属性约束的人脸素描-照片转换与识别
2021-06-03黄婕赵启军吕泽均
黄婕,赵启军,2,吕泽均
(1.四川大学计算机学院,成都610065;2.西藏大学信息科学技术学院,拉萨850000)
0 引言
人脸素描图像识别在很多刑侦案件中起着十分重大的作用。在一些案件中,往往只有一些目击证人的证词以及专业人士根据证词所画的嫌疑人人像素描作为参考,如何根据这些有限的信息追捕嫌疑人极具挑战。
近年来,人脸识别技术飞速发展,基于照片的人脸识别已经可以达到很高精度,然而基于素描的人脸识别精度依然偏低。素描人脸识别面临的挑战主要有:①信息缺失,素描图像只能刻画人物大致的特点,无法反映人脸丰富的纹理信息,而在人脸识别中,纹理提供了非常重要的特征信息;②主观性,不同画师对目击证词会有不同理解,而且画风也可能存在差异,导致画出来的图像具有一定主观性。
现有素描人脸识别方法主要分为两大类。第一类是通过设计特征提取器[1,13,14,18,20,22],提取有利于人脸识别的素描特征,直接对素描和照片进行跨域识别。第二类是把不同风格域的图像转换到同一域中进行识别。有一部分学者提出将照片转换成素描[5,16],在素描域进行识别;另一部分学者提出将素描转换成照片,在照片域进行识别。传统第二类方法主要对素描和照片分别进行建模[16,21],然后根据模型特点进行转换。近年来,对抗生成网络受到广泛关注。有人提出DA-GAN[9]生成照片,但是只能生成一些低精度的照片;又有学者[2]在图像翻译网络pix2pix[8]的基础上,改进了网络结构,提出一种素描转照片的方法;Shikang Yu等人[19]则在现有环形生成对抗网络的基础上,增加一些损失函数,实现素描转照片。

图1 不同方法将素描转换成照片的效果
尽管现有基于图像转换的素描人脸识别方法取得了不错的准确率,但是依然存在一些局限性。①现有方法在转换图像域后一般只在素描域或照片域进行识别;②现有方法在图像转换过程中仅考虑图像信息,而忽略了人脸属性信息(如目击证人对嫌疑人面部特征的描述)。
为了解决这些问题,本文提出了属性约束的人脸素描-照片转换和识别方法。由于素描图像的信息缺失和主观性,本文将人脸属性作为额外的约束信息引入人脸素描与照片之间的转换过程。属性信息对于素描人脸识别的作用在文献[7]中已经得到了证明。文献[21]中方法是用属性引导特征提取器提取素描图像特征,而本文是用属性引导素描照片相互转换。此外,为了更充分利用素描和照片图像中的信息,本文提出基于互转换生成的素描和照片在素描和照片域中同时进行人脸比对,再融合两个域中的比对结果以提高人脸识别准确率。
具体地,本文在环形生成对抗网络[23](CycleGAN)的基础上,训练一对适用于素描识别的素描照片互转换器,其中生成器为U-Net结构[11],判别器为Patch-GAN结构。图1对比了本文方法、传统CycleGAN和pix2pix方法生成的照片。本文的创新性主要体现在以下两方面。
(1)本文提出将人脸属性作为约束条件与素描照片一起输入生成器,以控制生成器生成更真实的照片。
(2)本文提出在进行素描人脸识别时,融合照片域和素描域中的比对结果,提高人脸识别准确率。
1 属性约束的人脸素描-照片转换与识别方法
本文提出的素描人脸识别流程如图2所示,主要包括以下几个步骤。第一步,将输入人脸素描图像转换成照片,与背景人脸库中的人脸进行对比,得到两者在照片域中的相似度;第二步,将背景人脸库中的照片全部转换为素描图像(此转换只需在人脸识别之前执行一次即可),再与输入素描图像进行比对,得到两者在素描域中的相似度。最后将两个域中的相似度进行融合,得到最终的比对结果。本文实验中使用了简单的取均值的融合方法。
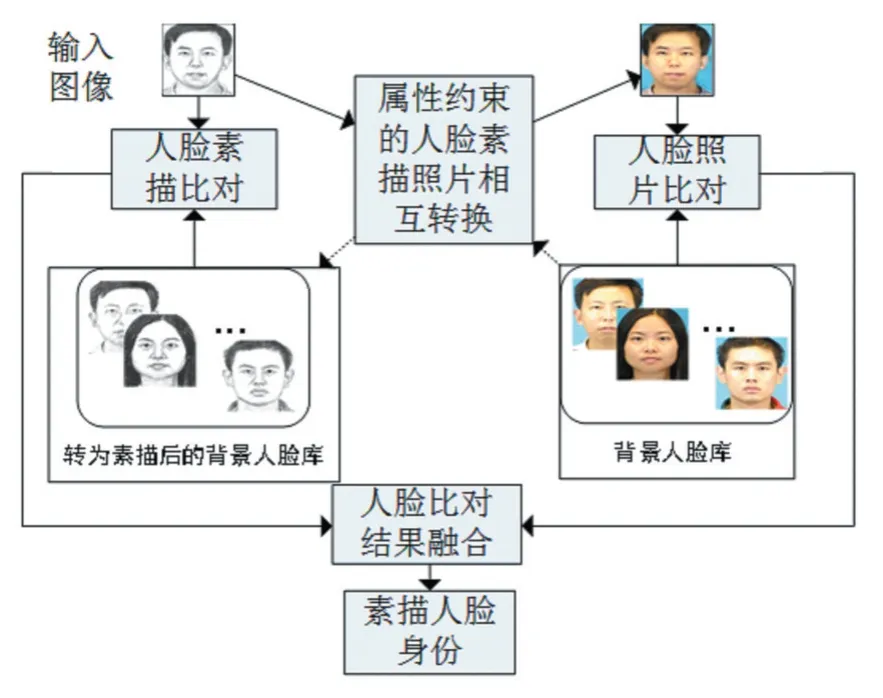
图2 本文提出的素描人脸识别流程
接下来分三部分重点介绍本文提出的属性约束的人脸素描照片转换方法:首先介绍其网络结构,其次介绍训练时使用的损失函数,最后介绍方法的实现细节。
1.1 网络结构
假设x属于素描图像域X中的一张人脸素描,y是照片图像域Y中与素描图像x对应的人脸照片,c代表的是样本x的属性。图4展示了本文提出的人脸素描与照片转换方法的网络结构。
其中生成器G将素描图像转化为真实照片,生成器F是将真实照片转化为素描图像。两个生成器均在U-Net的基础上,增加一个属性向量c作为输入,分别表示为G(x,c),F(y,c)如判别器DX用于判别其输入是否是真的素描图像,判别器DY则用于判别其输入是否是真的照片图像。这两个判别器均采用PatchGAN判别器的结构,其输出结果不是用单个值表示图像的真伪,而是用一个70×70的矩阵,其中每个值代表当前图像对应位置的图像块的真伪。相比单个值的判定结果,基于图像块的矩阵判定结果更加适用于图像的真伪判断。这两个判别器分别表示为
1.2 损失函数
损失函数主要由四部分组成:对抗损失函数,循环一致损失函数,身份损失函数,和边缘损失函数。对抗损失和循环一致损失是环形对抗生成网络中的基本损失函数,身份损失函数主要是为了控制生成器生成对应图像域的图像时能保留原始图像的身份特征,边缘损失函数主要用于控制生成器生成的图像有比较清晰的边缘。

图3 生成器G,F的网络结构
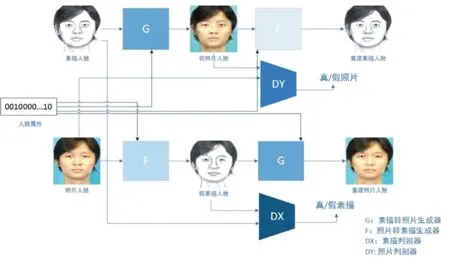
图4 本文提出的属性约束的人脸素描和照片互转换网络结构
(1)对抗损失
传统对抗生成网络要同时训练一个生成器和一个判别器,前者输入一个噪声变量,输出一个伪图片数据,后者输入一个图片,输出一个值表示该输入的真伪。理想情况下,判别器需要尽可能准确判断出数据的真伪,而生成器需要生成伪数据尽可能去欺骗判别器,这样就形成了一种对抗式的学习。在本文任务中,也同样需要这样的对抗学习。两对生成器和判别器的损失函数如下:

(2)循环一致损失
为了避免生成器F与G将所有输入都映射到同一个输出,引入循环一致损失,要求输入映射到另一个域后,再映射回原域时与输入保持一致,即:
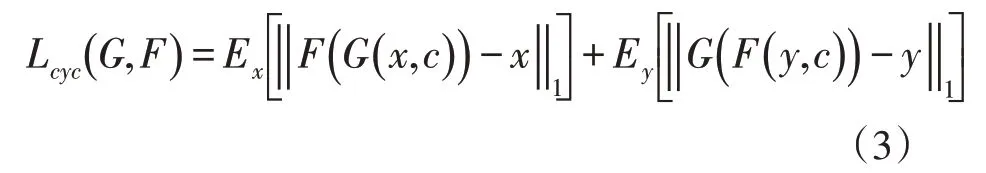
(3)身份损失
为了使转换后的图像有利于身份识别,生成器G和F必须能够保留原始图像的身份特征。因此,引入如下身份损失函数:

(4)边缘损失
为了提高生成图像的清晰度,受W.Chao[9]的方法启发,本文引入控制边缘的损失函数。该损失函数用Sobel算子S(x)提取生成图像和目标图像的边缘信息,然后计算相互间的L1距离。

本方法的总损失函数为上述损失函数的加权和,即:
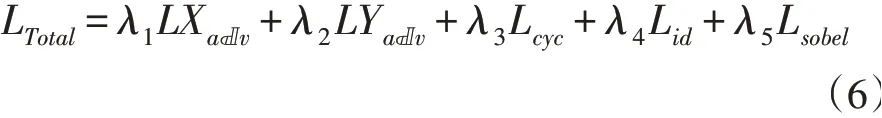
1.3 实现细节
本文基于U-Net结构实现生成器,其输入数据是128×128大小的人脸图像和该人脸属性向量。本文实验中,人脸属性向量为21维的二值向量,每一维对应一个人脸属性,其值为1时表示人脸具有此属性,值为0则表示没有此属性。本文考虑的21个属性为:"5_o_Clock_Shadow","Arched_Eyebrows","Bags_Under_Eyes","Big_Lips","Big_Nose","Bushy_Eyebrows","Chubby","Double_Chin","Eyeglasses","Goatee","High_Cheekbones","Male","Mustache","Narrow_Eyes","No_Beard","Oval_Face","Pale_Skin","Pointy_Nose","Rosy_Cheeks","Sideburns","Young"。本文的判别器则采用PatchGAN中提出的判别器结构,输入128×128大小的人脸图像,输出70×70的判断结果。
训练过程中,损失函数的权重设定为:

学习率设定为0.002。训练时,先固定判别器的参数,训练生成器,然后固定生成器的参数,训练判别器,如此交替进行,训练200个epoch。
2 实验和评估
为了证明本文方法的有效性,本文实验分别从生成的图像质量和对人脸识别准确率的提升效果这两个角度进行评估。本部分首先介绍实验所使用的数据库,然后给出图像质量评估和人脸识别实验的结果,最后介绍消融实验的结果。
2.1 数据库介绍
本文使用的数据库是CUFS[16],即CUHK人脸素描数据库,是人脸素描合成和人脸素描识别研究中广泛使用的公开数据库。本文实验使用了CUFS中的188个人的素描和照片数据,其中88个人的数据用于训练,其余100人的作为测试集。
实验中使用的人脸素描和照片图像首先按照Dlib[4]中的工具进行对齐裁剪,尔后缩放为128×128大小。而这些人脸的属性则使用[6]方法根据其照片图像得到。
2.2 图像质量评估
本实验使用以下几种图像质量评估指标:IS(Inception Score)[3]、FID[10]、PSNR、SSIM[17],对比本文方法和传统方法生成的图像。
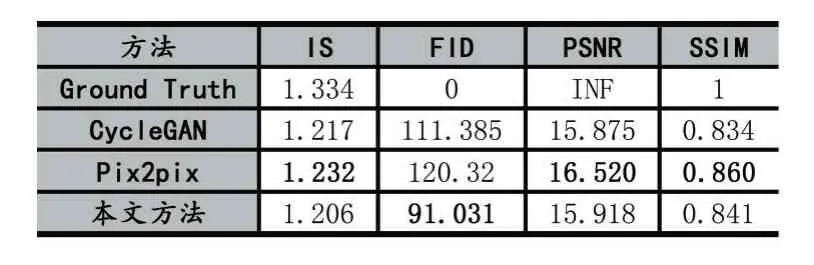
表1 图像质量评估
IS的值越接近真实(Ground Truth)图像的值越好,FID的值越接近0越好,而PSNR和SSIM的值则是越大越好。需要指出的是,这些指标绝大部分都是单纯从图像的视觉效果角度评估图像质量,而不考虑图像中的具体内容。根据表1中的结果可以看出,本文方法与现有方法相比,并不能显著改善生成图像的视觉效果。这可能是因为本文方法的主要目标是提升素描人脸识别的准确率,因此在图像转换过程中保持人脸的身份特征比图像的视觉效果更重要。下面的人脸识别实验结果证明了这一点。
2.3 人脸识别评估
人脸识别实验中,为了与最新的W.Chao[9]的方法进行对比,本文也采用Dlib[19]中的人脸识别模型。表2总结了不同方法的Rank1、Rank3和Rank5识别率。
从表2可以看出,单独在照片域上做识别,本文方法将W.Chao[9]方法的Rank1识别率提升了11%,而融合照片域和素描域的识别结果后,又进一步提升了17%。这证明了本文方法在素描人脸识别方面的优势以及融合不同域识别结果的必要性。与现有其他图像转换方法相比,本文方法对素描人脸识别准确率的提升幅度更加显著,这印证了本文方法虽然在图像视觉质量上稍差,但是更注重保留人脸身份特征,因而更有利于素描人脸识别。
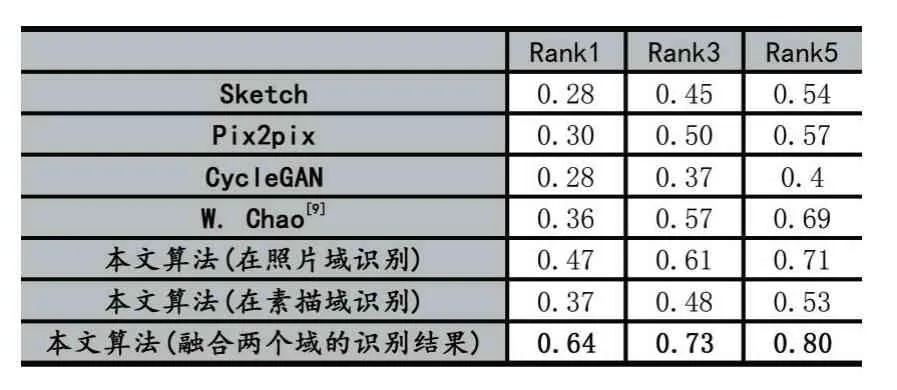
表2 不同方法的识别效果
2.4 消融实验
本实验评估引入不同属性约束和边缘损失函数的效果。本实验中,为了降低复杂度,人脸比对仅在照片域进行。

表3 消融实验结果
针对属性约束的评估,实验对比了使用21个属性(见前文定义)和方法[20]提供的全部40个属性时的素描人脸识别准确率。由表3中的结果可以发现引入更多属性并不能确保更好的人脸识别效果。一般而言,能够准确刻画人脸面部特征的属性用于本文方法的属性约束更有效。
针对边缘损失函数,由表3可见,无论引入属性约束与否,边缘损失函数都能有效提升人脸识别准确率。图5展示了一些生成图像,由图可见加入了边缘损失函数后,图像边缘更加清晰,因而有利于人脸特征的提取。

图5 消融实验生成的图像效果
3 结语
针对素描人脸识别问题,本文将人脸素描与照片相互转换,并在素描域和照片域中同时进行人脸比对,最终结合两个域的识别结果确定输入素描图像中的人脸身份。为了提高生成图像的判别性,与现有方法不同,本文提出引入人脸属性信息作为额外的约束,与素描图像一起输入生成器,得到相应的照片图像。在CUFS数据库上的评估实验证明了本文方法能够显著提升素描人脸识别的准确率。
