利用翻译模型的跨语言中文命名实体识别
2021-05-26孙凌浩
孙凌浩
中国科学技术大学 计算机科学与技术学院 中国科大-伯明翰大学智能计算与应用联合研究所,合肥230027
命名实体识别(Named Entity Recognition,NER)是序列标记任务的子任务之一,它将文本中具有特定意义的名词提取出来并分为不同的类别,如人名、地名、组织名等。命名实体识别是计算机理解自然语言的基础,准确地识别命名实体对于信息检索、情感分析、问答系统等应用领域问题具有重要帮助。目前最优的命名实体识别方法通常使用长短期记忆循环神经网络(Long Short-Term Μemory,LSTΜ)和条件随机场(Conditional Random Field,CRF)来预测序列标签[1]。
区别于英文命名实体识别的大量标注数据以及英文中前缀后缀对词性的重要指示作用,中文命名实体识别的难度较大,模型对于实体的识别能力相对较低。更为重要的是自然状态下的中文语料并没有对词语进行分割,实体边界的确定相对于英文也是一个挑战[2]。在数据量较小的数据集下,模型训练不充分,得到的结果对后续的实际应用带来了更大的困难。
将英文命名识别模型抽取的特征应用于中文时,存在两个难以处理的问题:首先,中英文中具有相同含义的句子的长度可能不同,并且单词在句子中的排列顺序通常不对应。如图1 所示,给定句子“美联储主席是鲍威尔”,英语和汉语之间的词语顺序是不同的,很难使用统一的规则确定中文句子中的字与英文中的词的对应关系。其次,中英语言之间同一个实体的标签可能不同。在图1 中,鲍威尔由一个英语单词(标注为S-PER)组成,而在中文中,鲍威尔由三个汉字表示(标注分别为B-PER,I-PER,E-PER)。即使两种语言间的对应关系找到,也不能直接在语言之间投影标签,因为同一实体在不同语言中的长度通常不同,这导致了不同的标注结果。因此,在两种语言之间交换信息存在一定困难。目前没有一个简单有效的方法可以将英文命名实体识别模型中抽取出的高层特征信息迁移到中文模型中,从而提高中文命名实体识别的效果。
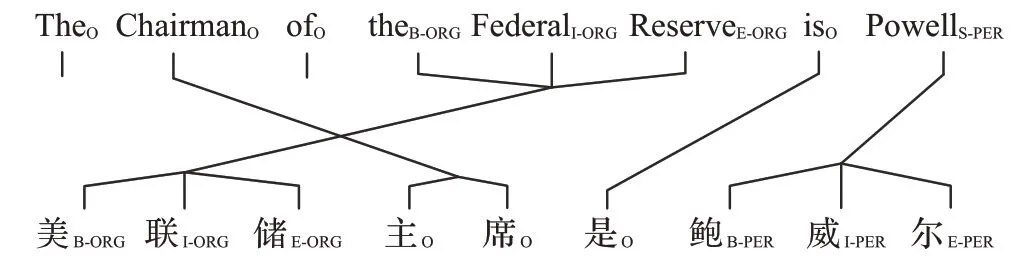
图1 中英平行语料命名实体识别中的对应关系
命名实体识别方法与动力学系统学习方法[3]具有相关性,其学习方法多样,包括基于集成学习[4-6]、统计模型[7-9]等。近年来,许多跨语言迁移学习方法被用于解决命名实体识别任务,已有的工作主要基于启发式方法在两种语言之间传递浅层信息[10-11],一些算法需要标记平行语料,这比单语言标记语料的成本更高,例如Che等[12]利用人工标记的语言间对应关系传递信息。一些算法利用不同语言底层的通用特征,例如Ni等[13]提出将不同语言词的分布式表示(词向量)投影到一个公共空间中,作为词的独立性特征。这些方法主要利用简单的规则映射或使用底层任务无关的通用信息,如词向量等进行信息增强。目前,也有方法尝试利用翻译模型建立不同语言之间的联系,例如Feng[14]利用翻译模型对单个单词进行翻译,并使用翻译后语言的词向量来丰富源单词的嵌入,单词的逐个翻译避免了语序不对应的影响,但单个单词的翻译会丢失单词的上下文信息。更重要的是以上方法并不能获取特定任务的专有信息,因此在命名实体识别任务上的迁移效果有限。
为了解决以上问题,本文提出了利用翻译模型的跨语言中文命名实体识别模型,该模型充分利用了从预训练的英文命名实体识别模型中提取的特征。本文算法利用基于注意力机制(Attention Μechanism)的Seq2Seq翻译模型中的编码器-解码器注意力权重,将英文模型的高层信息迁移到中文模型中。编码器-解码器注意力层的Global Attention 权重代表了翻译模型中源语言(中文)和目标语言(英文)之间的单词对应相关度[15]。由于单词对应关系在两种语言间的等价性,通过反向使用注意力矩阵,可以将英语预训练的命名实体识别模型抽取的信息转换到中文语言。相比于基于共享表示的方法[16-17],该模型利用预训练的英文命名实体识别模型抽取出的任务相关信息,通过编码器-解码器注意力矩阵转换到中文环境下,迁移效率更高,噪音更少,并且该算法不需要任何手工标注的特征和带有标签的平行语料。实验表明,提出的模型在OntoNotes 4.0[18]和Weibo NER[19]数据集上取得了较好效果,尤其是在数据量较小的Weibo NER数据集上效果有更显著的提升。
1 利用翻译模型的跨语言中文命名实体识别模型
利用翻译模型的跨语言中文命名实体识别模型整体结构如图2所示。
该模型利用基于注意力机制的翻译模型将中文译为英文,并保留包含中英文对应关系的注意力权重;预训练的英文命名实体识别模型抽取英文状态下的特征;将英文状态下的特征信息通过反向使用翻译模型中的注意力权重迁移到中文环境中,辅助中文命名实体识别。模型分为基于注意力机制的中文-英文翻译模块、预训练英文命名实体识别模块、信息增强的中文命名实体识别模块三部分。

图2 利用翻译模型的跨语言中文命名实体识别模型
1.1 基于注意力机制的中文-英文翻译模块
基于注意力机制的Seq2Seq 模型可以利用注意力机制在生成翻译结果时对每个翻译目标词进行有针对性的信息选择,使翻译结果更准确。同时得到的注意力权重可以表示翻译前后词语的相关性。该模块采用Gehring 等[20]提出的卷积Seq2Seq 翻译模型,模型如图3所示。
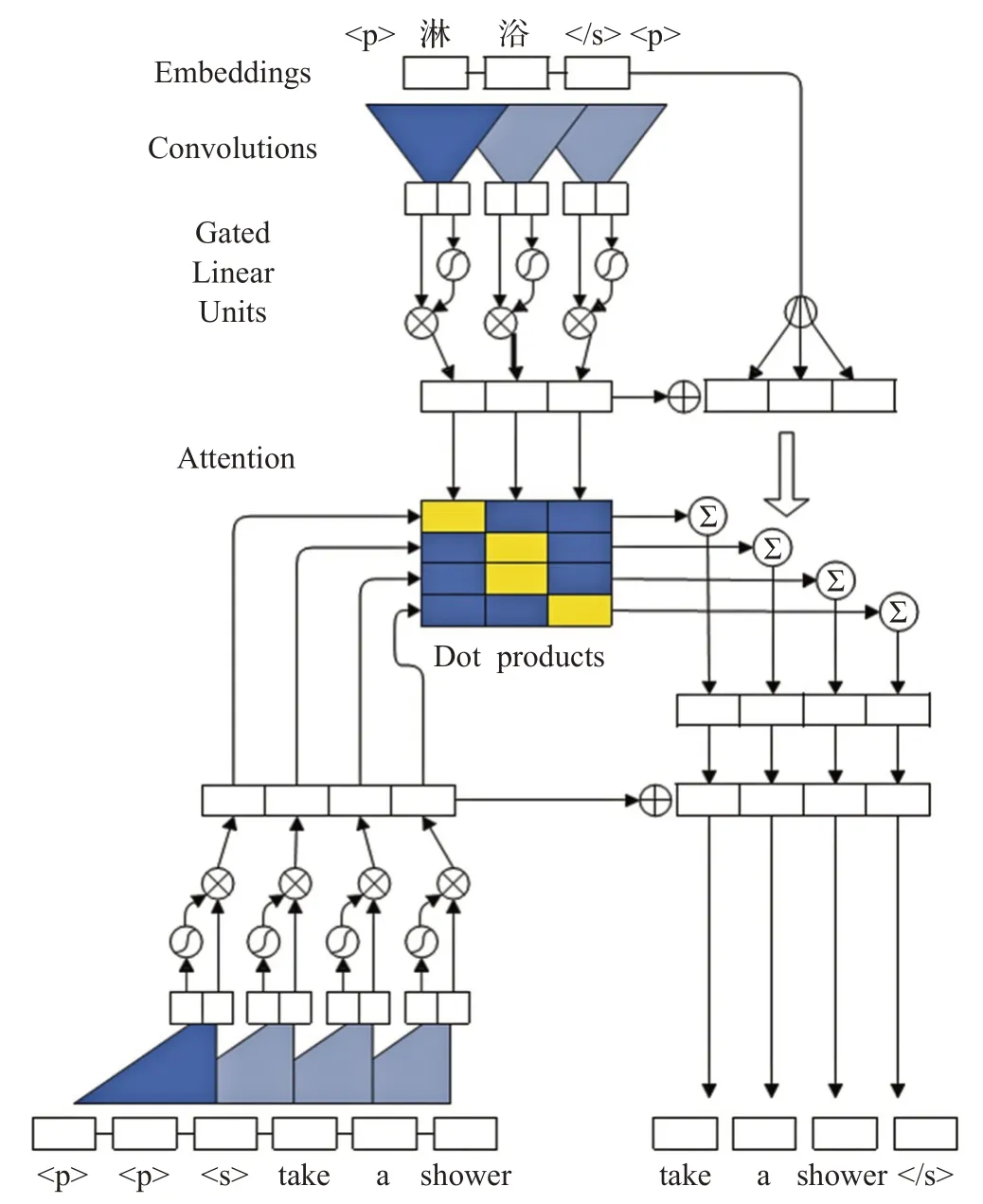
图3 基于注意力机制的翻译模型
该模块分为两部分:编码器和解码器。编码器的输入是词向量与位置向量的拼接,采用添加位置嵌入的方式来增加时序特征,之后通过卷积操作提取特征,再通过激活函数后生成编码器输出。编码器的输入输出如式(1)和(2)所示:



该模型训练过程中操作与普通的Seq2Seq 模型一致,由于采取卷积操作使模型可以并行,相比基于循环神经网络的Seq2Seq模型,训练速度大大加快。
1.2 预训练英文命名实体识别模块
BiLSTΜ-CRF命名实体识别模型是Huang等[1]提出的,之后的命名实体识别模型大多改进自该模型。本算法采用的预训练模块基于当前最好的英文命名实体识别模型[21],是由BiLSTΜ-CRF模型改进而来。与传统模型的不同之处在于,输入层部分采用字符级语言模型表征词向量,字符级语言模型为BiLSTΜ,如图4所示。

图4 字符级语言模型中得到的词嵌入示意图
模型选择每个单词正向LSTΜ 最后一个字符后一个位置的输出与反向LSTΜ 第一个字符前一个位置的输出组成词嵌入。以正向为例,选取正向LSTΜ最后一个字符后一个位置产生的输出包含从句子开始位置到当前位置的上下文信息。该模型与使用传统词向量的模型相比,使用语言模型可以动态表征词语在不同语言环境下的不同含义,使词向量根据单词在不同环境中的含义动态改变。
获得词嵌入wt后,将其输入到命名实体识别模型的BiLSTΜ层,该层分为两个方向,选取正向过程,公式如下:
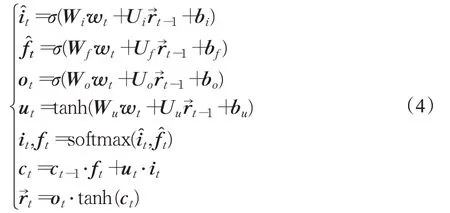

CRF 可以通过考虑抽取出的信息与输出标签之间的邻接关系获得全局最优标签序列[22]。因此,选择使用CRF作为最终识别层:

由于CRF层包含标签信息,而中英文环境下标签信息存在差异,本模型选择BiLSTΜ层输出当作英文状态下的特征信息Re=[r1,r2,…,rn],该特征信息包含了英文环境下抽取的语义信息与任务相关信息。
1.3 信息增强的命名实体识别模块


将迁移自英文状态特征矩阵T 转置后与中文状态BiLSTΜ层的输出Rc=[r1,r2,…,rl]按列拼接后得到:

F 包含中文环境下BiLSTΜ 抽取出的信息与英文环境下BiLSTΜ 抽取信息,将其作为一个新的CRF 输入。最终命名实体识别标签y 由CRF给出:

2 实验分析
2.1 实验数据
本文使用两个公开的中文命名实体识别数据集,分别是OntoNotes 4.0[18]和Weibo NER[19]。表1 展示了实验中使用的数据集的详细统计信息。
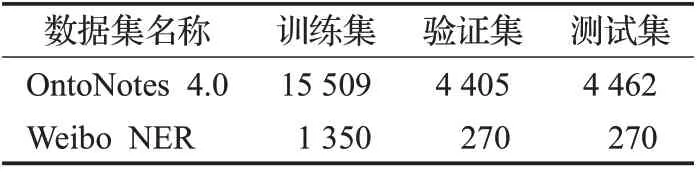
表1 数据集中句子数量统计数据
2.2 标注规范与评价指标
命名实体识别的标注规范存在BIO、BIOE和BIOES等多种形式。本实验使用目前应用最多的BIOES 标注模式,该模式标签一共13 种,分别是“O”“S-PER”“BPER”“I-PER”“E-PER”“S-LOC”“B-LOC”“I-LOC”“ELOC”“S-ORG”“B-ORG”“I-ORG”和“E-ORG”。
命名实体识别的评价标准一般为精确率(P)、召回率(R)和F1 值。具体定义如下:

其中,Tp为模型标注正确的实体个数,Fp为模型识别为实体但不是实体的个数,Fn为是实体但模型没有识别的个数。
2.3 实验设置
模型中的BiLSTΜ-CRF 结构采用PyTorch 框架实现,中文嵌入分别选择使用FastText 嵌入[24]与预训练中文BERT 嵌入[25],翻译模块由Fairseq 框架(https://www.github.com/facebookresearch/fairseq)实现,并且翻译模块在联合国平行语料库“汉语-英语语料库”上进行训练,预训练的英语命名实体识别模块采用Flair框架(https://github.com/flairNLP/flair)的英文命名实体识别模型。
2.4 参数设置
使用随机梯度下降法训练命名实体识别模型,设定训练上限为150 轮,采用学习率衰退算法,初始学习率为0.1,训练损失在3个连续的迭代周期内不下降,学习率衰退一半,学习率小于10-3停止训练。BiLSTΜ模型的隐层大小设置为256,BiLSTΜ 模型的层数为1 层。Batch size为16,单词嵌入Dropout为0.05。实验使用翻译模型Attention 层第一层和最后一层作为转换矩阵进行信息迁移,并在训练前生成全部迁移特征。该实验使用不同的随机种子并进行5次重复实验,选择测试集的平均结果作为最终结果。
2.5 实验结果及分析
为了验证算法的有效性,选择两种中文字嵌入在两个大小不同的数据集上进行实验。中文嵌入选择使用静态嵌入FastText 与基于BERT 的动态嵌入,Alingedfirst和Alignedlast分别表示模型使用基于第一层与最后一层Attention 权重迁移来的英文模型信息。OntoNotes 4.0命名实体识别实验结果如表2所示,Weibo NER命名实体识别实验结果如表3所示。

表2 OntoNotes 4.0命名实体识别实验结果 %
OntoNotes 4.0:表2 展示了OntoNotes 4.0 中文数据集上的实验结果。该数据集有人工标注的分词信息,Gold Seg和No Seg表示是否使用分词信息。现有的最好结果是Yang等[27]利用分词信息、离散特征和半监督学习实现的。基线模型(即Char+BiLSTΜ+CRF),由于未使用中文分词信息,模型在数据集上的精确率、召回率和F1 值相对较低。Char+BiLSTΜ+CRF 模型在无分词信息下的精确率、召回率和F1 值分别为69.51%、53.17%和60.25%。利用本文提出的算法,分别加入Alignedfirst和Alignedlast信息后,基准模型的性能从60.25%分别提高到67.15%和71.99%,说明英文模型提取出的信息对中文命名实体识别具有一定作用。为了进一步提升命名实体识别结果,本文使用预训练的中文BERT 模表示字嵌入。最优结果为BERT+BiLSTΜ+CRF+Alignedlast,在不使用分词信息的条件下,得到80.42%、82.02%和81.21%的精确率、召回率和F1 值,优于当前最好的算法。
Weibo NER:表3 展示了Weibo NER 中文数据集上的实验结果,其中NE、NΜ和Ovarall分别表示具体命名实体、泛指命名实体和全部实体。已有的最优模型[29]综合利用跨领域数据进行半监督学习。由于数据集较小,基准模型(即Char+BiLSTΜ+CRF)在使用静态Fast-Text 嵌入的条件下,在三种标注要求下的F1 值分别为32.35%、31.91%和32.18%。通过利用对齐的高资源语义特征,模型效果得到了显著的提升。在F1 得分方面,Char+BiLSTΜ+CRF+Alignedlast相对于基准模型Char+BiLSTΜ+CRF 在三种标注结果下的F1 值平均提高了30%,说明当模型使用的词向量表示能力较弱时,利用该方法可有效提高标注结果。利用预训练中文BERT模型生成字嵌入当作输入后,BERT+BiLSTΜ+CRF 模型在三种标注上的F1 得分别达到70.24%、68.51%和69.14%。加入迁移后英文模型信息Alingedfirst和Alignedlast,结果得到进一步的提升,在三种不同标注下,BERT+BiLSTΜ+CRF+Alignedlast的F1 值均取得最好,分别是72.16%、70.09%和71.28%。
2.6 不同Attention层对迁移信息的影响
从上面的实验可以看出,使用不同Attention层权重对英文NER 模型抽取信息进行迁移获得了不同的结果。本文进一步分析不同Attention 层权重获得的对齐特征对结果的影响,选择Weibo NER数据集,将微博数据集翻译成英文,记录神经机器翻译模型中全部注意力层的权重A1,A2,…,A15,通过公式T=A×RTe 得到了15个迁移到中文环境中的英文模型抽取特征,利用该特征的实验结果如图5所示。
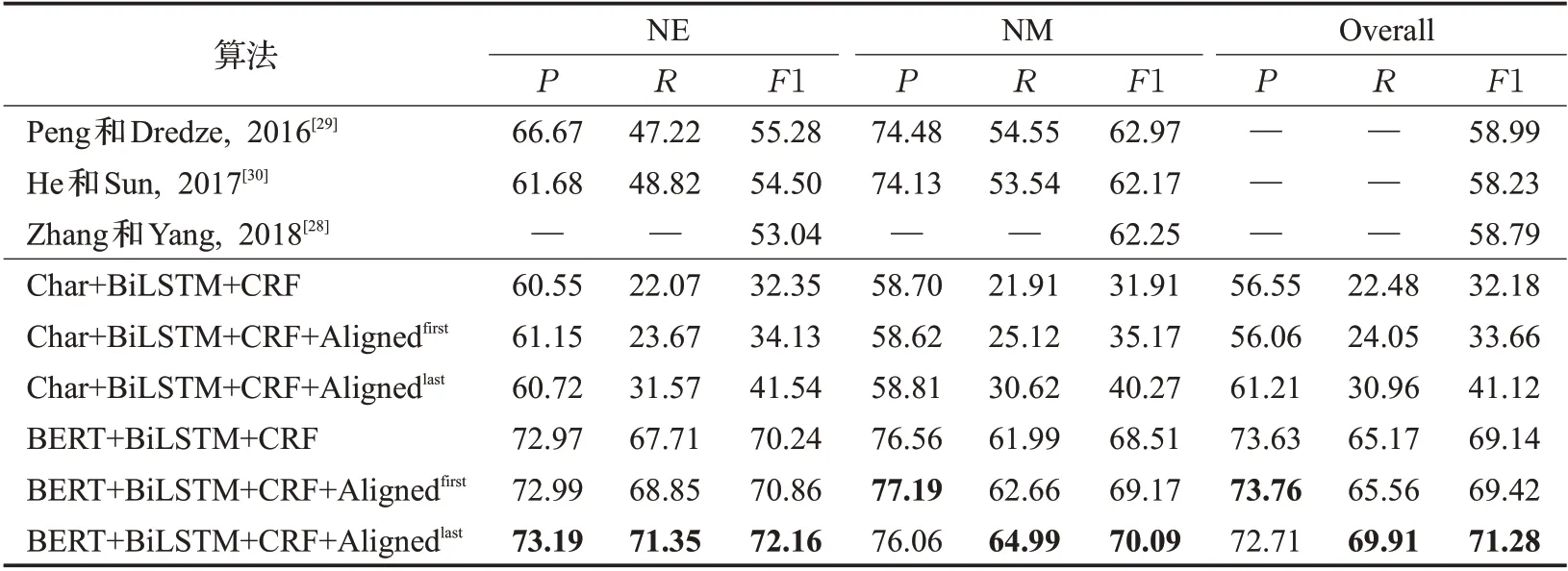
表3 Weibo NER命名实体识别实验结果 %

图5 利用不同注意力层迁移特征的结果对比
图5 显示了利用不同编码器-解码器注意力层权重获得不同的迁移特征后,算法通过不同的迁移特征获得的F1 值。实线表示使用预训练BERT 嵌入的模型结果,虚线表示使用FastText 嵌入的模型结果。从图5 中可以看出使用更深层的注意力层权重当作转移矩阵可以获得更好的效果,在使用第八层或更高层注意力权重时性能达到稳定。本文提出的算法通过反向使用翻译模型中的注意力权重将英文模型抽取出的特征进行迁移,使英文预训练的模型抽取出的命名实体识别相关特征有效地辅助中文命名实体识别。而且高层注意力可以捕获更深层次的语义依赖关系,具有更精确的对齐效果,从而使识别效果提升更加明显。
3 结束语
本文力求通过使用语言较为简单且训练语料丰富的英语命名实体识别模型来提高中文命名实体识别效果,通过反向使用翻译模型注意力机制来实现这一目标。反向使用注意力权重,利用其包含的语言间单词对齐信息,将预训练模型中的高层特征从英文环境迁移到中文环境。实验表明,本文提出的算法可以提高模型识别能力,特别在小数据集上的提升更为明显,表明算法对于实际任务中在标注数据不足的情况下的实体识别具有重要意义。此外,本文还研究了翻译模型中多层解码器中不同的注意力权重对迁移英文模型抽取信息的影响。在下一步的工作中,希望能将此方法扩展到其他自然语言处理任务中,例如关系抽取和指代消解,从而解决更多数据不足的实际问题。同时研究将数据转化为函数空间[31-33]的方法与神经网络结合,共同解决自然语言处理任务。
