基于信息扩散视角的虚拟社区用户影响力研究
2021-05-26周艳菊
卢 开,周艳菊
中南大学 商学院,长沙410000
基于各类社交媒体形成以用户生成内容(User Generated Content,UCG)为主要信息传播方式的虚拟社区,成为群众聚集的新场所。依赖于品牌依恋、人际依恋和社区依恋三大情感动机,虚拟社区用户形成稳定的信息共享与相互影响机制[1],这使得以虚拟社区为主要传播媒介,以“领导型”用户为信息扩散中心的网络营销(Online Μarketing)开始流行,也为新零售时代的到来创造了有利条件。
虚拟社区运营的核心是“人”,意见领袖们对信息的传播和导向、群体行为的形成和发展等方面都起到重要作用[1],而意见领袖们的领导能力通常用影响力来度量。用户之间存在的社会影响(Social Influence),促使其行为受自身特点与人际关系圈共同决定,这是信息扩散的内在动因[2],而信息扩散通过用户的社交活动及形成的交互网络来体现[3],因此,从交互行为数据入手,探索用户的信息扩散能力,是影响力评价的关键。
1 文献回顾
经过多年的研究发展,不少学者对经典节点排序算法进行了不同角度的改良:刘忠华等人在改进Κ-shell分解和节点基本属性的基础上,提出了基于Κullback-Leibler 的节点排序方法[4];Rui 等人利用节点逆向秩信息和邻居节点产生的影响,提出了基于影响最大化的反向节点排序方法,以此估计节点影响力[5]。有些学者从网络结构出发来进行节点影响力度量:朱晓霞等人基于多个社交网络共同构成的多层网络拓扑结构,构建了多层社交网络中的影响力节点识别方法[6];杨剑楠等人基于多层耦合网络分析,提出了基于节点层间相似性的节点重要性识别方法[7]。也有学者将网络分析方法与其他领域的理论进行有效结合:齐林等人将两类不平等映射为节点在网络中的能力与权力的二重异质性,设计了评价节点重要度的DH指标[8];Lin等人将网络整体结构和传播动力学特征进行耦合分析,并利用差分方程考察节点传播特征,进行重要性度量[9]。交互网络的时间维度也是国内外学者的关注点:Tang等人对时序网络中的介数中心度、接近中心度等特征进行了定义,并在此基础上提出了基于时间切片网络的节点重要性预测方法[10]。
通过文献梳理发现,目前节点排序方法的相关研究中,实验数据多为Club、Arpa、Workspace等线下网络,使用真实网络数据验证模型在虚拟社区网络中的适用性与有效性的研究较少。更重要的是,大多数研究多从整体网络结构出发,少有学者考虑群聚效应所产生的局部社区特征差异对算法效果的影响:同质性(Homophily)用户自发形成相同的行为模式[11],而群体规范(Group Norm)使得同质性用户更愿意在自己的“小圈子”里活动,中心人物影响力扩散存在“饱和效应”[12],且局部聚集程度越强,越不利于信息在社区全局的广泛扩散。由此可见,群体规范对用户信息扩散能力产生的干扰,可能会影响用户影响力度量的准确性。
综上所述,本文提出一种考虑网络局部特征的节点影响力评价方法,从中观层面出发,分析凝聚子群结构特征,在此基础上对用户影响力进行分析与讨论。
2 模型构建
2.1 理论基础
2.1.1 社区发现

2.1.2 凝聚子群分析
凝聚子群分析(Cohesive Subgroup Analysis,CSA)是一种社区子结构分析方法。虚拟社区用户自发形成凝聚子群,各子群结构特征的差异对内部用户的交互行为产生影响,凝聚子群分析可用来分析其结构特征与运营机制。凝聚子群分析的主要内容有:互惠性(Reciprocity)通常用来衡量社区用户之间存在相互交流现象的程度;密度(Density)是用来衡量社区用户间关系密切程度的指标;直径(Diameter)用以衡量信息传播范围;平均最短路径(Average Shortest Path)为所有节点对之间使用Dijkstra 算法计算最短路径后的平均值,通常用来判断社区的小世界特性。
2.1.3 节点排序
通过节点排序来度量用户影响力,挖掘意见领袖,是常用的方法。节点排序算法主要有基于中心性分析的度中心性(DC)、中介中心度(BC)、接近中心度(CC),以及考虑邻居节点拓扑结构的聚集系数指标、考虑网络全局信息的特征向量指标等;基于随机游走的PageRank算法(以下简称PR算法)在谷歌公司创立之初用于评价网页质量,是节点挖掘算法中最著名的链接分析算法之一;Hits 算法也是经典链接分析算法之一,它使用内容权威值(Authority)和链接权威值(Hub)来分别衡量用户的信息质量与传播倾向。
2.1.4 创新扩散理论与Bass模型
创新扩散理论根据创新(Invention)与模仿(Imitation)这两个信息扩散主要过程的信息采用速度差异,将潜在用户分为创新者、早期接受者、早期大众、晚期大众和落后者五类:少数创新者和早期接受者优先“认知”信息,再对大众实施“说服”,最终引导“决策”;而模仿者群体(包括早期大众、晚期大众等)除了被创新者“说服”外,新信息的接受与传递还受个人特征与偏好的影响[14]。在创新扩散理论基础上,Bass模型指出信息扩散不仅取决于创新采用者们自身的创新能力,模仿采用者的模仿能力也是决定因素之一。Bass 模型的三大建模要素为潜在用户数量、创新系数和模仿系数:潜在用户数量指信息达到完全扩散时的接受者总量;创新系数为用户受渠道选择、广告偏好等主观因素的影响,主动接受新产品、新信息的可能性;模仿系数为用户受到已采用群体的口口相传,从而被动接受的可能性[15]。
2.2 模型流程
虚拟社区中,潜在局部用户群体的群体规范差异会影响用户的信息传播,少有研究考虑这点。社区发现算法能够挖掘出潜在群体,而凝聚子群分析可以分析不同潜在的局部群体在信息接受与主动传递上的水平差异。鉴于此,本文考虑将用户重要性分析与局部群体特征分析进行有效结合,提出一种基于凝聚子群分析的用户局部影响力评价模型(Cohesive Subgroup Analysis Based Local Leadership,CSA-LL)。
CSA-LL模型的建模依据与步骤如下:
(1)用户全局影响力度量
虚拟社区中,信息感知与接受比创新者更谨慎的早期接受者通常作为社区中的意见领袖,促进信息流通,影响关系网络结构与其他用户的行为发展[16],在信息扩散过程中发挥着重要作用。正是信息早期接受者们迅速向大众传播,扩散的爆发期才得以到来[14]。Bass也指出,创新采用者对新产品、新服务等信息的早期扩散影响较大,是大多数模仿采用者接触并采用信息的前提[15]。因此,意见领袖挖掘是探究虚拟社区中信息扩散过程的关键,而准确度量用户在全局网络中的重要程度,是挖掘意见领袖、分析其在群体规范下的信息传播能力以及影响力度量的研究前提。
PR算法和Hits算法皆是度量用户重要性的有效算法,但单一算法无法包含用户所有性质,且无法适用于所有网络,混合指标常作为用户影响力排序的手段[17]。本研究采用混合指标的方法,将PR 算法与Hits 算法中更能体现用户信息质量与影响他人程度的Authority 维度(简称H(a)算法)进行有效结合,作为评价用户重要性的定量指标,并将之定义为用户的全局影响力(Overall Influence,OI)。
基于多属性的影响力度量,多使用专家打分、层次分析法等过于依赖个人素养的主观赋权法进行属性赋权,这只在熟悉研究对象与属性特征时才有较好的效果。在多属性决策中,信息熵越小的属性,所含信息量越多,作用越大,因此,取决于客观数据的客观赋权法——熵值法能够提升赋权效果与合理性[18]。PR算法和H(a)算法均为基于链接分析的排序算法,但算法原理、节点权重传播模型、适用数据量等方面均存在差异,难以主观判断两者在不同网络中的性能优劣[19],使用基于信息离散度的熵值法,能够提高全局影响力度量中属性赋权的合理性与准确性。
综上所述,用户全局影响力的计算方法如下:
对虚拟社区用户交互行为原始数据进行清洗和预处理。之后,以用户名作为节点vi,合并形成节点集合V,vi∈V 。对存在交互的节点(vm,vn),vm,vn∈V,根据方向与强度,建立加权有向边ej,合并形成边集合E,ej∈E 。将节点集合V 与边集合E 作为输入,建立加权有向网络G(V,E),计算所有节点vi∈V 在G 中的PR数值和H(a)数值并归一化,形成节点属性向量:

合并所有节点属性向量,使用熵值法计算权重向量:

最终,使用混合指标度量用户全局影响力:

(2)凝聚子群挖掘
用户的信息传播并非仅取决于意见领袖的“说服”,个人偏好与行为特征也是决定因素之一。受人口统计学特征、UGC 特征(包括主题、情感、丰富度与可读性等)、社区活动参与度、活跃时间等因素的影响,用户的内容发布、交互频率等行为特征有所不同。存在相同行为特征的用户会自发聚集,形成凝聚子群,且结构趋于稳定,对外部信息存在一定抵制,形成群体规范,进而产生了用户密度、互惠水平等子群结构特征的差异,这是造成各子群内部信息扩散效率不同的主要原因。因此,有必要挖掘与分析子群特征,探索子群信息扩散效率,进而分析其对用户信息传播能力的影响。
本文使用社区发现算法挖掘潜在的凝聚子群。对G(V,E)使用不同社区发现算法进行子群挖掘并计算模块度Q,选取Q 值最大的结果:

(3)子群结构分析与信息扩散效率度量
创新扩散理论指出,累计扩散数量大致呈S曲线分布,意见领袖促成了扩散前期的爆发式增长。然而,随着扩散的推移,模仿型群体的重要性逐渐增强。Bass模型指出,模仿系数越大,潜在群体接受新产品、新信息的可能性越大,而且新的采用者会参与下一阶段的扩散。类似地,虚拟社区用户的信息扩散,在早期受社区等级、口碑等用户个体因素的影响更大,但信息采用群体能自发推动个体用户下一阶段的内容传递,形成“口口相传”,可以低成本、高效率地提升用户发布信息的传播速率,扩大信息覆盖范围,个体传播能力得到提升,这也是各个企业偏好于在活跃的在线社区中实施病毒式营销策略的内因。因此,探讨子群的扩散效率,并考虑其对用户信息传递效率的提升作用,能够提高用户影响力度量的准确性。


其中,直径与平均最短路径和的数值与信息传播效率呈负相关,取值为与1的差值。
上述子群结构特征指标皆可描述信息扩散现象,但偏重角度有所不同,使用混合指标法结合各类特征,用以综合评价子群信息传递效率,是科学合理的。同样使用熵值法计算子群结构特征权重向量:

最终,使用混合指标来度量每个子群的信息传递效率,并将其定义为凝聚子群内部的信息扩散效率(Information Diffusion Efficiency of Subgroups,IDES),计算公式为:

(4)用户影响力排序
创新扩散理论强调意见领袖个体与采用者群体均为扩散效果的重要影响因素,Bass模型也指出意见领袖的创新系数和采用群体的模仿系数是决定传播速度与程度的主要因素。此外,每个用户的潜在扩散群体都是社区全体用户,Bass模型建模要素中的潜在用户体量不予考虑。综上所述,将用户个体全局影响力和所在群体的信息扩散效率进行结合,计算用户影响力数值:

其中,CS(vi)为节点vi所在的子群编号。通过上式获取数值排序后的Top-K个节点,即为影响力高的意见领袖序列。CSA-LL模型弥补了经典节点排序算法与已有研究未考虑子群特征对用户信息扩散的影响这一不足之处,用户影响力度量与排序结果更为合理与准确。
3 数据处理
3.1 数据收集与清洗
本文选取豆瓣网第二大社区“穷游天下”小组中最后回复时间在2019.9.16 至2019.10.18 的用户交互行为数据,维度包括评论、热评、转发、收藏四种交互行为涉及的用户名。

表1 异常节点示例
对清洗后的数据集进行二次检测,结果不再包含异常数据,清洗效果较好。各类交互行为数据统计量如表2所示。

表2 一般统计量
3.2 数据预处理
不同的用户评论包含的信息存在差异:(1)评论者对某一发帖进行初次评论,是以其对发帖者的信息传递的有效接收为前提;(2)帖子为非发帖用户提供了互动平台,发帖者在其中起到了中介作用,而用户之间持续沟通更依赖于双方的同质性,发帖者的作用减弱;(3)置顶的热门评论比普通评论更能显示信息的接收程度。因此,对各种评论关系进行如表3 所示的权重设置,n为相应维度的产生次数,对合并重复边的权值取倒数,作为最终的相异权,形成边集合E。

表3 社区用户交互维度与权重设置
4 模型实现与实验分析
4.1 模型实现
使用预处理得到的数据构建网络G(V,E),计算所有节点的PR值与H(a)值,并使用熵值法得到ω(node_prop)=[0.455,0.545],再使用上述数据与式(3)计算得出所有节点的全局影响力OI值。选取GN算法、Louvain算法、Infomap 算法和LPA 算法,分别对G(V,E)进行社区发现,得到Qˉ=[0.592,0.650,0.614,0.516] ,最终选取Q值最大的VCS(Louvain),网络结构示例如图1 所示。子群数量与体量如图3所示,最终得到295个子群,人数超过100人的子群有30个,人数不超过2人的边缘子群有191 个。对VCS(Louvain)中的子群分别构建网络,使用式(5)和(6)计算得出互惠性、密度、直径、平均最短路径4 个结构特征,并使用熵值法计算得出ω(cs_struc)=[0.582,0.341,0.039,0.038],再使用式(7)得到所有子群的信息扩散效率IDES 值。在得到所有节点的OI 值与其所属子群的IDES 值后,使用式(8)计算得出节点的CSA-LL 数值作为用户影响力度量与排序指标,结果如表4所示。

图1 网络构建与社区划分结果示例
4.2 节点营销能力实验
为了验证CSA-LL模型的性能优势,从用户营销能力角度入手,比较本模型与标准方法的差异。AISAS模型[23]强调了网络营销中搜索(Search)和分享(Share)的重要性,企业社交媒体营销效果影响因素的相关研究通常使用企业内容分享数据作为其营销效果和发展潜力的度量[24]。本文借鉴AISAS模型,使用分享数据对用户进行营销能力排序,再使用肯德尔相关性系数(Κendall’s tau-b)计算其与各节点排序算法结果的相关性,作为衡量营销能力的指标。肯德尔系数τ 的范围为[-1,1],τ=1 时两组随机序列完全一致,τ=-1 时完全不一致,τ=0 时完全不相关。

表4 节点排序对比示例
豆瓣社区中,除了转发功能外,内容收藏机制——“豆列”也属于具有特色的分享行为:不同于其他平台收藏机制的隐私性,豆瓣社区用户可收藏其他平台的内容放入豆列,也能查看他人的豆列列表。因此,使用被转发与被收藏数量之和(以下简称“Rel&Col”)进行节点营销能力排序。将共存在1 575 次被转发和被收藏的437个节点在各排序算法中的序列编号作为输入,使用SPSS计算肯德尔系数,结果如表5所示。从表5中可以看出,各算法的节点排序序列与营销能力序列均呈显著正相关,且CSA-LL模型比PR和H(a)的相关性稍高,并通过了显著性检验。这说明,CSA-LL模型输出的用户,具备更高的营销能力与发展潜力,模型效果得到验证,也证实了基于信息扩散的分析视角对用户影响力算法性能的提升作用。

表5 Κendall相关性分析结果
4.3 节点传播性能实验
4.3.1 实验1:基于豆瓣社区网络的LT模型实验




图2 用户个体传播LT模型实验输出结果(豆瓣网络)
在用户个体传播实验中,单一根节点依次为RootSeed(CSA-LL,PR,H(a))=[“No See 。”,“有理想的吃货”,“她们叫我小地图”],输出结果如图2所示:图(a)显示,RootSeed(CSA-LL)在激活阈值θv的所有不同水平下的LT_num 数值分布具有明显优势,短期传播性能更强;图(b)显示,θ <0.2 时,所有RootSeed(ai)达到饱和传播时的活跃人数峰值差距不大,如子图(c),θ ≥0.2 时RootSeed(CSA-LL)的LT_num 数值均更大,且θ=1,即所有用户的被激活难度水平最高时,CSALL 是唯一的LT_num 数值大于100 的算法,CSA-LL模型输出用户个体的饱和传播性能最强。为避免偶然性,选取除去上述节点以外的根节点进行实验,RootSeed(CSA-LL,PR,H(a))=[“三国轻轻鱼笑”,“出发吧”,“喵仔”],得到相同结论。
在用户群体传播实验中,选取各算法排序的Top-20节点作为RootSeed(ai),实验结果如图3 所示。图(a)与图(b)显示的结论与上一实验类似:所有θ 水平下的RootSeeds(CSA-LL)短期传播性能比PR 算法和H(a)算法更高;θ <0.2 时三种算法的饱和传播性能相当,而节点激活难度提升时,CSA-LL算法性能更好。
综上所述,较之于PR算法和H(a)算法,CSA-LL模型输出用户的信息传播能力要更优,模型可行性与有效性得到验证,也证实了子群信息扩散效率对用户传播能力的正向影响作用,以及基于信息视角进行用户影响力分析的优势。
4.3.2 实验2:基于Advogato 网络与Polblog 网络的LT模型实验
为验证CSA-LL 模型在不同虚拟社区网络上的鲁棒性,选取Advogato 网络和Polblog 网络,使用LT 模型进行实验分析。Advogato 是一个面向免费软件开发人员的虚拟社区,以用户为节点、用户之间的信任程度为边构成信任关系网络;Polblog网络(Political Blogosphere Dataset)是美国政客们在线上发表博客的互动关系数据。分别使用CSA-LL 模型对两个网络进行影响力度量与排序,中间计算与排序结果如表6和表7所示,分析比较不同算法输出用户的信息传播能力。
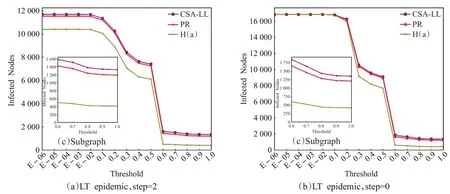
图3 用户群体传播LT模型实验输出结果(豆瓣网络)

表6 CSA-LL模型实现
对Advogato 网络排序结果(表7 Part.1)进行LT 模型传播实验。用户个体传播实验中,PR 算法和H(a)算法与CSA-LL 模型第一次出现排序差异的序号不同,节点选取RootSeed(CSA-LL,PR)=[429,431] ,RootSeed(CSA-LL,H(a))=[438,577] ;用户群体传播实验的输入节点为各算法的Top-20节点集合。
用户个体传播实验结果如图4 所示:图(a)显示,在短期传播中,LT_num('429')>LT_num('431') 、LT_num('438')>LT_num('577')在所有激活阈值水平下均成立,CSA-LL 模型输出用户的短期传播优势明显;图(b)显示,在饱和传播中,各算法在用户激活难度较低时的活跃人群峰值差异不大,但用户激活难度较高时,CSA-LL模型的优势再次体现。用户群体传播实验结果如图5所示,所得结论与个体传播实验相同。基于以上结果,CSA-LL模型在Advogato网络中的可行性和有效性得到验证。

表7 节点排序示例
对Polblog 网络排序结果(表7 Part.2)进行LT 模型传播实验。用户个体传播实验的节点选取分别为:

图4 用户个体传播LT模型实验输出结果(Advogato网络)
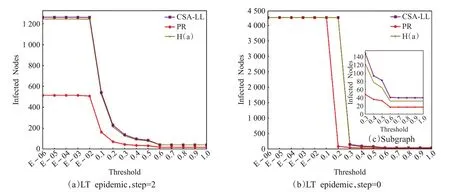
图5 用户群体传播LT模型实验输出结果(Advogato网络)
RootSeed(CSA-LL,PR)=[1101,641]
RootSeed(CSA-LL,H(a))=[1051,642]
用户群体传播实验的输入节点也为Top-20节点集合。
用户个体传播实验结果如图6所示:图(a)显示,在短期传播中,用户激活难度较低时,LT_num('1051')>LT_num('642')成立,而θ ≥0.2 时,CSA-LL模型与H(a)算法的性能相当;图(b)显示,在饱和传播中,各算法输出结果的峰值与谷值差异不大,但拐点出现时θ(CSA-LL)=0.1 >θ(PR)=θ(H(a))=0.01,CSA-LL模型输出用户对高激活难度用户实现有效传播的能力更强。用户群体传播实验结果如图7所示,所得结论与个体传播实验类似,CSA-LL 模型用户激活难度低时的短期传播效果更好,而激活难度较高或达到饱和扩散时,效果与前两者相当。
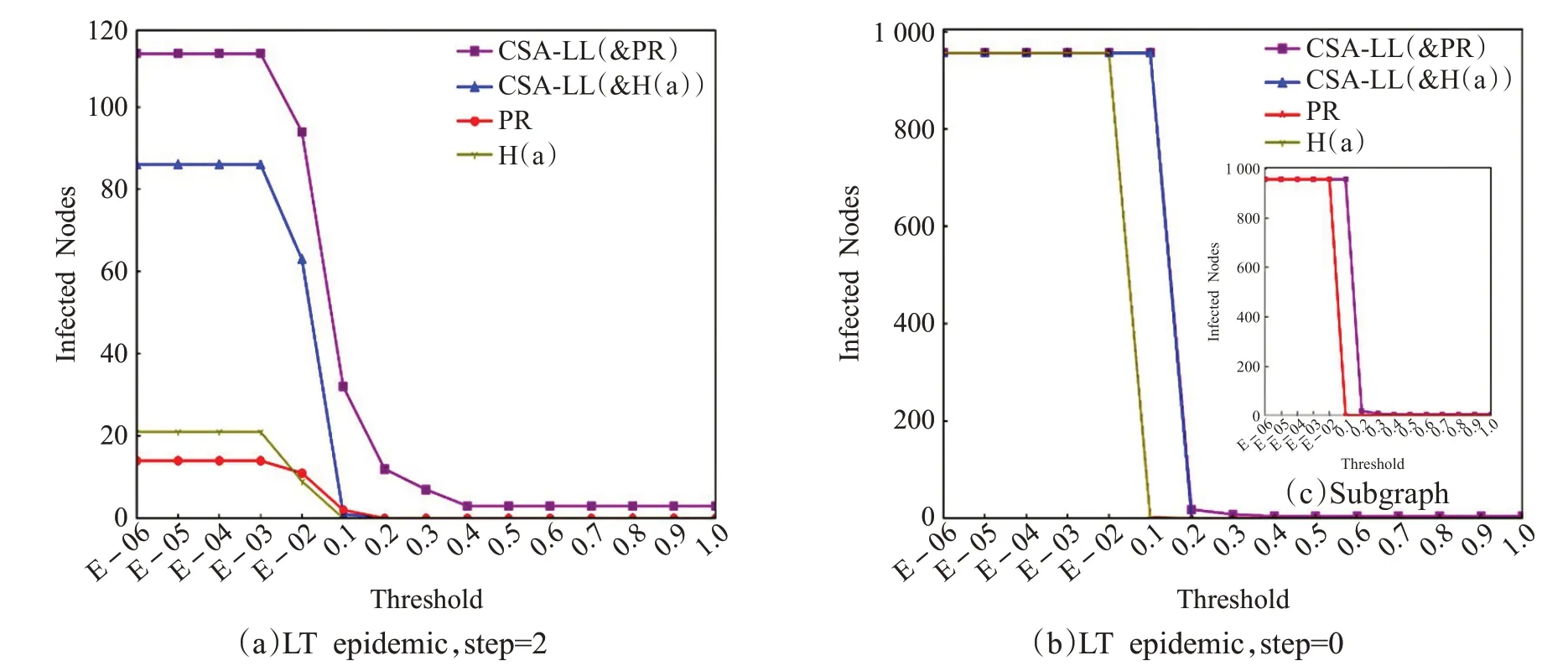
图6 用户个体传播LT模型实验输出结果(Polblog网络)
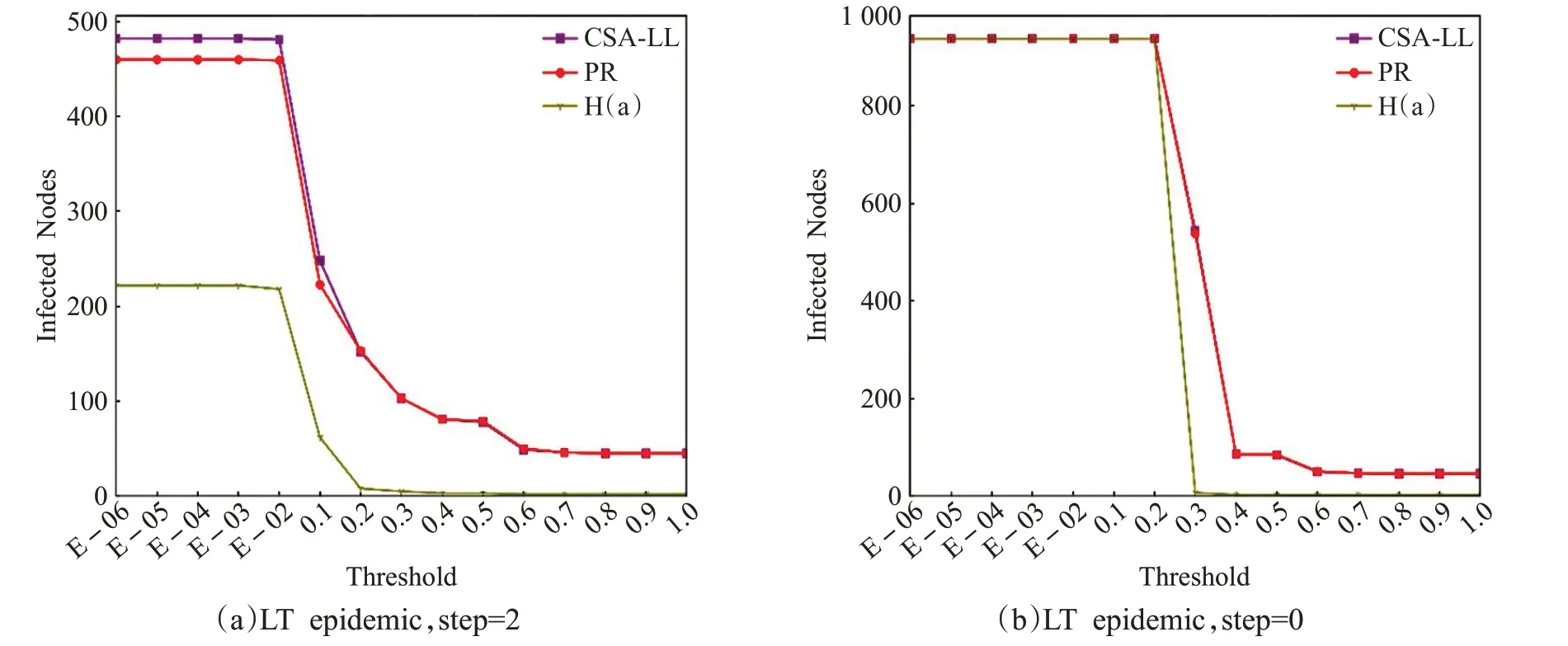
图7 用户群体传播LT模型实验输出结果(Polblog网络)
上述结果可能是由于Polblog 网络性质所导致:Polblog用户均来自美国政客圈,彼此熟悉,实际的激活难度较小;各算法Top-20 用户均来自122 号和198 号子群,且IDES('112')=0.389,IDES('198')=0.376,子群的信息扩散效率对传播影响不大,且对于Polblog 这种小规模网络,用户达到饱和传播时可能均已覆盖大多数用户,导致峰值差异不大。为了验证推断,进行补充实验:选取拐点θ=0.1 作为所有用户的激活阈值,设置不同传播阶段,进行群体传播实验。结果如图8 所示:在step <6 时,CSA-LL 模型输出用户的基础激活人数更多,传播速度更快,子群信息扩散对用户短期传播能力具有显著效果,而当达到饱和传播时,各算法输出的活跃人数占比77%,上述假设得到验证。基于以上结果,CSA-LL 模型在Polblog 网络中具有较好的可行性和有效性。

图8 用户群体传播LT模型补充实验结果(Polblog网络)
综上所述,CSA-LL 模型在不同虚拟社区网络中的鲁棒性得到验证,同时也再次验证了基于信息扩散视角进行用户影响力度量,比标准方法的性能更强。
4.3.3 实验3:基于豆瓣社区网络的IC模型实验
考虑到传播模型的种类可能对结论产生影响,选取LT模型之外的信息传播模型,对实验1、实验2得到的结论进行稳健性检验。


图9 IC模型实验输出结果(豆瓣网络)
综上所述,子群信息扩散效率对用户信息传播能力具有正向影响这一结论的稳健性得到验证,较之标准方法,本文提出的基于信息扩散视角的用户影响力度量方法具有更好的性能。
5 总结
针对以往研究少有考虑群体规范对信息传播效率影响的问题,本文提出一种适用于虚拟社区网络的用户影响力度量方法——CSA-LL 模型,从传播性能与营销能力两个角度出发,结合豆瓣社区网络、Advogato 网络和Polblog 网络,使用LT 模型、IC 模型、AISAS 模型、Κendall相关性分析等方法,分析比较CSA-LL模型与PageRank算法和Hits算法的差异,验证了模型的可行性、有效性和在不同虚拟社区网络中的鲁棒性,也证实了基于信息扩散的分析视角进行用户影响力度量的准确性。本文选取的社区发现算法大多属非重叠社区发现,对于存在社区重叠的用户,找到准确度量其所属区域信息扩散效率的方法,可以提高模型效果,这是之后的研究重点。
