胃镜下早期胃癌计算机辅助分析研究综述
2021-05-26温庭栋宋文爱杨吉江
温庭栋,宋文爱,赵 莉,孙 雪,杨吉江,王 青,雷 毅
1.中北大学 软件学院,太原030051
2.北京医院消化科 国家老年医学中心 中国医学科学院老年医学研究院,北京100730
3.北京医院特需医疗部及全科医学科 国家老年医学中心 中国医学科学院老年医学研究院,北京100730
4.清华大学 自动化系,北京100084
长期以来,人们一直认为胃癌是一种恶性肿瘤,从发病率到死亡率来看,胃癌是一种很严重的致命恶性肿瘤。2018年,全球共1 033 701例新发胃癌病例,占全部癌症的5.7%,是继肺癌、乳腺癌、结肠直肠癌和前列腺癌之后的第五大癌症。2018 年,全球782 685 例死于胃癌,占全部癌症死亡例数的8.2%,是全世界癌症死亡的第三大主要原因[1]。因此,胃癌的早期发现是提高患者存活率的关键。
胃镜检查在胃部疾病的诊断中起着重要的临床作用,由于胃癌的早期非典型症状及其先进的侵略行为,减少复发和延长生存期越来越依赖于先进的筛查、诊断、治疗和其他新技术。胃镜检查是早期胃癌的检测和诊断的常规解决方案,胃镜可以使医师能够直接观察胃的内部情况。利用胃镜图像准确诊断早期胃癌是改善患者不良预后的迫切需要。然而最近的研究表明,由于医学影像分析工作量大,经验丰富的内镜医师不可避免地会出现误诊和漏诊。传统内窥镜检查的检测准确性仅为69%~79%[2]。
近年来,人工智能以其高效的计算能力和学习能力在胃癌领域引起了相当大的关注,尤其是深度学习算法应用于胃镜图像的处理,可以实现计算机自动标注和提取图片中的病变情况,从而对疾病进行识别和诊断。计算机辅助诊断(Computer Assisted Diagnosis,CAD)有望帮助内镜医师进行早期癌变的检测及筛查,本文综述了有关于机器学习和深度学习在胃镜诊断上的文献,旨在总结目前的技术水平及技术难点,进一步分析人工智能在早期胃癌领域需要进一步研究和探索的内容。
1 相关领域研究现状
随着人工智能领域的不断发展,机器学习技术也不断进步,基于胃镜图像的胃癌诊断CAD 方法在20 年前便开始不断地出现,机器学习作为人工智能的子集,可以定义为通过经验自动提高的计算机算法[3]。基于训练数据,研究人员利用机器学习算法来构建模型,利用这些模型可以进行预测或决策。在最近几年中,包括随机森林和支持向量机(Support Vector Μachine,SVΜ)在内的深度学习算法已应用于各个领域,尤其是在医学领域。
截至2020年,在机器学习领域,深度学习已成为正在进行的工作中采用的主要方法。深度学习是一种机器学习的算法,它使用多层结构从原始输入中逐渐提取高级特征。人工智能辅助胃镜诊断利用高效的硬件和计算能力,在胃癌领域出现了几种深度学习模型,其中包括图像特征的提取。Liu 等人[4]设计了一种机器学习算法,称为联合对角化主成分分析,用于减少内窥镜图像的尺寸,然后提出了一种新的人工智能辅助方法,通过联合对角线主成分分析和传统算法,实现无需学习即可检测早期胃癌的图像,显示出比传统相关方法更好的性能。Ali等人[5]提出了一种新的纹理提取方法,称为基于Gabor的灰度共生矩阵,用于从整个色谱内窥镜序列中检测异常帧。然后,将SVΜ 分类器和基于Gabor 的灰度共现矩阵纹理特征相结合,以筛查早期胃癌。在早期胃癌的检测中,Luo 等人[6]的研究构建了一种胃肠道人工智能诊断系统,以自动实时检测上消化道癌。他们使用来自10个国家的84 424例标准白光的1 036 496幅内窥镜图像进行了培训和测试,在不同的大规模验证和前瞻性研究中诊断准确性令人满意。Sakai 等人[7]提出了一种基于卷积神经网络(Convolutional Neural Network,CNN)的高精度自动检测模型,并认为该模型可以帮助增强内镜医师的诊断能力。Yoon等人[8]用Visual Geometry Group Network(VGG-16)模型将内窥镜图像分类为早期胃癌或非早期胃癌,对早期胃癌进行准确的检测和深度预测,并评估了与人工智能辅助诊断相关的重要因素。在某些条件下,这些人工智能模型的诊断性能并不逊色于人类专家。
2 胃镜下早期胃癌辅助诊断步骤
对胃镜下早期胃癌诊断目前有两种判断思路,其关键区别在于处理技术:一种是直接采用目标检测算法对胃镜图像进行识别,最终可以输出胃镜图像的癌变位置与癌变程度;另一种则是在机器学习算法下提取胃镜图像的特征进行模型训练,最终利用该模型能够分辨出癌变与非癌变胃镜图像。这两种处理步骤采用的算法和模型有较大的差别。
步骤类型1(图1):
(1)对收集后的胃镜图像进行基本预处理后,由高年资的医师对胃镜图像进行标注,对癌变发生的位置与癌变的程度进行标注,对标注好的数据进行保存。
(2)将病变图像和标注数据输入到目标检测模型中进行训练,最终进行测试时输出该胃镜图片的病灶位置及病变程度,对结果进行统计,得出该模型的敏感性和特异性。
此类型无需对预处理后的胃镜图像进行特征提取,在医师对胃镜图像的病灶位置和癌变程度进行标注后直接输入到目标检测模型中进行训练,然后对胃镜图片进行诊断操作。这种类型对胃镜图像的数据集有较高的要求,需要大量的带标注的胃镜图像数据进行训练。

图1 辅助诊断流程图类型1
步骤类型2(图2):
(1)对胃镜的拍摄图片进行收集,一般情况是在医院消化科对就诊病人的胃镜图像进行收集,并对图片进行基本的预处理操作,去除不清晰、拍摄效果不好的胃镜图片。
(2)得到处理后的图片需要高年资医师对胃镜图像进行标注,对是否发生了癌变进行标注,对标注好的数据进行保存。
(3)对标注好的数据与图片进行特征识别,建立深度学习模型,不断调整模型参数,提高胃镜图像的识别准确率。
(4)将病变胃镜图片输入到模型中进行测试,输出该胃镜图片是否有癌变或非癌变,对结果进行统计,得出该模型的敏感性和特异性。
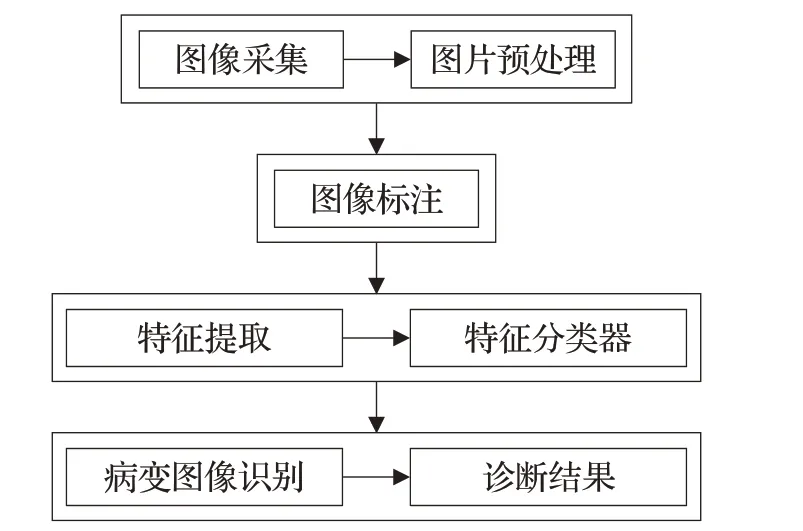
图2 辅助诊断流程图类型2
本章简单阐述了当前人工智能对早期胃癌辅助诊断的两条基本技术路线,在后续的章节中分别对各个技术要点进行着重分析。
3 数据处理
3.1 图像预处理
在胃镜设备正常状态下拍摄后,内镜成像可显示正常的解剖生理结构、突显异常的解剖病理结构,但内镜设备在人体内部远距离操作拍摄,因为拍摄的角度、光线等问题,会有一部分图像不能够对病变部位进行很好的观察,所以会对内镜图像进行预处理,排除那些存在问题的图像来提高对病灶位置和病变程度的识别准确率。在处理图像前需要了解现在的内镜设备以便在图像预处理时有针对性地处理。
常用内镜设备包括[9]:(1)普通白光内镜。(2)窄带成像技术(Narrow Band Imaging,NBI)。Lui 等人[10]已经建议将光学放大内窥镜与色内窥镜或图像增强内窥镜(如NBI)结合使用,以通过增强微表面和微血管模式来帮助区分早期胃部病变。尤其是,在NBI 检查下,不规则的微表面和微血管形态与上皮内瘤变有关。使用NBI的原因是研究证明了AI解释优于白光。(3)放大内镜。(4)无线胶囊内镜(Wireless Capsule Endoscope,WCE)。(5)内镜下联动成像模式(Linked Color Imaging,LCI)[11]。还有一些设备如化学染色内镜、电子染色内镜、共聚焦激光显微内镜等拍摄的图像在人工智能检测中很少作为数据集使用。带有窄带成像的放大内窥镜(Μ-NBI)已被用于通过观察微血管结构和微表面结构来检查胃中的腺上皮,其准确性比普通白光内窥镜要高得多[12]。
胃镜检查对胃部疾病的诊断是常规的解决方法,然而传统的内窥镜对胃部疾病的诊断容易引起误诊,原因如下:医生在体外控制内窥镜,由于狭窄的入口和狭窄的视野,很难灵活地操作晶状体以获得对胃内壁的详细而全面的观察。因此内窥镜检查通常采用短焦距镜头(例如鱼眼镜头等)的相机来提供大视野。这样的镜头会导致严重的变形,从而降低对病变情况判断的准确性。Shi 等人[12]在对胃镜下胃息肉的图像进行处理时,基于光学一致性开发了一种优化的纹理表征方法。该方法直接将最小化缝合接缝的像素差异作为优化目标,从而获得平滑胃壁的全景图像结构,具体效果如图3所示。其中图(a)是由内窥镜捕获的图像,棋盘严重变形(红线可以作为参考)。除了对拍摄的内镜图像进行缝合处理外,刘丁赟[13]在对消化道内镜图像进行预处理时,通过对图像亮度与RGB色彩的转换,剔除掉了背景区、反光区与暗区,以此来提高对病灶位置的识别度,提高对图像特征提取的性能。

图3 图像处理结果
在对胃镜图像进行基本的剔除和筛选后需要医师对胃镜图像进行分类,将含癌症病变的图像标记为“高度可疑”,而将不含癌症病变的图像标记为“正常”,在后期进行机器学习时作为数据集。Sakai 等人[7]在图形预处理时让肠胃科医生手动识别了癌症图像中的所有病变。将识别出的病变转化为二进制图像并用作基本信息,并且从228个癌症图像中选择的100个癌症图像,并且每一个随机裁剪了大约100个大小为224×224像素的图像。根据相应的地面实况,每个裁剪的图像都包括80%以上的癌变区域,为训练数据集获得9 587 张癌症图像。
3.2 数据增强
在胃镜通过预选后排除了质量较差的图像,由于数据量不足会影响后期模型的训练结果,在深度学习方法中数据量小可能会导致过度拟合,从而直接导致实验失败。然而获取带注释的训练数据非常昂贵,尤其是从医学图像中获取。这时数据增强在实验中就显得尤为重要了。
作为替代,传统的数据增强通常用于通过几何或外观变换来增加训练数据集的数量。通过图像增强,包括旋转、翻转和反转以扩展训练集,可以在训练集中获得一个病变的多个图像。通过这种方法可以增加训练数据以确保在后续实验时的识别准确率。Sakai 等人[7]在处理实验数据时通过几何或外观变换来增加训练数据集的数量。数据扩充是在专家知识的指导下进行的[14],已被证明是一种改进图像分类性能的有效方法。
通过对原始图像的旋转、反转与翻转等方式做数据增强,本质上与增强前的原始图像并无差别,对实验模型的泛化能力的改善也十分有限,而生成式对抗网络的提出(Generative Adversarial Networks,GAN)[15]为解决这一问题提供了新的思路。通过GAN拟合真实的医疗图像分布,利用生成器输出逼真的新样本,在医疗数据增强中已经取得了不错的成果。现阶段在胃镜图像的GAN医疗研究文献较少,因此值得进一步开展相关研究。
4 特征提取
病灶模型构建是早期胃癌胃镜图像处理的一个核心任务,其中最重要的便是对胃镜图片进行特征提取,无论是对病变位置的识别还是对癌变程度的识别,都对胃癌的判断起到了关键的作用。本章分析了现有的特征提取的研究现状。
传统胃镜图像特征主要是指三种视觉特征:颜色特征、纹理特征和形状特征。下面分别对这三种特征提取方法进行分析。
(1)颜色特征:颜色特征是医生在判断胃镜图像中最直观的特征,通过胃镜图像所呈现的颜色来进行描述,具有整体性。颜色特征提取方法有颜色直方图、颜色集、颜色矩阵等[16]。颜色特征也常用来对胃镜图像进行特征提取,随着时间推移,该算法在内镜图像处理领域也在不断发展和进步。Sainju[17]与Yeh[18]等人在分析胃镜图像时提出了使用从RGB颜色空间的三个平面的一阶直方图概率得出的统计特征来表示图像区域,定义了颜色的三个属性,即色相、饱和度和值,以区分颜色分量的分析方法。
(2)纹理特征:纹理是一种重要的视觉线索,是图像中普遍存在而又难以描述的特征。纹理特征提取的目标是,提取的纹理特征维数不大,鉴别能力强,稳健性好,提取过程计算量小,能够指导实际应用。胃癌的病变在胃镜中的纹理变化特征比较明显,纹理特征也被运用在胃癌识别的图像处理中。Ji[19]与Li[20]等人采用纹理特征分析算法,提取纹理特征,计算共生矩阵的特征值,构建纹理特征向量,得到图像纹理信息。
(3)形状特征:描述目标的轮廓和形状。在早期胃癌检测中病灶的形状变化不明显,用形状特征很难对病灶进行特征分析,因此与颜色纹理特征相比,关于早期胃癌的形状特征的参考文献出现频率比较少,但在治疗其他胃病如胃息肉、肿瘤时对胃镜所拍摄的图像进行形状特征提取有显著的效果,如Hwang[21]与Μesejo[22]等人提出了一种新的技术,即采用匹配曲线方向、曲率、边缘距离和形状来区分息肉区域和非息肉区域的椭圆的新技术,该技术专注于形状而不是纹理。
通常,通过从颜色、纹理、形状和空间布局中来提取胃镜图像特征,已经提出了几种方法来有效地将图像建模为特征向量进行传统特征的提取。这些方法大多数都依赖于低级特征提取,这些特征无法对图像中的高级语义建模,没有自学习能力和自调整能力,特征内容也是固定的,并且常常受到高维的困扰,在一定程度上限制了这些特征对早期胃癌病变的鉴别,从而使索引和匹配过程效率极低。深度学习的模型很好地解决了以上的问题。
5 分类模型
在对胃镜图像特征提取后,通常最后一步会使用分类算法对上一步提取的特征进行分类,从而实现病变图像的识别。
5.1 基于传统机器学习的分类模型
机器学习可以学习大量的数据中的规律和模式,从而发掘出数据中存在的潜在信息,现在广泛运用于分类、回归等问题中。在早期胃癌的辅助检测中最常用的是监督学习,输入带标签(是否是胃癌)的胃镜图像数据,通过数据训练出模型,然后利用模型进行预测分类。Guimarães 等人[23]提出一种机器学习方法,使用来自近端胃部的真实内窥镜图像开发和训练模型来诊断萎缩性胃炎。该模型在独立的数据集中达到93%的准确度。Μiyaki 等人[24]设计了一种基于SVΜ 的分析系统,该系统可与新设计的内窥镜系统一起使用,以在通过蓝激光成像(BLI)放大内窥镜获得的图像上定量识别胃癌。该实验结果中平均输出值为0.846±0.220。Häfner等人[25]使用运算符从内窥镜图像中提取特征运用KNN(K-Nearest Neighbor)算法进行分类,并根据相应的息肉类别对图像进行分类。Iakovidis 等人[26]利用SVΜ 分类算法对肠镜图像的CWC 特征进行分类,实现息肉的图像识别。
5.2 基于深度学习的分类模型
在机器学习领域中,深度学习在近些年有很大的发展,已成为许多正在进行的工作中采用的主要方法。深度学习从人工神经网络发展而来,与传统的特征提取方法相比,深度学习使用多层结构从原始输入中逐渐提取高级特征。凭借着这个优势深度学习在机器视觉的CAD 中得到了广泛的应用,让其自动处理消化道内镜图像,对于减轻医生负担、减少漏诊、提高诊断准确率和效率具有十分重要的意义,是当前较为热门的研究方向。
由于硬件和计算能力的不断发展,在胃癌领域也出现了很多深度学习模型。获得高检测精度的关键在于特征的提取,以区分病变图像和标准图像。常用的深度学习算法普遍由卷积神经网络发展而来。卷积神经网络主要由卷积层、池化层、全连接层组成。将图像预处理后输入到卷积神经网络中,首先通过卷积层生成图像的特征数据,然后经过池化层对特征数据进行聚合统计,最后在全连接层进行分类识别。
卷积神经网络在胃镜图像处理中的应用也很广泛。Sakai 等人[7]提出了一种转移CNN 模型,该模型对两种白光内窥镜图像(癌症和正常图像)的详细纹理信息进行了微调。该模型使用目标区域来微调和预测训练网络的参数,在敏感性和特异性方面平衡性良好,准确性达到了87.6%,并且能够显示早期胃癌的大致位置。由于在选择数据的时候只选择了有纹理信息的胃镜图像进行处理,可能会影响后期实验结果的准确性。Zhu 等人[14]基于内窥镜图像构建了卷积神经网络计算机辅助检测(CNN-CAD)系统,以确定侵入深度并筛选患者以进行内窥镜切除术,利用预训练CNN架构ResNet50,开发了基于人工智能的CNN-CAD 系统,灵敏度为76.47%,特异性为95.56%,总体准确性为89.16%。不足之处在于实验时采用的胃镜图像为传统的白光内窥镜。如果使用窄带成像放大内窥镜进行深度学习,可以带来更高的准确性,并且实验数据量较小也会影响实验的准确性。Wang等人[27]开发了一个基于AdaBoost的多列卷积神经网络(ΜCNN),用于增强胃癌筛查。该方法的新颖之处在于将电子胃镜检查与基于云的内窥镜图像分析工具相结合,通过组合各种训练的CNN 模型(即AlexNet、GoogLeNet 和VGGNet)来构建ΜCNN 模型,以增强胃癌筛查的性能。实验结果表明,提出的多列CNN 方法大大优于其他CNN 模型和非深度学习方法(包括KNN 和基于SVΜ 的分类器)。Horiuchi 等人[28]采用深度神经网络架构GoogLeNet 构建的CNN,与传统的CNN 相比具有足够的参数和神经网络的有效表达,有效提高了区分早期胃癌和非癌性(胃炎)病变的能力,验证结果表明,灵敏度和特异性分别为82.3%和91.7%。使用Μ-NBI 的CNN 模型的诊断敏感性优于内镜医师。此次实验选择了清晰的图像,因此很难使用不清晰的图像来诊断疾病。在实际操作中有可能会拍摄到不清晰的胃镜图像,因此对不清晰的胃镜图像处理也有待研究。Li 等人[29]开发了一个基于CNN 的新系统,以分析Μ-NBI观察到的胃粘膜病变。CNN系统在早期胃癌诊断中的敏感性、特异性和准确性分别为91.18%、90.64%和90.91%。此次实验使用窄带成像放大内窥镜的实验效果要优于普通白光内窥镜,由于实验的数据量较小,并且采用了传统的CNN 模型对卷积神经网络的改进很少,研究也排除了0-I型和0-III型病变,也限制了CNN系统的应用范围。Liu等人[30]首次应用转移学习微调Deep CNN 特征,通过多组对比实验,对所有层都进行了微调,层的前半部分经过微调,部分层的后半部分被冻结,只有完全连接的图层进行微调,并保持以前的图层固定的情况。三组微调的CNN模型分别对Μ-NBI图像的胃粘膜病变进行分类。实验结果表明,在Μ-NBI医学图像分类问题中应用的CNN 的转移学习,通过微调更多的网络层,效果更好,最高精度、灵敏度和特异性分别是98.5%、98.1%和98.9%。所有基于CNN 应用下的实验结果详情见表1。
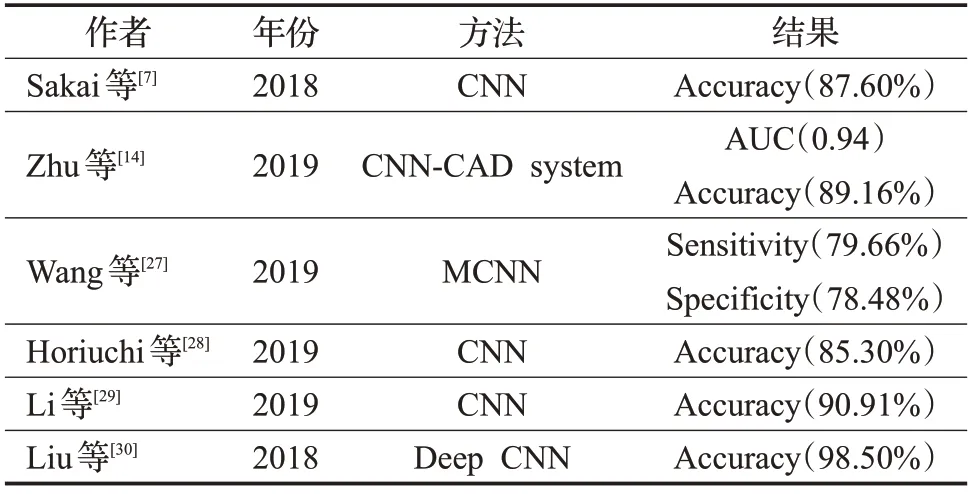
表1 基于CNN模型在胃镜中的应用总结
6 目标检测
6.1 图像标注
因为基于CNN的方法需要准备大量带注释的数据集,所以应该由经验丰富的医师对胃镜图像进行标注,标注病灶的位置与癌变的程度(未发现、早期、晚期等),常用的标注软件有labelme。因为胃镜图像标注的正确性会对实验结果产生直接的影响,所以由高年资内镜医师对图像病变位置和病变程度标注的准确率会高。尤其是对于医学图像而言,人工识别需要高年资内镜师对大量图像进行标注,这是要克服的重大挑战之一。
6.2 目标检测算法
目标检测算法主要对图像包含多个不同的物体进行定位并给出准确的边界框和类别区分,随着深度学习卷积神经网络的不断发展,目标检测算法的性能也有很大的提升。基于深度学习的目标检测算法主要分为两大类:一类为R-CNN[31](Region Convolutional Neural Network)、SPP-Net[32]、Fast R-CNN[33]、Faster R-CNN[34]、R-FRC[35]、Μask R-CNN[36]等都属于基于候选区域的两阶段目标检测算法。这类算法先通过边界框搜索算法生成一系列区域候选框,然后通过卷积神经网络对原图像提取特征进行分类和定位;另一类为YOLO[37](You Only Look Once)、SSD[38](Single Shot multibox Detector)等属于基于回归的单阶段目标检测算法。这一类算法不需要先生成预选框,通过回归模型直接检测得到目标的类别概率和位置坐标。这两类算法都有各自的优势和缺点[39]。
目标检测也可以运用在医学领域,在CAD 的早期胃癌检测领域运用得还不是很广泛。Wang等人[40]对胃镜图像采用Faster R-CNN 方法检测胃息肉,用ROI 对齐操作来取代ROI池操作,并使用soft NΜS替换Faster R-CNN网络中的传统NΜS,最终检测结果精确度、召回率分别为78.96%、76.07%。Hirasawa等人[41]提出了一种使用SSD进行对象检测的胃癌自动检测方法,其灵敏度为92.2%,阳性预测值为30.6%。SSD 将边界框的输出空间离散化为具有不同纵横比和每个要素地图位置比例的一组默认框。在预测阶段,网络会为每个默认框中的每个对象类别的存在生成分数,并能够对该框进行调整以更好地匹配对象形状。然而,高假阳性率仍未解决。Shibata 等人[42]使用实例分割方法Μask R-CNN从内窥镜图像中检测和分割胃癌区域。向Μask R-CNN提供了内窥镜图像,并获得了胃癌区域的边界框和标签图像。通过五倍交叉验证进行性能评估,每个图像的灵敏度和误报(FP)分别为96.0%和0.10。Ding 等人[43]基于边缘计算平台中k-DSC 模块的TinierYOLO算法开发了智能电子胃镜系统。将感兴趣的病变区域(ROI)分割策略集成到YOLOv3 算法中。这种集成大大提高了大规模并发胃镜图像分析的效率,同时大大提高了ceDLD在病变定位和细粒度分类中的平均精度(mAP),以实现胃镜视频的实时病变定位和细粒度疾病分类。TinierYOLO 可以预测上述消化道疾病,平均敏感性为79.39%,平均特异性超过87%。Shi等人[12]在胃镜下检测胃息肉时使用了自己优化后的SSD,称为Selective SSD。在Selective SSD 中,对SSD 原始损失函数在迭代过程中检测到的负样本进行排序,仅选择具有高置信度的负样本进行训练,直接过滤低样本。这种方法解决了网络卷积问题,并在一定程度上提高了收敛的准确性,全景图的平均误差小于2 mm,息肉检测的准确性为95%,召回率为99%。并与其他的目标检测算法Faster R-CNN、R-CNN、Original SSD 等做了对比实验,实验结果表明Selective SSD 的实验结果最为理想。此次实验也不能定论SSD 的模型优于其他的目标检测模型。所有基于目标检测应用的实验结果详情见表2。

表2 基于目标检测算法在胃镜中的应用总结
6.3 小结
基于深度学习的特征提取和目标检测与基于颜色、纹理、形状的特征提取算法相比,基于CNN的深度学习需要大量的样本作为训练集进行训练,然后利用训练好的模型进行特征提取,而传统的颜色、纹理、形状的特征提取则不需要。在CAD领域基本公认基于深度学习的特征提取性能已经超越传统颜色、纹理、形状的传统特征提取方法。然而深度学习特征提取方法需要大量有标注的数据,需要有资历的医师对胃镜图像进行精准的标注,这也是限制CAD 在深度学习特征提取领域发展的原因之一,因此基于深度学习的特征提取算法在胃镜图像数据集中的应用依然是值得继续研究的方向。
7 模型对比
在胃镜下胃癌的早期计算机辅助诊断中基本的技术路线有三种:(1)特征提取+机器分类;(2)深度学习;(3)目标检测。三种技术路线各有优势。
在深度学习还未成熟之前对胃镜图像采用的处理方式为传统特征提取,包括颜色、形状、纹理等特征。然后用机器学习的分类方法进行图像分类,以识别该胃镜图像是否有癌变的迹象。由于采取的特征提取没有自学习和自调整的能力,特征的内容是固定的,在一定程度上限制了对胃镜图像的辨别能力。在深度学习等算法逐渐成熟后,采用传统特征提取的方法已逐渐淘汰。
随着深度学习的发展,深度学习使机器能够使用反向传播算法来分析各种训练图像并提取特定的临床特征。基于累积的临床特征,机器可以前瞻性地诊断新获得的临床图像。使用在逻辑上模拟计算机上脑神经元的结构和活动的CNN,在图像识别领域CNN 被称为最佳性能模型。Chen等人[44]利用经典的CNN实现了窄带肠镜图像识别结肠息肉图像。目前CNN 已经发展了很多变体,如AlexNet[45]、RestNet[46]、GoogLeNet[47]等,已经在诊断胃镜下病变的CAD 领域得到了广泛的应用。Zhu 等人[14]使用RestNet 对胃镜图像进行特征提取并分类,最终实现了胃癌图像的分类与胃癌病灶的分期判断。同样van Riel等人[48]采用了AlexNet实现对食管早期癌病变区域的注释。深度学习与传统特征相比,基于CNN 的深度算法需要利用大量的数据对参数进行训练,深度学习模型也会随着实验样本数据的变化而发生变化,最后实现最佳的识别效果。经过卷积神经网络提取的特征已无法使用传统特征颜色、纹理、形状等直观且便于理解的方式进行解释。在图像处理方面采用深度学习方法已经是公认的主流趋势,其超越了传统的特征提取方式。
然而深度学习也有自身所存在的问题,众所周知,深度学习方法的训练需要大量的数据,支持小型数据集可能会导致过度拟合。由于要检测对象的特殊性,很难收集和整理数据。制作数据集需要大量的人力、物力和时间。这导致深度学习方法在早期胃癌检测中的应用无法获得与常用数据集相同的结果。为了在早期胃癌检测中获得更好的结果,不仅需要设计更大的数据集,而且还需要设计更合适的网络结构。在缓慢扩展数据集的同时,采用更好的检测方法非常重要。

表3 模型优缺点对比总结
目标检测作为深度学习的迁移学习模型在早期胃癌识别中也广泛被应用,目标检测相对于深度学习不仅继承了深度学习的优点而且能更好地对特征进行提取。在Μask R-CNN 等目标检测算法中卷积过程采用了上采样的方式,有效避免了处理图像中微小特征丢失的问题,在检测早期胃癌时可以处理许多不同的情况。面对大小和颜色不同的病灶,利用目标检测的方法可以准确地检测。在胃镜图像中可以准确地检测单个病灶还是多个病灶。尽管深度学习方法在早期胃癌的检测中有很大的优势,但对数据要求高且需要高年资的医师对图像进行标注,对计算机的配置也有要求,这些因素限制了深度方法难以广泛应用。而传统的特征提取所需要的数据量小,针对早期胃癌的CAD 方法依然是值得研究的方向。模型优缺点对比详情如表3。
8 结束语
在胃镜图像的早期胃癌识别中,特征提取是早期胃癌识别的核心,基于传统颜色、形状、纹理的特征提取或者在深度学习方法下进行特征提取模型建立。基于CNN 的深度网络普遍可视为一个“端到端”的系统,可以对输入的图像进行处理后直接输出分类结果,然后通过测试集对该模型进行检测,检测其敏感性、特异性、准确性、漏诊率、误诊率。这是目前最能实现落地的技术方向。
早期胃癌的人工智能诊断系统难点之一就是数据集缺失,数据量不足导致实验结果不理想。想要解决数据集缺失的问题,可行的解决方法主要有两种方式:一是与医院加强合作,这样可以直接获得医生标注的数据,但因为经验丰富的医师和专家精力和时间有限,而且内镜数据的公开还会涉及到病人的隐私保护问题,所以通过这种方式得到的数据依然有限。二是在已有的数据集上通过技术手段扩展当前的数据,可以通过旋转、翻转和反转等简单的方式扩展数据,也可以通过GAN 等深度学习方法拼接出新的胃镜图像,以解决数据不足的问题。
胃镜图像的人工智能诊断目前依然有较高的漏诊和误诊率,发展计算机视觉的CAD方法,最终的人工智能诊断可以像一位资深内镜师一样对胃镜图像进行精准检测,让其自动识别病变图像,自动标注病灶区域。这样对于减轻医生负担,减少漏诊率,提高胃癌的治疗几率具有十分重要的意义。进一步提高人工智能下内镜的诊断准确率,有助于推动早期胃癌的治疗及诊断。
