基于AI芯片加速的卷积神经网络的车辆检测算法
2021-06-03张畅陶青川
张畅,陶青川
(四川大学电子信息学院,成都610065)
0 引言
随着目前社会经济快速发展,私家车的拥有量愈来愈多,城市的交通管理面临着一个严峻的挑战。城市的十字路口随着城市的建设越来越多,十字路口红绿灯时间的设置对通行的效率显得尤为重要,传统的红绿灯时间设置主要通过前端设备(路口监控)上传视频资料到中心端,然后通过人工去统计单位时间内的车流量从而为红绿灯时间设置提供依据。但是随着城市的高度发展,一个路口不同时间段车流量可能会发生较大变化,所以需要在不同时间段对红绿灯时间控制进行调整,如果还采用传统的人工分析,不仅成本巨大且信息分析不及时,无法达到最大的通行效率。
在智能视频监控系统中,车辆检测是一个很重要的应用模块。车辆检测由于它的大小、颜色、外形有一定的特点。传统的目标检测方法中,Paul Viola等人提出了级联分类器[1]第一次使得目标检成为现实。N.Dalal等人提出的方向梯度直方图(HOG)[2]用于检测;P.Felzenszwalb提出的基于可变部件的模型(DPM)[3]实现了级联结构并且在不牺牲任何精度的情况下实现了超过10倍的加速度。这些传统方法在应用过程中都存在准确率低并且鲁棒性差的问题。近几年,深度学习的兴起使目标检测进入了一个新的阶段。基于深度学习的目标检测主要分为两种:基于候选区域方法和基于回归方法。R.Girshick等人提出R-CNN(Region-CNN)[4]检测方法,在精度上有了大幅提高,但存在大量重叠的冗余特征计算,导致检测速度极慢。后来K.He等人提出空间金字塔池化网络(SPPNET)[5]速度是RCNN的20多倍,并且没有精度损失,但是训练是多阶段的以及SPPNET只对其全连接层进行微调,忽略了之前的所有层。S.Ren等人提出的Fast R-CNN[6]以及后续改进的Faster R-CNN[7]是第一个端到端,并且也是第一个接近实时的深度学习检测器。2016年,Liu Wei等人提出了基于回归的检测方法SSD(Single-Shot Multibox Detector)[8],去掉了区域推荐和重采样等步骤,仅在单个步骤完成预测,显著提升了检测速度。虽然SSD、YOLO基于回归方法[9]的深度学习目标检测在性能上已经较之前的有很大提升,但对于计算力有限的嵌入式设备中,不能达到预期的检测效果。
为了解决上述问题,本文提出的一种AI芯片加速计算的卷积神经网络应用在嵌入式设备,将中心端分析的工作移植到了前端设备中,给中心端减轻计算压力。本文网络在应用基于回归方法的SSD目标检测方法上,根据AI芯片的特性针对特定的应用场景对网络模型进行重新设计,计算速度有明显提升,大大降低时间成本,能够满足红绿灯路口下的实时车辆检测以及车流量统计需求。
1 相关知识
在深度习技术突飞猛进的时候,AI(Artificial Intelligence,人工智能)出现更是加快了人们对深度学习技术应用到实际场景中。深度学习的网络模型往往在效果和耗时上难以达到一个动态平衡状态。网络模型较为复杂,效果理论上要较好一点,但是计算耗时也会成倍数级的增加。在实际应用场景下,成本是一个很大的制约因素,在效果和成本中达到一个动态的平衡显得尤其重要,所以AI芯片有着广阔的应用前景。AI芯片一般是用来加速神经网络计算,减小模型对平台计算力的依赖。AI芯片训练总体分为两个步骤,首先训练普通浮点型数据,然后在浮点型的基础上进行量化操作。AI芯片在训练量化后,精度会比浮点型有所下降,这种误差在大多数应用场景都是可以被接受。
当前已有多家公司推出各自的芯片,华为的昇腾系列;英伟达的TX、TK系列;英特尔的Movidius神经计算棒,等等。但是考虑到经济成本问题,不太适应在中小型项目中使用,所以本文采用的AI芯片是Gyrfalcon Technology公司推出的第二款AI芯片。
本文中采用的芯片是Gyrfalcon Technology公司自研APiM架构(存储和计算融合一体的本地并行AI运算),节省了数据搬运环节的耗时间,并且解决了数据搬运强的难题,释放高密度计算原力。其中芯片共有28000个并行神经计算核,180mW功耗下基于VGG、ResNet18模型每秒处理图片167张,兼容CNN、RNN等常见深度神经网络的模型训练及推理。同时支持标准的开源框架,软件开发包SDK提供一站式的开发套件,可以满足视觉、语音和声纹等人工智能应用需求。
2 AI芯片加速的卷积神经网络算法
像一些传统的目标检测算法,例如HOG+SVM均存在算法准确率低、计算量比较大、权值参数过多等弊端,所以不适用一些准确率要求高并且低成本化的应用场景;像一些后来居上的优秀的深度学习算法,例如SSD、YOLO、MobileNet-SSD等虽然在准确率上基本能满足场景要求,但是不能够有效移植到低成本的嵌入式平台上,满足实际需求。因此,本文利用的AI芯片加速计算的特性,重新设计网络,能够有效的加速计算,降低时间成本,并且在可接受准确率变化范围内,明显提高检测速度,使人工智能更好地应用到实际生活中。
2.1 预测尺寸的选取
SSD采用的多尺度预测模型,所以特征图的大小能够决定每个特征点的感受野范围,大特征图对应着小目标的位置和类别的预测,小特征图对应着大目标的位置和类别的预测。因此,本文针对在十字路口红绿灯特定应用场景下,以及芯片的特性,在沿用SSD网络模型的基础上采用了7×7、5×5、3×3、1×1四种不同尺寸特征图作为目标检测与识别分支网络的输入,在能达到预期效果的基础上尽量减小计算,计算目标的位置信息和类别信息。
2.2 AI芯片网络算法模型设计
由于本文中使用的AI芯片的硬件特性,本文基于SSD网络模型进行适应性的修改,在设计的网络算法模型中,AI芯片是计算输入224×224×3到输出7×7×512的VGG模型块,剩余部分由嵌入式平台的CPU计算,最后设计的网络算法如图1所示。
设计模型是基于SSD针对AI芯片做的部分改进,首先为了适应芯片特性,将输入大小调整为224×224×3,经过AI芯片计算部署的部分(VGG)后,输出7×7×512的定点数据,然后由嵌入式平台CPU继续完成后续的神经网络部分的计算,其中从Pool5输出后,本文的后续改进之处,主要是将原来Conv6、Conv7由1024通道数改为128通道数,后面的卷积主要是为了在精度在可接受范围内下降的情况下减小参数计算量换取更快的速度。并且将池化下采样(Pooling)变为设置卷积步长stride为2来达到同样的效果。由于嵌入式平台计算力有限,为了满足实时要求,必须得减小参数,在大量的实验数据条件下,本文最终调整为后续的卷积核个数均降为原来的1/2,可以达到预期的效果。
3 实验与分析
本文为了验证AI芯片加速的实际效果,主要是针对用户提出的红绿灯十字路口车流量统计的应用场景,与传统算法和经典的深度学习算法做两个方面的对比:准确率和计算耗时。

图1 本文网络结构图
本实验所使用的平台包括本地计算机以及实际应用的前端嵌入式开发板,其基本配置如下:
本地用于训练和测试的计算机硬件配置和开发环境:CPU为Intel Core i5-7400,频率为3.0GHz;内存8GB;GPU为NVIDIA GeForce GTX1080 Ti,显 存11GB;操作系统为Ubuntu 16.04;开发环境为Caffe-1.0,Python2.7,OpenCV3.4.3,AI芯片MDK。
前端嵌入式开发板硬件配置和开发环境:主板AIO-3399J;芯片RK3399;处理器为ARM Cortex-A72(双核)及Cortex-A53(四核)主频2.0GHz,内存2GB;操作系统为Ubuntu 18.04;开发环境为Python 2.7,OpenCV3.4.3,AI芯片SDK。
3.1 AI芯片训练及部署过程
本文中训练过程都是基于Caffe-1.0框架训练网络模型来进行训练的,AI芯片有相应的SDK、MDK包,其中SDK主要是AI芯片自己支持的量化训练计算层;MDK是在量化模型训练完成后,对芯片进行量化模型转换,以实际部署芯片在各种平台上的计算。训练AI芯片的模型需要重新编译Caffe,主要是将AI芯片模型的特有的量化计算层融合到Caffe中,以获取在训练过程中的对量化计算的支持。训练AI模型主要分为4个步骤:①训练浮点模型,选取浮点模型中在测试集中达到最好的一个模型;②训练量化模型,将①中的浮点型模型作为②中的预训练模型,继续进行量化训练,最终选取最合适的一个量化模型;在步骤②中,具体包括量化卷积训练和量化激活训练步骤,以及模拟上芯片的步骤,具体的训练步骤如图2所示。

图2 训练步骤图
在训练完成后,模型转换成功,在前端实际部署芯片的时候计算流程图如图3所示,其中由芯片计算的VGG部分,芯片输出7×7×512定点数据,剩下由前端设备CPU继续完成计算,计算的结果由前端设备上传中心端汇总。
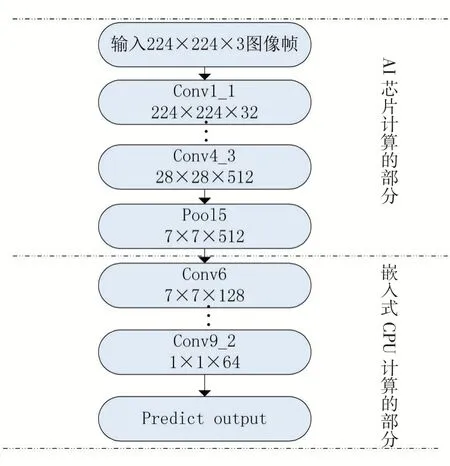
图3 前端计算图
3.2 车辆检测模型的评价标准
本文中使用衡量传统深度学习模型较多的两个指标即误检率(Miss Rate,MR)与平均漏检率(False Positive Per Image,FPPI)作为评判指标,对本文中的网络模型和典型的深度学习模型进行对比验证。其中MR、FPPI越低,表明网络框架性能更优,漏检率和平均误检率的具体计算公式分别如下:
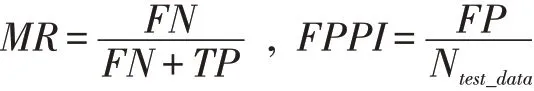
其中:FN(False Negative)表示实际为车辆,被判定为非车辆的个数;TP(True Positive)表示实际为车辆,被判定为车辆的个数;FP(False Positive)表示实际非车辆,被判定为车辆的个数;N test_data表示测试集图片的张数。
3.3 实验结果与分析
在模型训练过程中,部分训练参数具体如下:在训练AI芯片模型的时候,第一步浮点型数据模型中批大小设置为128,最大迭代步长设置为100000。学习率设置为0.01,权重衰减系数设置为0.001。后面三步训练量化模型时候,由于量化模型计算较慢,占显存较浮点型高,所以批大小设置为64,最大迭代步长不变。学习率设置为0.001,后面量化是在第一步的基础上进行微调,寻找局部最优解,权重筛减系数设置为0.001。
本文提出的网络旨在为了解决客户提出的如何实时统计十字路口红路灯下车流量问题,所以训练数据集的选取主要是包括VOC数据集中的所有车辆数据,以及3D-Car-Instance数据集(主要是行车记录仪视角拍摄的路面车辆信息)合计30000张数据集。训练完毕后,在用户提供的十字路口数据上进行测试和比对以核对预期效果。图4是本文中的AI芯片加速的网络结构计算路口车辆检测情况。
图5 是AI芯片在嵌入式开发板上加速计算的实际运行图,AI芯片以USB的形式直接与开发板相连,部署较为简单,在实际场景部署时,只需将开发板与红路灯路口摄像机绑定,并且此款RK3399开发板厂商提供的数据表明,可以同时支持8路视频流计算,计算结果通过开发板传至中心端即可。
表1 是各个模型的车辆检测速度对比。由于AI芯片上计算的模型参数和工作原理与普通的算法不一致,所以不进行参数量对比。其中具体的耗时为AI计算的部分耗时6ms,后续由CPU计算的部分耗时29ms。从表1中得出,本文提出的基于AI芯片加速计算的卷积神经网络有明显的速度优势,完全能够满足在嵌入式设备中的实时计算的要求。
表2 为各个模型在测试数据集上的MR和FPPI的数据结果,从表2中可以得出,传统算法的MR和FPPI偏高,表明在测试集上传统算法的漏检率和误检测率比较高。而经典深度学习算法例如YOLO、SSD、Mobile-SSD等在测试数据集上MR和FPPI整体较本文提出的网络偏低,表明本文提出的网络准备率是有所下降,但是综合表1、2来看,本文提出的网络优势较为明显,在十字路口检测车流量应用场景完全能够满足需求。

图5 实际运行计算场景图

表1 车辆检测速度对比

图4 本文网络检测效果图

表2 车辆检测率对比
4 结语
针对传统算法对于目标检测漏检率比较高且计算速度较慢,基于深度学习的传统算法模型计算量较大,移植到嵌入式平台基本不能达到预期的效果。本文提出的这种AI芯片加速的卷积神经网络模型在可接受范围内有一定的精度损失,获取了更快的速度,在特定的应用场景下相比一般的算法有明显的优势。嵌入式平台配合AI芯片加速,在实验室场景下验证可以达到预期效果,但是目前停留在实验室验证阶段,算法性能有待实际验证,下一步的目标就是重点往实际场景应用来验证方案的有效性。
