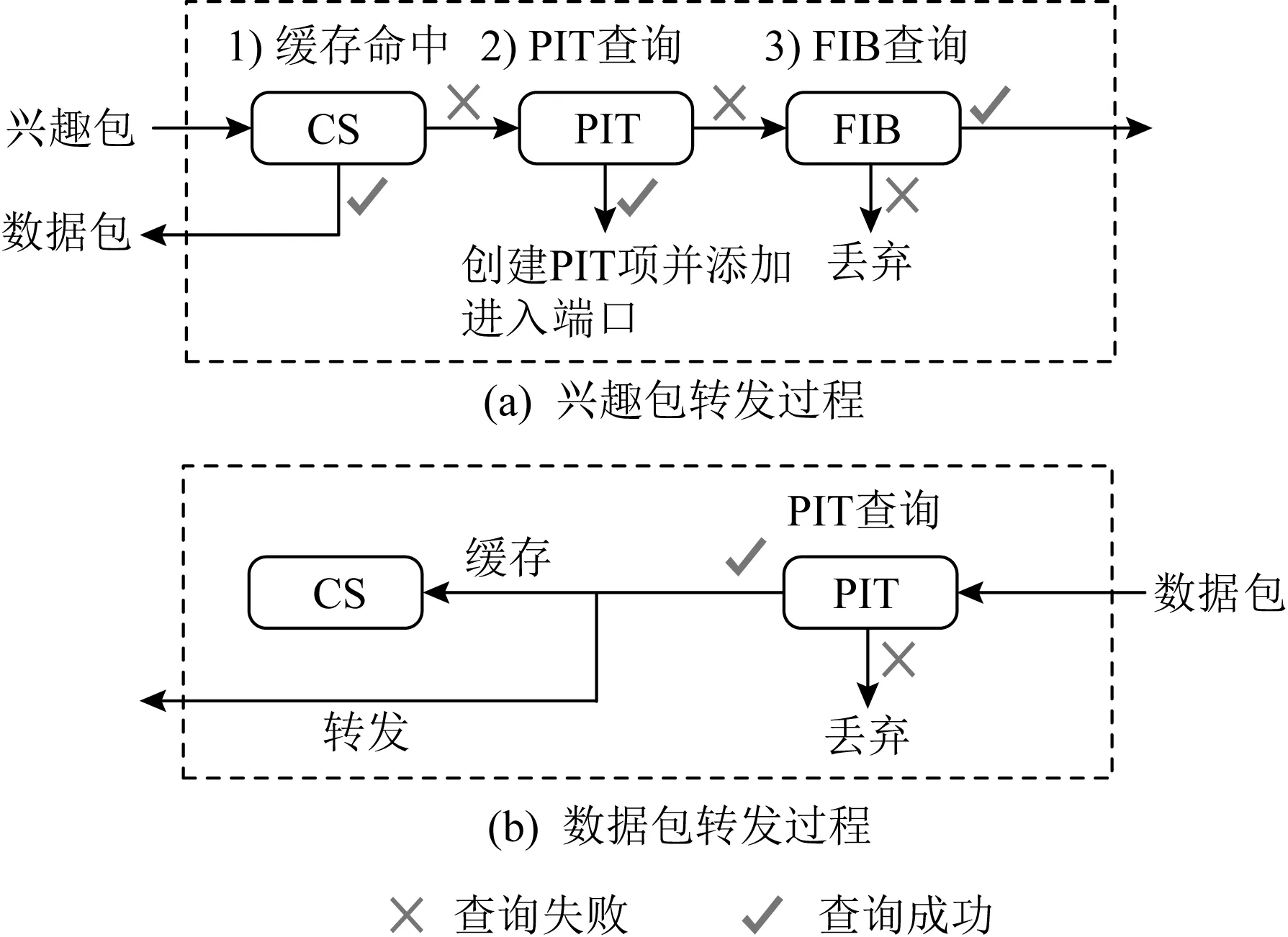
Fig. 1 Communication flow of single node in NDN图1 命名数据网络单个节点通信流程
NDN网络用户获取内容的过程分3个步骤:
1) 当需要内容时,用户发送一个兴趣包.路由器收到兴趣包后,首先查找CS是否有请求的数据,如果有,则从兴趣包接入接口返回数据包并丢弃兴趣包;否则,继续查找PIT,查找之前是否转发来自其他节点的,并且与该条目的请求内容相同的兴趣包.如果找到,则将本次兴趣包的接入接口添加到对应的PIT信息条目中;否则,在PIT中创建兴趣包接入接口的信息条目,继续查找FIB,进行路由寻址.
2) 兴趣包到达发布者并找到内容对象时,兴趣包被丢弃,响应的信息以数据包的形式原路返回.当数据包到达路由器时,首先查找CS,如果有相同的缓存数据,则丢弃数据包;若没有,则与PIT中条目匹配.如果PIT中有匹配条目,则向相应的接口转发数据包,缓存数据包在CS中,并删除PIT中的匹配条目;否则丢弃数据包.
3) 用户在接收到数据包后进行签名验证,确保内容完整性和真实性.
1.2 内容业务划分
NDN网络提供差异化服务主要体现在请求路由、内容转发、缓存策略等方面[15-24].Kim等人[15]提出了差异化服务的转发和缓存机制,由内容发布者标记内容属于哪个分类并注册到网络,当路由节点收到数据包时,读取数据包的标记判断内容属于哪个分类,并将内容缓存到该分类对应的缓存空间中.该模型实现了差异化服务的缓存,但每种类型的缓存空间大小是固定的,而且在沿途节点都缓存数据包,容易造成数据冗余,浪费宝贵的缓存资源.针对视频流业务,Li等人[16]提出了一种沿途协作缓存算法,节点记录内容索引与其标签值相等的数据单元,避免相同内容的重复冗余缓存.Guo等人[17]设计了一种支持实时内容快速传输的机制BoNDN,通过在路由节点增加订阅推送表,实现对实时数据包转发.该方案对于非实时业务内容采用NDN原有转发机制,对于实时动态业务内容(例如区块链中的区块)采用推送机制,但缺乏缓存策略的考虑.
1.3 缓存策略
缓存策略是NDN网络研究热点之一,考虑缓存哪些内容、缓存位置选择、缓存内容替换等问题中实现差异化缓存,获取较高命中率.Laoutaris等人[8]提出了LCD(leave copy down)缓存机制,内容响应过程中仅在命中节点的下一跳节点存储内容副本,随着后续相同的用户请求不断达到,内容副本逐步被拉向用户侧.这种隐式协作缓存方法易于实现,但是随着重复请求增多(例如,请求流行度高的内容),沿传输路径上的各路由节点都缓存内容副本,因此仍存在无效缓存和冗余缓存问题.Psaras等人[9]提出了基于概率缓存方法ProbCache,传输路径上的各路由节点基于一定的概率决定是否缓存内容,从而减少传输路径上的内容副本数量.Sun等人[25]提出了基于路由跳数的概率缓存方法HPC,引入路由跳数作为缓存权重,计算缓存概率,使得距离用户侧的缓存可能性越大,从而减少用户请求的时延.这2种方法一定程度上减小网内缓存冗余,但对于那些共享度低、私有性强的动态内容依旧会进行缓存,显然这类内容缓存造成资源浪费.Chai等人[7]提出了基于节点中心度的缓存策略Betw,通过统计路由节点的中心度值,并以其值作为衡量节点的重要程度,由汇聚能力更强中心度最高的节点对内容进行缓存.这种策略使得内容过于集中在中心度高的节点上,容易导致这类节点发生高频缓存替换操作,不利于整个网络化缓存性能的提升.Cho等人[10]提出了基于热度的缓存机制WAVE,用户对同一内容的不同分块的请求具有连续性,根据内容热度决定对该内容不同块的缓存数量,以便减少非热度内容的缓存.然而这类基于本地视图的缓存策略因忽略了边缘节点对请求热度的过滤影响[26]而无法准确感知热度内容,也不能合理规划热度内容的缓存位置.另外,Zheng等人[11]提出了基于网络拓扑和内容热度的缓存策略BEP,通过将热度较高的内容缓存在重要程度较高的节点,降低缓存替换率,减少冗余缓存,但忽略了内容类型对缓存的影响.
综上,目前的研究已经取得了许多积极的成果,多数工作是基于网络拓扑、内容热度等单一因素考虑缓存,以提高缓存利用率,尽管BEP结合网络拓扑和内容热度2方面进行缓存决策,但这些工作都没有考虑内容类型这一重要影响因素.本文引入内容类型因素,并考虑网络拓扑和内容热度方面,提出了一种命名数据网络中基于内容类型的隔跳概率缓存方法,旨在兼顾效率的同时解决冗余缓存问题.
2 CTJP机制
CTJP机制整体工作流程如图2所示,其设计思想:对接收的数据包,网络节点先依据PendingCache标识,判断是否有必要缓存,若无需缓存,则直接转发;否则执行隔离待定缓存策略,进一步查看CotentType标识,判断数据包所属内容类型,并提供不同的缓存决策:无缓存、基于网络边缘概率缓存、基于网络次边缘概率缓存和基于网络核心概率缓存.首先介绍CTJP机制支持的内容类型以及包格式扩展,然后具体说明缓存算法,最后描述数据传输中缓存的详细过程.
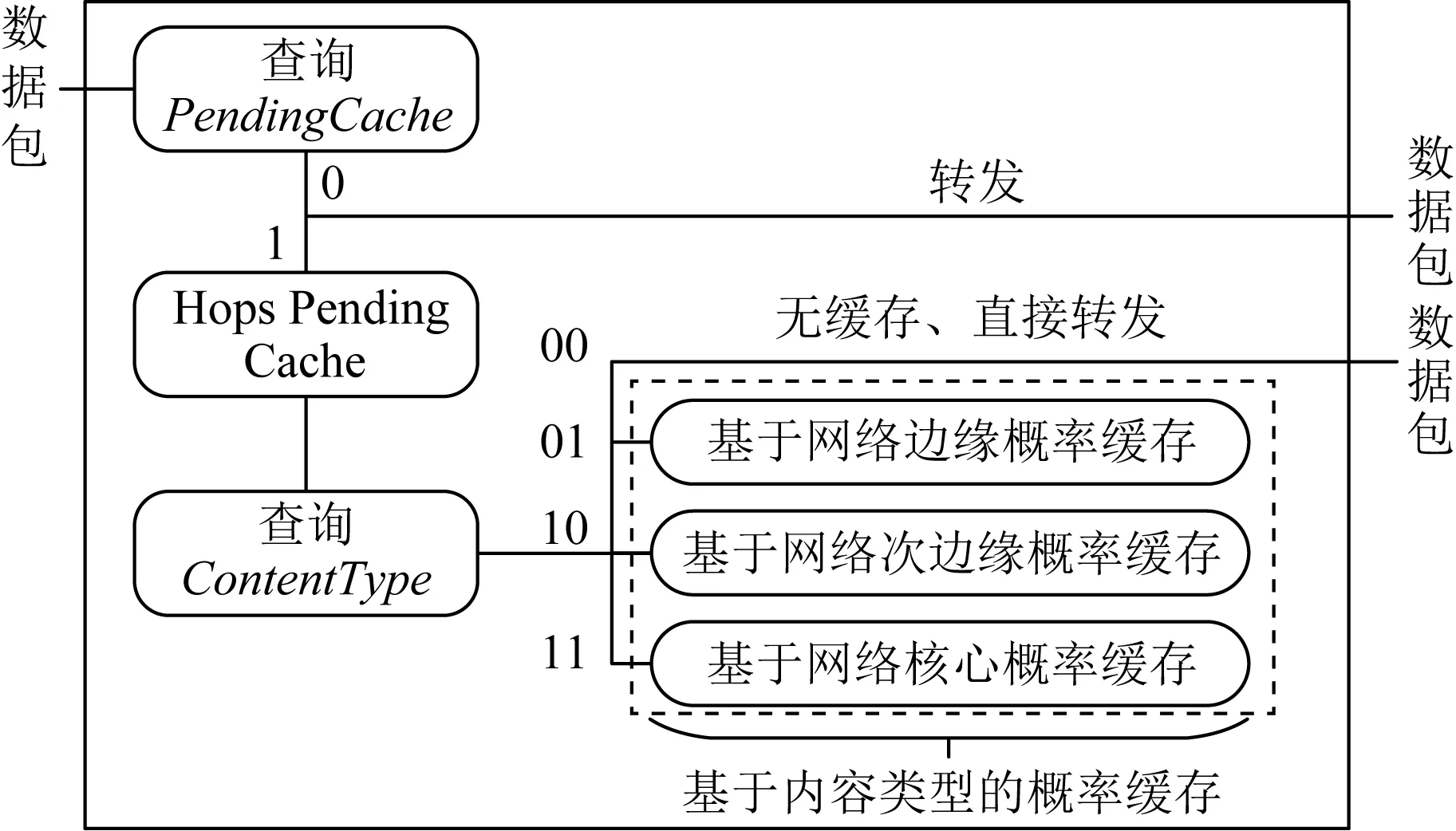
Fig. 2 Workflow of CTJP图2 CTJP机制整体工作流程
2.1 内容类型定义
考虑用户、内容发布者、中间路由对质量服务QoS的要求,首先对不同业务内容进行类型划分,以便支持后续的内容缓存策略.根据业务的共享程度、时延要求、带宽占用等特征,将缓存内容划分为4类:动态类、实时类、大数据类、小数据类,类型代码分别为00,01,10,11,如图3所示.对于动态类(类型1),例如邮件、即时通信等,该类业务内容后续共享程度低[17],中间路由没有必要浪费宝贵的资源对其缓存;对于实时类(类型2),例如直播视频、网络电视等,该类业务后续共享程度高,此外请求时延要求严格[16],将其缓存在网络边缘节点比在网络核心节点更好地提供低延时服务;大数据类(类型3),例如离线视频、音频等,该类业务包含的内容文件容量大,通常被划分为多个数据单元(内容块),除了时延要求低于实时类业务,但对于带宽资源要求大,将其缓存在网络次边缘,既避免占用网络边缘稀缺资源,又节省网络带宽的占用;小数据类(类型4),例如网页、共享文件等,该类业务内容文件容量小,对于时延和带宽要求比较低[27],将其缓存在网络核心节点,有利于网络缓存负载平衡.
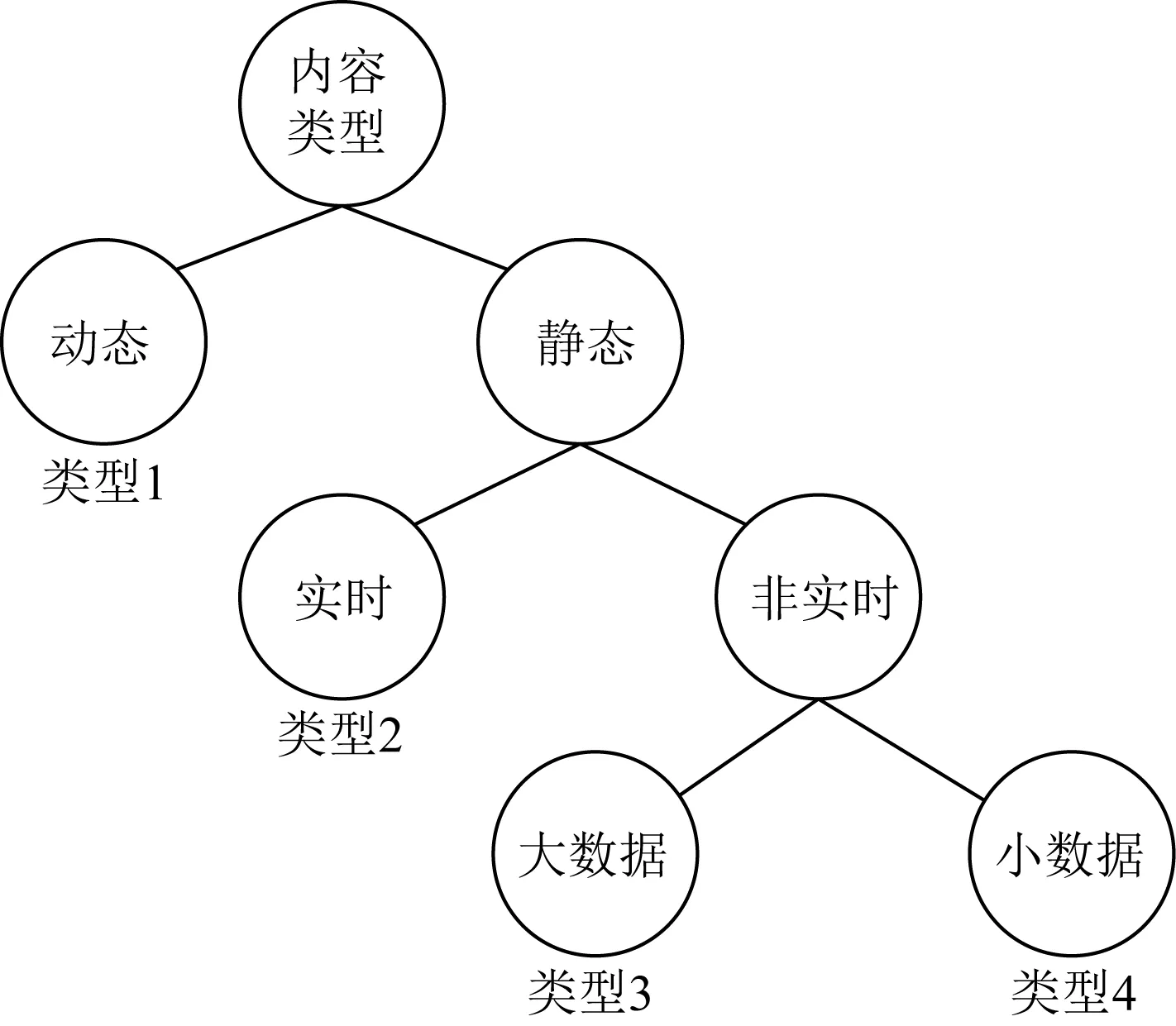
Fig. 3 Types of content service图3 内容业务分类
2.2 包格式扩展
为支持数据传输过程中基于内容业务的缓存策略,在保留NDN原有的基础上,对兴趣包和数据包的格式进行扩展,如图4所示.兴趣包仅增加IntHop字段,用于记录兴趣包转发的路由跳数.数据包增加3个字段:PendingCache,ContentType,DataHop,其中PendingCache标志是否执行隔跳待定缓存策略,ContentType标识数据包内容的业务类型,DataHop记录的是数据包沿途返回中经过路由的跳数.
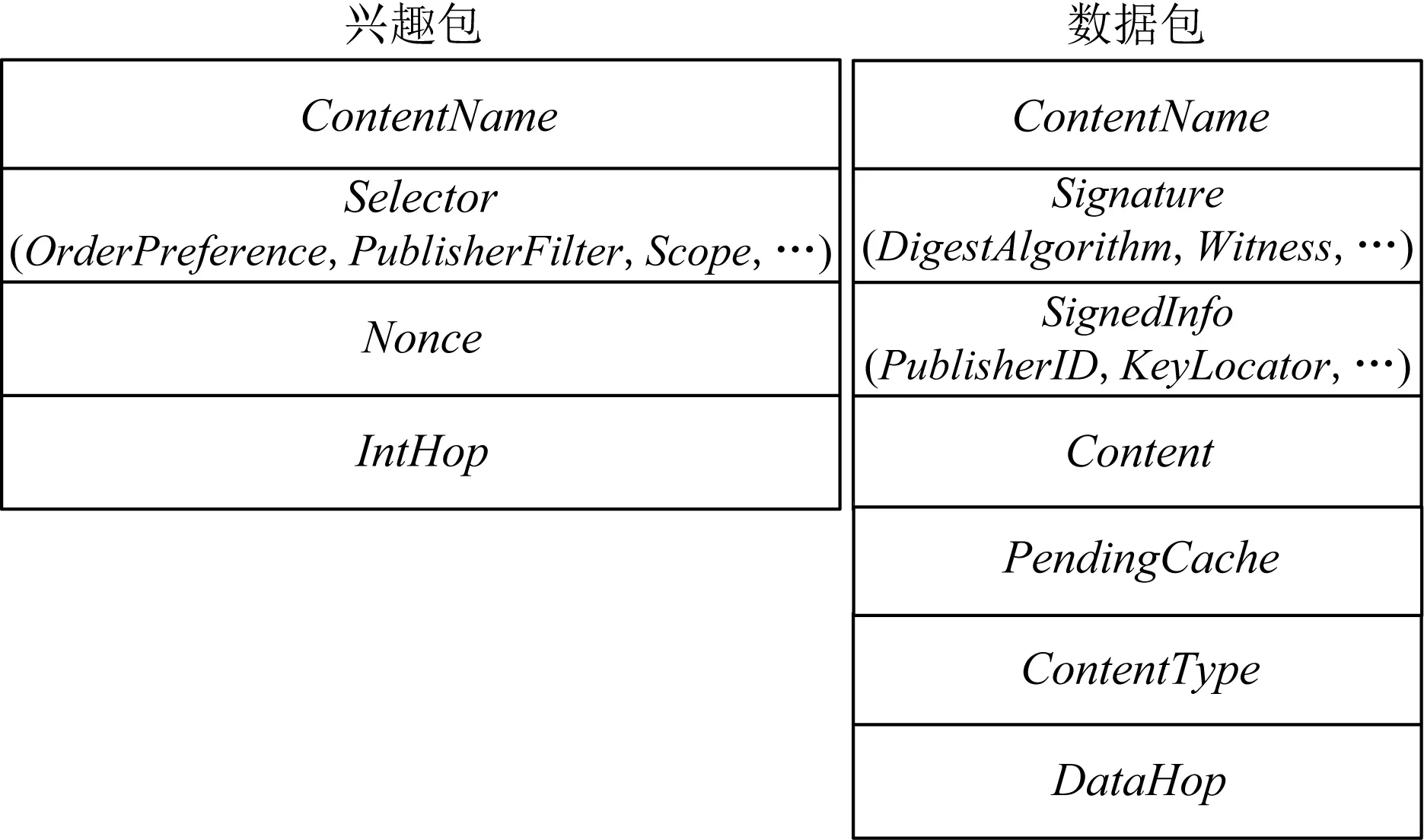
Fig. 4 Extended packet format图4 扩展后的包格式
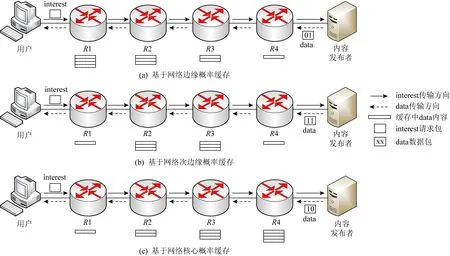
Fig. 5 Based on content type probability caching policy图5 基于内容类型的概率缓存策略
2.3 缓存算法
在数据包返回给用户阶段,沿途路由节点根据缓存算法对该内容选择性缓存.缓存算法分为2个部分,隔跳待定缓存策略和基于内容类型的概率缓存策略.
2.3.1 隔跳待定缓存策略
本文将数据存储在非连续的传输节点上,从空间上减少冗余缓存.随着隔跳跨度的增加,尽管缓存的冗余将逐渐减小,但是其他用户请求响应的时间也将增大.具体选择相隔多少跳数进行缓存数据比较合理,还需进行建模分析.在此,我们通过路由节点对数据包进行隔一跳待定缓存,既有效地减半冗余缓存,提高网络化缓存内容的多样性,节省对数据包缓存所需的操作开销,又避免用户请求响应时间的增大.具体地,沿途路由节点对到达的数据包进行逐一检查,若数据包的扩展字段PendingCache值标记为1,则待定缓存到本地,并对PendingCache值取反操作,即标记为0;否则不进行缓存,并对PendingCache值取反操作,即标记为1.
2.3.2 基于内容类型的概率缓存策略
为了进一步减少冗余缓存,基于内容类型概率缓存策略提供差异化的网络缓存服务.根据第2节中提出的4种内容类型,分别提供无缓存、网络边缘缓存、网络次边缘缓存,网络核心缓存.针对动态类内容,沿途路由节点不进行任何缓存操作,从而节省大量不必要的缓存空间和时间;针对实时类内容,沿途路由节点采用基于网络边缘概率缓存方法,如图5(a)所示,即从内容发布者到用户传输路径中,中间路由节点以递增概率缓存数据包,使得类型2内容大概率缓存在网络边缘,以满足用户低时延的服务要求;针对大数据类内容,沿途路由节点执行基于递增递减概率缓存方法,如图5(b)所示,即中间路由节点先以递增概率再以递减概率缓存数据包,使得类型3内容大概率缓存在网络次边缘,以节省带宽;针对小数据类内容,沿途路由节点采用基于网络核心概率缓存方法,如图5(c)所示,即中间路由节点以递减概率缓存数据包,使得类型4内容大概率缓存在网络核心,避免在网络边缘汇聚过多而造成高频缓存替换操作.
缓存策略具体过程如算法1所示,当用户发送兴趣包时,通过兴趣包的上行逐跳传输,依次更新传输路径跳数IntHop,即每当兴趣包抵达下一个节点,传输跳数加1;兴趣包到达内容发布者,记录的就是沿途传输路径节点的数目.当数据包沿回路传输时,沿途节点先判断数据包内容类型,按照4种方式计算缓存概率:
1) 若ContentType=00,则不进行缓存并对数据包进行直接转发.
2) 若ContentType=01,则依据PIT表的接口列表统计对应名字的接口数量,即请求聚合度β,反映同一时间段内用户请求内容的热度;计算TotalHop(IntHop与DataHop之和),其表示请求用户与内容发布者的距离;计算DataHop和TotalHop相关比值,其反映数据包距离请求侧的远近;按照式(1)计算沿途节点的缓存概率为
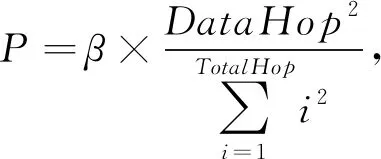
1≤DataHop≤TotalHop.
(1)
3) 若ContentType为10,则依据PIT表的请求聚合度β和TotalHop,计算沿途节点的缓存概率为
(2)
4) 若ContentType为11,则依据PIT表的请求聚合度β和TotalHop,计算沿途节点的缓存概率为
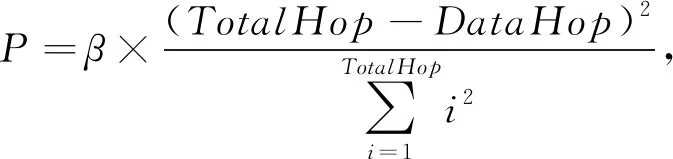
1≤DataHop≤TotalHop.
(3)
算法1.路由节点缓存算法.
/*兴趣包处理*/
/*Interest(n)是请求名字为n的兴趣包*/
IFIsCache(n) THEN
GenerateData(n);
CachePending置0;
根据PIT表转发数据包;
ELSE
IFIsPIT(n) THEN
AddPITInterface(n);
ELSE
AddPITEntry(n);
IntHop++;
根据FIB表转发兴趣包;
END IF
END IF
EXIT
/*数据包处理*/
/*Data(n)是对应名字为n的数据包*/
1) /*隔跳待定缓存策略*/
IFPendingCache=1 THEN
PendingCache置0;
Goto 2);
ELSE
PendingCache置1;
Goto 3);
END IF
EXIT
2) /*基于内容类型的概率缓存策略*/
IFContentType=00 THEN
Goto 3);
ELSE
统计PIT(n)请求聚合度β;
TotalHop=DataHop+IntHop;
获取DataHop;
END IF
IFContentType=01 THEN
计算概率P1并赋值到变量P;
ELSE IFContentType=10 THEN
计算概率P2并赋值到变量P;
ELSE
计算概率P3并赋值到变量P;
END IF
END IF
IFP>概率门限值P0THEN
存储数据包到CS;
END IF
3)DataHop++;
根据PIT表转发数据包;
EXIT
2.4 包转发和缓存过程
命名数据网络中基于内容类型的包转发和缓存流程,如图6、图7所示:
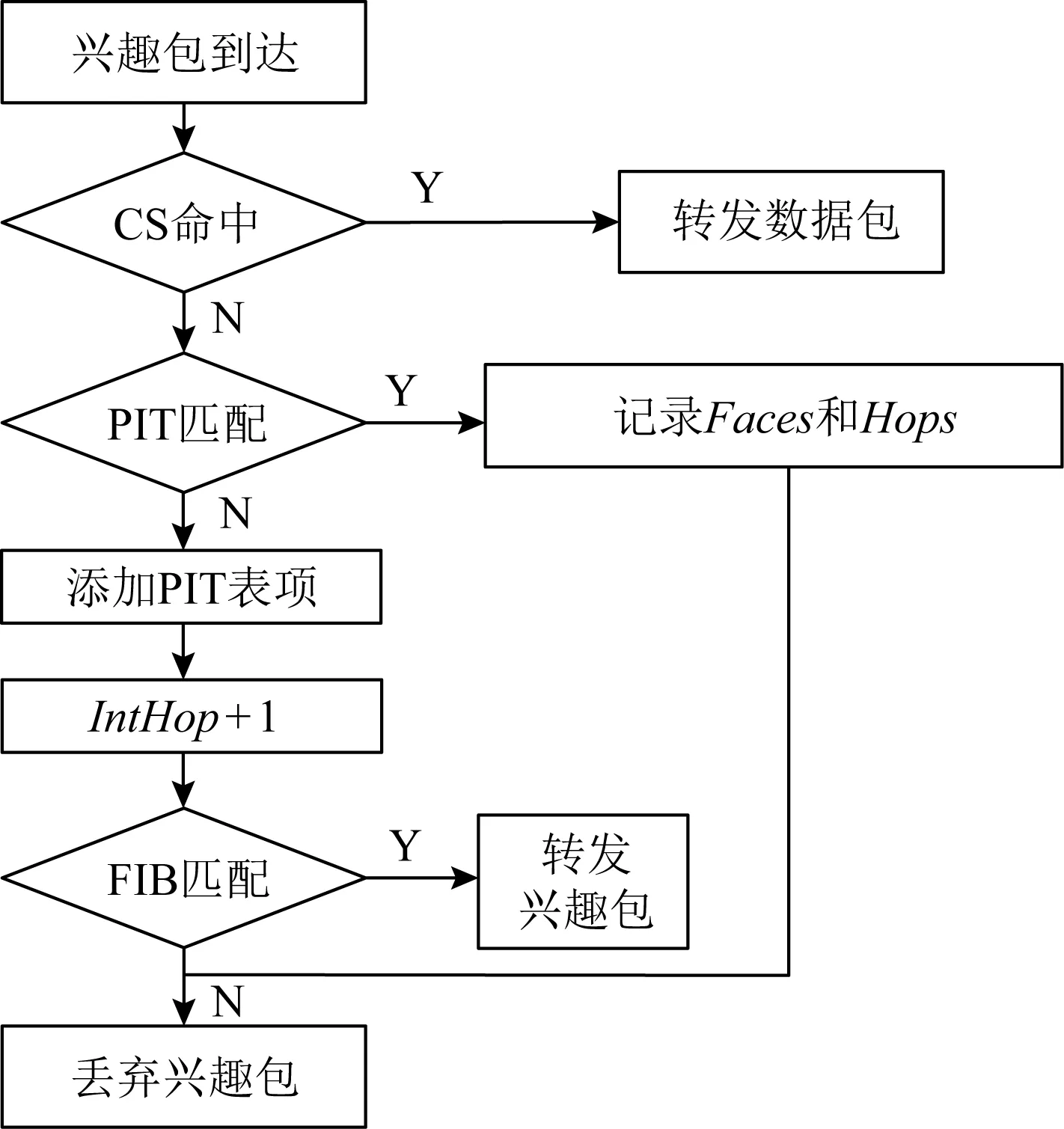
Fig. 6 The process of interest forward图6 兴趣包转发流程图
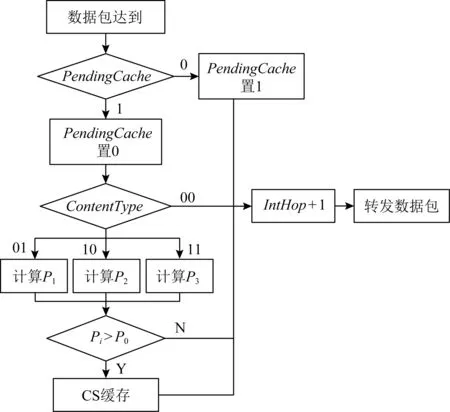
Fig. 7 The process of data forward图7 数据包转发流程图
步骤1. 用户发送请求兴趣包(interest),路由节点接收到兴趣包后查找CS表,若找到对应名字的缓存内容,则返回数据包(data);否则执行步骤2.
步骤2. 查找PIT,若PIT中存在对应内容名字的记录,按照路由节点原有的处理流程将进入端口号,端口数和跳数记录在对应的PIT表项上;否则执行步骤3.
步骤3. 按照路由节点原有的处理流程增加一条新PIT表项,即将兴趣包的名字、进入端口号、端口数和跳数记录在PIT上.
步骤4. 对兴趣包的跳数标志位(IntHop)增加1,并将兴趣包依照FIB中记录向内容发布者转发,至此路由器完成了对这个兴趣包的处理.在处理其他兴趣包的同时,等待这个兴趣包所请求的数据包返回.
当数据包返回时,执行4个步骤:
步骤1. 路由节点接收到内容发布者发来的数据包,首先查看数据包PendingCache字段值决定当前数据包是否需要缓存,若PendingCache字段值为0,则执行步骤4;否则,PendingCache置1,并判断数据包的内容类型,然后执行步骤2.
步骤2. 根据数据包的跳数DataHop和传输路径总跳数TotalHop(即IntHop与DataHop之和),计算缓存概率:若数据包内容类型字段为00,则执行步骤4;若数据包内容类型字段为01,则采用基于网络边缘缓存策略计算缓存概率;若数据包内容类型字段为10,则采用基于网络次边缘缓存策略计算缓存概率;若数据包内容类型字段为11,则采用基于网络核心缓存策略计算缓存概率.执行步骤3.
步骤3. 根据概率计算结果决定缓存数据包,若计算得出的概率值P大于预先设置的门限概率值[13],则缓存数据包;否则不进行任何操作.执行步骤4.
步骤4. 对数据包的DataHop增加1,按照路由器默认流程将数据包依照PIT记录的端口进行转发.
3 实验评估
为了验证本文所提方案在缓存方面的性能优势,我们在基于NS-3[28]的网络仿真平台NDNSim[29-30]上对CTJP机制进行模拟实现,选取了LCE,ProbCache,Betw,HPC典型的缓存策略作为参照对象,并从以下方面进行性能比较,包括平均请求时延、缓存命中率以及额外开销.
3.1 仿真环境设置
所有仿真作业在本地计算机上执行,其运行环境如下:CPU Intel Core i7,主频3.4 GHz,内存16 GB,硬盘1 TB,操作系统内核Ubuntu 14.04(64 b),NDNSim版本1.0.实验拓扑是参照AS-3967真实且复杂的网络拓扑,链路带宽、链路时延、路由度量等参数都是基于Rocketfuel的追踪结果[31-32].该拓扑由279个节点组成,其中255个路由器,20个用户,4个源服务器,负责4种业务内容的产生.
为了模拟不同的业务请求,分别设置动态类、实时类、大数据类、小数据类对应的内容前缀名为“blockchain.com”“skype.com”“youtube.com”“google.com”,后缀为随机数.假设用户请求内容流行度服从参数α=0.8[33]的Zipf分布,每个内容大小为1 024 B,内容个数为200,内容序号以1~200排序.每个路由器具有相同的缓存空间,可容纳内容数量500,缓存初始时不存储任何内容,采用NDN默认的缓存替换算法,即最近最少使用策略LRU.表1列出了各项模拟参数,仿真运行时长600 s, Interest包请求产生的平均速率服从参数10个/s的泊松分布.为了方便比较,ProbCache机制中每个路由器以0.2的概率缓存内容.

Table 1 Simulation Parameters Setting
3.2 性能评价指标
针对路由器、用户、服务器,实验引入3个指标评估缓存的性能,即平均请求时延、缓存命中率和额外开销.平均请求时延是从用户发出请求兴趣包到获得数据包的平均等待时间,单位为ms,该值用来衡量用户体验好坏.缓存命中率是指在路由器命中的兴趣包数目与兴趣包总数的比值,能反映网络化缓存(路由器)为源服务器分担的压力.额外开销在整个通信过程中可细分为控制开销和传输开销2部分,用于比较各种机制带来的开销情况.
3.3 实验结果分析
3.3.1 平均请求时延
我们通过平均请求时延分析CTJP机制的传输效率.图8显示了CTJP机制与对比方案的用户请求时延,采样时间周期2 s.对于动态类型内容,如图8(a)所示,CTJP机制略小于LCE,请求动态类型内容的兴趣包需要转发至内容发布者才能得到响应,而CTJP机制对动态类型内容不进行存储操作,同时节省缓存空间.对于实时类型内容,如图8(b)所示,CTJP机制明显小于HPC,由于CTJP机制采用网络边缘概率缓存,使得实时类型内容大概率分布在网络边缘侧,同时避免相同内容的重复冗余存储,增大就近响应率和缓存利用率.对于大数据内容,如图8(c)所示,CTJP机制采用网络次边缘概率缓存,使得大数据类型内容大概率分布在网络次边缘,并减少相同内容的重复冗余存储.对于小数据内容,如图8(d)所示,CTJP机制与LCE持平,但波动起伏较小,由于CTJP机制采用网络核心概率缓存,使得小数据类型内容大概率分布在网络核心,同时避免占用网络边缘稀缺资源而引发高频的替换.
3.3.2 缓存命中率
图9显示CTJP机制中某条传输路径节点的缓存命中率情况,其统计时间为500 s.在实时类、大数据类、小数据类的缓存决策中,分别采用网络边缘递增概率缓存、网络次边缘递增递减概率缓存、网络核心递减概率缓存.针对不同内容特征,用户与内容存储位置的距离有所不同,为提升整个缓存系统的整体利用率.图10给出了各个方案的平均缓存命中率的对比,CTJP机制的命中率为31.1%,明显高于其他方案.
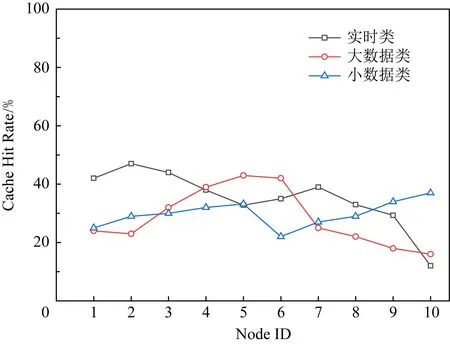
Fig. 9 The cache hit rate of on-path node图9 沿途路径节点的缓存命中率
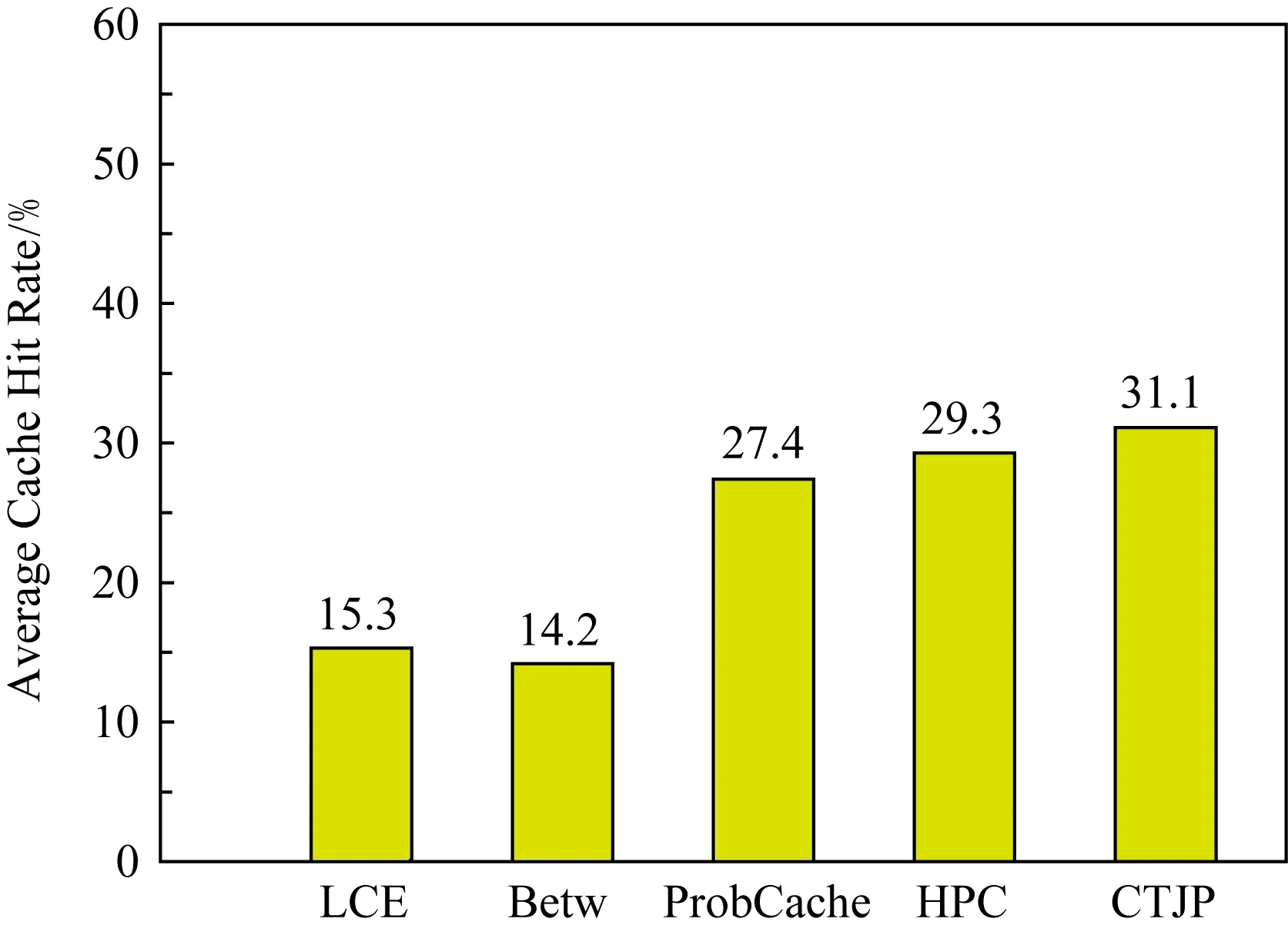
Fig. 10 The average cache hit rate图10 平均缓存命中率
3.3.3 额外开销
CTJP机制为了提供内容差异化的缓存服务,在NDN原始的兴趣包和数据包中增大了额外的控制字段IntHop(8 b),PendingCache(1 b),ContentType(2 b),DataHop(8 b),以匹配不同的内容缓存服务.控制开销定义为控制字段与传输跳数的乘积.假设一次传输跳数为n,则带来的额外开销是O(3n)字节的存储开销.内容传输开销为兴趣包请求过程中,请求包和数据包分别与其传输距离的乘积之和.假设一次完整的的请求响应,经过传输跳数n到达内容发布者,所需的传输开销为O(n+2n).因此,在最坏情况下,CTJP机制所需的控制开销,传输开销与传输跳数相关,而且成线性相关,开销较小.
4 相关讨论
CTJP机制不仅适用于NDN网络环境,还适用于所有基于网络化缓存的未来网络架构,但是需要服务提供商(内容发布者)支持对内容业务进行分类.
CTJP机制根据业务特征划分内容种类,并结合非连续缓存策略,对待不同内容实行差异化缓存,从而达到降低数据冗余,提高缓存命中率,减少用户请求时延.其优势具体体现在3个方面:
1) 在动态类方面,采用无缓存策略,避免动态类型内容无效占用缓存空间,降低数据冗余.
2) 在实时类方面,结合路由跳数和请求热度设计网络边缘概率缓存,使得用户就近访问实时内容,减少用户请求时延.与HPC机制相比,CTJP机制还引入请求热度因素,对于热度较高的请求,更有可能缓存在网络边缘,减少用户请求时延.
3) 在大数据类和小数据类方面,考虑到该内容对时延要求不高,设计网络次边缘和网络核心概率缓存策略,避免占用网络边缘稀缺资源而引发高频的替换,尽管实验结果显示CTJP机制在这些内容请求响应时延表现不是最好,但不影响总体命中率.
5 总结与展望
本文提出基于内容类型的隔跳概率缓存方法,采用隔跳待定缓存策略,减少数据缓存冗余;定义内容类型,并针对不同内容提供差异化缓存服务,进一步降低冗余,同时提高用户获取内容的效率,实验结果表明该方案的有效性.后续研究主要完善CTJP机制设计思想,在实际平台上实现方案.
