多时间尺度双流CNN与置信融合的视频动作识别
2021-05-28詹永照
陈 洁,詹永照
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
近年来,在通信技术和手机APP大发展的环境下,视频已经成为人们分享状态和表达情感的主要形式之一,网络中的视频数量呈爆发式增长,视频类型趋于多元化[1].为了能高效地检索出用户关注的视频,对网络上的海量视频进行分类和识别的技术具有愈加广阔的应用前景.
视频动作识别的流程主要包含特征提取和分类两个步骤,其中特征提取是关键.传统视频动作识别分类方法如基于标签文本的关键字匹配,在应对互联网海量视频数据及视频内容复杂度区分方面表现有待提升,而先获取HOG、Sift、LBP等局部特征描述子或基于原始视频图像帧的整体特征(颜色、边缘检测、Cabor等)的方法,又或是应用WANG M.等[2]将局部特征转换成全局特征描述,最后载入分类器的方法都不可避免手动特征提取的问题.相对于传统的方法,深度学习通过一种深层非线性网络结构[3],使用可训练的过滤器层次结构和特征池化操作,实现复杂函数逼近,能够鲁棒且自动地提取样本的复杂特征,从而能够刻画样本的丰富内在信息,使得更加容易分类或预测.其在机器人交互、人机交互、智能监控、体育视频分析等领域取得成功应用[4-5].
由于卷积神经网络在ImageNet大规模视觉识别挑战赛(ILSVRC)上表现出的卓越性能,文献[6-8]提出了将卷积神经网络(convolutional neural networks,CNN)应用于动作识别任务.然而,因为每个单独的视频帧只构成了视频故事的一小部分,当两个视频的背景极为相似时,原始的空间流很容易被愚弄.例如UCF101数据集中的FieldHockeyPenalty(曲棍球点球)和FrisbeeCatch(飞盘接住),对于这两个类别,相似的场地导致类别极易混淆.除了使用标准的CNN捕获静态语义信息外,几种最新的方法[9-11]尝试使用光流数据构成CNN 的第2个流来捕获运动信息;但是,仔细研究这些模型时,笔者发现原始光流仅接收10个连续的堆叠光流帧.因此如果在这样一个简短的视频段中有两个类似的动作,模型可能会导致混乱和错误.另外,视频中物体时序信息的时间依赖度是不同的,即不同的动作运动速度不同,造成的时间跨度不同,故而如何最大化地挖掘利用视频中隐藏的时序信息,建立更好的视频动作识别模型有待解决.
文中在双流网络的基础上引入了置信融合的策略,并且考虑到视频序列中隐藏的不同的上下文信息,提出利用CNN-LSTM网络学习并提取视频中的多时域特征表达.文中的方法实现包括:① 利用均值采样的方法对视频进行下采样,保证输入样本的统一性,在此基础上扩大时间间隔,提取不同时间尺度的关键帧序列;② 利用卷积神经网络提取序列的原始帧特征和光流图像特征,并馈送到长短期记忆网络(long short-term memory,LSTM)提取视频的动态语义信息;③ 对多个分类器产生的不同结果进行置信决策融合.
1 相关工作
视频动作分类识别任务相对于图像分类等识别任务内容更加丰富复杂,表现出目标的旋转、平移、缩放等现象.除了包括目标人物、背景等静态语义信息,视频分析为识别任务提供了更多的信息——时序信息.很多工作针对学习并提取视频的静态帧外观信息和运动时序信息已经设计了各种有效的深度卷积神经网络.JI S.W.等[6]首次提出利用3D卷积核进行3D卷积,对视频沿着空间和时间维度直接提取时空特征;在此基础上,D.TRAN等[12]系统化地研究了3D卷积核的时序卷积核长度,从稠密的RGB帧序列中提取特征进行分类识别.然而,由于视频连续帧中的冗余,密集帧序列上的3D卷积计算成本非常高昂.K.SIMONYAN等[9]提出了双流网络,分别把视频帧的原始图像和相应的光流图像作为网络输入,提取视频的空域信息和时域信息,把每帧的分类结果得分作为特征输入,对多类线性SVM进行训练,最终融合成视频的分类结果.C.FEICHTENHOFER等[10]探讨了如何融合两流网络,提出在网络之间添加一个新的卷积融合层,融合之后保留时间网络,在最后再把结果融合一次,另外还添加了一个新的包含三维卷积和池化的时间融合层来把两个网络的一系列在时间上的特征图融合分类.除了使用3D卷积和双流网络学习动作识别任务外,通过将CNN与递归神经网络(recurrent neural network,RNN)相结合建模来解决该问题的方法在计算机视觉社区中也越来越流行.J.DONAHUE等[13]介绍了一种长期递归卷积网络,该网络通过从2DCNN中提取特征并将其作为LSTM的输入;与文中挖掘多序列特征的方法不同,该工作预测了视频序列的每一帧的动作类别,之后通过平均各个预测来确定最终结果.M.BACCOUCHE等[7]进一步扩展了这个想法,他们利用3DCNN而不是2DCNN网络来提取特征;每次从原始视频序列中获取9帧视频帧作为一组输入进行卷积,然后送入LSTM学习预测9帧序列的相关动作类别.C.FEICHTENHOFER等[14]考虑如何在时间维度上更好地处理运动信息,提出了一种快慢结合的网络来用于视频分类:其中一路为slow网络,输入为低帧率,用来捕获空间语义信息;另一路为fast网络,输入为高帧率,用来捕获运动信息.因为输入网络序列帧长度的限制,所以上述方法很难在这些帧中学习到长期的时序关系.为了解决如上问题,提出了多时间尺度双流CNN与置信融合的动作识别网络,可以在多个时间尺度上有效捕捉时序信息并进行动作预测,同时考虑更合理的置信融合方法进行决策识别,以获取更佳的识别准确率.
2 视频动作识别框架
鉴于视频采样的变化和目标主体在视频中运动速度的不同,单一的动作可以包含多种时序信息.为了捕捉多种时空变化特征,文中提出了多时间尺度双流CNN与置信融合的动作识别网络,其总体处理框架如图1所示.

图1 多时域特征提取与置信度融合网络
该模型分为2个阶段:对采样的不同序列特征学习并预测阶段和多分类器置信融合阶段.对每一段视频进行多序列采样,然后通过卷积神经网络将视频帧序列和光流图像序列分别进行空间流特征提取和运动流特征提取,之后输入到长LSTM网络中进行时间序列特征建模,最后对每一种尺度与模态的动作分类器进行置信融合得到最终试验结果.
具体来说,该网络旨在利用整个视频的不同序列之间的上下文信息.不是在单个帧或者帧堆上工作,而是从整个视频中稀疏采样多个时间尺度序列视频帧,每个序列都将对动作类别产生初步预测,然后通过置信融合的决策方法融合双流网络的各个时间尺度的分类器得分,获得最终结果.
2.1 多时间尺度双流CNN的特征学习
用于提取图像特征的卷积网络在视觉识别任务中起着重要作用[15].大多数传统的学习方法只能接受有限数量的训练样本,而深度网络随着训练数据量的增加可获得更高的性能.因此,需要大量数据来训练卷积神经网络以获得更高的性能.然而,对于视频分类识别任务,使用当前可用的数据集来从头训练卷积神经网络是非常艰巨的.为了克服有限训练数据的问题,并确保准确性和效率之间的良好平衡,获得更具分辨性的空间特征,文中使用在大型图像分类数据集(ImageNet挑战数据集)上进行预训练的Inception-V3模型,并在试验中进行微调,用来分别学习提取空间流特征和运动流特征.

2.2 基于LSTM网络的视频动作分类
由于视频包含动态内容,因此视频帧之间的变化可能会编码其他信息,这些信息有助于做出更准确的预测.递归神经网络是一种非常适合处理并学习顺序数据的神经网络结构.S.HOCHREITER等[16]介绍了一种改进的递归网络架构,称为长短时记忆网络(LSTM),它引入了非线性乘法门结构和存储单元,可以有选择地记忆信息,能够克服常规循环网络的梯度消失或爆炸问题,从而对特征向量内的长时间对应关系进行建模.LSTM架构使用存储单元来存储和输出信息,如图2所示.
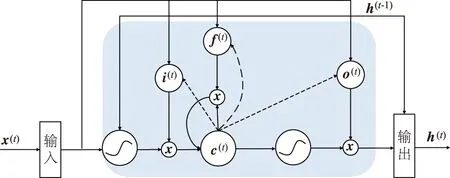
图2 LSTM单元的结构
LSTM架构隐藏层h的计算如下:
i(t)=σ(Wxix(t)+Whih(t-1)+Wcic(t)+bi),
(1)
f(t)=σ(Wxfx(t)+Whfh(f)+Wcfc(t)+bf) ,
(2)
c(t)=f(t)c(t-1)+ittanh(Wxcx(t)+
Whch(t-1)+bc),
(3)
o(t)=σ(Wxox(t)+Whoh(t-1)+Wcoc(t)+bo),
(4)
h(t)=o(t)tanh(c(t)) ,
(5)
式中:σ为激活函数sigmod;i(t)、f(t)、c(t)和o(t)分别为输入门、遗忘门、存储单元和输出门的激活向量;而Wαβ为α和β之间的权重矩阵,例如,输入向量x(t)到遗忘门f(t)的权重矩阵为Wxf.
尽管LSTM能够长时间建模,但前期的工作并没有学习视频中丰富的序列信息.视频中无论场景的变化速度还是人物物体的运动速度不尽相同,因此视频中人或物的运动时域尺度是不同的,即动作变化周期不同.在文中的视频分类框架中,利用LSTM来捕获不同关键序列帧的时间依赖性,学习不同时间跨度的动作类别的上下文信息.文中从Inception-V3网络的最后池化层获取输入,并将其馈送到LSTM网络中学习不同视频序列中的编码信息.第i个尺度下关键子序列最后一层输出的特征为
(6)
式中:mi为视频关键子序列中的帧数.经过LSTM网络得到的序列特征定义为
(7)
获取到的不同时间尺度的关键序列特征分别送入各个分类器得到相应的类别得分为
(8)
再之后对原始帧和光流帧多个序列的网络Softmax层的输出进行置信度融合.
2.3 置信度动作分类决策融合
空间流特征和运动流特征之间以及不同时间尺度序列特征之间有很强的互补性,选择合适的融合方法能够有效地提升视频分类精度.K.SIMONYAN等[9]提出的双流网络使用固定权重进行帧间预测值融合,但是其没有讨论融合权重的选择方法.仅仅对视频帧的预测结果进行融合,并不能保证涵盖视频的所有信息,因此会产生较大的误差.分类器的置信度是分类任务中的一个重要参量,它决定了拒识门限,在多分类器集成中起着关键作用.鉴于样本的随机分布性,合理地权衡样本所属类别与其他类别的总体差异性和所属类别的唯一性.文中采用加权融合样本所属某个类别的最大概率与次大概率的误差和样本所属某个类别的最大概率与样本所属其他各类别的平均概率误差,来确定空间流网络中不同时间尺度分类器和光流网络中不同时间尺度分类器的置信度[17],该置信度算式如下:
(9)
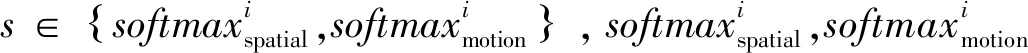

(10)
将类别得分矢量记为yfinal(x)=(p1,p2,…,pn),则样本x的动作类别标签为
(11)
3 试验及其结果与分析
3.1 数据集及试验环境
在UCF101数据集上训练和评估模型的有效性.该数据集选取来源于YouTube的13 320个视频,包含了5个大类的动作类别:人-物交互、人-人交互、肢体运动、弹奏乐器、运动,共计101类动作,总时长达27 h.每个类别有25个组,每组有4个以上的视频片段,包含多样的内容,同一组中的视频具有相同的目标、类似的角度和类似的背景等特点.遵从文献[11]的验证方法,分别在数据集的3个splits上进行训练和测试.在处理数据集时,首先对每个视频进行了统一的格式转换,然后将原始视频帧转换成了统一大小的彩色图像.在数据集上,利用2.1提出的方法进行关键帧序列提取,然后在这些关键序列的基础上,利用文中提出的算法进行分类识别任务.硬件试验环境如下:处理器为i9,GPU为NVIDIA 2080 Ti,内存为64 GB;软件环境如下:python,CUDA10.0,tensorflow1.1.8.
3.2 参数的选择与设置
试验参数的选取会直接影响最后的试验结果.首先随机选择15%的训练数据作为验证集来调整网络中的超参数.对于初始视频样本的下采样,经过反复试验调试,最终选择将N设置为40.对于特征提取网络,将输入的视频帧截取为229×229,利用相关标签学习微调后的Inception-V3模型提取空间和短时运动特征,其包含5个卷积层和3个池化层及3个优化后的Inception Module结构.经过多次试验,考虑网络综合性能最佳的情形,LSTM底层的隐藏层的维度设置为2 048,第2层拥有512个隐藏单元,每层的dropout分别设置为0.5和0.3.Adam优化器的初始学习率为10-3,权重衰减系数为10-5,批量大小设置为32.
3.3 试验结果分析
3.3.1时间尺度的选择及融合方法的试验结果
为了验证提出的多时间尺度双流CNN及置信融合方法的有效性,采用准确率来评估检验文中方法的试验结果.分别选取1-4时间尺度并采用平均融合[9]和置信融合方法进行了动作训练与测试的试验,其动作识别的准确率如表1所示.

表1 时间尺度个数及融合方法对分类性能的影响 %
由表1可见,文中提出的置信度融合方法比平均融合方法具有更高的动作识别准确率.当只有1个时间尺度时,平均融合方法得到的识别准确率为86.3%,而文中方法精确度达到87.7%,提升了1.4个百分点.随着时间尺度的增多,识别准确率逐渐提升;当时间尺度为3时,识别准确率达到最大,为92.2%.当选取的时间尺度继续增加,融合后的识别准确率出现下降同时还会更耗费处理时间.因此,最终将空间流和时域流的时间尺度设置为3.图3给出了文中多时间尺度双流CNN和置信融合的方法在UCF101数据集上代表性10类的动作识别准确率.

图3 UCF101数据集中典型动作识别结果
由图3可见,仅仅提取单时间尺度的视频序列时,双流网络的识别率相对较低,而随着融合的时间尺度的个数增加,大部分类别的识别率得到提升,但少许类别的识别率没有改变或出现下降.对于Swing、Skyjet等大多数类别而言,其运动周期较长,时间跨度较大,所以在时间尺度多的序列特征融合下能够提高动作识别准确率.而对于类别CleanAndJerk,其运动周期较短,所以在密集帧尺度下就能够获得较准确分类.故文中方法考虑多时间尺度与多模态特征学习与提取,并采用LSTM进行各尺度特征的动作分类预测同时进行置信融合,能够使得各个样本在不同时间序列下的时空信息进行相互补充,从而获得更好的动作识别结果,验证了文中提出方法的有效性.
3.3.2与现有方法的对比试验结果
将多尺度双流CNN与置信融合的动作识别方法与目前优秀的分类识别方法在UCF101数据集上的试验结果进行比较,其识别准确率对比见表2.

表2 对比现有方法的试验结果
由表2可见,相对于其他已有的动作分类方法,文中提出的多时间尺度双流CNN与置信融合的网络框架能够取得较好的分类效果.与DT+MVSV、iDT+HSV、MoFAP等采用传统手工设计特征的方法比,神经网络学习深层次特征,从而更具有类别区分性.与现有的深度学习算法相比,文献[9]采用双流网络并进行均值融合的分类方法准确率达到了88.0%,文献[11]在双流网络的基础上利用LSTM获取学习序列特征的方法准确率达到了88.6%,文献[21]通过双流网络学习视频空间特征和时间特征,然后利用Fisher向量和VLAD进行特征融合准确率达到了90.6%.文中采用多时间尺度多模态特征学习并分别动作预测同时通过置信融合的方法,比文献[9]、[11]、[21]分别提升了4.2%、3.6%、1.6%.这说明文中多时间尺度多模态特征学习方法包含的视频上下文信息更加丰富,采用置信度融合两流多个时间尺度分类器的方法能更加合理地融合各个空间网络和时域网络对动作的识别结果,有效地提高了动作识别准确率.
4 结 论
视频的上下文信息能够丰富视频特征的表达.针对目前基于卷积神经网络的视频动作识别任务中未最大化挖掘并利用视频中的时序信息导致识别准确率较低的问题,提出了多时间尺度双流CNN与置信融合的动作识别方法.在UCF101数据集上进行的试验表明文中的方法更合理地学习了视频的时空特征,同时采用多分类器置信融合的方法,为试验分类的101种不同的动作行为实现更好的分类结果,平均识别准确率达到了92.2%,相较于文献[21]等新近的动作识别方法,得到了较大的提升.
在未来的工作中,可考虑通过神经网络自动学习采样视频的关键序列,以期实现更佳动作分类识别.
