面向土壤环境质量等级划分的统计推断与加密采样优化方法研究综述
2021-05-25高秉博郝朝展李发东胡茂桂李晓岚郜允兵潘瑜春
高秉博,郝朝展,李发东,胡茂桂,李晓岚,郜允兵,潘瑜春
(1.中国农业大学土地科学与技术学院,北京100083;2.农业农村部农业灾害遥感重点实验室,北京100083;3.中国科学院地理科学与资源研究所,北京100011;4.国家农业信息化工程技术研究中心,北京100097)
严格精准的环境管理与治理是实现生态文明与可持续发展战略的必由之路。为了加强生态环境保护,我国陆续发布了《大气污染防治行动计划》《土壤污染防治行动计划》和《水污染防治行动计划》,部署了环境管理治理任务与目标。将环境按照污染程度划分为不同等级以实施差别化管理与治理是我国环境管控的基本策略,同时不同污染等级的面积变化监测也是考核责任主体的主要手段。因此,环境质量等级划分是环境管理与治理的一项基本需求[1]。
在土壤环境质量调查和监测中,空间采样是目前最主要的手段。统计推断是采样的目的,决定采样点布局优化方法的选择。土壤环境质量等级划分是不同于均值估计、空间插值和热点探测的一种特殊的统计推断,其目的是准确估计未采样单元处污染物浓度与等级划分阈值之间的关系。由于空间相关性的存在,土壤环境质量等级在空间上的分布具有连续性,因此土壤环境质量等级划分的目的可以转化为确定不同环境质量等级间的边界。由于常规调查监测一般服务于多个目标且样点分布较为稀疏,为了提高土壤环境质量等级边界划分的准确性,通常需要在等级错误划分发生概率较大的地区进一步开展专项加密采样。但是由于其目标的特殊性,土壤环境质量等级划分需要具有针对性的统计推断与加密采样布局优化方法,以提高采样效率与等级划分精度[2]。
本文梳理了土壤环境质量等级划分统计推断与加密采样布局优化方法的研究进展,对比了理论方法的优势与不足,归纳了以等级划分为目的的统计推断方法与加密采样布局优化方法体系,并探讨了下一步研究的方向。
1 空间采样布局优化与统计推断之间的关系
采样,也称为抽样,通常指从研究对象全体中抽取一部分进行试验和观察,并获取试验数据的工作[3-4]。为了获得精度更高的土壤环境质量等级划分图(即获得研究区域中每个空间单元上污染物的环境质量等级),空间采样和统计推断仍然是目前最重要的方法。统计推断是采样的目的,指基于样本数据对产生样本总体的某些性质以概率的形式进行推断,从而获得对总体的认知。空间采样是土壤环境调查和监测的常用手段[5-8]。De Gruijter 等[9]认为,一个空间采样方案由样本布设和统计推断两部分组成,并将这些方法分为基于设计的方法和基于模型的方法两大类。基于设计的方法由概率采样和基于设计的统计推断方法组成,适用于获得总体参数的估计,如均值、标准差等全局变量;基于模型的方法由目的性采样和基于模型的统计推断组成,适合估计与具体位置相关的污染物浓度,如空间插值、热点探测和等级划分等[10-11]。而空间采样与统计推断三一准则(Trinity principle of spatial sampling and statistical inference)认为,调查精度由总体特征、样本布设方式、统计推断模型,以及三者之间的匹配关系所决定[12-13],不同的组合方法有不同的效率。因此,在具体土壤环境等级划分中,需要根据具体的统计推断目标、样本布设方式和研究区域变量特征制定合适的采样设计方法。本文依据空间采样与统计推断三一准则分析归纳面向土壤环境质量等级划分的统计推断与加密采样布局优化方法。
2 土壤环境质量等级划分统计推断方法
2.1 方法体系
环境质量等级划分方法可以按照等级划分依据分为物理阈值法和概率阈值法两类,如表1 所示。物理阈值方法首先对研究区域中每个空间单元的污染物浓度进行估计,然后通过对比估计值与物理阈值的大小确定待估计单元的环境质量等级。概率阈值方法则首先估计每个单元不超过物理阈值的概率,然后将所估计概率值与设定的概率阈值对比确定待估计单元的环境质量等级。物理阈值法和概率阈值法都需要对研究区域的每个空间单元进行估计。物理阈值法主要包括确定性方法、地统计方法、模糊数学方法和机器学习法。地统计方法按照估计的方式可以进一步分为物理值估计方法和不确定性估计方法[14-15]。物理值估计方法主要目标是根据样点估计环境变量在待估计单元的取值及其估计误差,如普通克里金、回归克里金和协同克里金等方法[16-20]。关于土壤环境物理值估计方法更全面的综述,请参见Goovaerts[21]、Li等[17-18]和史文娇等[22-23]的文章。不确定性估计的目标主要是构建待估计单元处污染物浓度的概率分布,该类方法可进一步分为参数法和非参数法两类。参数法通过假设待估计单元处污染物浓度的概率分布模型,并使用样本计算概率分布的关键参数如期望方差等,构建待估计单元处随机变量的概率分布。最常用的方法为multi-Gaussian 模型,它假设环境变量服从正态分布,并使用简单克里金的估计值和估计误差作为正态分布的期望和方差[21,24]。非参数方法并不预先假设待估计单元处环境变量分布的形式,只估计一些关键阈值所对应的累积概率,必要时使用内插和外插方法生成完整的累积概率分布函数[25]。模糊数学方法采用模糊隶属函数量化采样点与待估计单元之间环境相似程度,并据此进行土壤属性插值,是一种基于地理环境相似性的非监督学习方法。构建模糊隶属函数需要两种知识[26]:第一种类型称为Ⅰ型知识,定义特定土壤属性的典型环境条件;第二种类型称为Ⅱ型知识,定义了环境条件偏差带来的土壤属性变化,具体可参见Zhu等[26]、Yang等[27]、谢军等[28]的文章。机器学习法即统计模型的算法化,采用各种不同形式的基函数开展监督学习,并权衡训练样本拟合精度与模型泛化能力,如随机森林、提升树、人工神经元网络模型等,通过学习训练建立相关辅助变量与环境变量之间的关系以估算污染物浓度的空间分布[29-31]。
2.2 方法对比分析
环境质量等级划分方法比较分析如表2 所示。总体而言,物理阈值法由于需要首先估计未采样单元处污染物浓度,而不是直接估计环境质量等级,因此会引入额外的步骤与误差;而概率阈值可以直接判定未采样单元处污染物浓度与等级划分阈值之间的关系。在物理阈值法中,确定性方法虽然易于理解、参数较少且鲁棒性较强,但是用于环境质量等级划分和加密采样空间布局优化时存在明显不足。由于在土壤环境中经常面临研究对象知识掌握不全面且数据不足的情况,难以建立准确的确定性模型进行估计,因此每个估计结果都存在误差。而确定性方法不能给出计算结果的不确定性程度,同时也不能依据区域空间变异进行计算参数的自适应调整,因此不能有效指导土壤环境管理[32]。地统计方法能够实现插值参数的自适应调整,给出插值结果及其不确定性,而且其中的协同克里金、回归克里金等方法还能利用辅助变量信息提高插值精度。但是其中的物理值估计方法在用于指导土壤环境质量等级划分时也存在明显不足:一方面,由于其估计值存在平滑效应,在处理较大或较小阈值的等级划分时存在较大误差,甚至会造成划分结果中等级的丢失;另一方面,其估计误差假设为正态分布,且假设误差只与样点位置有关,难以符合实际情况,不能准确反映估计结果与阈值关系的不确定性[33]。而其中的不确定性估计方法用于估计空间单元污染物浓度时,需要首先计算获得其概率分布,然后基于概率分布估计污染物浓度,如使用期望估计(E-type estimate)、中位数估计(Median esti⁃mates)和百分位数估计(Quantile estimates)等损失函数(Loss function)对污染物浓度进行优化估计[21,34]。在优化估计过程中需要完整的累积概率分布模型,而参数法由于其较强的分布假设难以获得较好的结果,非参数法则会因需要概率内插和外插而引入较大的误差。模糊数学方法能够充分利用先验知识和土壤环境相关辅助数据提高土壤属性的插值精度,同时也能给出对插值结果的不确定性估计,但是该方法通常过分依赖先验知识,没有进行样本的监督训练,而且对空间位置关系的考虑不足。机器学习法的优势在于有效处理多维多类型辅助变量,能充分挖掘利用辅助变量与环境变量之间的相关关系提高插值精度,部分方法还能给出插值结果的不确定性,目前已经成为数字土壤制图的主流方法。不足之处在于目前的机器学习方法需要较大样本量进行模型训练,目前尚不能有效融合空间相关性与异质性解决稀疏样点条件下的插值精度问题[35-36]。

表1 环境质量等级划分方法体系Table 1 Environmental quality classification method system

表2 土壤环境质量等级划分方法比较分析Table 2 Comparison of soil environmental quality classification methods
概率阈值法由于需要获得关于物理阈值的概率,只能与不确定性估计方法结合进行环境质量等级划分。其中非参数方法由于没有较强的分布假设,同时在等级划分时只需要阈值所对应的累积概率,因此更适 合 用 于 环 境 质 量 等 级 划 分[32,37]。Antunes 等[38]和Chica-Olmo 等[39]探讨了基于概率阈值方法的空间等级划分,但是这些研究仅止步于将环境质量等级划分问题转化为基于概率阈值的等级划分问题,而对于如何确定概率阈值并没有给出有效的解决方案。高秉博[40]提出了基于指示克里金估计概率及其不确定性的土壤环境等级错误划分方法,建议概率阈值以0.5为基础,依据实际需求进行调整,但未给出定量的确定方法。Gao等[41]在此基础上提出了基于交叉检验的自适应概率阈值确定方法,如图1 所示,通过设定不同的概率阈值并进行交叉检验,获得研究区域环境质量等级划分的第一类错误、第二类错误和总错误随概率阈值变化的曲线,并依据曲线的特征点确定概率阈值,如总错误曲线最低点、第一类错误曲线与第二类错误曲线交叉点等。该方法能够适应不同区域数据分布的特点,提供了一种定量确定概率预知的方法。李晓岚等[42]将该方法拓展到时空维,基于时空克里金统计推断结果与概率阈值自适应确定方法,完成了北京市农田土壤重金属含量的等级划分。
3 土壤环境质量等级划分加密采样布局优化方法
3.1 方法体系
当多阶段采样或补充调查需要额外的加密样本时,采样布局优化尤其重要。为了提高土壤环境质量等级划分的精确性,应优化采样布局,使用更少的样点获得更高的等级划分精度。采样方法是否适合取决于采样的目标,当以土壤环境质量等级划分作为统计推断目标时,不需要强调每个空间单元的污染物浓度或全局平均浓度的估计精度,而需要精确估计未采样单元上污染物浓度与等级划分阈值之间的大小关系,以实现对土壤环境质量等级的准确划分。由于土壤环境变量的空间自相关性,土壤环境质量等级在地理空间上具有连续性,因此加密采样时应该将更多样点布设在等级过渡地带[32]。按照加密采样布局优化目标设定的依据,可以将环境质量等级划分加密采样布局优化方法分为估计值准确度和等级划分精确度两类,具体如表3所示。
依据估计值准确度加密采样布局优化方法包括随机采样和目的性采样。随机采样中分层随机抽样在实际中应用比较广泛,它基于先验知识、历史调查数据或辅助数据,首先将研究区划分为内部方差较小的若干个较为均质的子区域,然后为每个子区域分配样本量并分别布设样点。目的性采样方法主要通过设定优化目标函数并使用优化求解方法生成采样布局方案[43]。常见方法可以分为统计推断误差最小优化方法、地理空间分布优化方法、特征空间分布优化方法、地理空间与特征空间分布同步优化方法四类[44]。统计推断误差最小优化方法一般以最小、最大或者平均统计推断误差作为优化目标函数进行优化布样,如普通克里金误差[45-47]、协同克里金误差[48]、泛克里金插值误差[5,49]、泛协克里金误差[7]和非均质表面估计模型误差(Mean of Surface with Nonhomogene⁃ity,MSN)[2]等。地理空间分布优化方法通过设计候选样点与待估计点之间的距离函数并将距离函数作为优化目标,常见的目标函数包括平均最短距离最小(Minimization of the Mean of the Shortest Distances,MMSD)[50]、加权平均最短距离最小(Weighted Mean of the Shortest Distances,WMSD)[51]、均方距离准则(Mean squared distance to sides,vertices,and boundaries)[52],还包括同时优化插值制图精度与半变异函数精度的组合方法,如Simbahan 等[53]提出结合MMSD 与WM准则(Warrick-Myers criterion)[54]的样点空间分布优化方法。特征空间分布优化方法主要优化样点在辅助变量组成的特征空间中的分布,如按照辅助变量分布比例分层的等间距分层设计(Equal Range Stratification design,ER design)[55],特征空间等概率间距分层与优化覆盖的拉丁超立方体方法(Latin Hypercube Sampling,LHS)[56]及条件拉丁超立方体方法(Conditioned Latin Hypercube Sampling,cLHS)[57]。地理空间与特征空间分布同步优化方法同时优化样点在地理空间与特征空间的分布,解决空间非平稳区域变量插值的采样优化问题,包括基于辅助变量的方差四叉树分步优化方法(Variance Quad-tree)[58]和地理空间与特征空间同步优化的空间条件拉超立方体方法(Spatial Conditioned Latin Hypercube Sampling method,SCLHS)[2]等。

表3 土壤环境质量等级划分加密采样布局优化方法体系Table 3 Soil environment quality grade with additional sampling layout optimization method system
等级划分精确度加密采样布局优化方法直接以等级划分精确度为采样优化目标,主要分为基于等级估计结果的布样方法和基于等级估计结果及其不确定性的布样方法。前者使用前阶段获取的样本数据估计未采样单元属于某一环境质量等级的概率,并基于该概率指导加密样点布设。如Garcia 等[59]认为,在使用非参数估计方法指导布样时,概率值低于0.2、高于0.8 的位置不大可能出现等级错划的情况,因此需要重点在概率值介于0.2~0.8 之间的区域进行采样。该类方法忽略了等级概率估计本身的不确定性,同时划定的采样范围较大,效率不高。后者综合考虑等级估计结果及其不确定性指导样点布设。如Van Meir⁃venne 等[32]提出的基于条件模拟的加密采样方法,该方法首先基于前期样本数据产生大量的模拟数据,以模拟值与阈值差异的(累积概率的)标准差和期望之比来衡量等级划分的不确定性,用于指导加密采样布局优化。该方法在估计中需要进行大量的条件模拟计算,同时还需要完整的累积概率分布函数,会引入累积概率分布函数内插和外插的误差。Juang 等[60]基于阶次地统计提出了包含等级划分中第一类和第二类错误的错划指数,高效地综合了等级估计结果及其不确定性。但是在该方法中物理阈值需被转化为标准阶次并在标准阶次中进行计算分析,在将物理阈值转化为标准阶次时会带来较大误差,如果样本在特征空间的代表性较差,则会从根本上影响该方法的准确性[61]。另外,该方法固定以估计值上下3 倍的标准差作为两类错误的置信区间,不能基于具体需求调整对两类错误的偏好。Gao等[62]基于多高斯模型提出了针对正态分布(或能够转化为正态分布)数据的等级划分错误指数,基于克里插值结果、误差方差和物理阈值量化发生等级划分错误的概率,如公式(1)所示。
Index=G(threshold,ẑ0,δ2)/G(ẑ0,ẑ0,δ2) (1)式中:G为高斯分布函数;threshold为等级划分的概率阈值;ẑ0为克里金插值结果;δ2插值的误差方差。
如图2 所示,其中蓝色与绿色曲线为由待估计点的插值结果和估计方差确定的归一化高斯分布,红色竖线为等级划分物理阈值(90 mg·kg-1),其中图2(a)为估计结果相同但估计误差不同的两点的等级划分错误指数,图2(b)为估计误差相同但估计结果不同的两点的等级划分错误指数,由图可知,估计结果越接近阈值且估计误差越大,越容易发生等级划分错误。Gao等[62]定义了基于该指数的等级划分加密采样优化目标函数,并基于空间模拟退火方法(Spatial Simulated Annealing,SSA)实现了加密样点位置优化布设。
由于土壤环境数据经常不符合正态分布并且难以转化为正态分布,Gao 等[41]基于指示克里金估计结果及其不确定性构建了等级划分错误指数,如公式(2)所示,它由阈值错划指数和误差错划指数两部分组成,阈值错划指数反映了累积概率估计值与阈值的接近程度,如图3(a);误差错划指数反映了累积概率估计值的不确定性,如图3(b);由于概率分布的分布为均匀分布,因此使用线性相加的方式组合阈值错划指数与误差错划指数形成综合错划指数,如图3(c)。
Gao 等[41]进一步推荐采用平均错划指数最小、最大错划指数最小等作为优化目标函数,采用图1 的自适应方法确定概率阈值,并基于优化算法进行土壤等级划分加密采样布局优化。基于多高斯模型的等级划分错误指数和基于指示克里金的等级划分错误指数分别针对正态分布数据和非正态分布数据,通过简单的数学变换综合考虑估计结果与阈值关系的不确定性,能够刻画出土壤环境质量等级可能的边界,可在多阶段采样或补充调查的加密采样布局优化中选用。
3.2 方法对比分析
环境质量等级划分方法比较分析如表4 所示。分层随机抽样能够考虑环境变量的分层异质性,提高样本代表性,但是关注样点对整个区域的代表性,不能重点关注等级过渡地带,因此适用于均值估计,而不适用于等级划分。在目的性抽样方法中,统计推断误差最小优化方法能够充分利用统计推断模型及参数直接提高样点布设效率;地理空间分布优化方法基于空间自相关性指导样点布设,不需要先验知识和辅助数据;特征空间分布优化方法能够充分利用相关辅助变量指导样点布设,提高样本对环境变量变化特征的代表性;而地理空间与特征空间分布同步优化方法则兼顾了地理空间与特征空间分布,能够同时提高样本对地理空间和变量变化特征的代表性。但是总体而言,依据估计值准确度加密采样布局优化方法没有考虑土壤环境质量等级划分加密采样优化的特殊性,不能重点关注等级过渡地带。而在土壤环境质量等级划分加密采样布局设计中,由于空间自相关性的存在,空间单元的质量等级具有空间连续性,在等级过渡地带(即在值域上接近阈值的区域)更容易发生等级错划,应加密样点;而在远离过渡地带(即在值域上远小于或大于阈值)的区域,增加过多的样点无益于等级划分准确性的提高[32]。因此,依据估计值准确度的加密采样方法效率较低,适用于土壤环境质量空间插值,而不适用于土壤环境质量等级划分。
依据等级划分精确度的加密采样布局优化方法直接以等级划分精确度为采样优化目标,将样点布设在容易发生等级错误划分的区域[2]。其中基于等级估计结果的加密采样布局优化方法,使用前阶段采样数据估计每个空间单元等级概率并据此进行加密样点布设,侧重于在等级过渡地带进行加密布点。但是由于前阶段采样的样本量不足,导致对等级概率的估计存在不确定性,而该类方法忽略了等级概率估计本身的不确定性,会导致等级过渡带划分不够精细和准确。基于等级估计结果及其不确定性估计的加密采样布局优化方法,在划定不同环境质量等级过渡带时综合考虑了等级概率估计结果及其不确定性,能够获得较合理的等级错误划分概率,进而提高加密采样的布设效率。目前该类方法不足之处在于未充分利用多维辅助变量信息,提高加密样点布设效率。
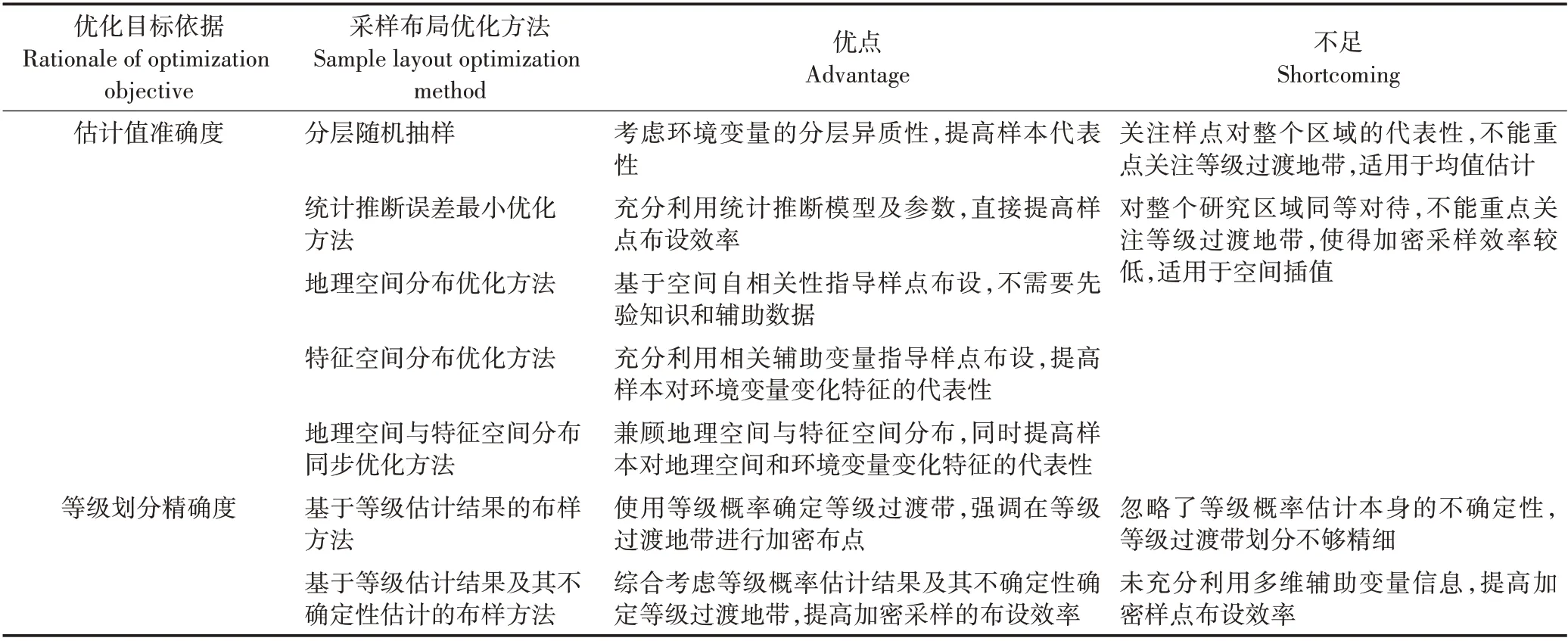
表4 环境质量等级划分加密采样布局优化方法体系Table 4 Soil environment quality grade with additional sampling layout optimization method system
4 结论与展望
4.1 结论
目前,土壤环境质量等级划分统计推断与加密采样布局优化研究已经取得了较大进展。环境质量等级划分统计推断方法可以分为物理阈值法和概率阈值法,两类方法各有优缺点。其中物理阈值法由于需要首先精确估计未采样点的含量,而不是直接估计环境质量等级,因此会引入额外的步骤与误差。而概率阈值法直接以环境质量等级估计为目标,其中非参数估计不需要完整的概率分布,只需要估计与等级划分阈值大小关系的概率,更加适合土壤环境质量等级划分。对应于两类环境质量等级划分统计推断方法,加密采样布局优化也可以分为依据估计值准确度和等级划分精确度的两类方法。前者以研究区域各个空间单元处污染物浓度精确估计为目标,对整个研究区域同等对待,未针对等级边界,采样效率较低。后者以降低等级划分错误为目标,重点将样点布设在等级边界过渡地带,具有更好的采样效率。其中基于等级估计结果的布样方法仅采用候选样点属于某一环境质量等级的估计概率指导加密样点布设,未考虑估计概率的不确定性。而基于等级估计结果及其不确定性估计的布样方法,综合考虑了具有不确定性参数的估计值与等级划分阈值的关系,能够刻画出土壤环境质量等级之间可能的边界带,为多阶段采样或补充调查的加密样调查提供加密采样布局优化方案。
4.2 展望
虽然土壤环境质量等级划分统计推断与加密采样布局优化方法已经初步形成一套理论方法体系,但是土壤环境质量空间格局复杂,影响因素多样,为了能进一步满足土壤环境质量等级划分实际工作需求,作者认为还需要进一步研究解决以下三方面的问题:
(1)土壤环境相关辅助数据使用问题:随着土壤环境相关数据的积累,如何在土壤环境质量等级划分的加密采样布局优化和统计推断中充分应用辅助数据,以提高采样效率和等级划分精度。
(2)样本量的确定:如何根据具体的应用需求(如划分修复区边界、划分农用地环境质量类别等),确定环境质量等级划分的等级属性精确度与等级边界空间的精确度参数,进而结合这些参数确定加密调查所需样本量。
(3)如何进行多阶段协同采样优化:目前统计土壤环境质量等级划分加密采样优化大都针对后续加密调查阶段的布样优化,对于没有历史调查数据的区域(如确定废弃工矿区的污染修复边界),如何综合考虑采样成本与等级划分精度,划分调查阶段,在阶段间分配样本量并制定各阶段的样点优化布局方案。
随着土壤污染防治法的实施,我国土壤环境质量等级划分需求将不断增加。目前即将完成全国农用地土壤环境质量类别划分,下一步将开展农用地土壤环境质量类别动态调整和安全利用工作,需要开展大量的土壤环境质量等级划分与加密采样工作,由于我国已经积累了大量农用地土壤污染采样数据,建议后续工作中采用具有针对性的土壤环境质量等级划分加密采样布局优化和统计推断方法(如概率阈值法),基于等级划分精确度的加密采样布局优化方法或者具有针对性的其他先进方法。随着我国土壤污染修复行业不断发展壮大,在划定修复区时,建议采用先进的土壤环境质量等级划分采样布局优化和统计推断方法,在污染修复区范围划定中同时考虑修复成本与健康风险,实现科学决策。
