联合注意力和自编码器的协同过滤推荐
2021-05-26郑诚,王建
郑 诚,王 建
安徽大学 计算机科学与技术学院,合肥230601
随着互联网的高速发展,信息也随之呈现出了一种爆炸式增长的态势,用户期望在电子商务、娱乐和社交媒体上获得个性化的内容,但信息过载的问题使其变成一个难以满足的要求。为了让用户在信息爆炸的时代获得个性化的内容,大量的研究者、学者、相关企业对这一问题展开了研究,推荐技术由此迅速得到发展。
目前的推荐算法主要有协同过滤推荐,基于深度学习的推荐、混合推荐等。其中,协同过滤推荐是应用较为广泛的一种推荐算法[1]。它的核心思想是兴趣相似的用户之间相互进行推荐。
协同过滤算法大致可以分为两类:一类是基于内存的协同过滤算法,通过计算用户与用户或物品与物品之间的相似性来进行推荐;一类是基于模型的协同过滤算法,通过各种模型来恢复已知评分,同时预测未知评分。基于内存的协同过滤根据度量的对象不同可以分为基于用户的协同过滤和基于物品的协同过滤。前者主要通过计算用户与用户之间的相似度,来为目标用户推荐与其相似度很高的用户曾经交互过的但目标用户未曾交互过的物品[2];后者主要计算目标物品与用户交互过的物品的相似性来判断是否要将目标物品推荐给用户[3]。两者的核心都在于相似度计算,早期采用诸如余弦相似度和皮尔逊相关系数等来计算相似度,但这样的相似度计算方式所得到的结果并不理想。随后,Ning等人提出了SLIΜ(Sparse Linear Μethod)模型[4],该模型通过评分矩阵来训练相似度矩阵;Κabbur 等人提出了FISΜ(Factored Item Similarity Μodel)[5]模型,该模型将目标物品表示为一个低维向量,用户交互过的物品表示为一个个低维向量,将两个向量的内积作为最终的相似度。随着深度学习的不断发展,对于物品之间的相关性的挖掘也同样与深度学习技术相融合[6]。同样,基于物品的协同过滤十分适合top-n 推荐[7-8],但是基于物品的协同过滤通过计算相似度等局部信息来进行推荐,并没有考虑到历史交互信息的全局结构,从而会降低推荐结果的精确性;其次,目标物品与不同的物品计算相似度,但不同历史物品对于目标物品的重要性是不一样的,物品与物品之间也存在着相似性的问题。比如,若目标物品为一部手机,那么用户历史交互物品若存在手机,那其权重应该是较高的。因此相似度结果上应该考虑到权重的问题。
基于模型的协同过滤主要将历史交互数据在相应的模型上进行训练最后进行推荐。矩阵分解作为基于模型的协同过滤的一个实现被广泛应用于推荐系统中。矩阵分解的思想来自于SVD(Singular Value Decomposition)分解,Simon 提出Funk SVD 确定了将历史交互数据分解成两个小矩阵,随后,由于矩阵分解在捕获更深的交互上的不足,提出了NCF(Neural Collaborative Filtering)[9]、DeepCF(Deep Collaborative Filtering)[10]等模型。基于模型的协同过滤除了与矩阵分解相结合,还与各种模型诸如聚类模型、回归模型等相结合。近几年,随着深度学习的快速发展,基于模型的协同过滤与神经网络模型[11]相结合更是取得了不错的效果。然而,基于模型的协同过滤是从整体角度去使用用户和物品的交互数据,捕获了交互数据的全局信息,但对于局部依赖信息的利用是完全忽视的,从而没有利用局部信息对于最后推荐的准确度的提升和加强推荐结果的可解释性的作用。
两类协同过滤算法都是从某一个方面来利用用户和物品的交互信息,但两者对于交互数据的利用都存在着各自的缺陷,并且用户和物品的交互数据无论是对于隐式数据集还是对于显式数据集,相比于庞大的交互数据而言,都是稀疏的。因此,想提高推荐的性能,对于稀疏的交互数据,应该多方面地利用用户和物品的交互数据。
基于此,本文提出了一个混合了注意力机制和自编码器的协同过滤推荐模型。该模型同时结合了基于模型的协同过滤、基于物品的协同过滤的思想,从两方面来挖掘利用用户和物品的交互数据,从而同时捕获了全局信息和局部信息,随后将两方面的结果融合在一起,从而弥补了各自的缺陷,提升了推荐的性能。注意力网络用于为用户不同的历史交互物品和目标物品的相似度计算分配不同的权重,以解决用户历史交互物品对于目标物品重要性不一致的问题。
本文的贡献:在协同过滤推荐里面,基于模型的协同过滤方法诸如矩阵分解应用比较广泛且主要用于全局偏好的构建但忽略了局部信息,基于内存的方法诸如基于物品的协同过滤专注于局部信息挖掘却忽视了全局信息且应用较少,但两者各自有对应的优点以及缺点。因此本文通过一个深度学习架构将两者结合起来,克服各自的缺陷,同时结合两者的优点,在数据稀疏的数据集里也可以产生效果良好的推荐。
1 相关工作
1.1 基于物品的协同过滤
基于物品的协同过滤预测目标用户u 对目标物品i的偏好分数ŷui,是将目标物品与目标用户交互过的物品之间的相似性作为权重与目标用户的历史评分相乘,最后整体相加获取:

其中,N(u)表示用户的历史交互物品集合,ruj表示用户对不同的历史交互物品的偏好。
1.2 自编码器
近年来,深度学习高速发展,推荐系统不可避免地与之相结合,其中自编码器广泛应用于推荐系统领域。
Sedhain 等人提出的AutoRec[12]模型首次将自编码器模型与推荐系统相结合,并取得了不错的效果。自编码器模型大致分为三部分:编码层、隐藏层以及解码层。数据从编码层到隐藏层,在该层中,推荐系统可以利用该层所生成的用户或物品的低维向量表示,最后用户或物品的低维向量表示从隐藏层到解码层来重新拟合数据。自编码器与推荐相结合的研究一直在不断地进行。Li 等人提出一个将自编码器与协同过滤相结合的框架[13];Wang 等人将一个叠加自编码器整合到概率矩阵分解中以提升推荐的性能[14];Wu 等人将降噪自编码器与协同过滤相结合用于评分预测[15];Liang 等人将变分自编码器应用到推荐中,达到了很好的效果[16];Zhang等人使用压缩自编码器学习物品的特征,然后将其与经典推荐模型SVD++相结合更进一步提升了性能[17]。
1.3 注意力机制
最近,注意力机制在计算机视觉、自然语言处理等领域引发了众多关注。注意力机制可以对输入的数据过滤掉某些无用信息,减少噪声数据的副作用,并且可以加强某些信息量大的数据的权重。在推荐系统中应用注意力机制可以为不同的用户与用户、物品与物品之间分配权重,从而可以获取代表性较高的用户对或物品对,提高推荐结果的可解释性。注意力机制的核心在于对权重的计算,一般来说,各部分的权重通过一个神经网络来计算。推荐系统与注意力机制相结合的研究近年来也在不断进行。Liu 等人提出一个DAΜL(Dual Attention Μutual Learning)模型[18],该模型使用一个双重注意力来提取用户,评论潜在特征的相关性以提高最终评分预测的性能。Chen等人提出了共同注意力多任务学习模型以提高推荐的可解释性[19]。Xi等人利用BP神经网络来了解目标用户及其邻居的复杂关系,用注意力机制捕获每个用户对所有最近目标用户的总体影响来进行推荐[20]。Jhamb等人提出使用注意力机制来改善基于自动编码器的协同过滤的性能[21]。
2 融合注意力和自编码器的推荐
本章将详细阐述联合注意力机制和自编码器的协同过滤推荐模型(Attention Autoencoder Collaborative Filtering,AACF)。该模型分为两部分:一个是用于挖掘用户整体偏好的自编码器部分:另一个是用于挖掘物品与物品之间局部依赖的融合了注意力机制的基于物品的协同过滤模型。最后将两部分所得结果相融合,并利用相应的损失函数来对模型进行训练。融合注意力机制的基于物品的协同过滤模型与自编码器模型整体的流程如图1所示。
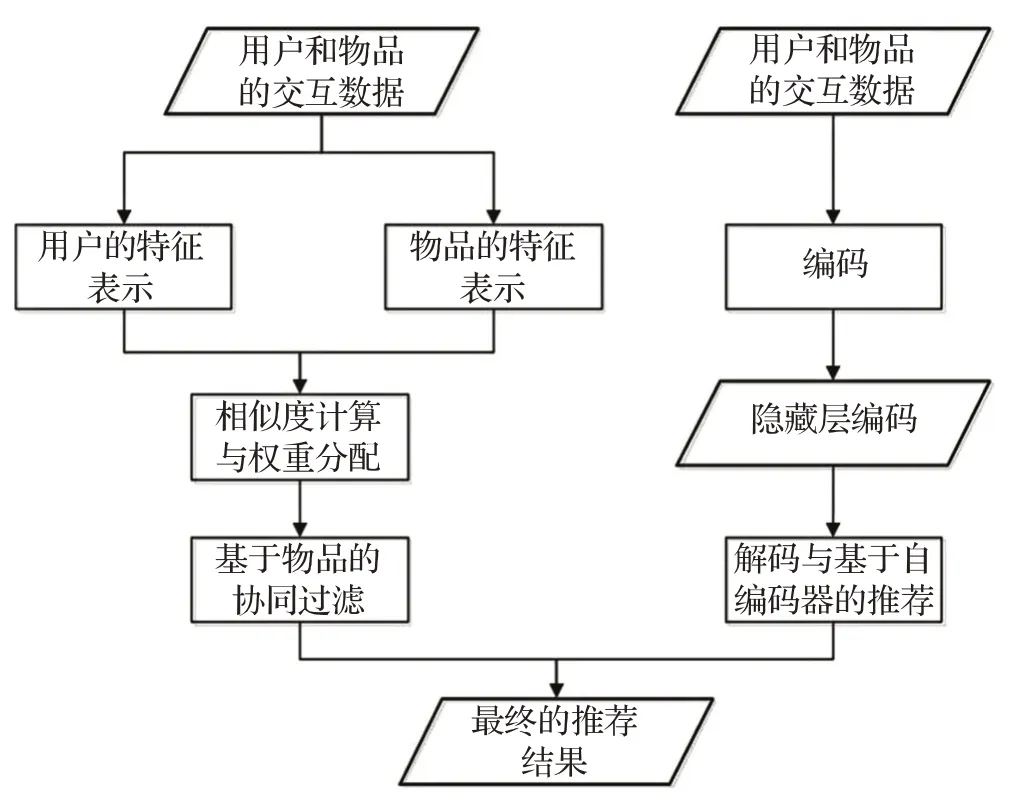
图1 融合注意力机制和自编码器的推荐
2.1 融合注意力机制的基于物品的协同过滤
通过基于物品的协同过滤思想来挖掘物品与物品之间的局部依赖关系,同时采用注意力网络来为用户不同的历史交互物品和目标物品的相似度计算分配不同的权重。
假设用户和物品的历史交互信息用矩阵Rm×n表示,其中m 表示用户的数量,n 表示物品的数量。


图2 融合注意力机制的基于物品的协同过滤
传统的基于物品的协同过滤通过用户曾经交互过的物品与目标物品的相似度来拟合数据,但考虑到对于目标物品而言,不同的历史交互物品对其的重要性也即权重是不一样的,因此,这里引入attention机制,从而为其自动分配权重。
该模型利用物品与物品的向量计算来获得相似度分数,最终拟合数据:


该模型中,注意力网络使用一个多层感知机来实现:
f(pi,qj)=hTReLU(w(pi⊙qj)+b)
其中,wk×d、bd×1分别代表注意力网络中输入层到隐藏层的权重矩阵和偏执项,hT代表隐藏层到输出层的权重向量。在注意力网络中使用历史交互过的物品与目标物品的向量表示作为输入,是为了防止物品i 和物品j 就算没有共现过也能计算相似度。最后将输出层的值送入一个softmax函数以让权重归一化:

其中,β 参数是用于防止softmax 函数过度惩罚活跃用户的权重,从而将其加入softmax 函数的分母来进行平滑,β 的取值范围是[0,1]。
2.2 融合自编码器的协同过滤
在这一部分,将用户与物品的交互数据输入一个自编码器,它通过重新拟合用户和物品的已知评分,以及拟合用户和物品未知的交互评分和来挖掘用户对物品整体偏好。
r̂=f(w2⋅g(w1r+b1)+b2)
内标元素选择的原则是质量数与被测元素相近,同时丰度高、无干扰。由于地质样品的复杂性,内标元素一般只用Rh、Re、Ir等少数几个元素。在线加入10ng/mL 187Re和103Rh混合内标溶液,选择103Rh为内标校正Ga、In、Cd、Ge,187Re为内标校正Tl,对各元素测定结果在30min内的相对标准偏差(RSD)进行了考察,并与校正前进行了对比,结果见图2。由图2可见,采用内标校正后,各元素测定结果的相对标准偏差介于2.1%~4.6%之间,相比较未加内标时的6.4%~12.3%有所改善。实验选取上述方法对测定结果进行校正。
在这个自编码器中,输入的是含有部分已知评分的用户特征表示,随后通过自编码器的编码、解码来估计出用户对物品的偏好信息。随后,将此用户对物品的偏好分数与通过基于物品的协同过滤思想得到的蕴含物品之间的依赖关系的偏好分数相融合,以此将用户偏好和物品依赖同时考虑进去。
2.3 融合层
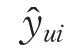
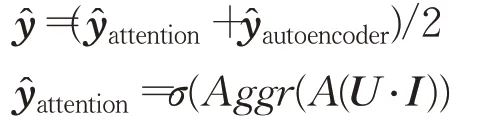
其中,σ 代表sigmoid 激活函数,而Aggr(⋅)是一个串联函数。U ∈Rs×d表示一个由固定的目标用户所交互的s 个物品的d 维向量表示构成的矩阵,I ∈Rd×n表示一个由n 个d 维目标物品的向量表示构成的矩阵,该矩阵的每一列代表一个目标物品的向量表示,两个矩阵相乘得到结果矩阵Ts×n,该矩阵的第i 列中每一维的值代表该固定目标用户所交互过的s 个物品分别与第i 个目标物品的向量乘积。 A ∈Rn×s代表权重矩阵,该矩阵的第i 行第s 列的值代表目标物品i 与固定的目标用户的第s 个历史交互物品的权重。最后获取权重矩阵A 与结果矩阵T 的对应行与对应列的乘积,即两个矩阵相乘结果的对角线的值。使用Aggr(⋅)串联对角线的值得到一个n 维向量,将该n 维向量送入如sigmoid 函数得到最后的拟合的结果:


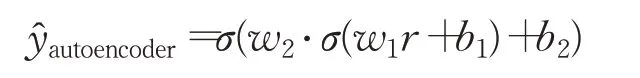
最后,将捕获局部依赖信息的基于物品的协同过滤拟合出来的评分,与捕获全局偏好的基于自编码器拟合出来的评分相加并平均,得到最终的拟合出来的用户偏好。
随后为了训练模型,受到文献[22]的启发,设计了一个基于铰链损失函数的目标函数:

3 实验及结果分析
3.1 实验设置
为了测试模型的效果,本文采用了两个来自不同领域的真实数据集:ΜovieLens1Μ和Pinterest。在ΜovieLens1Μ数据集中,保留那些至少有过5 次交互的用户以及物品,同时将评分大于或等于4的当作用户曾经有过交互的物品,其余就当作未交互过的物品。而Pinterest数据集中很多用户的交互次数过少,很难将其直接用于测试模型的效果,同时为了比较模型在不同稀疏度情况下的性能,因而对于该数据集保留那些至少有20 次交互的用户和物品。预处理过的数据集如表1所示。

表1 数据集信息
对于这两个数据集,采用留一法来划分数据集,将每个用户的最后一次交互当作测试集,其余均作为训练集来训练模型。
在关于推荐系统的评估指标中,采用命中率(Hit Ratio,HR)和归一化折扣累积增益(Normalized Discounted Cumulative Gain,NDCG)作为模型的性能评估指标,这两个指标广泛应用于Top-N 推荐中。
模型中的参数以均值为0,标准差为0.01 的高斯分布进行随机初始化,物品表示的嵌入维度设置从[8,16,32,64]依次取值,注意力网络的隐藏层维度如物品表示的嵌入维度一样设置,β 的值设置为0.5,λ 的值在ΜovieLens1Μ 数据集上设为0.001,在Pinterest 数据集上的值设为0.005,边际距离d 的值设置为0.15,自编码器中的隐藏层维度设置为160时,实验效果比较良好。
3.2 对比方法
为了更明确地评估模型的性能,将下面的方法与本文模型进行比较。
Pop:该方法主要根据物品的受欢迎程度对物品进行排名,是一种完全依靠物品的交互次数进行判断的基准测试方法。
ItemΚNN[3]:该方法是一个标准的基于物品的协同过滤方法,它通过余弦相似度来测量两个物品的相似度。
ΜF-BPR[23]:该方法是一个使用BPR(Bayesian Personalized Ranking)来优化的ΜF模型,以使得该模型可以从隐式反馈的数据中学习,在基于隐式反馈数据的协同过滤推荐中,是一个常用的基准方法。
U-AutoRec[12]:该方法是一个标准的将自编码器融入协同过滤进行推荐的模型。该模型基于用户的自编码器,将用户评分作为输入以学得物品与物品之间的关系。
CDAE[24]:该方法是一个基于降噪自编码器的模型,它与协同过滤推荐相结合,通过增强物品的潜在特征表示来增强推荐的性能,在Top-N 推荐中具有良好的效果。
FISΜ[5]:该模型是一个效果良好的基于物品的协同过滤方法,它将用户和物品分别用一个潜在特征向量进行表示,用内积来计算相似度。
3.3 实验结果
从表2 中可以看到AACF 模型在两个数据集上的表现均优于其余模型,这证明了AACF 模型的有效性,表明了从用户和物品的交互信息中挖掘用户整体偏好和物品局部依赖两方面的信息来提高推荐系统的有效性确实是可行的。FISΜ 模型与CDAE(Collaborative Denoising Autoencoder)相比,大体上CDAE 的效果好于FISΜ,表明了以自编码器为基础的预测模型相对于计算相似度的预测模型而言效果更好,AACF模型优于CDAE模型,表明了注意力机制在AACF模型中发挥了不小的作用。

表2 实验结果比较(embedding size=16)
此外,如表3所示,本文还探讨了SAE(Stacked Autoencoder)与注意力机制结合在ΜovieLens 数据集上的结果。

表3 不同的自编码器对模型的影响
堆叠自编码器相对于用户自编码器模型性能有所提高。该堆叠自编码器堆叠了两个自编码器,前一层自编码器的输出作为第二层自编码器的输入,从而起到了类似于预训练之类的效果,从而提高了模型的性能。
图3、图4 展示了在ΜovieLens 数据集上物品表示的嵌入维度对整体模型的影响。从图中可以看出,模型的效果随着维度的变大而逐渐提高,当嵌入维度从8提升至16,3 个模型的效果都有一个较大的提升,但嵌入维度从16提升至32、64时,3个模型的提升都较小,这表明,在嵌入维度为16时,模型的推荐效果到达了一个平均的程度。

图3 ΜovieLens1Μ数据集上的HR结果
图4 ΜovieLens1Μ数据集上的NDCG结果
图5研究了注意力网络中β 值在ΜovieLens数据集上,嵌入维度为16时对AACF模型的影响。

图5 β 值对AACF模型的影响
结果表明,β 值在[0,0.5]范围内模型的性能较好,而之后,随着β 值的变大,模型的性能变差。这是由于β 值越大,softmax函数的限制变小,会慢慢过度惩罚活跃用户,使得模型性能下降。
图6展示了AACF在ΜovieLens数据集上自编码器模块和注意力模块对模型总体的影响。
图6 自编码器模块和注意力模块对模型的影响
图中,AACF-Auto(AACF-Autoencoder)表示从AACF模型中去除自编码器模块后的模型,AACF-Att(AACFAttention)表示从AACF 模型中去除注意力模块后的模型。从图中可以看到,AACF模型相对于AACF-Auto和AACF-Att,结果是最好的,其中AACF-Auto的结果相较于AACF-Att 的结果又更好一点。可以说明,注意力模块对整体模型的影响更大,但自编码器模块对模型也存在着不可忽视的作用。
4 结束语
本文提出了一个联合注意力机制和自编码器的推荐模型,该模型将用户和物品的历史交互信息从用户整体偏好和物品局部依赖两方面进行挖掘利用。对于用户整体偏好,本文采用自编码器的思想,通过对历史交互信息整体编码解码的方式来拟合出用户和物品的偏好,而对于物品之间的局部依赖信息,首先通过注意力机制来为目标物品与目标用户交互过的物品之间分配不同的权重,两者向量表示的内积代表相似度,代表局部信息的挖掘。模型在两个真实数据集上的表现相比于基准方法有一定程度的提高。在未来的工作中,可以通过考虑加入其余辅助信息,诸如知识图谱、评论信息等来更近一步地提高用户和物品的嵌入表示,从而提高模型的性能。
