基于CatBoost集成算法的用户购买预测研究
2021-06-03盛钟松
盛钟松
(四川大学计算机学院,成都610065)
0 引言
电商平台的发展逐渐影响着人们的消费方式,随着互联网技术的发展,网上购物已经成为新时代的一种趋势和常态,电商作为一种服务为广大群众提供了方便和舒适的购物体验。近年来,各大电商平台的规模也越做越大,国内电商市场也逐渐被淘宝、京东和拼多多所占领,电商平台要在如此激烈的竞争中保持前行,必须要对用户群体有足够的了解。不同的用户在电商平台的各种行为操作为平台带来了海量的数据,如何从海量数据中分析出用户的兴趣爱好,为用户推荐其最可能感兴趣的商品,提高平台的交易额以及产品知名度,成为了平台亟需解决的难题。当然,数据挖掘技术的日益成熟为用户购买预测问题提供了解决方案。
1 相关工作
基于用户在各大电商平台的行为数据,预测用户未来是否对目标商品具有购买意向,可以建模成一个二分类问题。针对二分类问题,学术界提出了多种不同的机器学习分类算法。如何将这些机器学习算法应用到电商用户购买预测问题中,已经逐渐成为学术界的一大研究热点。祝歆等人[1]基于淘宝电商平台的用户历史行为数据,通过训练多个不同的基类学习器,再对不同的基类学习器进行融合,实验表明融合模型的预测准确率要优于其他个体模型。葛绍林等人[2]对深度深林算法做出改进,对用户购买做出预测,实验表明该模型的训练时间和训练效果都要优于其他个体模型。Liu等人[3]在特征工程方面生成了一千多个新特征,建立预测模型,模型证实了预测用户双11之后是否在商家购买商品的有效性。Liu[4]通过使用支持向量机模型对用户网上购买做出预测,在电商产品的推荐准确率和转化率有了大幅的提升。胡晓丽等人[5]在深度学习领域对用户购买行为预测做出研究,利用神经网络对特征自动学习和选取的特性,建立CNN-LSTM组合神经网络模型,该模型的F1值要比个体学习器平均提高了7%~11%。
对于大部分的分类和回归问题而言,其主要工作分为两部分:特征工程和搭建模型。基于用户庞大的历史行为数据,构建出可以影响用户购买的特征,要求对统计学知识和电子商务领域的业务知识的足够掌握和熟悉。本文在特征工程方面分别从用户和商品的角度,挖掘出大量的用户商品交互特征;在模型搭建方面,主要采用了集成学习方法中的CatBoost[6]模型用于预测。由于生成的特征中大部分都是类别特征,并且CatBoost模型会自动对类别特征做出处理,因此将Cat-Boost模型应用到用户购买预测任务中,整体上有一定的优势。
2 方法
2.1 特征工程
特征工程工作往往决定了一个预测模型的性能好坏,通过模型调参对预测模型效果整体的提高是有限的,如果能够从原始数据集中挖掘出有效的特征用于模型的训练,通常可以大幅度提高预测的准确率。而特征工程的目的就是更加详细和更加全面地描述目标问题,为机器学习算法提供有效的训练集和测试集。预测模型框架的有效性很大程度上取绝于构建的特征是否正确全面地描述了目标任务。然而,特征的构建与实际的问题密切现关,对模型训练有利的特征往往需要建立在对专业知识和实际问题的理解和掌握的基础之上。
本文主要从用户基本特征、商品特征、用户-商品交互特征和评价特征四个方面进行特征工程的工作,构建的四类特征如表1所示,主要从用户和商品的角度出发,对特征进行构建,通过对原始数据集的探索性分析,发现用户在购买商品前的一些行为动作往往能影响用户的购买判断,因此本文以用户购买预测日为界线,生成了离预测日7天、15天和1个月这3个时间窗口,再基于这3个时间窗口计算用户各类行为的购买转化率,作为用户-商品的交互特征。此外,还对用户和商品分别生成了大量的统计类特征,如用户的点击数、浏览数,等等,作为预测模型的用户特征和商品特征。

表1 构建的特征表
2.2 基于CatBoost的用户购买预测框架
集成学习算法通过迭代的方式训练多个弱分类器,每一次迭代的过程都训练出一棵决策树来拟合预测结果和实际结果的误差,最终通过设置的决策树数量或者误差阈值来决定是否停止迭代。集成学习算法的模型表示如公式(1)所示,F表示生成的最终模型,x为输入样本集,f为每次迭代生成的分类回归树,ω为分类回归数的参数,α表示f在最终模型的权重。

目前主流的集成学习算法有GBDT、XGBoost和LightGBM等,集成学习的主要思想就是建立多个弱分类器,赋予每个弱分类器不同的权重,最终结合得到一个新的预测模型。
CatBoost模型是Yandex公司提出的一种基于传统的梯度提升树改进的集成算法,该算法在处理离散型特征时并不采用传统的独热编码的方式,而是将离散型变量分配到有限的簇中,再对这有限的簇采用独热编码的方式进行处理。其次在模型训练的过程中,模型会自动对一些离散特征进行组合,生成内部特征作为模型的训练,并且模型允许采用GPU训练数据,极大地提高了训练速度,使得模型能够用于快速预测。为了解决传统梯度提升树算法训练过程导致地过拟合问题,CatBoost模型采用排序提升算法来解决由于梯度偏差造成的过拟合问题。图1是基于CatBoost建模的整体框架图。

图1 模型框架图
3 实验
3.1 数据
本文实验采用的数据集来自2018年京东“高潜用户购买预测”算法比赛,京东作为国内前二的电商购物平台,积累了大量的用户消费数据。本次比赛主要提供的数据大小为2.15G左右,包含用户信息表、商品信息表、用户在2016-02-01到2016-04-15的行为数据和商品评论数据表,具体统计信息如表2所示。其中用户表和商品表主要描述用户和商品的基本信息,用户行为表中主要包括购买、加入购物车、浏览和点击等行为动作,商品评论表主要描述了用户对商品的评论信息。预测的目标是用户在2016-4-16到2016-04-20这5天内对给定商品是否购买做出预测。

表2 数据统计表
3.2 评价指标
机器学习分类任务的模型评估指标有很多,例如准确率、查全率、AUC值和F1评分等,不同的分类任务,采用的评估指标也有所不同。有些分类任务可能并不关心模型整体的预测准确率,而更加看重预测正确的样本数有多少,即采用查全率作为评估模型好坏的标准。本文采用的评估指标为比赛定义的F1评分,综合考虑了模型的准确率和查全率,具体表示如公式(2)所示,R和P分别表示模型的准确率和查全率。

TP表示预测正确的正样本数,即预测为购买实际也购买的用户-商品数,FP表示预测错误的负样本数,即预测为购买但实际不购买的样本数,FN为预测错误的正样本数,即实际购买但是预测为不购买的样本数。
3.3 实验对比
为了对比CatBoost模型的预测效果,本文在集成学习算法模型中,基于相同的训练特征和数据训练了XGBoost模型和Light GBM模型,在线性分类模型中,训练了生成了SVM模型,最终在相同的测试集上对这四个模型的预测效果做出对比,实验结果如表3所示,可以看出CatBoost模型的F1值要远高于其他个体预测模型,并且模型训练时间也比Light GBM和XG Boost的训练时间要短,表明了CatBoost模型应用到用户购买预测问题上可以取得比其他模型更好的预测效果。

表3 各模型实验对比
为了证明本文特征工程的有效性,分别基于两个不同的特征子集组成的训练样本,对以上4个模型进行训练,其中一个特征子集包含了生成的用户-商品交互类特征,另一个特征子集不包含用户-商品交互类特征,实验对例如表4所示,通过对比可以发现,引入了用户-商品交互特征训练的模型,其预测效果比没有采用此类特征的模型明显要好,说明用户-商品的行为特征是影响用户购买的一类重要特征,此类特征在一定程度上能够反映出用户的兴趣爱好。
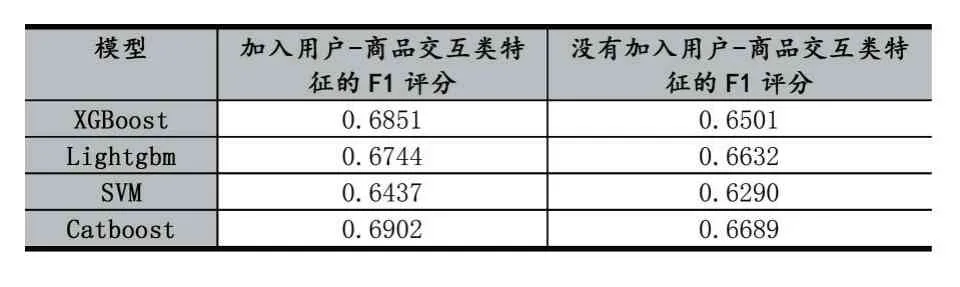
表4 是否引入用户-商品交互特征的实验对比
4 结语
本文主要介绍了应用CatBoost模型解决电商用户购买预测问题,从最终的实验结果上可以看出,Cat-Boost模型相比于其他模型要具有更好的准确率和更强的鲁棒性。本文在特征工程方面,通过数据分析的方法,首先对原始数据中存在的噪声做了一定的去噪处理,重点在用户对商品的历史行为动作这一方面生成了大量的用户商品交互类特征,形成二者之间的联系,实验证明了本文特征工程的有效性,对模型的预测有一定的提升,也间接反映了在购买预测日之前,用户的一些行为动作,例如浏览商品、点击商品等动作可能暗示着用户在近期的购买意向。CatBoost模型在F1评分上的表现要优于其他分类器,说明了CatBoost模型在用户购买预测研究方面具有很好的应用前景,能帮助电商平台为用户精准推荐商品,提高平台的交易率。
