基于贝叶斯模型平均法的多模型综合预报洪水概率研究
2021-05-28赫淑杰陈燕朋
赫淑杰,陈燕朋
(1.山东省防汛抗旱物资储备中心,山东 济南 250014;2.山东省济南生态环境监测中心,山东 济南 250100)
1 引言
洪水预报作为一项重要的防洪减灾非工程措施,水文模型是开展流域洪水预报研究的重要工具之一。大量实践表明,没有哪个模型提供的预报结果总能优于其他模型,因此可以将不同模型的预报结果进行综合,发挥各模型的优势,从而得到更为可靠的预报结果。贝叶斯模型平均法通过综合多个确定性模型的模拟预报结果,充分考虑模型结构的不确定性,给出传统的均值预报结果的同时,提供预报变量的置信区间,实现概率预报,为防洪决策提供更准确的水文水情信息。
2 贝叶斯模型平均法概率预报原理
贝叶斯模型平均法(Bayesian Model Averaging,缩写记为BMA)是利用贝叶斯理论在处理数据的过程中考虑模型本身不确定性的统计分析方法。BMA方法主要是以各模型的后验概率为权重,组合各模型预报值的后验分布,从而得到预报变量更可靠的概率分布。
BMA方法中组合预报变量的概率密度函数或分布函数,不仅可以提供如常规模型一样的确定性预报,同时也可以提供概率预报或对定值预报结果的不确定性评价,获得更丰富的预报信息。下面介绍BMA方法。
假设y为组合预报变量,D={y1,y2,…,yT}为实测的数据资料,M={M1,M2,…,MK}为所有可能的预报模型组成的模型空间。模型空间中的哪个预报模型为最优事先并不知道,这是模型本身不确定性的表现。根据全概率定律,BMA方法的组合预报量y的后验概率密度函数的表达式:
(1)
式(1)中:p(y/Mi,D)为已知数据D与模型Mi的条件下预报量y的后验分布;P(Mi/D)为模型Mi的后验概率,即已知数据D的条件下Mi为最优模型的概率。
从(1)可知,组合预报量y的后验分布是以模型Mi的后验概率P(Mi/D)为权重,并对模型的后验分布p(y/Mi,D)进行加权后所得的均值。其效果属于变权估计,即权重将随着模型预报精度的改变而发生变化,预报精度越高的模型将被赋予越大的权重,反之亦然,从而提高组合预报模型的预报精度。
组合预报量y后验分布的均值和方差的计算公式分别为:
(2)
(3)
对水文模型的概率预报结果进行适当的分析与评估是必不可少的。目前,洪水概率预报的评估指标还未有统一的规范。采用覆盖率、平均偏移幅度、平均相对偏移幅度、平均带宽、平均相对带宽、平均不对称度以及平均离散度共7个指标对模拟及预报效果进行评价。
贝叶斯模型平均法的预报结果以概率密度函数或分布函数的形式表示,因此其不仅可以给出传统的均值预报结果,而且还可以实现概率预报。
3 基于BP神经网络的组合预报模型
基于BP神经网络的组合预报模型(其原理介绍详见文献)是水文学领域发展相当成熟的一种组合预报方法,限于篇幅这里不详细论述。
4 研究实例
以淮河流域内的息县、潢川、班台至王家坝区间集水区(简称区间)作为研究实例。息、潢、班至王家坝区间的集水面积为7 110 km2。研究区域的数字化地图见图1。从息县、潢川、班台至王家坝区间1980—2010年的水文资料中选取12场洪水进行多模型综合预报。在用基于BMA的洪水概率预报模型与基于BP神经网络的组合预报模型之前,先用新安江模型和降雨径流经验模型分别对率定期与验证期内洪水进行了模拟计算。

图1 息县、潢川、班台至王家坝区间数字化图
4.1 基于BMA的洪水概率预报模型计算结果
采用BMA方法将新安江模型和降雨径流经验模型的模拟结果进行综合,获得预报变量的概率分布函数,提供期望预报及置信区间预报,并对预报结果进行评估。
率定期内8场洪水的模拟结果及精度统计见表1,验证期内4场洪水的模拟结果及精度统计见表2。
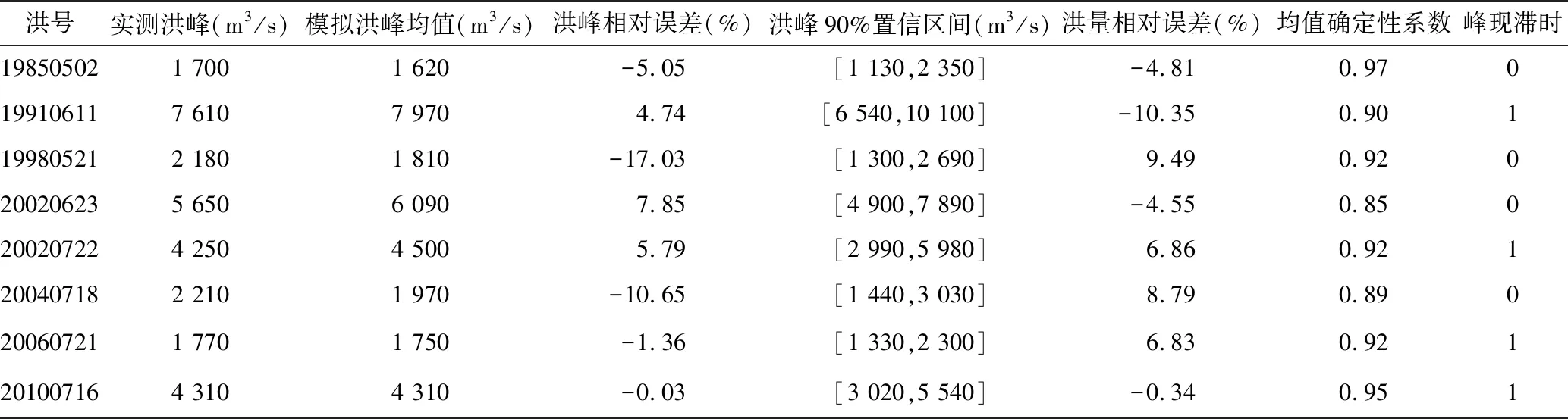
表1 率定期内BMA的模拟结果及精度统计表

表2 验证期内BMA的模拟结果及精度统计表
BMA方法是对各成员模型模拟结果的综合,其模拟精度的改善很大程度上依赖于各成员模型本身预报精度的提升。例如,对于“20080721”场次洪水而言,虽然新安江模型提供场次洪水的模拟洪量高于实测值,但是降雨径流经验模型提供场次洪水的模拟洪量偏低于实测值,且其偏低的程度要高于新安江模型模拟洪量偏高的程度,故导致基于BMA方法时,模拟该场次洪水的洪量值低于实测值。
4.2 基于BP神经网络的组合预报模型计算结果
将新安江模型、降雨径流经验模型的洪水预报结果作为神经网络输入层的输入,输出层的输出结果为基于BP神经网络的组合预报模型的预报结果。由于BP神经网络需要足够的训练样本,因此在每场洪水进行组合预报之前,需要提前取10个时段的实测、预报数据,用于预热BP网络。训练样本在每场洪水开始之前,不参与模拟精度的统计。率定期内8场洪水模拟结果及精度统计见表3,验证期内4场洪水模拟结果及精度统计见表4。
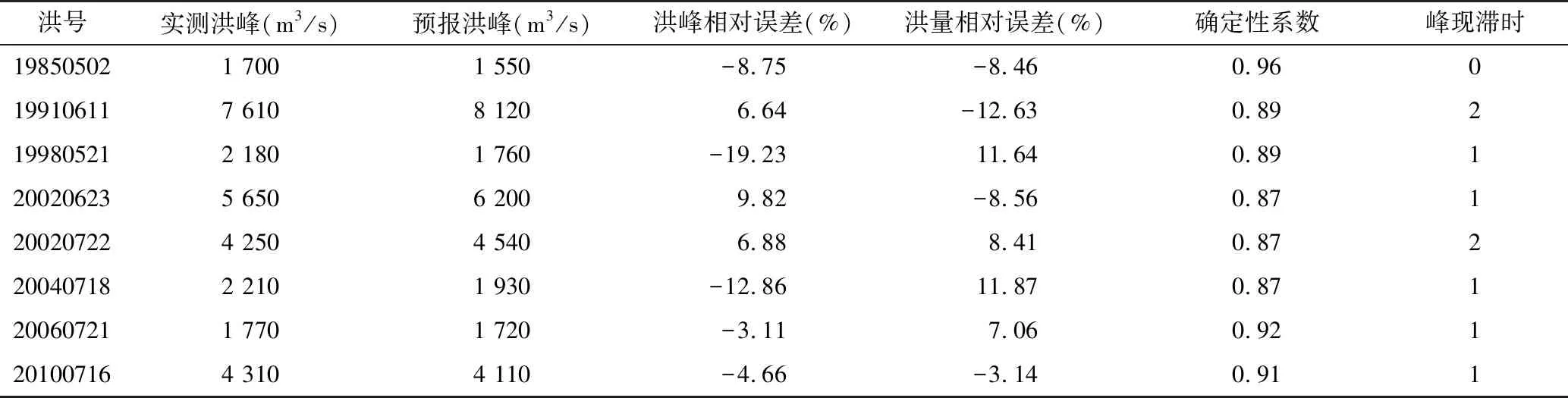
表3 率定期内场次洪水模拟结果及精度统计表

表4 验证期内场次洪水模拟结果及精度统计表
验证期内场次洪水的模拟洪量偏低于实测值的原因与前面所述的基于BMA的洪水概率预报模型所提供均值预报结果偏低的原因相似,这里不再重述。
4.3 两组合预报模型计算结果的对比分析
率定期与验证期内所有场次洪水BMA方法与BP神经网络模拟结果分别见表5、表6,两模型误差特征统计见表7。
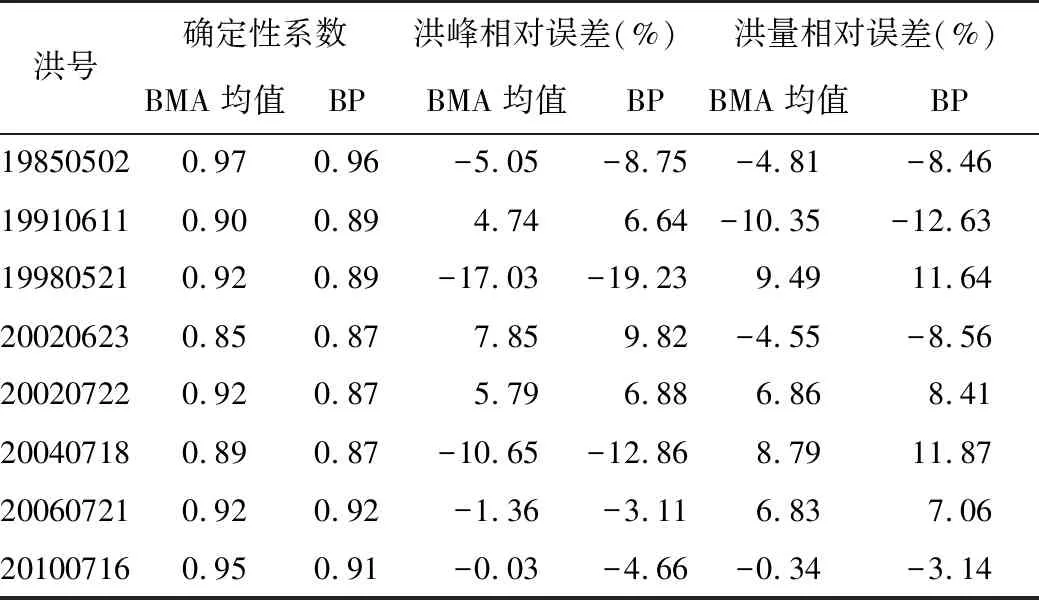
表5 率定期内场次洪水BMA均值与BP神经网络模拟结果及精度统计表

表6 验证期内场次洪水BMA均值与BP神经网络模拟结果及精度统计表
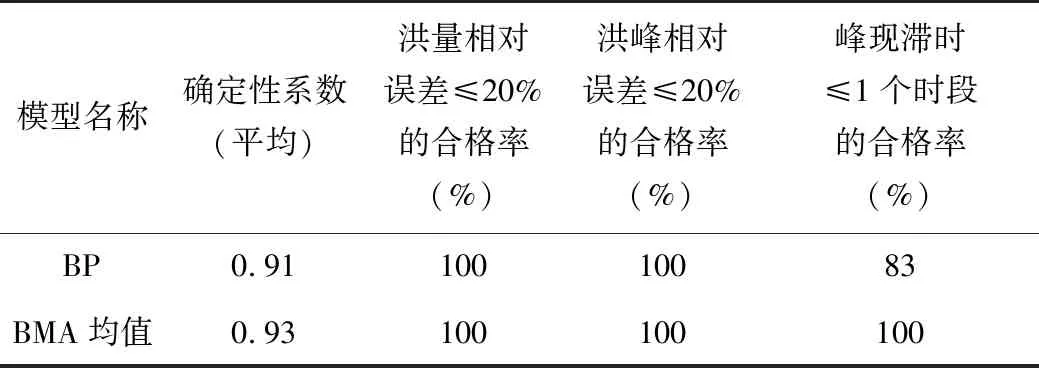
表7 两模型误差特征统计表
从表5中可知,率定期内所有场次洪水,BMA方法模拟结果的确定性系数均大于等于BP神经网络;从洪峰相对误差来看,两种方法模拟结果的洪峰相对误差均在允许误差之内,BMA方法模拟结果的洪峰相对误差均小于BP神经网络;从洪量相对误差来看,两种方法模拟结果的洪量相对误差均在允许误差之内,BMA方法模拟结果的洪量相对误差均小于BP神经网络。
从表6可知,验证期内场次洪水,BMA方法计算结果的确定性系数均大于等于BP神经网络;从洪峰相对误差来看,两种方法模拟结果的洪峰相对误差均在允许误差之内,BMA方法模拟结果的洪峰相对误差均小于BP神经网络;从洪量相对误差来看,两种方法模拟结果的洪量相对误差均在允许误差之内,BMA方法模拟结果的洪量相对误差均小于BP神经网络。
从表7可知,整体上,基于BMA的洪水概率预报模型比基于BP神经网络的组合预报模型提供的确定性系数高,因此前者的预报结果优于后者。
5 结论
采用贝叶斯理论考虑模型结构的不确定性时,为得到预报变量的解析解,利用模型对各序列进行正态化变换,对变换后的结果进行线性假设,同时对参数估计、后验分布等作了简化处理,这些都可能影响到预报的精度。因此,在满足预报精度的情况下,如何利用贝叶斯模型平均方法减少求解预报变量过程中的简化处理是未来研究的方向。
