基于CEEMDAN多尺度熵和SSA-SVM的滚动轴承故障诊断研究*
2021-05-24李焕锋刘自然
李 怡,李焕锋,刘自然
(河南工业大学 机电工程学院,河南 郑州 450001)
0 引 言
滚动轴承作为旋转机械的重要组成部分,一旦发生故障时,旋转机械就会受到很大的影响。因此,对滚动轴承故障诊断研究是十分必要的[1]。
在故障特征提取方面,自适应白噪声完整经验模态分解(CEEMDAN)是Torres等人在集合经验模态分解(EEMD)算法的基础上,提出来的一种信号处理算法[2]。该算法对EEMD算法进行了优化处理。与EEMD算法相比,CEEMDAN算法改善了分解的完整性,降低了重构的误差,还提高了分解的效率。
在故障分类方面,支持向量机(SVM)被广泛应用于机械故障诊断方面[3]。它在解决非线性、小样本以及高维模式识别的问题中有很好的表现[4]。但在SVM中,惩罚因子C以及核函数参数σ的取值对故障诊断的准确性起决定性的作用[5]。为了提高SVM故障识别的准确率,张小龙等人[6]提出了一种基于ITD复杂度和PSO-SVM的滚动轴承故障诊断。赵蕾等人[7]提出了一种基于FOA-WPT降噪和PSO-SVM的滚动轴承故障诊断方法。时培明等人[8]提出了一种基于分形维数和GA-SVM的轴承故障诊断方法。然而传统的智能算法在优化SVM参数时,存在寻优速度慢、调节参数多,以及容易陷入局部最优值等问题,从而导致其故障分类的准确率较低。
本文引入一种麻雀搜索算法优化支持向量机(SSA-SVM),提出一种基于CEEMDAN多尺度熵与SSA-SVM相结合的故障诊断方法,用于轴承故障诊断,并通过实验来证明该方法能够准确地获得故障信息,且故障识别效果更好。
1 故障特征提取
1.1 CEEMDAN算法
设x(t)为实验数据,则CEEMDAN算法对信号分解过程具体如下:
(1)IMF1分量与EEMD算法分解得到的IMF1分量相同;
(1)
从x(t)中去除IMF1(t)得残余分量r1(t):
r1(t)=x(t)-IMF1(t)
(2)
(2)采用EMD算法将N次高斯白噪声分解,获得IMF和残余分量r1(t)相加,再通过EMD算法,取均值得到的第一个IMF,将其作为IMF2(t):
(3)
式中:E1(.)—通过EMD算法提取的第1个IMF;vi—单位方差均值为0的高斯白噪声;ε1—幅值。
则第二个残余分量为:
r2(t)=r1(t)-IMF2(t)
(4)
(3)重复上面步骤,可求得第j个IMFj(t)和残余分量rj(t);
(5)
rj(t)=rj-1(t)-IMFj-1(t)
(6)
若残余分量不能在被分解,则中断上述过程,此时信号x(t)为:
(7)
1.2 多尺度熵
多尺度熵是计算不同时间尺度下信号的复杂程度[9]。它具有良好的抗干扰和抗噪效果[10]。当一个信号越复杂,波动越大,多尺度熵就越大;同样,信号越规则,波动越小,多尺度熵就越小。
该算法详细步骤如下所示:
(1)粗粒化处理。粗粒化处理时间序列就表示为对不同数量的连续点取平均值,来创建不同尺度的信号,即:
(8)
式中:xi—时间序列;τ—时间尺度。
(2)求各时间尺度下,经过粗粒化处理过的信号的样本熵记MSE,即:
MSE(X,τ,m,r)=SampEn(y(τ),m,r)
(9)
式中:m—嵌入维数;r—相似容量。
2 麻雀搜索算法优化支持向量机
2.1 支持向量机
SVM自身理论比较复杂,难于理解,所以研究人员自己实现该算法有难度。但是通过多年的摸索与研究,现在已经有许多研究人员研究出了相关的软件包,故直接安装运行即可。该实验采用的SVM是Libsvm软件包中的一个部分。
在采用SVM进行故障分类时,确定适合的核函数、惩罚因子C以及核函数参数σ是SVM的核心[11]。
基于径向基核函数(RBF)有很强的局部性能以及抗干扰等特点,在轴承故障诊断中SVM常选择RBF核函数。因此,惩罚因子C以及核函数参数σ的取值对SVM故障识别的准确性至关重要。
2.2 麻雀搜索算法
麻雀搜索算法(sparrow search algorithm, SSA)是薛建凯等人[12]于2020年基于麻雀的觅食行为和反捕食行为提出的一种新的群智能优化算法。该算法具有全局搜索能力强、寻优速度快、收敛速度快等优点。
SSA的社会行为可以通过以下列数学模型来描述:
假设麻雀种群表示为:
(10)
式中:n—麻雀的数量;d—要优化的变量的维数。
则所有麻雀的适应度值可以用以下向量来表示:
(11)
式中:FX中每一行的值—个体的适应度值。
在搜索过程中,适应度较高的麻雀会先得到食物。探索者作为麻雀种群的领导者负责搜索食物,且提供搜索食物的方向,故探索者的搜索食物范围最大。
当麻雀种群周围存在没有捕食者时,探索者可以随意进行食物搜索;一旦发现了周围存在捕食者,探索者会带着追随者向安全地方移动。
探索者的位置如下:
(12)
式中:t—当前迭代次数;itermax—最大迭代次数;Xij—第i个麻雀在第j维的位置信息;α—随机数,α∈(0,1];R2—预警值,R2∈(0,1];ST—安全值,ST∈(0.5,1];Q—服从正态分布的随机数;L—1×d的矩阵,其中该矩阵内每个元素全部为1。
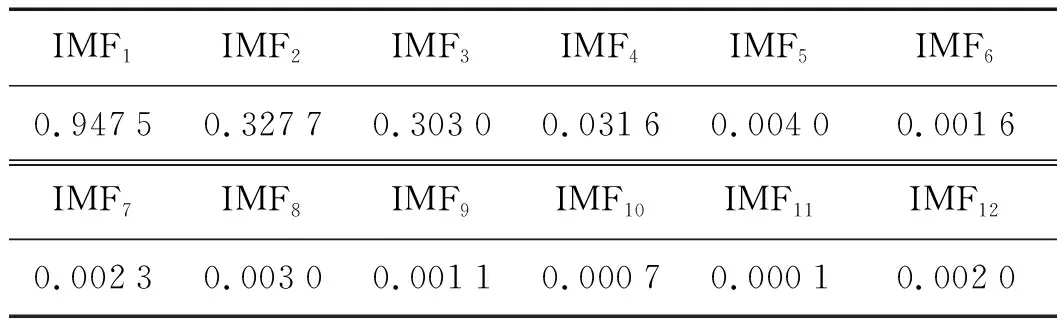
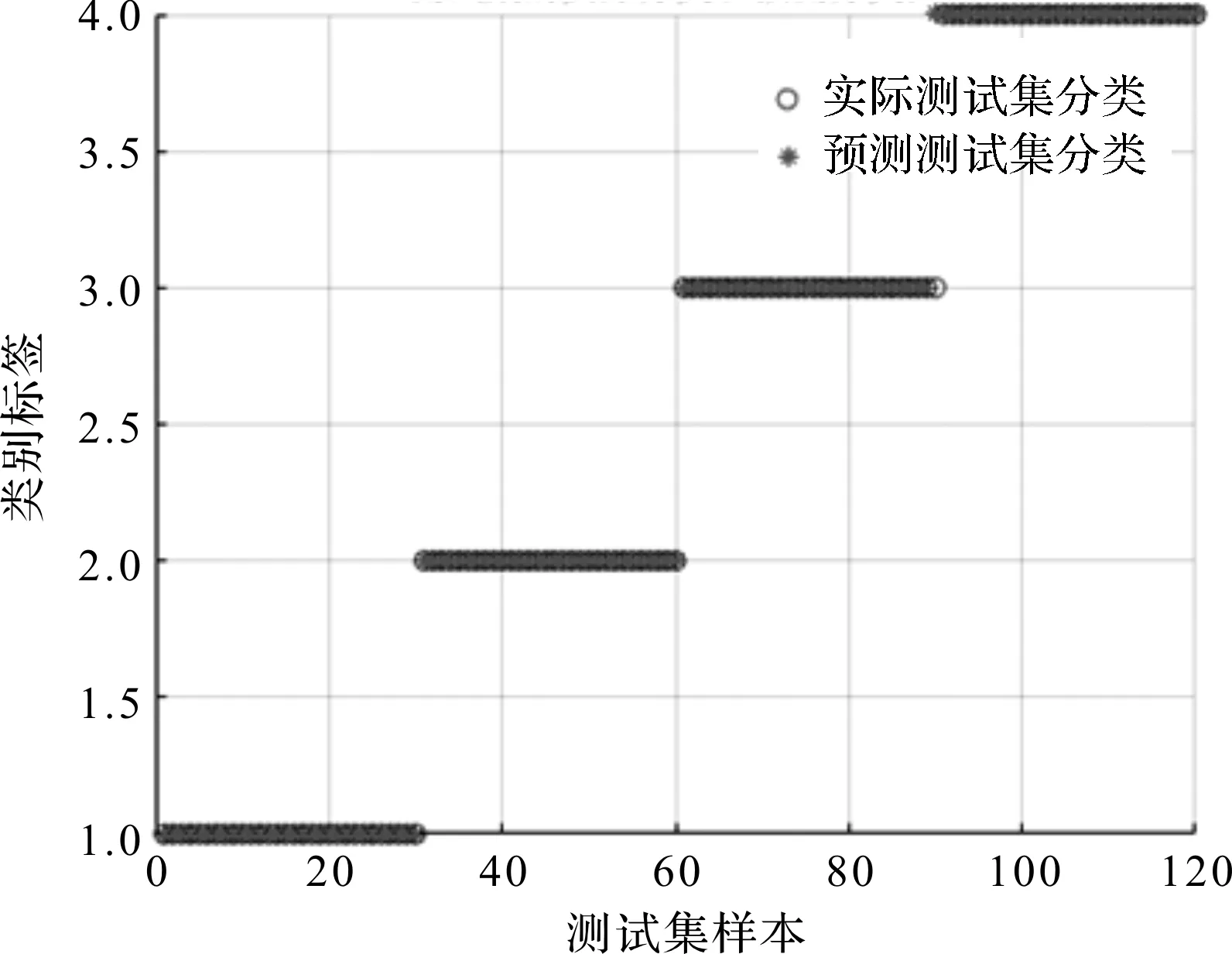
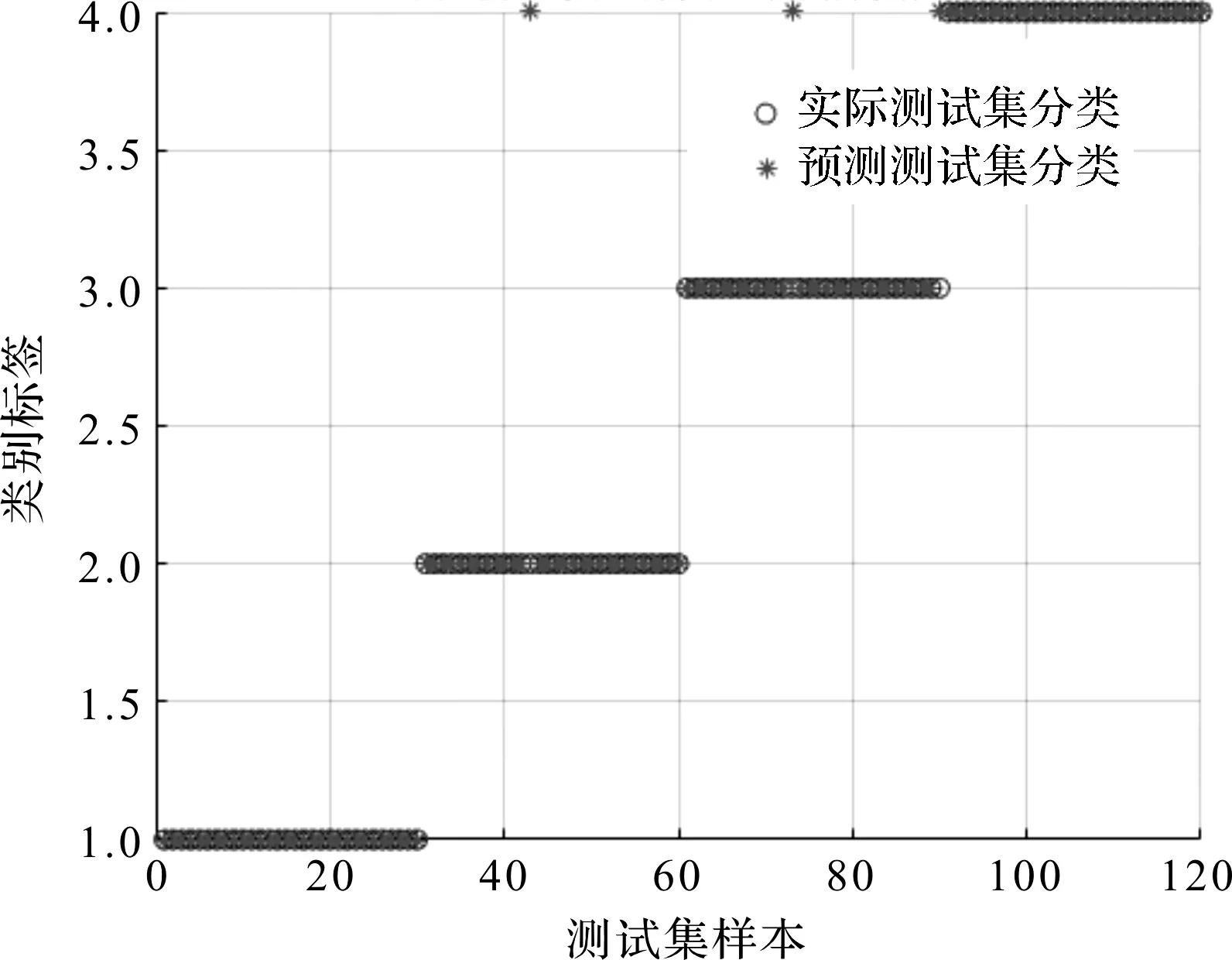
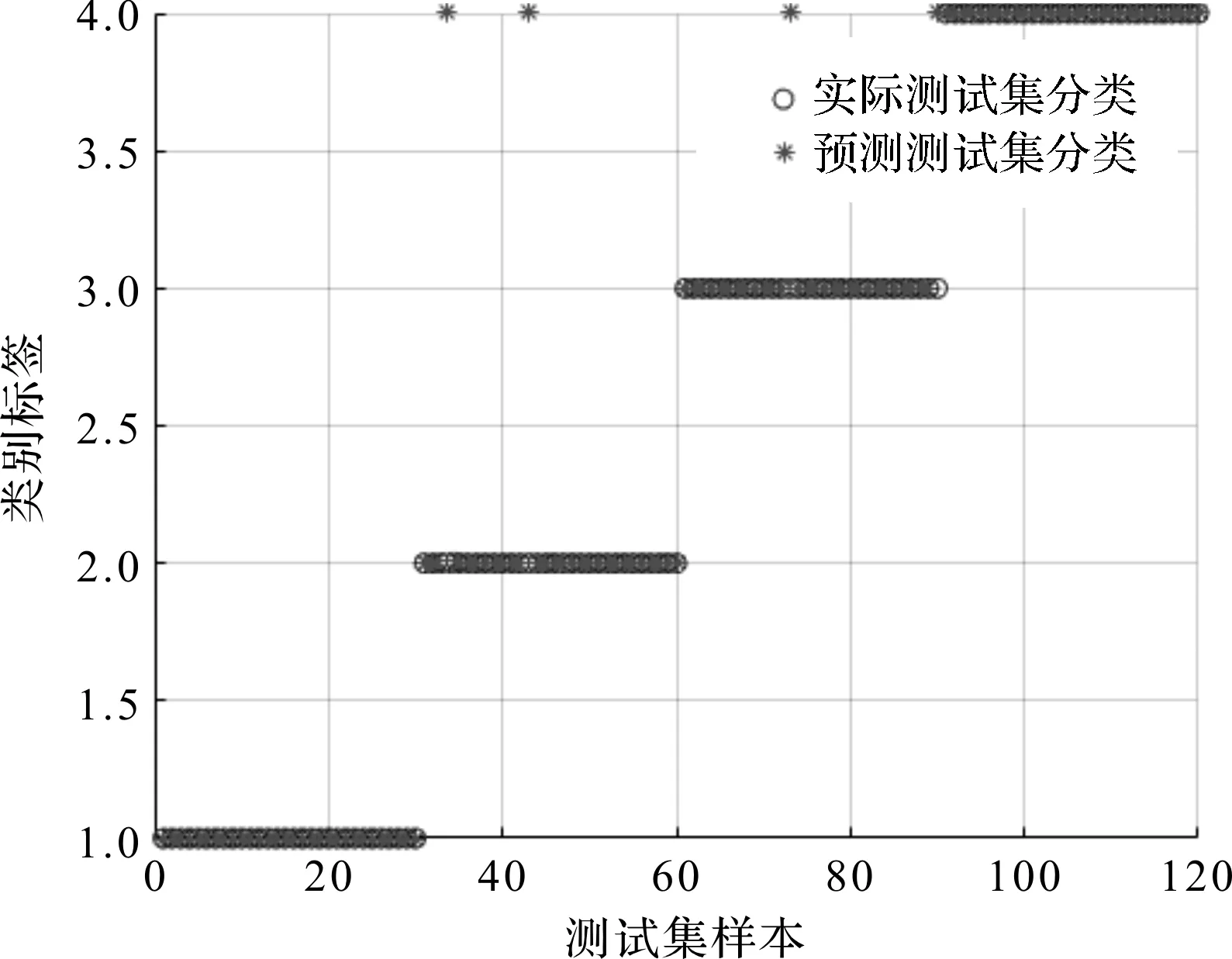
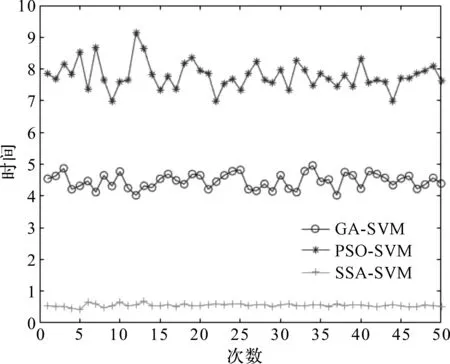
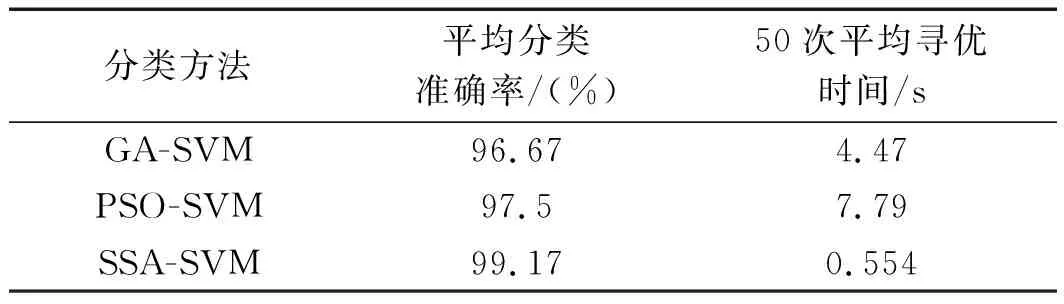
当R2 在整个麻雀种群中,探索者与追随者的比重是不变的,只要能够找到好的食物,就能成为探索者,反之就是追随者。麻雀种群中追随者的觅食环境与范围很差,因此,它们就会随时注意探索者的情况并与探索者争抢食物,若抢夺成功,它们就会获得探索者的食物代替去更远的地方搜索食物。 则追随者的位置为: (13) 式中:Xworst—全局最差位置;Xp—当前发现者中最优位置;A—代表一个1×d的矩阵,其中该矩阵内每个元素为1或-1,并且A+=AT(AAT)-1。 当i>2/n时,表示此时追随者没有获得食物,需要去更远的地方搜索食物。 在整个麻雀种群中,假设警惕者占总数量的10%~20%,且警惕者的初始位置是在种群中随机分布的,当警惕者意识到周围存在捕食者时,外围的麻雀将快速地向安全的地方飞行,来获取优越的搜索环境;内部的麻雀将在安全区域内一直走动,减少被捕食概率。 警惕者的数学模型为: (14) 式中:Xbest—当前的全局最优位置;β—步长且服从标准正态分布;K—代表一个随机数,K∈[-1,1];fi—当前麻雀个体的适应度值;fg—当前全局最佳适应度;fw—当前全局最差的适应度值;ε—常数,以避免分母出现0。 当fi>fg时,表示外围麻雀发现捕食者;反之,中间麻雀发现捕食者。 SSA-SVM的具体优化步骤如下: (1)设置SSA算法中的麻雀群总数n,最大迭代次数itermax,发现者的比例、追随者的比例以及C、σ的取值范围,随机初始化麻雀种群; (2)计算每个麻雀的适应度,并进行排序,定义每只麻雀所属于的种群; (3)根据式(12~14)更新每种麻雀种群的位置; (4)对更新位置后的每只麻雀重新进行适应度计算,对更新前后的适应度进行对比,保留更优的适应度继续进行更新; (5)判断迭代次数是否为itermax。若不是itermax,跳到(2)继续进行,直到为itermax为止,终止运行; (6)得到的最优的适应度Xbest的位置就为SVM的参数C和σ。 基于CEEMDAN多尺度熵-SSA-SVM故障诊断流程如下: (1)将振动信号随机分为训练样本和测试样本,利用CEEMDAN算法对其分解得到若干IMF; (2)提取敏感IMF并进行信号重组和多尺度熵的计算,然后进行归一化处理作为提取的特征向量; (3)将得到的故障特征向量经SSA-SVM进行故障诊断。 其总体流程示意图如图1所示。 图1 流程示意图 为了检验上述过程的真实性,笔者采用美国西储大学公开的电机轴承数据进行研究[13-15]。 被测轴承为6205-2RSJEMSK,采用的数据为驱动端数据;其采样频率是12 kHz,转速为1 797 r/min。 此处分别取轴承正常状态、内圈故障、外圈故障和滚动体故障4种状态下的振动信号各60组,训练与测试样本各30组,每组样本的采样长度为2 048个点。 其中,多尺度熵中τ=10,r=0.15S(S—样本的标准差),m=2。滚动轴承4种状态的标签为1~4。 实验所采用的4种状态的时域图如图2所示。 图2 4种状态的时域图 该实验将4种状态下的数据通过CEEMDAN算法进行分解,共获得12个IMF。 因为篇幅关系,此处只给出内圈故障状态下通过CEEMDAN算法提取的前5个IMF,如图3所示。 图3 内圈故障信号CEEMDAN处理结果 由于若干IMF中存在一些没用信息,则选取相关系数超过0.1的IMF作为有用信息保留。 各个IMF相关系数大小如表1所示。 表1 各个IMFS的相关系数值 根据表1可得,超过0.1的为IMF1、IMF2、IMF3,并对IMF1、IMF2、IMF3进行信号重组。 对重组信号求取尺度熵,并作为特征向量分别输入到PSO-SVM、GA-SVM以及SSA-SVM中,进行对比试验。 其中:每种SVM模型迭代次数为100次,种群数量为20。 SSA-SVM模型的单次分类准确率如图4所示。 图4 SSA-SVM模型的单次分类准确率 PSO-SVM模型的单次分类准确率如图5所示。 图5 PSO-SVM模型的单次分类准确率 GA-SVM模型的单次分类准确率如图6所示。 图6 GA-SVM模型的单次分类准确率 通过图(4~6)可知: GA-SVM模型与PSO-SVM模型对正常状态分类与外圈故障准确,但将内圈故障与滚动体故障不同程度的识别成了外圈故障。而SSA-SVM模型对正常状态、内圈故障与外圈故障均识别正确,仅在滚动体故障识别出现略微错误。 为了使该实验的实验结果更有说服力,笔者将GA-SVM、PSO-SVM以及SSA-SVM模型均进行50次实验。 实验环境为在2.40 Hz的英特尔i5-9300H处理器和8 GB内存电脑上的Matlab2016a中进行的。 此处笔者选用平均准确率和3种优化算法对SVM参数C与σ寻优的50次平均时间作为指标,对3种SVM模型的分类性能进行分析比较,可以很清楚地得出3种模型的差异。 GA-SVM、PSO-SVM以及SSA-SVM模型的50次寻优时间如图7所示。 图7 3种模型50次寻优时间 3种模型的比较结果如表2所示。 表2 3种模型的比较结果 通过对图7与表2分析可得: GA-SVM模型的平均寻优时间4.47 s且寻优时间略不稳定,平均分类准确率为96.67%,该模型的故障诊断效果最差;PSO-SVM模型的寻优时间高于GA-SVM且寻优时间极差较大,但平均分类准确率略提高了0.83%。SSA-SVM模型与其他两种模型相比,其平均寻优时间最短,每次的寻优时间较为稳定以及平均分类准确率最高。 综上所述,SSA-SVM模型的分类准确度高,寻优速度快,在轴承故障诊断中表现出了更好的故障诊断性能。 针对支持向量机(SVM)应用在轴承故障分类时,传统的智能算法优化SVM的参数容易存在寻优速度慢、调节参数多,以及容易陷入局部最优值等问题,本文提出了一种基于CEEMDAN多尺度熵与SSA-SVM相结合的故障诊断方法。 该故障诊断方法利用CEEMDAN多尺度熵对数据进行了故障特征提取,再利用SSA-SVM对提取的故障特征进行了分类;并对美国西储大学公开轴承故障数据进行了PSO-SVM、GA-SVM以及SSA-SVM模型对比实验。 实验结果表明:相比于PSO-SVM与GA-SVM模型,SSA-SVM模型具有更快的收敛速度、更好的分类效果以及更短的寻优时间等优点,对研究其他方向有一定的参考价值。2.3 SSA-SVM的优化步骤
3 基于CEEMDAN多尺度熵-SSA-SVM故障诊断流程
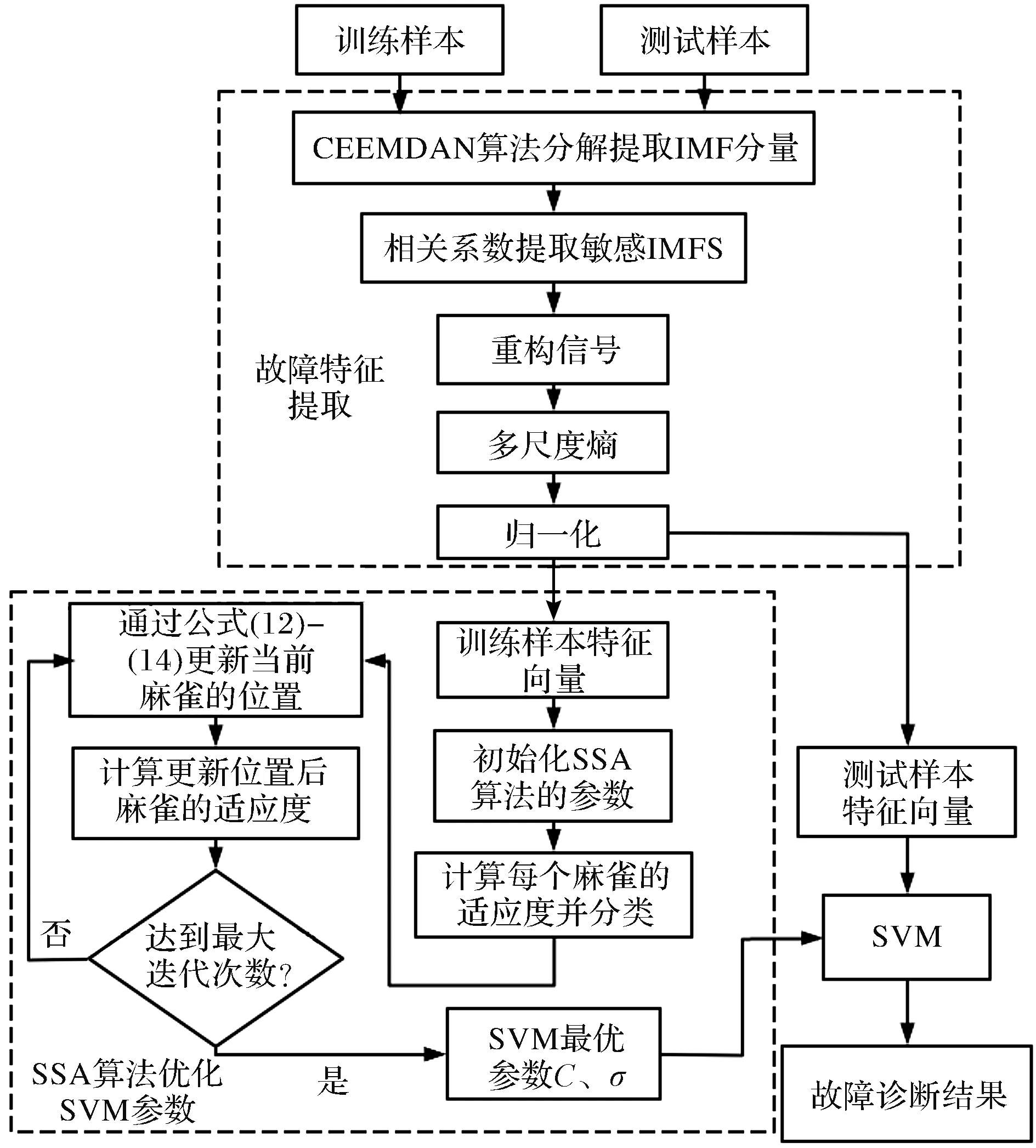
4 实验及结果分析
4.1 实验数据准备
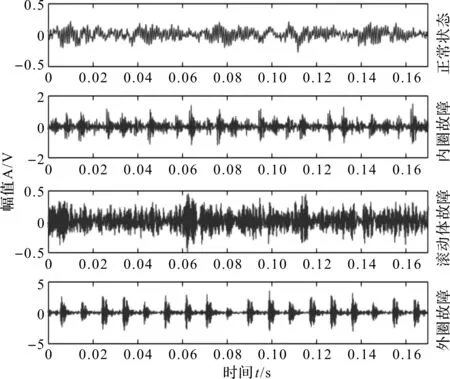
4.2 实验结果分析

5 结束语
