基于K近邻的变权组合预测模型及应用
2021-05-28刘晴晴
刘晴晴
(安徽大学,安徽 合肥230601)
1 概述
组合预测是各单项预测方法的加权平均,通过提取各种单项方法赋予的有用信息来提高整体预测精度[1]。近年来,组合预测模型的独特优势获得了众多国内外学者的青睐,是未来组合预测发展的方向,已广泛应用于经济、交通、环境等各个领域[2-5]。目前组合预测的发展大多基于定权系数来构建模型,这样就忽略了各单项预测方法预测数据之间的相互关系。为了进一步提高预测的性能和适应性,有必要探索变权重的组合预测模型。本文将K 近邻算法运用于变权组合预测模型预测时点权系数的计算上。以传统的变权组合预测权系数的计算方法为基础,利用K 近邻算法来筛选与预测时点最相关的已发生时点来计算预测时点的权重,而不是将已发生时点进行简单平均,这样确定的预测时点的权重就会避免更多不相关信息。
2 基于K 近邻的变权组合预测模型

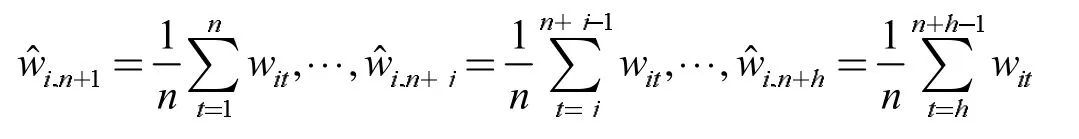
简单平均法确定的预测权重是对过去连续时间点的最优权重进行平均,很明显这样确定的预测时点的权重会涵盖多个不相关时点的信息。
K 近邻算法是基于某种距离度量找出某样本与其最近的K个样本的一类算法[6],本文引入此方法来筛选与预测时点最相关的时点以解决传统简单平均法在计算预测时点权重时的信息冗余问题。

3 基于K 近邻的变权组合预测模型的应用
3.1 模型拟合结果
本文将选择武汉市2018 年8 月20 日至2019 年8 月20 日的PM2.5 浓度数据进行实验,使用的单项预测方法包括自回归滑动平均(ARIMA)模型、支持向量回归(SVR)模型、人工神经网络(ANN)模型和长短期记忆(LSTM)神经网络模型。为了降低计算的复杂度并保证维度相同,本文对每个时间节点取相同个数的近邻。通过实验对比,发现本文PM2.5 浓度预测中设定k 为6时取得了最好的实验效果。为了验证基于K 近邻的变权组合预测模型效果,本文将定权组合预测模型与简单平均法的变权组合预测模型也纳入实验对比中。图1 显示了30%测试集范围内PM2.5 浓度的预测值与观测值的拟合序列对比。
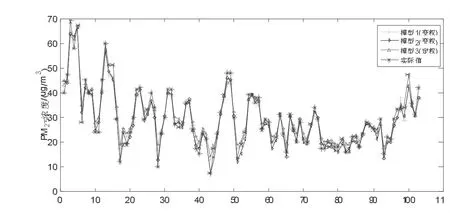
图1 三种组合预测模型的拟合序列图
图1 中,模型1 为基于简单平均法的变权组合预测,模型2为本文基于K 近邻法的变权组合预测,模型3 为定权组合预测。图1 表明,三种组合预测的结果与PM2.5 浓度的真实时间序列趋势大体上是一致的,但是两种变权组合预测更能有效地模拟PM2.5 浓度的时间序列变化特征,尤其是本文提出的基于K 近邻的变权组合预测模型对一些明显高于或低于邻近值的特殊点,也能实现很好的预测。
3.2 模型效果评估
本文采用误差平方和(SSE)、均方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE)四个预测误差指标对模型进行评估。表1 列出了三种不同组合预测模型的预测精度。
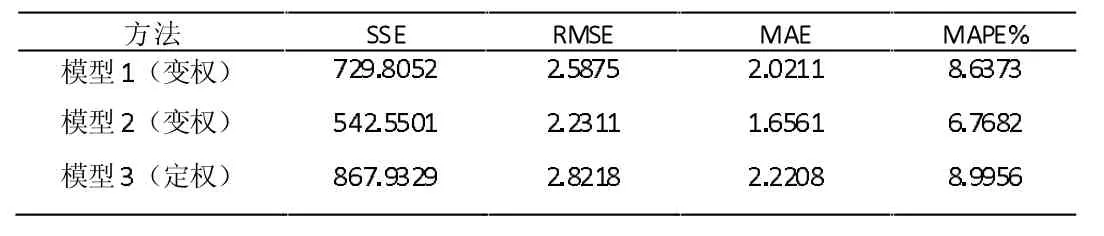
表1 三种不同组合预测模型的预测精度
以上结果显示SSE、RMSE、MAE 和MAPE 四种预测误差在模型2 中都是最小的,很明显可以看出两种变权组合预测模型的精度要高于定权组合预测模型的精度,变权组合预测模型2的效果又比变权组合预测模型1 的效果好。
为了更好的展示预测值与观测值的效果,分别绘制模型1(变权)、模型2(变权)以及模型3(定权)之间的拟合效果如图2所示。
与图1 的结果一致,三种组合预测模型都能有效地模拟观测值的时间序列特征,但是与观测值之间的解释方差分别为94.7%、95.2%和96.7%,因此拟合效果由低到高为模型3(定权)、模型1(变权)和模型2(变权),说明本文提出的基于K 近邻的变权组合预测模型对PM2.5 浓度时间序列特征具有更好地捕捉性能。
4 结论
本文从变权组合预测模型的预测时点权重的计算方法作为出发点,为改进传统的简单平均法,提出了基于K 近邻算法的变权组合预测模型,实验结果表明本文基于K 近邻的变权组合预测模型的预测效果有着明显优势。无论是在拟合效果还是误差评估中都表现出了优于其他对比模型的预测性能和稳定性。
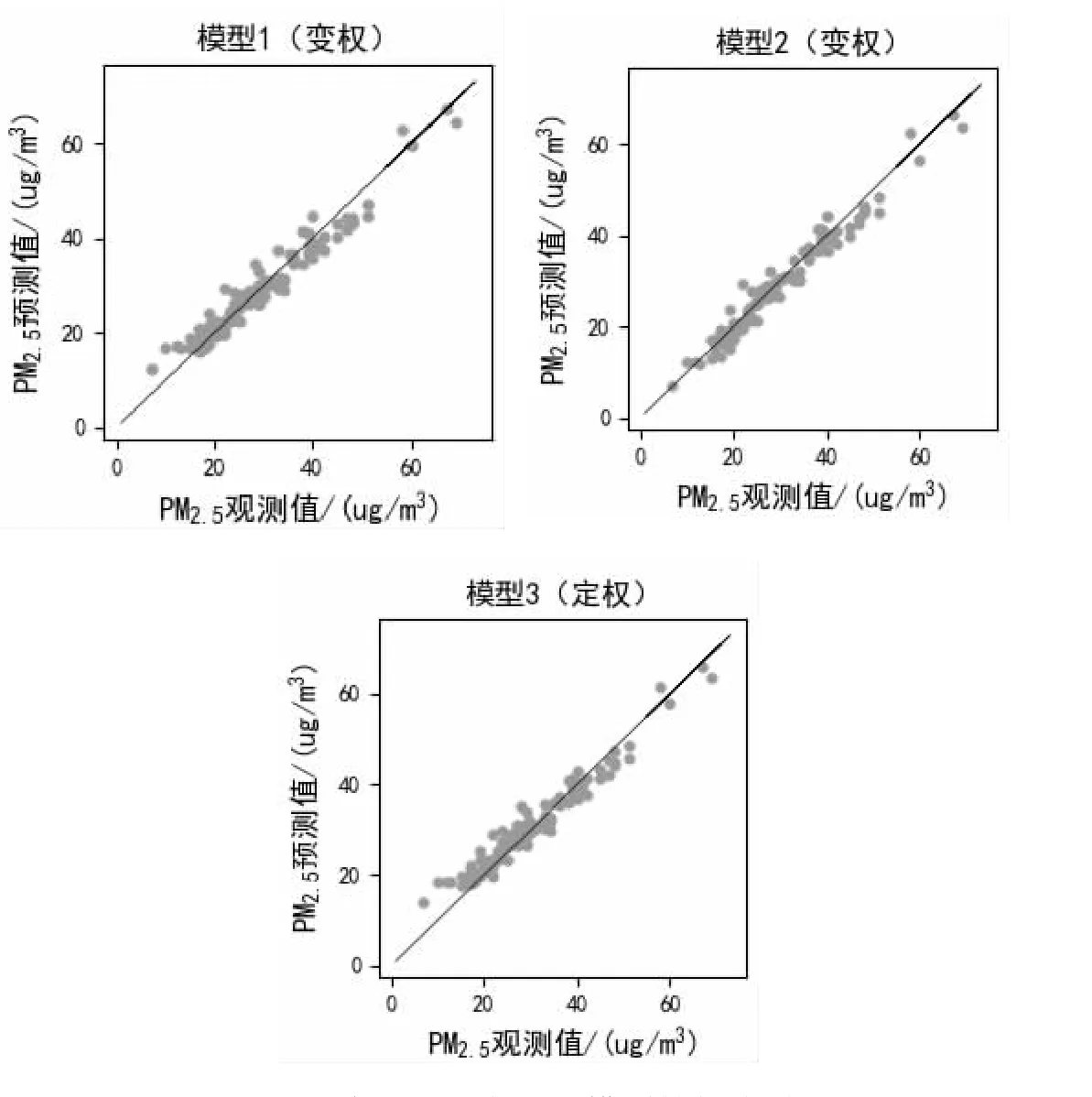
图2 三种不同组合预测模型的拟合效果
