面向政治领域的事理图谱构建
2021-05-27周子雅李斌阳刘宇涵邵之宣吴华瑞
白 璐,周子雅,李斌阳,刘宇涵,3,邵之宣,吴华瑞
(1.国际关系学院 网络空间安全学院,北京100091;2.北京市农业信息技术研究中心,北京100097;3.中国科学院大学 网络空间安全学院,北京101408)
0 简介
事理演化图谱(以下简称事理图谱)是一个描述事件之间顺承、因果关系的事理演化逻辑有向图[1]。作为知识图谱的延伸,事理演化图谱以事件为节点,以事件间关系为连接节点的边,这使得事理图谱较之知识图谱具有更丰富的信息表达形式及更强的事件间逻辑关系描述能力。事理演化图谱应用场景十分广泛,主要原因是其具备良好的描述事件间演化规律和模式的能力,尤其在以具体事件间关系作为研究对象的学科中,如金融、医疗和历史学等领域,构建相关学科的事理图谱具有重要意义。
“政治学作为一门社会科学学科,主要研究国家和社会公共权力的活动、形式和关系及其发展规律,政治学研究重视揭露事件间的因果关联,在分析过程中,运用归纳与演绎、分析与综合、抽象与概括等方法,并结合人类主观经验判断,从而认识事物本质、揭示内在规律”[2]。在政治学领域,研究事件间关系不仅可以有效辅助研究人员挖掘导致政治事件发生的深层因素,更能够从宏观层面衡量相关重大政治事件的影响,预测其未来走势。因此,亟待构建一套面向政治领域的事理图谱,以辅助政治学研究。
图1展示了中美双边贸易相关的重要事件及其关联关系。图中主要包含了五个事件以及事件间的关系,事件关系包括顺承关系和因果关系两种。其表达的隐含信息可解释为,“取消加征关税”是“习特会”达成的共识,随之“货币汇率反弹”“双方股价增长”,促成了“中美贸易战暂告一段落”。为了更好地辅助研究人员展开政治领域的研究工作,理想的政治领域事理图谱应包含相关事件及事件间的逻辑关系。例如,研究人员可以利用图1预测中美贸易战的未来走势。

图1 中美双边贸易事理图谱
然而,政治领域事理图谱的构建面临诸多挑战,其原因是政治事件类型和事件内容较为复杂,且政治事件抽取较为困难,主要表现在以下三个方面。
(1)用于图谱构建的政治领域语料库匮乏。政治领域语料库是构建领域事理演化图谱的基础,是进行事件抽取和政治事件间关系挖掘的前提。但目前可用语料库匮乏,其原因有两个方面。一方面,图谱构建对于政治领域数据集的要求较高,需保证数据的真实性及客观性,即数据文本所描述信息必须符合事实,且不含有明显的立场偏向和个人主观色彩;另一方面,对于政治领域事件类型尚无明确的划分标准。传统事件抽取任务中定义的面向开放域的事件标注方式(如Automatic Content Extraction会议所制定的事件类型划分标准[3])并不适用于政治领域事件。语料库的匮乏严重影响了封闭域事理图谱的构建工作。
(2)政治类事件抽取任务精度较低。作为事理图谱的节点,事件抽取的精度影响着图谱构建的效果。由于自然语言的表达具有灵活性和歧义性,且政治领域文本句式结构普遍较为复杂,这为从非结构化文本中准确抽取事件带来了困难。
(3)政治事件间关系复杂,深层关系提取困难。对于一些领域的事理图谱,事件之间的关系是清晰明确的。例如,在金融事理图谱中,“国际资本的流入”“经济增长模式的转变”可能会导致“货币超发”,从而产生对“农产品价格”“交易房屋价格”及“货币汇率”等相关事件的影响(1)http://eeg.8wss.com,而政治领域的事理图谱因事件错综复杂的关系导致了构建的难度大大增加。
针对上述挑战,本文在领域专家指导下,结合政治事件的特点,以搜集的近20年两岸重大政治事件整理为语料库,设计了一套事件分类标准和标注模板。其中,包括16个事件类别以及针对每个类别所定义的事件触发词和论元;在此基础上,标注了一套适用于政治领域的事理图谱语料库,命名为政治事理图谱(political eventic graph,PEG)。PEG语料库共包含约1 700个事件及1 500个事件间关系。此外,本文提出了一套面向政治领域的事理图谱自动构建框架。针对政治领域文本包含大量长句及缩写的表达特点,提出了一种融合注意力机制与字嵌入修正的神经网络,并采用一种BERT+BiLSTM模型框架用于事件抽取及论元抽取。通过实验验证,在PEG语料库上进行事件分类与论元分类任务,F1指标均有所提高。
1 语料库构建
1.1 事件类别及标注模板
为构建政治领域的事理图谱,本文选用了“华夏新闻网(2)http://www.huaxia.com/lasd/twdsj/index.html”上近20年关于两岸关系的政治新闻作为数据集。采纳领域专家意见对数据集进行标注,并设计了一套针对政治领域事件的标注模板。
与Automatic Content Extraction[3]定义的事件标注模板相比,该模板在服务于政治领域的事件抽取方面具有更强的事件覆盖度和领域专业性。首先,该模板根据事件内容对16类政治事件进行定义,其中包括访问行为、选举行为、侦查行为、庭审行为等。其次,由触发词作为定义一个事件的标识,通过专家指导和大量文本分析的方式,罗列出各事件类型的主要触发词。最后,针对每类事件的内容组成和句式结构,提出事件主要论元组成成分,包括主体、客体、时间、地点等特殊要素(3)事件类别属性是指针对某些特定的事件类型所特有的论元。。综上,本文提出的政治领域事件标注模板主要由事件类型、触发词、论元三部分组成,具体如表1所示。为方便理解,表中提供了对于事件类型的详细解释。

表1 政治领域事件标注模板

续表
本标注模板可帮助构建政治领域事件抽取任务的数据集,以此辅助后续事件抽取模型的训练。所提事件标注方法也可拓展到其他领域,以丰富训练语料。
1.2 事件标注举例
为了便于理解,下面就选举类事件的标注进行举例说明。在例句“前民主进步党主席蔡英文宣布参选下届民进党主席。”中,触发词是“参选”,论元包括:(1)主体:选举人(蔡英文);(2)客体:职位(下届民进党主席)。

选举类案件
2 图谱构建框架
本文提出了一套面向政治领域事理图谱的自动构建框架。该框架主要由制定标注模板、事件抽取、关系抽取以及图谱展示等四部分组成。本节主要介绍其中的两个核心部分,即事件抽取和关系抽取。
事件抽取任务包括触发词抽取和事件论元抽取两部分,即识别输入句子中的触发词和判定句中实体是否为某种事件类型的论元。本文主要提出两种事件抽取任务模型:①流水线模型(pipeline model):按顺序完成触发词抽取模型和论元抽取模型的训练。如本文将事件抽取视为分类任务,使用DMCNN网络[4]先进行触发词抽取并确定事件类型,再根据事件类型进行该场景下的论元抽取。②联合模型(joint model):将任务整合为结构预测问题,通过一次模型训练完成触发词及实体论元的抽取。本文采用的联合抽取方式相较于流水线方式能够有效消除误差传递的问题,从而提高模型性能。
2.1 融合字向量的事件抽取方法
与英文分词使用空格作为天然分隔符不同,中文分词会因为数据预处理工具的好坏而影响分词的效果,进而导致误差传递,尤其对于具有实际意义的单字的分词会有很大偏差,从而导致了中文事件抽取任务的难度更高。在对数据集的观察过程中,我们发现词语的单字简称问题在政治领域文本中比较普遍,如国家、领导人名称的简写(“中国”简称为“中”,“蔡英文”简称为“蔡”)。以词向量为输入的网络模型不能很好地捕捉到文本中每个字符所蕴含的语义信息,进而影响触发词及论元的识别性能,导致事件抽取的准确率较低,最终影响事理图谱的构建。
为了解决上述问题,本文在借鉴Lin等人[5]工作的基础上,引入注意力机制,并针对政治领域的事件抽取任务提出了一种融合字向量的深度学习网络CM-DMCNN(char-modified dynamic multi-pooling CNN),网络结构如图2所示。整个网络由五部分组成,分别是字表示层、注意力机制层、动态多池化卷积神经网络层、字修正混合表示层和输出层。其中,输入为文本的向量表示,输出为论元类别。本文引入注意力机制,用以捕获长句中触发词与论元间的依赖关系,以解决CNN无法获取全局特征的问题。本文采用一种字修正混合表示,以应对政治文本中频繁出现的简称现象,即在词向量基础上融合了字向量,以便更好地捕捉单字的语义特征。以下对网络结构中的每一层进行详细介绍。

图2 CM-DMCNN模型网络结构
2.1.1 字表示层
不失一般性地,我们令由n个词组成的输入句子表示为S={w1,w2…,wn}。通过训练能将词转化为向量表示的向量矩阵M∈k×|V|,其中k为词向量维度,V为可变词表长度,查表得到输入词对应的k维词向量xW∈Rk。为了更好地获取触发词及论元候选词间的依赖关系,词表示ti由三部分组成,即传统词向量xW、相对位置向量xP和事件类型向量xE。那么对于第i个词或字,其表示向量ti如式(1)所示。
这里我们仅以词表示为例进行说明,对于字可以采用相似方式的表示,为了行文方便,我们将字和词统一表示为token。
2.1.2 注意力机制层
如前所述,在政治事件文本中普遍存在长句。使得在长句中触发词与论元间隔较长,词间依赖关系较弱。因此,我们引入注意力机制来有针对性地增加某些词语的权重,从而获取间隔较长的词之间的依赖关系。计算如式(2)、式(3)所示。
其中,vT,Wa,ba均是模型中需要训练的参数,αi为系数。为了保留每一个token的语义信息,我们将所有ti与系数αi相乘所得的向量拼接起来作为本层输出,即X1:n。
2.1.3 DMCNN层
在卷积层,我们利用CNN进一步获取词的深层语义特征。具体地,使用大小为h的窗口将ti和ti+h-1经过注意力层的输出Xi和Xi+h-1连接,并分别与各层卷积核进行卷积计算,如式(4)所示。
其中,wj为卷积层的第j个卷积核,bj∈R为偏置项,卷积结果C∈m×(n-h+1)。
为了解决触发词的歧义问题,同时最大程度地保留语义信息,采用动态多池化方法,在池化层将各层卷积结果按候选触发词和论元进行划分,对每部分的结果进行池化并将其拼接,以此得到每个token词级别的特征fword。同理可得字符级别的特征fchar。
2.1.4 混合表示层
本模型借鉴了Lin等人[5]的思想,采用了混合特征表示学习方法,在得到词级别的特征fword和字符级别的特征fchar之后,统一将其转化为维度d′的向量,即f′word和f′char,并使用sigmoid函数将其混合在一起得到包含更丰富信息的混合特征表示fC。过程如式(5)、式(6)所示。
其中,s为sigmoid函数,WC、UC为权重矩阵,WC∈Rd′×d′,UC∈Rd′×d′,bC为偏置值,ZC为一个d′维的向量,调节f′char、f′word在混合表示fC中的权重。
2.1.5 输出层
在得到融合字向量的混合表示fC后,通过一个softmax全连接网络,得到结果向量O,其中第i个元素对应分类标签i(论元角色),由此得到条件概率P(i|x,θ),如式(7)所示。
其中,m为论元角色的数目。
本文在训练模型时,选择交叉熵作为损失函数,如式(8)所示。
其中,m为分类类别的数量,P(i)为预测分类标签的概率。
2.2 基于预训练模型的事件抽取方法
以上CM-DMCNN模型为流水线模型,对于联合模型,本文引入预训练模型BERT,采用BERT+BiLSTM序列标注模型应用于事件抽取任务。作为可以同时抽取事件触发词和论元的联合模型,该方法可有效减少误差传递。预训练模型BERT能很好地提取句子中的不同层次的特征关系,全面反映句法特征,且能获取更多语义信息,避免歧义问题的出现。在BERT的下游添加RNN网络可以很好地补充对于句子序列特征的获取。针对中文事件抽取问题,之前针对神经网络方法的一种较好改进是加入字向量,而我们使用的BERT预训练模型对中文并不进行分词,而是将单字作为输入文本的基本单元,这有效解决了中文事件抽取对于分词结果的依赖性和减少了误差传递。模型网络结构如图3所示。

图3 BERT+BiLSTM模型图
基于BERT+BiLSTM的联合事件抽取框架主要有以下三部分组成。
(1) 基于BERT的词向量表示层
由于BERT对于中文文本的输入是以单字为基本单元的,即BERT层的输入为一句话中的每个字和位置向量,经BERT层输出得到每个字的向量表示xi,输入文本的表示为X=(x1,x2…xn)。其中,i为字向量的维度,n为输入文本的字符长度。
(2) 基于BiLSTM的特征捕捉层
将得到的向量表示输入一个双向LSTM神经网络,如式(9)所示。

(9)
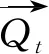
(3) 输出层

(10)
其中,f为激活函数,yti为第i个词的触发词标注标签。
在完成触发词的抽取之后,我们将其他实体的表示和触发词聚合在一起后接全连接层来预测实体在该触发词场景下的论元角色标签,如式(11)所示。

(11)
其中,Ej为实体向量,Ti为已标注的候选触发词向量,[Ti,Ej]是将两个向量拼接,yaij为第j个实体在第i个触发词的场景下是论元的概率。
2.3 事件关系抽取方法
由于当前我们主要聚焦于政治领域事件间的顺承、因果两种关系,且政治领域的事件间关系较为隐晦,为了保证准确率,本文利用基于关键词匹配的方法来进行关系抽取。
具体地,首先基于已标注的事件,根据其论元信息(如所研究的国家、机构等)与相关事件进行匹配,然后基于关键词进行事件关系抽取。部分顺承及因果关系的关键词如表4所示。利用上述框架,我们可以构建出面向政治领域的事理图谱,并在实验部分展示图谱示例。

表4 顺承、因果关系关键词表
3 实验
3.1 事件关系抽取方法
我们在PEG语料库上进行了一系列实验,以验证面向政治领域事理图谱构建框架的效果。PEG语料库由约1 000条文本构成,共包含16个事件类型,约1 700个政治事件;1 500个事件间关系,其中因果关系约300条,其余为顺承关系。将全部文本按照4∶1的比例划分为训练集和测试集进行实验。
针对事件抽取任务,我们采用CM-DMCNN模型,分别训练了100维的字向量和词向量,并将二者最大长度设置为250字和150词。同时,在模型的动态卷积池化部分,分别设置字卷积核以及词卷积核窗口大小为5和3,以对其进行训练。此外,将f′word和f′char均设置为400维,令dropout=0.5。我们针对触发词识别和论元检测任务采用相同设置,在触发词识别过程中,没有使用事件类别向量xE。对于BERT+BiLSTM模型,其中使用BERT(base)版本[6],对于BiLSTM层,设置层数为1且每层100个神经元。令dropout=0.5,batchsize=64,learningrate=5e-5。
为了评估实验效果,我们采用精确率(Precision)、召回率(Recall)和F1值作为评价指标,如式(12)所示。

(12)
3.2 事件关系抽取结果
在实验中[7],我们对比了CM-DMCNN、BERT+BiLSTM和未使用字向量的Word-DMCNN(Chen等人[4])在事件触发词分类、事件论元分类子任务上的表现,结果如表5、表6所示。
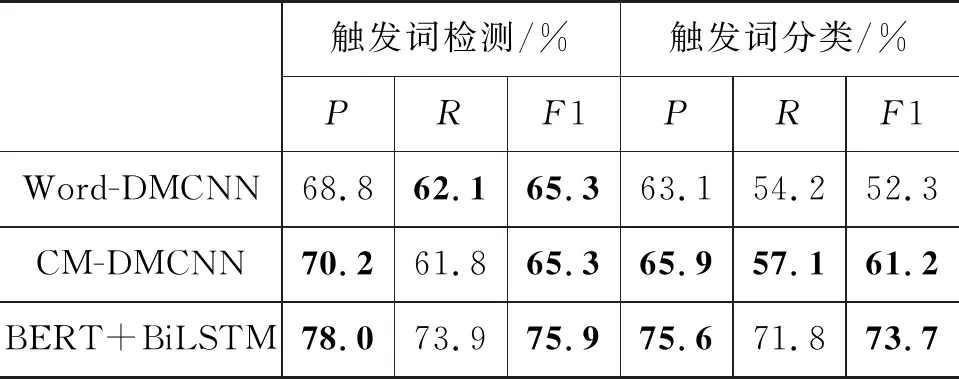
表5 事件触发词分类结果

表6 事件论元分类结果
实验结果表明,本文所提模型在触发词分类以及论元分类任务中均取得了不错的效果,且其相较于Word-DMCNN在F1上均有较大提升。对于CM-DMCNN,这说明融入字向量和注意力机制可有效提高政治领域事件抽取的准确率。事实上,我们在语料库中发现,政治事件的表述当中大量存在单字简称,例如“台当局对菲启动制裁措施”中的“台”和“菲”二字分别是“台湾”和“菲律宾”的简称。因此,融合字向量的词嵌入表示可以有效地获取单字简称的语义信息。对于BRRT+BiLSTM,BERT具有强大的特征提取功能,添加的RNN网络可以很好地补充对于句子序列特征的获取。但BERT模型较大,在下游接复杂神经网络容易产生严重的过拟合,因此,将下游RNN层数设为1层,可有效提高任务性能。
3.3 图谱示例
为了更好地说明如何利用事理图谱对政治领域事件进行分析预测,我们给出了一个自动构建的图谱示例,如图4所示。图中节点表示某一政治事件,边表示事件之间的关系,其中浅色边表示顺承关系,深色边表示因果关系。该图谱共包含6个节点,4个因果关系,1个顺承关系。该图谱可解释为,“撤出核电电力供应”引发“大规模停电事故”,而“大规模停电事故”“蔡当局推进年金改革”和“民进党通过‘劳动基准法’修正草案”这三个事件共同导致了“蔡支持率走低”,而在随后的九合一选举中“国民党人任16席县市长”。

图4 图谱示例
4 相关工作
本文的工作重点在于如何构建面向政治领域的事理图谱,因此本节对事理图谱的研究现状及其两个核心技术——事件抽取方法与关系抽取方法的相关工作进行介绍。
4.1 事理图谱构建
事理图谱最初是由Yang等人[8]提出的。在之后的几年,业界在多领域对事理图谱进行研究并积极实践,在不同应用场景构建事理图谱。如丁等人构建的(4)http://eeg.8wss.com金融事理图谱,即通过大规模的财经新闻语料抽取金融事件,挖掘事件间因果关系,并由事件泛化得到不同文本中的共指事件,该图谱可用以挖掘金融事件间的内在关系。除此之外,在出行、舆情、安全等多个领域,如李等人提出的出行领域事理图谱、周京艳等人[9]构建的面向情报应用的事理图谱,以上图谱均可用以整合信息,归纳联系,帮助用户及研究人员综合了解事件信息及掌握事态发展规律。
然而,目前尚缺少面向政治领域事理图谱的研究。为了填补这一空白,本文设计了一套政治事件的分类标准和事件标注模板,构建了一套面向政治领域的事理图谱。
4.2 事件抽取
事件抽取是文本处理领域的一个重要任务,其研究方法大体可以分为两类——知识驱动方法和数据驱动方法[10]。知识驱动的抽取方法主要依赖于人为制定的一些既有规则,如Yakushiji等人[11]提出了使用规则匹配并结合语法树抽取事件样本,再抽象生成生物医疗领域的事件模板。知识驱动的方法在准确率上有着不错的表现,但是由于过分依赖现有知识,因此其难以扩展。数据驱动方法的核心思想是将机器学习或深度学习的算法用于事件抽取。Li等人[12]提出借鉴命名实体识别的序列化标注思想,结合Zhao[13]提出的结构化的感知机(structured perceptron)来对事件进行抽取。即对输入句子中的每一个词语,人为地构造大量特征,例如该词的近义词、词根、该词是否为非指称代词等。然后将上述特征输入到感知机中进行事件预测。上述基于传统机器学习的方法仍然需要人为构造大量特征,于是Nguyen等人[14]引入神经网络,通过自动提取特征来对事件进行抽取,但该方法无法有效解决事件抽取中论元的歧义性问题。Chen等人[4]提出将动态池化卷积神经网络(DMCNN)应用到事件抽取中,该方法能够有效地识别同一词语在不同事件中所扮演的角色。实验结果表明,DMCNN在处理多角色问题上表现出色。针对中文表达特点,Lin等人[5]通过融合字嵌入的方法有效地提高了事件抽取效果。本文旨在抽取政治领域事件,而该领域文本包含大量长句及缩写,因此本文在文献[5]的基础上,进一步融合了注意力机制,将其应用于事件抽取以及论元抽取中,有效提高了面向政治领域的事件抽取的准确率。
4.3 关系抽取
关系抽取任务通常基于以下两种方法完成:基于规则的方法和基于机器学习的方法。杨健[15]基于事件元素的语义信息,构建事件以及事件元素间的语义关联性,对候选事件进行因果关系的识别。干红华等人[16]提出了一种基于结构分析的事件因果关系抽取方法。Marcu等人[17]采用朴素贝叶斯模型,通过分析相邻句子间的词对概率来抽取因果关系。Sorgente等人[18]首先通过定制的规则抽取事件因果关系,然后通过贝叶斯推理优化结果。本文由于受限于数据集规模,主要采用了基于关键词匹配的方法进行关系抽取。
5 总结与未来工作
本文旨在构建面向政治领域的事理图谱。为此,我们搜集了近20年的两岸重大政治事件,设计了一套事件分类标准和标注模板,标注了一套适用于政治领域的事理图谱语料库。同时,本文提出了一套面向政治领域的事理图谱自动构建框架。具体地,针对政治领域文本包含大量长句及缩写的表达特点,分别提出了一种融合注意力机制与字嵌入修正的神经网络CM-DMCNN和一种BERT+BiLSTM模型框架用于事件抽取及论元抽取。通过在PEG数据集上进行实验验证,在事件分类与论元分类任务中,F1指标与基准模型相比均有了较大提升。
未来工作将主要集中在以下两个方面。
第一,扩大数据规模。本文主要使用与“两岸关系”相关的新闻事件作为数据集,未来我们将扩展政治研究领域,以进一步扩大数据规模。
第二,丰富事件间的关系类型。目前,本文仅对因果和顺承两种事件间的关系进行研究,并不能完全覆盖政治事件间的复杂关系。未来我们将引入更多关系类型的事件,以丰富构建的事理图谱的信息,促进相关领域研究。
