基于特征融合的双模态低辨识度目标识别
2021-05-27薛培林殷国栋黄文涵耿可可
吴 愿 薛培林 殷国栋 黄文涵 耿可可 邹 伟
东南大学机械工程学院,南京,211189
0 引言
自动驾驶车辆是在普通汽车上增加雷达、摄像头等传感器、控制器、执行器等装置,通过环境感知技术获得周围环境中的行人、车辆等关键信息,使得车辆能够像人类驾驶员一样自动分析行驶的安全及危险状态,合理规划出安全的路径并安全地到达目的地。自动驾驶车辆的最终目的是实现无人驾驶车辆。环境感知技术是自动驾驶汽车的核心技术之一,是实现无人驾驶最难的技术。国内外学者都对环境感知技术作了不同程度的研究,其研究方法主要分为基于图像处理的方法、基于机器学习的方法和基于深度学习的方法三种。
传统的图像处理方法主要通过检测目标的颜色和形状特征来获得目标感兴趣区域。由于现实生活中RGB颜色空间对光特别敏感,因此基于颜色空间的研究主要包括Lab颜色空间[1-2]、HSV颜色空间[3-4]、YUV颜色空间[5-7]等。此类方法都是通过颜色空间的转化提高目标与周围环境的对比度,并通过形状特征等提取更为精确的目标感兴趣区域。
当使用传统颜色空间方法检测图像上的目标时,通常会与机器学习的方法相结合以获得目标的分类结果。机器学习的方法包括Adaboost[8-10]、支持向量机(SVM)[11-12]、人工浅层神经网络[13]等。机器学习方法在实时性与准确率上不能满足现实场景下的自动驾驶车辆要求。
近年来,随着深度学习的发展,神经网络在目标识别准确率与实时性方面表现优异。常用的神经网络算法大概分为三类。第一类是基于区域推荐的目标识别算法,如Faster-RCNN网络算法[14-15],该网络由特征提取网络、区域提取网络(region proposal net,RPN)、目标分类网络组成,RPN与特征提取网络、目标分类网络共享参数,因此产生的边际成本非常低,该网络对目标识别的准确率在85%左右。Faster-RCNN网络算法虽然识别准确率高,但是实时性较差,不能满足自动驾驶车辆实时性的要求。第二类是基于回归的目标识别算法,例如YOLO(you only look once)网络算法[16],YOLO网络算法在准确率方面略差于Faster-RCNN算法,但是其实时性可以达到要求。YOLO网络算法是直接对整个图像划分粗网格和生成一组目标边界框,若网格内存在目标,则该边界框会输出相应的分类和定位坐标,该算法对于目标识别的准确率在80%左右。第三类是基于搜索的目标识别算法,例如Attention Net网络算法[17],它是一种基于视觉注意力的Attention Net方法,不同于传统神经网络的输入向量与权重的相加,该算法使用点积进行相似度计算得出权重,再将归一化的权重与值加权求和得到最后的Attention值,该算法对目标识别的准确率在65%左右。
以上文献对目标识别的研究都是针对理想环境下的目标,在现实生活中,单模态的车载彩色相机通常会受到黑夜、雪天、雾霾天等低辨识度天气条件的影响而失效,严重影响人员、车辆目标识别的准确率,不能满足自动驾驶车辆的安全性需求。为了提高低辨识度目标识别的准确性,可以将两种不同类型的传感器进行同一目标特征的提取,例如彩色相机与红外相机,彩色相机能够采集到目标的颜色信息,且分辨率较高,而红外相机能够采集到目标的温度信息,所以在一定距离范围内是互补的。文献[18-20]对同一个目标进行多源的红外图像的温度特征与可见光图像的彩色特征提取与融合,可见光相机与红外相机由于其自身的成像特点,在一定程度上可以实现目标特征采集的互补,提高难检测目标的识别率。
为了提高低辨识度环境下人员、车辆识别的准确率,本文以光线昏暗的低辨识度环境下的目标为例,提出了一种利用彩色相机和红外热成像仪同时检测自动驾驶目标的方案,然后利用优化后的双模态网络算法融合彩色相机采集到的颜色特征与红外热成像仪采集到的温度特征,将融合后的特征输入到神经网络的分类层中,得到目标的分类和目标在图像上的坐标。为了融合彩色图像上的颜色特征与红外图像上的温度特征,本文将单模态的YOLOv3网络改进为双模态的网络算法。为了对比多种特征融合方案,本文还提出了四种主干网络的改进模型。
1 YOLOv3神经网络的改进
1.1 单模态YOLOv3网络
YOLO网络算法是一种一步走(One-stage)算法,即只要将一整张图像输入到网络中,就能够得到图像上目标的分类和定位,而如Faster-RCNN这类算法是两步走(Two-stage)算法,需要先在图像上生成一系列的候选区域然后进行分类,因此,YOLO网络在实时性上明显优于Faster-RCNN网络。实验表明,Faster-RCNN网络算法检测一张图像的速度为7帧/s,而YOLO网络算法检测一张图像的速度为45帧/s,能够满足复杂现实场景下目标检测的实时性要求。
YOLOv3网络结构见图1,可以看出YOLOv3网络算法是将一幅图像分割成S×S(S一般为7)的网格,如果某个目标的中心点落入这个网格中,则这个网络就负责检测该物体,并输出该物体的n(n一般为2)个边界框(bounding box,BBOX)值和置信度值(confidence scores,CS)。每一个BBOX需要预测目标类别的概率与目标在图像中的坐标位置,坐标位置包括坐标和宽高。
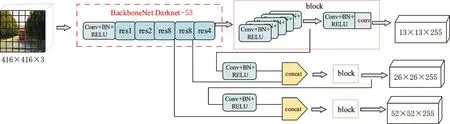
图1 YOLOv3网络结构Fig.1 Structure of YOLOv3
YOLOv3网络是对YOLO网络的改进,在保证速度优势的前提下,提高了预测精度。YOLOv3网络的主干网络是Darknet-53,是具有52个卷积层的特征提取网络,此特征提取网络借鉴了残差网络的做法,在一些卷积层之间设置短连接。为了提高目标识别的准确性,通常需要在特征提取网络上增加更多的网络层数,理论上网络层数的增加可以提高目标识别的精度,因为神经网络的训练是通过网络自主学习卷积层的参数来得到输入与输出的某种映射关系,使得网络预测的输出与实际输出更加接近。神经网络训练过程中会通过前向传播得到输入的非线性激活值即预测值,然后通过后向传播改进网络的参数,在后向传播时,为了减小预测值与实际值之间的误差即损失函数值,需要沿着函数梯度下降的方向调整参数值。但是,在实际训练神经网络的过程中,随着网络层数的增加,损失函数会在一开始逐渐减小后而又突然增大,这是因为,随着网络层数的增加,神经网络后向传播改进参数时每一层的梯度下降越来越少,而网络的后向传播是一个链式过程,在神经网络由后向前计算梯度时,中间某些层函数值对参数的导数特别小(趋近于零)或特别大(大于1),它们得到的乘积就会逐渐趋向零或无穷大,从而导致梯度的消失或爆炸。这就说明,神经网络在训练时,随着层数的增加,后面网络层数的训练效果远达不到前面网络层数的训练效果,这个问题可采用残差网络来解决。残差网络是由残差块(residual block,RB)组成的网络,残差块的结构见图2。由图可以看出,残差块是由两个卷积层和一个短连接组成,残差块的输出是输入和输入的非线性激活函数值的和,即输出H(x)=F(x)+x。在残差网络中,网络需要学习的参数是F(x)=H(x)-x,这样即使F(x)趋近于零,网络层数的输出值也能保持和输入层的值相同,更不会出现F(x)对x的导数大于1的情况,有效防止了深层网络出现梯度消失或梯度爆炸。

图2 残差块Fig.2 Residual block
为了进一步提高目标识别的准确率,YOLOv3网络学习Faster-RCNN网络中的多尺度Anchor机制对目标进行检测。YOLOv3网络分别在3种不同尺度的特征地图(feature map,FM)感受野上进行目标的检测,以输入尺寸为416×416的图像为例,YOLOv3网络分别向下32倍、16倍、8倍采样,得到13×13、26×26、52×52的特征地图感受野,每一种感受野分别应用3种不同尺度的先验框,总共得到9种不同尺度的先验框。这9种不同尺度的先验框不仅能够在目标区域选出最优的两个边界框进行回归,而且可以有效提高小物体识别准确率。
1.2 双模态YOLOv3网络
单模态的YOLOv3网络在识别正常理想环境下目标的准确率较高,在识别光线昏暗条件下目标时,由于单一模态彩色相机对目标特征采集的缺失,网络卷积层不能提取到更多的目标特征信息,严重影响网络识别的精度。为了解决这个问题,本文在自动驾驶车辆的环境感知模块上增加另一个模态的红外热成像仪,此传感器能够采集目标特征的温度特征信息,是对彩色相机采集的颜色特征的补充。
在神经网络提取特征的过程中,浅层网络提取到的是目标边缘性的信息(如简单的颜色、竖直的线条、横向的线条等),到了网络的深层才会提取到图像上更深层次的特征,这个特征可以是图像上的某一部分或者是完全看不懂的特征。是否在特征网络最深层处进行融合才是最佳的融合方案是待商榷的问题。
为了将两种模态的特征信息相融合,本文提出了一种双模态的YOLOv3神经网络算法,该算法分别在彩色图像和红外图像上提取目标特征。如果昏暗条件下彩色图像上的目标特征缺失而红外图像上同一个目标特征明显,则神经网络算法就能够根据红外图像识别出该目标,得到预测的目标分类置信度值和BBOX值,并将结果同时绘制在两个图像上,该网络结构如图3所示。首先,双模态YOLOv3网络的主干网络与其他网络结构不变,只是将网络的输入改为416×416×3的彩色图像与416×416×3的红外图像,其次利用Darknet-53分别提取双模态图像上的目标特征,然后在预测层之前将提取到的特征相融合,最后输入到网络分类对图像上的目标进行分类。
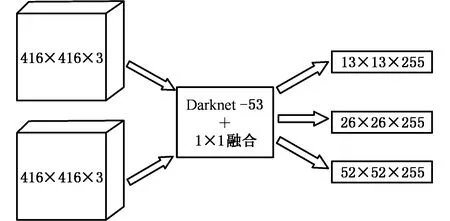
图3 双模态YOLOv3网络结构简图Fig.3 Dual YOLOv3 structure diagram
由于YOLOv3神经网络的主干网络会输出3个特征图用于后续的分类,所以为了得到同一个目标的预测信息,必须在3个特征图输出之前进行特征的融合,为此设计了3种融合模型。为了对比这3种模型,本文又增设了1种最浅层融合的模型。
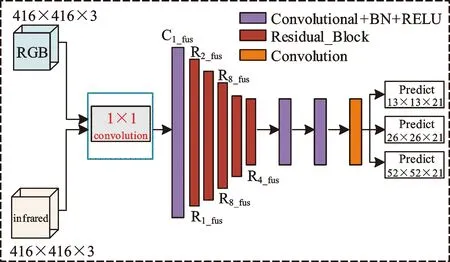
图4 模型一Fig.4 Model one
模型一在主干网络的第1层进行融合函数与1×1的卷积,如图4所示。双模态数据集输入到双模态YOLO v3网络算法中的矩阵维度为number×channels×height×width。双模态YOLO v3网络算法首先利用tf.concat函数将两个模态的数据集图像进行简单的线性叠加,相当于将红外模态3通道的数据集叠加到彩色数据集3通道之后,类似于变成了6通道的数据集。然后,将叠加后的6通道的数据集经过3个1×1×6卷积核函数的特征提取与激活函数,输出图像矩阵的维度为number×3×height×width。每一个1×1×6的卷积核进行图像特征的提取时,1×1×6卷积核分别与图像上某个局部区域的1×1×6的局部矩阵进行加权求和,局部区域加权求和后输出的矩阵维度为1×1×1,单个图像上加权求和后的矩阵维度为1×height×width。卷积操作后,图像输出矩阵维度为number×3×height×width,接下来进行原主干网络的52层特征提取的操作。融合后,将所有特征继续输入到主干网络接下来的卷积层中进行特征提取,并且输入到分类层进行3种尺度感受野的目标预测。在网络训练过程中同样采用反向传播更新参数的算法,由网络的最后一个预测层逐层向前更新参数。
模型二将双模态的数据集同时输入到主干网络Darknrt-53中进行特征提取,主干网络分别提取到图像上部分特征之后,在主干网络的第26层进行1×1的卷积融合,即在第一个特征图输出之前进行融合,如图5所示,其中,下标rgb表示彩色图像,下标T表示红外图像。在此模型中,本文首先利用主干网络的前25层分别提取两个模态图像上的特征信息;然后在26层将两个特征图的通道数相叠加,经过前25层卷积后,两个数据集的特征图输出都为number×52×52×256的矩阵,执行完tf.concat函数后,特征图输出为number×52×52×512,在26层进行1×1卷积核的加权求和后,特征图输出为number×52×52×256的矩阵,这是主干网络的第一个特征图的输出矩阵;最后将融合后的输出矩阵输入到主干网络剩下的卷积层中继续进行特征提取。
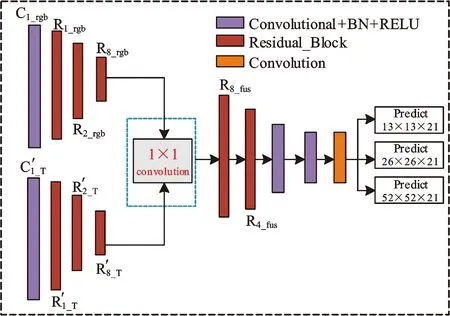
图5 模型二Fig.5 Model two

图6 模型三Fig.6 Model three
模型三在主干网络的26层和43层融合,即在前两个分类层之前融合,如图6所示。将双模态的数据集输入到网络算法中进行从浅层边缘特征到深层语义特征的提取,由于网络算法在第26层后就要输出number×52×52×256的特征图,并且经过一系列卷积操作后要在此特征图上进行目标的分类,为了对同一个目标进行分类,所以必须将两个模态的特征在26层进行第一次1×1融合,将融合后的特征图输出后,与模型二不同的是,这里并没有将融合后的特征输入到主干网络剩下的卷积层中进行特征提取,而是继续分别提取双模态数据集各自的特征,直到网络在43层进行第二次1×1融合,输出第二个number×26×26×512的特征图。此后,将二次融合后的特征也重新输入到网络的主干网络的卷积层中进行特征提取和最后一个number×13×13×1024特征图的输出。
模型四主干网络分别提取红外图像和彩色图像的整个特征,并且在每一个分类层之前相融合,如图7所示。由于网络会有3个不同尺度大小特征图的输出和后续的分类操作,所以为了预测同一个目标的分类,需要在每一个特征图输出之前进行融合,即双模态数据集输入到网络算法中,进行浅层边缘特征与深层语义特征提取之后,分别输出它们第25层、42层、51层的特征图。此模型没有执行融合操作,只是简单进行单模态特征提取操作。输出的特征图在分类卷积操作之前进行融合操作,执行三次tf.concat函数与1×1卷积融合操作,完成分类层之前的特征融合。
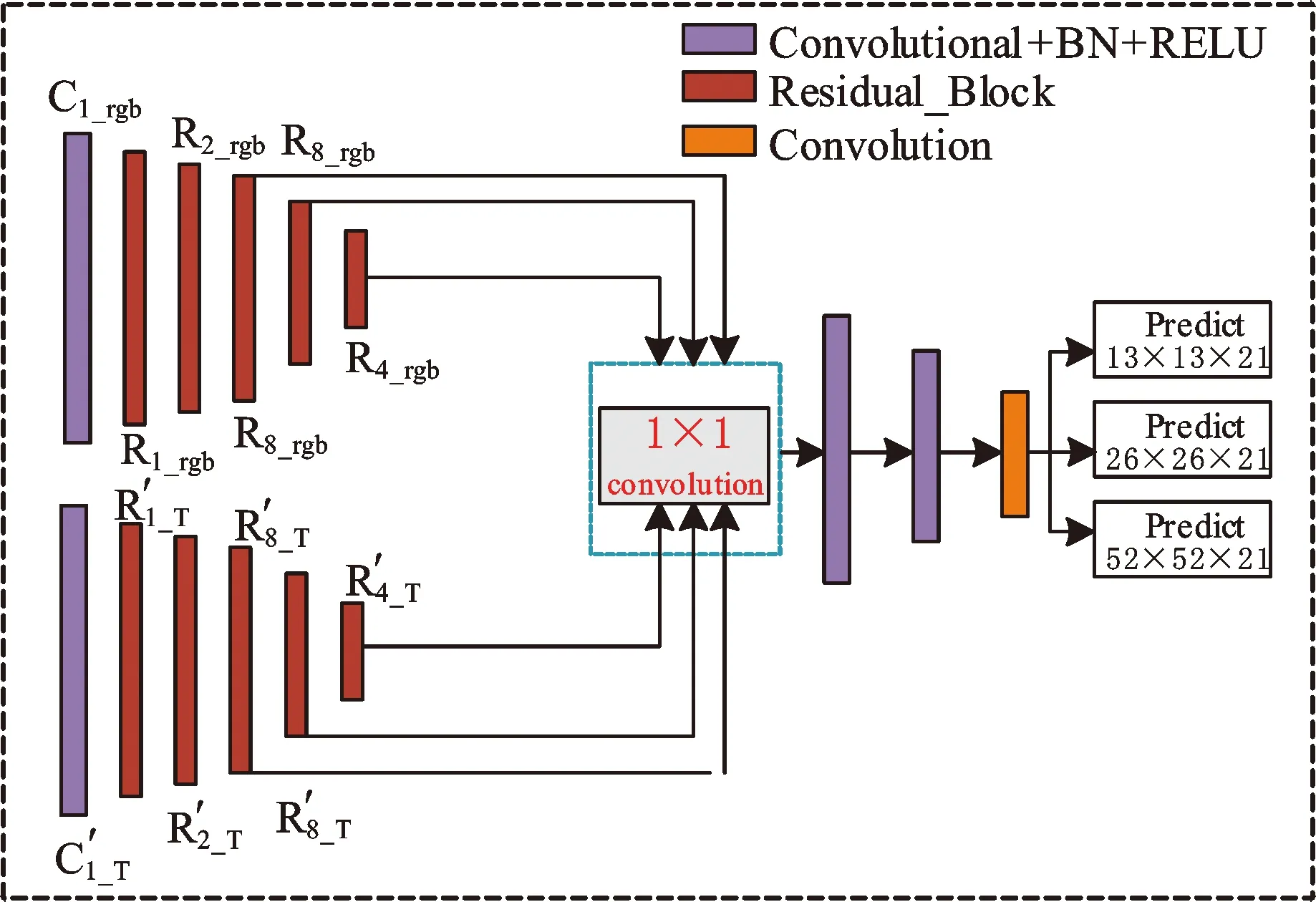
图7 模型四Fig.7 Model four
为了对比这4种不同主干网络模型的优劣,本文选取训练集损失(train loss,Tra-loss)、验证集损失(valid loss,Val-loss)与不同类别的平均精度(mean average precision,mAP)这三个指标进行评价。在计算每一类标签的平均精度时,不仅可通过目标置信度是否大于阈值来判断目标识别的准确性,还可通过预测出的BBOX与真实BBOX之间的交并比(intersection over union,IOU)来确定目标定位的准确性,即如果存在网络预测的目标分类正确,但是目标定位偏离真实的定位,依然认为此预测值是不正确的。
2 数据集
2.1 数据集的采集与配准
目前,网络上有很多开源的数据集,如COCO、Pascal VOC、KITTI等,但这些都是单模态的彩色图像,红外图像的数据集很少。为构建用于双模态YOLOv3网络训练和测试的红外图像与彩色图像对,本文自主搭建了彩色和红外数据集的同步采集系统,如图8所示,彩色相机与红外热成像仪的像素数为640×480。数据集共15 475对,其中,昏暗条件下的数据5881对,正常场景下的数据9594对,只有红外图像上有目标特征的数据1058对。

图8 双模态数据集同步采集系统Fig.8 Dual data set synchronous acquisition system
由于双模态网络算法能够只根据一个模态图像上的目标特征预测出目标的分类,然后分别绘制在两个模态的图像上,而一个图像上通常会有很多个目标,所以同一个目标必须出现在两种模态图像上的同一位置。为了配准彩色图像与红外图像,数据集同步采集系统必须在时间与空间上实现同步,才能进行信息的融合。
空间上的同步就是要得到同一个目标在三维空间内坐标系、彩色相机坐标系和红外相机坐标系之间的旋转平移矩阵,此旋转平移矩阵为外参。彩色相机成像原理与小孔成像类似,即彩色相机坐标系与彩色图像坐标系之间也存在坐标转换,类似地,红外相机坐标系与红外图像坐标系之间也存在坐标转换,此类坐标转换矩阵为内参。得到相机的内外参就能实现红外图像与彩色图像之间的配准。由于相机存在一定程度上的畸变,故在标定相机内参时还需要去畸变。设点在彩色相机坐标系中的坐标为[xlylzl]T,对应的红外相机坐标系中的点坐标为[xcyczc]T,则有
(1)
R和T为红外相机坐标系相对于彩色相机坐标系的旋转与偏移矩阵。该点最后成像到像素中的坐标为[uv]T:
[uv1]T=KPc=K(RPl+T)
(2)
式中,K为相机内参。
常见的相机标定方法是张正友标定法,由于红外相机只对温度较敏感,传统的张正友标定法不能标定,为了解决这个问题,本文分别在双模态图像上对应位置选取7个角点,计算出H矩阵,得到双模态图像对之间的旋转与平移矩阵,通过旋转与平移矩阵就能得到配准好的双模态图像对,如图9所示。

图9 配准好的双模态图像对Fig.9 Registered dual image pairs
2.2 数据集的标记与训练
为了标定双模态数据集,本文自主研发了双模态图像标记系统,如图10所示。将已经配准好的图像上传到系统中,就能进行标记,标记时只需要在一个模态的图像上框出目标,选取对应的标签,在另一个模态的图像对应位置上就会出现相同的框和标签。本文中设置person、vehicle、transport-vehicle三类标签。将数据集输入到双模态网络中进行训练,标记得到的框和标签作为真实值与网络输出的预测值进行比较。
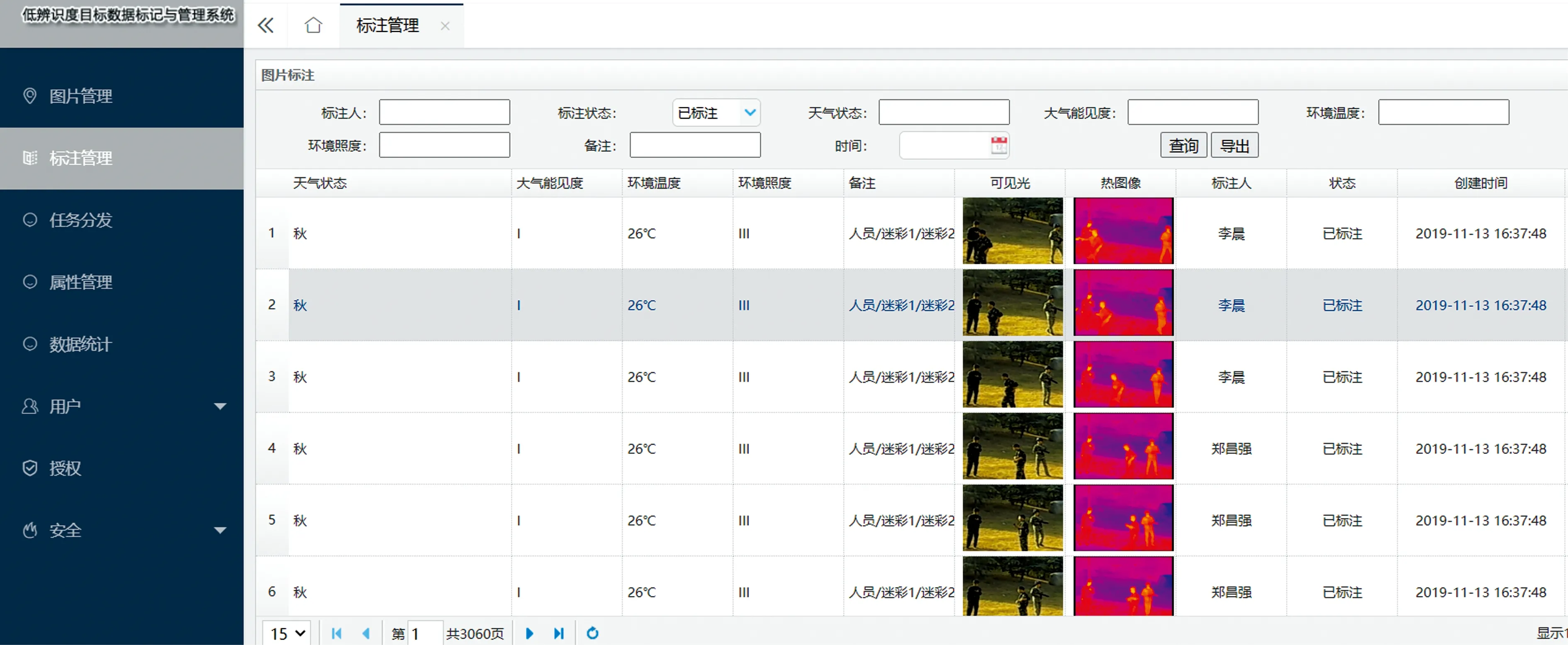
图10 双模态图像标记系统Fig.10 Dual image labeling system
在网络训练时,为了得到更好的网络参数,将13 543对数据进行训练,1502对数据作为网络的验证集,验证网络参数的同时微调参数值。本文一次训练所选取的样本数(Batch Size)为2。在网络训练过程中,由于数据集数目较大,若一次性地将数据集输入到神经网络中训练可能会引起内存爆炸,而且如果将整个数据集输入到网络中进行反向计算,得到的梯度计算值差距巨大,网络不能使用一个全局的学习率进行参数的优化。增加Batch Size能够通过并行化提高内存的利用率,并且使得梯度的下降方向更加准确。
3 实验结果
为了对比4种网络模型参数的优劣,本文对同一批数据集进行30个迭代次数的训练,前20次迭代的学习率为10-4,后10次迭代的学习率为10-6,得到每个模型不同批次的损失值,4种模型的Tra-loss损失曲线见图11,Val-loss损失曲线见图12。由于第一批训练集的损失值与第二批的损失值相差太大,故舍弃第一批的值。由图11和图12可以看出,网络在训练30个批次后,第二个模型的训练集损失值和验证集损失值梯度下降最快,并且在第30个批次损失值最小。
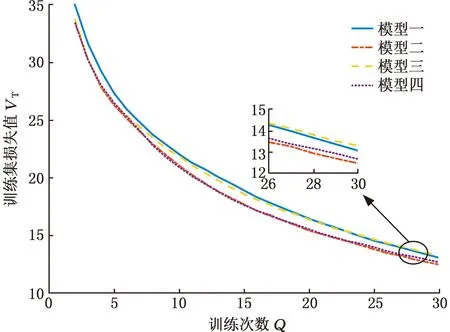
图11 训练集损失值Fig.11 Training set loss
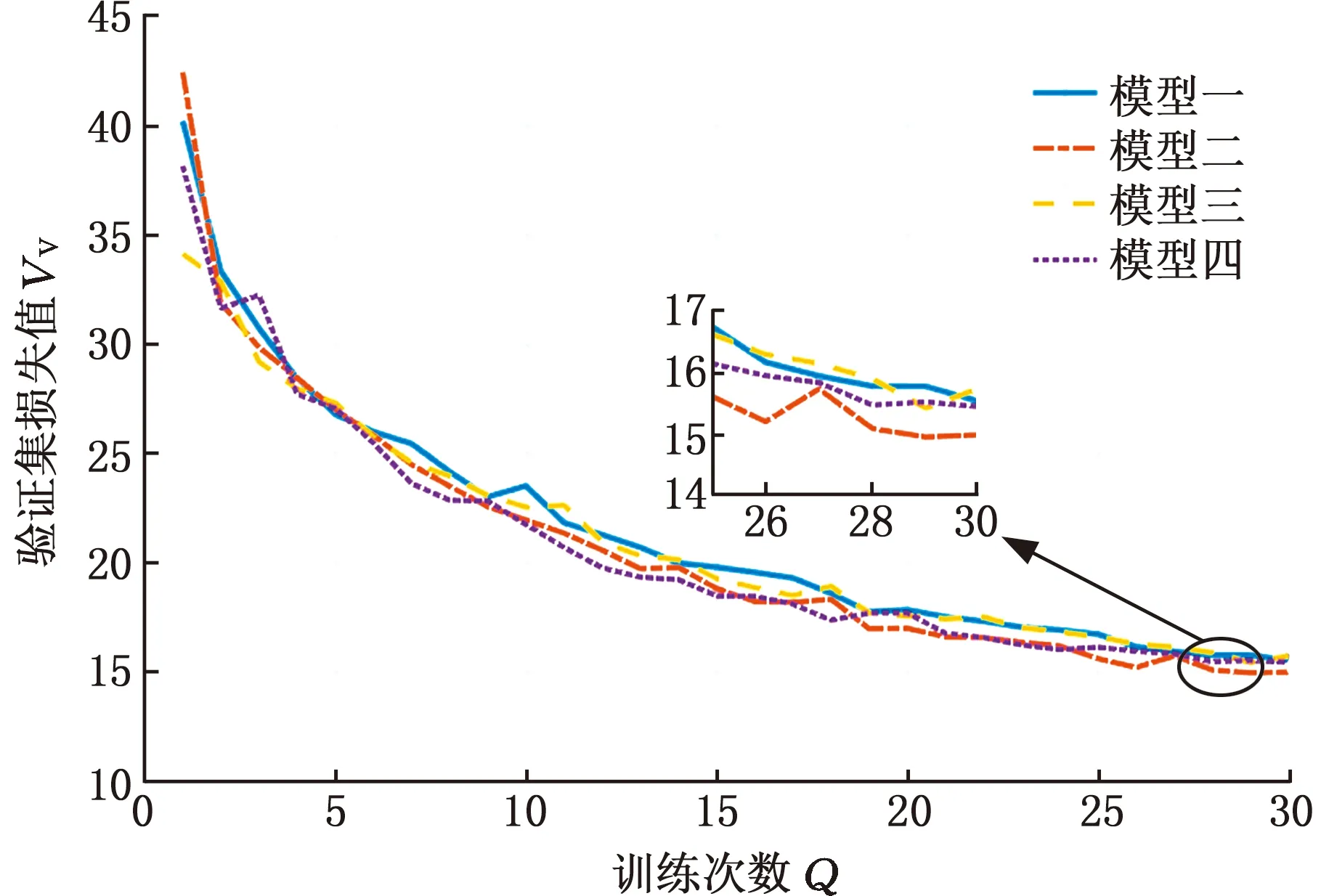
图12 验证集损失值Fig.12 Validation set loss
在计算网络的mAP值时,本文选取两种不同的阈值mAP_3与mAP_5,mAP_3即阈值设定为0.3,mAP_5即阈值设定为0.5,4种网络模型得到mAP_3与mAP_5的值如表1所示。4种网络模型在mAP_3与mAP_5下预测验证集中正确标签的数量与错误标签的数量如表2与表3所示。由表1可以看出,模型二在mAP_3和mAP_5上明显优于其他3个模型,在仅训练30个批次后,模型二的mAP_3能达到59.42%,mAP_5能达到51.61%。

表1 4种模型在不同阈值下的平均精度值
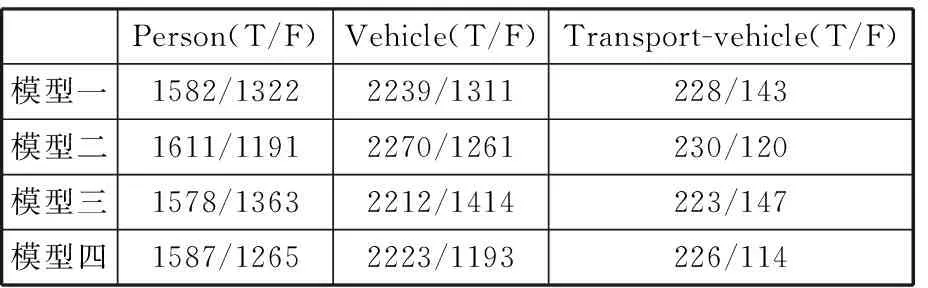
表2 4种模型在mAP_3下预测正确标签与错误标签的数量
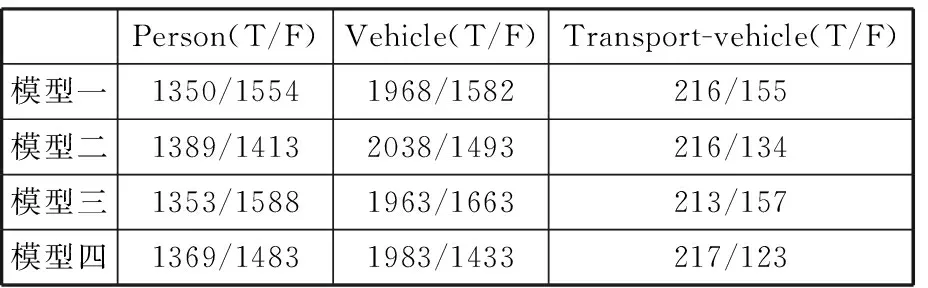
表3 4种模型在mAP_5下预测正确标签与错误标签的数量
由表2和表3可以看出,在阈值设定为0.3与0.5两种情况下,模型二对三类标签识别的准确数量均为最多。
单模态YOLOv3网络对部分光线昏暗条件下人员、车辆识别的结果见图13。双模态模型二网络对上述光线昏暗条件下车辆、人员识别的结果见图14。

图13 单模态网络识别结果图Fig.13 Recognition map of single-modal network

图14 双模态网络识别结果图Fig.14 Recognition map of dual network
由上述单模态与双模态网络的识别结果图可以看出,双模态网络能够识别出距离较远处的目标、受到周围环境中物体遮挡的目标、与环境对比度极低的目标,因此,双模态网络比单模态网络拥有更好的检测精度。
4 结论
为了提高低辨识度环境下人员、车辆识别的准确率,本文以光线昏暗的低辨识度条件为例,提出了一种利用彩色相机和红外热成像仪同时检测自动驾驶目标的方案。为了融合彩色相机采集到的颜色特征与红外热成像仪采集到的温度特征,本文在单模态YOLOv3网络算法的基础上将网络改进为双模态的网络算法。为了对比多种特征融合方案,本文还提出了4种主干网络的改进模型。通过对比4种模型的Tra-loss与Val-loss值、mAP_3与mAP_5值、不同阈值下对3种标签预测的正确和错误的数量,得出模型二最优的结论,即在主干网络第26层融合,第一个分类层之前融合效果最好,准确率最高,其mAP值最高可达59.42%。
