基于卷积神经网络的图像中文OCR 识别纠错方法及系统的研究
2021-05-31杜训祥
杜训祥
中电鸿信信息科技有限公司
0 引言
OCR(Optical Character Recognition)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。即将图像中的文字进行识别,并以文本的形式返回。
OCR 技术可应用于财务票据、证件、文字资料、档案卷宗、文案等的录入和处理领域。在财务领域,将OCR 识别技术运用在财务系统中,通过OCR 技术自动提取票据要素,如金额、账号、日期、证件号等,可代替手工完成票据信息的录入;将通过OCR 技术识别的票据金额与系统中的金额进行比对,从而可替代操作人员完成财务稽核工作,使专职人员从枯燥的重复劳动中释放出来,投入到更高价值的工作中。借助OCR技术,自动提取票据影像数据,进而推动财务系统智慧化、自动化转型,从系统优化的角度来看,可有效减少人工核算工作量、减少工作差错、为系统的数据安全保驾护航;从企业发展的角度来看,可激发员工的创造性、增强企业发展能力。
但由于OCR 的识别率并无法达到百分之百,一些除错或辅助更正的功能,也成为OCR 系统中必要的一个模块。
1 传统OCR 方法存在的问题
OCR 对数字、英文字符的识别效果普遍较好,然而其对中文的识别相对效果较差,这与中文字体的复杂形状有直接关系。传统的OCR 方法,针对文字噪声少,设计高性能的特征向量,使用模版匹配、支持向量机或者浅层神经网络等得到很高的识别准确度,但当用于大量噪声或者复杂的中文文字识别时,识别效果较差。
卷积神经网络(Convolutional Neural Networks,CNN)是一种深度学习网络,通过卷积运算由浅入深提取图像不同层次的特征,利用神经网络的训练过程让整个网络自动调节卷积核的参数,从而无监督地产生最适合的分类特征,对中文这种复杂的文字,具有较好的识别效果。
2 基于VGGNet 的图像中文OCR 识别纠错系统设计方案
2.1 VGGNet 网络结构特点分析
CNN 即卷积神经网络擅长处理图像分类的问题,具有参数较少以及平移不变性的优点。VGGNet 是CNN 的一种,其网络结构如图1 所示
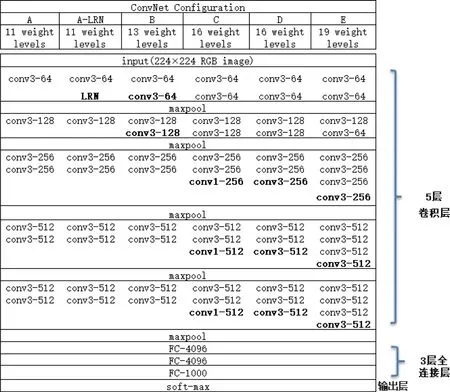
图1 VGGNet 各级网络结构
在池化核的选择方面,VGGNet 全部采用2x2 的池化核,池化层用于降维,使得VGGNet 网络模型在架构上更深更宽的同时,控制了计算量的增加规模。
VGGNet 共包含A、A-LRN、B、C、D、E 六种网络结构,因为VGG16 全程使用3x3 卷积核与2x2 池化核,其网络结构统一、简洁优美,所以本文在模型选择上选择VGG16网络模型。如图2 所示。
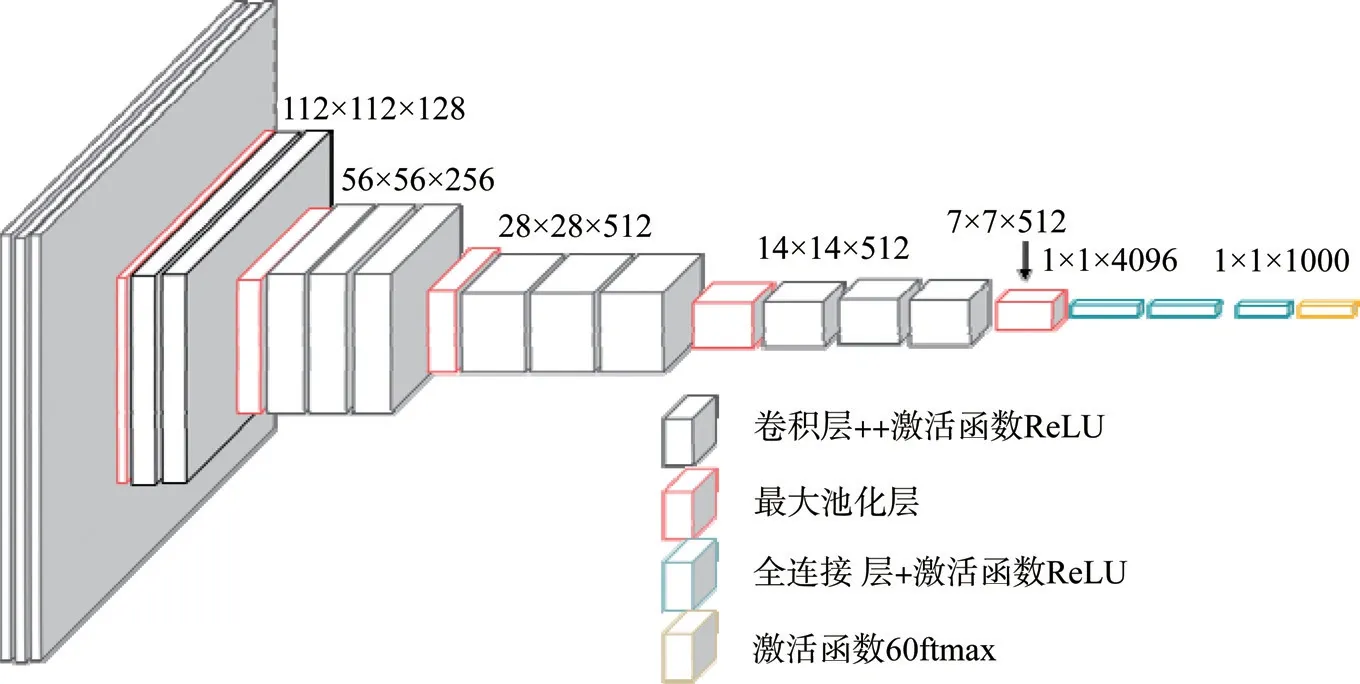
图2 VGG16 网络结构
2.2 系统整体设计思路
基于VGGNet 的图像中文OCR 识别纠错系统,首先对OCR 分析业务平台生产中间数据进行预处理,然后对预处理后的数据进行数据清洗、接着基于Tensorflow 深度学习框架,训练VGG 网络模型,最后对OCR 结果进行分析,智能纠正错误结果。
在数据清洗方面,本文设计了三步数据处理法,包括采用OCR 识别结果做初步过滤汇总、采用验证码服务进行数据清洗和通过人工核验方式进行数据清洗三个环节。
在模型训练方面,基于Tensorflow 深度学习框架,训练VGG 网络模型,建立字分类器、词分类器。
在对OCR 的识别结果进行错误分析时,对于不在正样本清单中的词语,查询词语映射表,若在映射表中查到该词语则通过映射表优化OCR 的识别结果,若其不存在词语映射表中则通过字、词分类器对OCR 的识别结果进行优化。
压实膨润土混合物自由膨胀-收缩、限制膨胀-收缩过程的特征点见表4和表5。其中, 收缩量是指膨胀稳定与收缩稳定之间体积的变化率差值。
3 中文OCR 识别纠错系统运行设计
系统运行以数据采集开始,经过数据预处理、数据清洗、模型训练等过程,最终输出模型,以来优化OCR 识别结果。系统主要提供预处理、数据清洗、模型训练和OCR 识别结果优化四个功能。
3.1 预处理
基于OCR 分析业务平台生产中间数据,对图像中识别的字、词进行积累,并建立字图像库、词语图像库。具体步骤如下
首先在OCR 识别引擎模块中,对要识别的字的局部图像进行保存,并以时间+识别结果的方式进行命名,从而建立字图像库;在OCR 字段定位模块中,对要识别的字段的词图像进行保存,并以时间+识别结果的方式进行命名,从而建立词图像库。接着开发“字词图像库汇总工具”,建立字典数据库,开发汇总服务、字典与本地库同步功能。最后开启字、词汇总服务,将识别结果相同的图汇总在同一文件夹中,如果本地库数据有所变化,点击同步按钮实现字典与本地库同步。
3.2 数据清理
使用三步数据处理法,对字、词库进行数据清洗,清除错误的数据,合并相同类别的数据。
第一步数据清洗,是针对预处理后的数据采用OCR 识别结果做第一步过滤汇总。基于现有数据量,使用字典数据库,查询样本数据量>N 的类别,做相应筛选或者增加,建立正样本类别清单,确定全部的正样本类别、建立负样本文件夹。
第二步数据清洗,是基于图像验证码服务做初步数据清洗,清除正样本中的错误数据。首先建立图像验证码服务器,服务器接受请求后输出验证码图像,并等待接受用户的验证值。设定清洗时间周期,如将时间周期设置为月,则每个月根据验证数据表或者本地日志文件,来初步清洗数据。
第三步数据清洗,是通过人工核验,完成最终的数据清洗。清洗文件夹,将不属于正样本类别的数据,移到负样本文件夹;把不属于该类别的正样本数据,移到相应类别对应的正样本文件夹,同时将字词的OCR 识别错位值与字词的真实值对应,建立常错字词映射表。通过词库更新程序,使本地图像库与字典数据库保持一致,将类型名从0 开始标注,生成标签文件。如图3 所示。
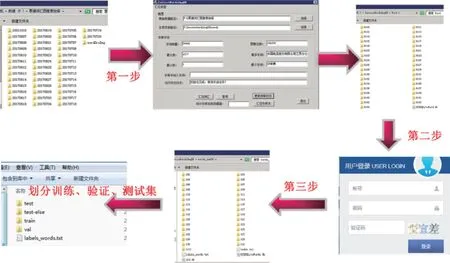
图3 三步数据处理法示意图
3.3 神经网络模型训练
基于Tensorflow 深度学习框架,训练VGGNet 网络模型,建立字分类器和词分类器。
3.4 OCR 识别结果优化
对OCR 的识别结果进行错误分析,在正样本清单中查询该识别结果字符串,如果在正样本清单中可查询到该结果字符串,则直接输出此结果;若在正样本清单中查询不到该结果字符串,则通过查询映射表的方式进行结果优化,若映射表中存在该字符串则通过映射表中对应的字符串替换该结果;若映射表中不存在该字符串,则使用字、词分类器对结果进行分类,将分类预测值和分类器设定的阈值进行比较,当预测值大于或者等于分类阈值时,使用分类结果替换原始结果,否则不做处理。如图4 所示。
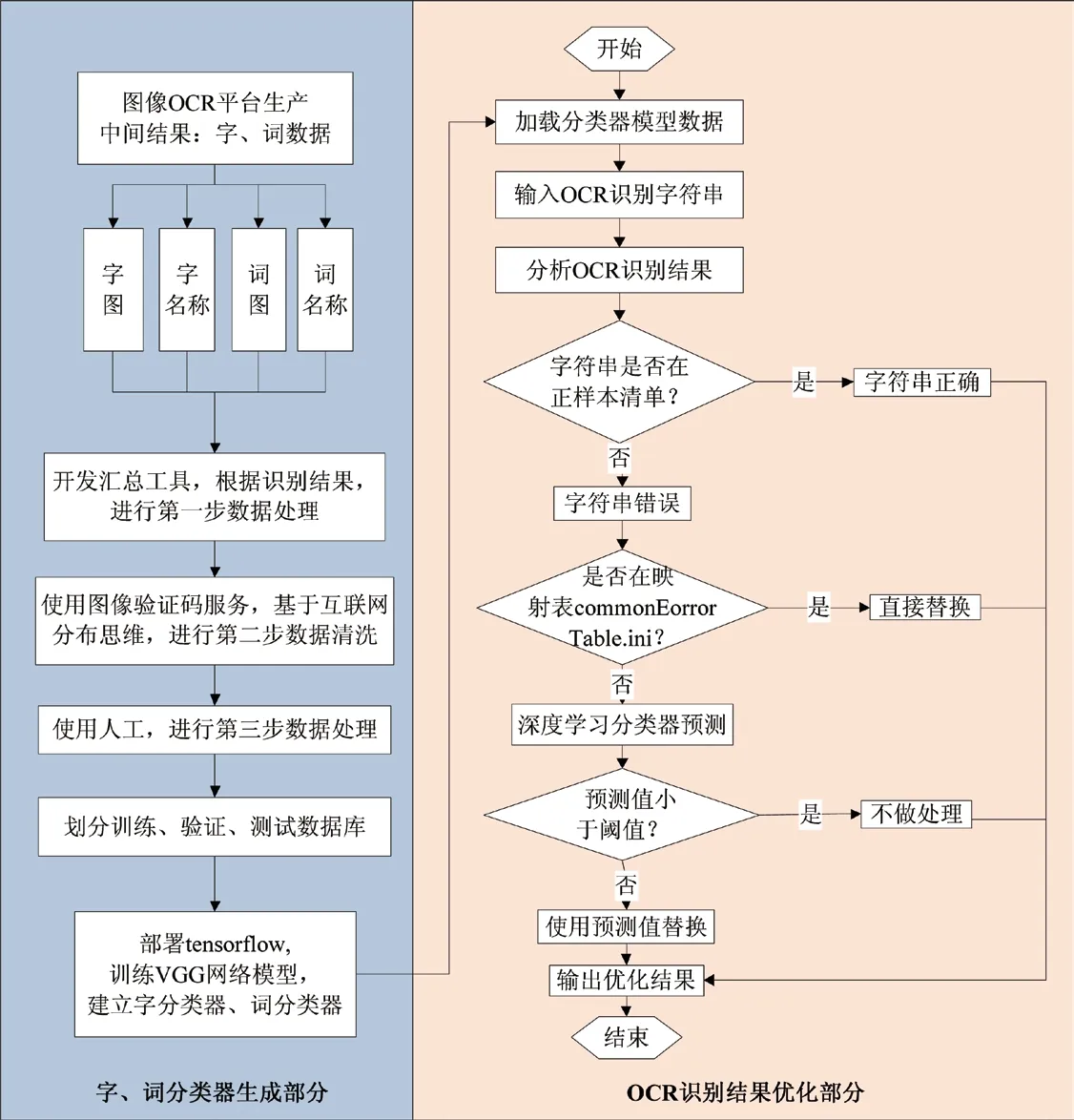
图4 OCR 识别结果智能优化流程图
4 初步成效
拿增值税发票识别结果举例,OCR 分析业务系统在改进前,由于受到票据质量影响,项目名称和购买方服务名称等容易出现识别出错情况,而其中哪怕一个文字识别出错,都将导致整个识别结果不可用。系统运行后,OCR 分析业务系统对中文词语识别准确度,在原来的基础上提高了10 个百分点,大部分识别错误的结果被纠正。对错误情况进行智能纠正,保证了OCR 识别结果的有效性,提升了数据的可用性,为后续的票据智能稽核打下坚实的数据基础。
财务部门每天有大量的票据影像,多岗位员工需对同一张票据重复稽核,不仅耗费人力,且降低了报账效率。通过图像OCR 技术实现票面信息的提取,将提取的票面信息与报账信息进行对比,可实现财务稽核工作的自动化。
此外,OCR 技术可应用于证件、文字资料、档案卷宗、文案等的录入和处理领域,如进行证件OCR,实现对身份证、驾驶证、名片等的关键信息的识别和提取。
5 结束语
本文在传统中文OCR 识别的基础上,结合深度学习方法来提高中文识别的准确度,所研究方法充分发挥了中文OCR 识别引擎的速度优势与深度学习分类器的高准确度优势,使得中文OCR 的准确度在原来的基础上提高了10 个百分点。
深度学习分类器,对数据要求很高,因此数据处理工作至关重要。对于字词数据来说,其总体数据量可以达到上亿级别,本文在数据处理方面设计了三步数据处理法,首先采用OCR 识别结果做第一步过滤汇总,然后采用验证码服务进行第二步清洗数据,最后通过人工核验完成数据清洗,本文设计的三步数据处理法使数据清洗工作量减少了50%,降低了数据清洗的成本。
