基于字符卷积神经网络的违法URL识别
2021-05-23汪俊明俞诗博李素云
汪俊明 俞诗博 李素云


摘要:违法URL是网络违法犯罪传播的方式之一,当前,依托互联网进行的诈骗、赌博等违法行为日益猖獗,上当受骗者众多,严重危害人民群众财产安全和正常生活秩序。针对上述问题,该实验利用深度学习方法,挖掘历史违法URL数据特征,建立违法URL快速识别模型,为打击网络犯罪提供支撑。
关键词:深度学习;神经网络;恶意URL
中图分类号:TP183 文献标识码:A
文章编号:1009-3044(2021)11-0181-03
近年来,随着移动网络应用的蓬勃发展,依托互联网进行的违法行为日益猖獗,通过App、网站进行的网络犯罪现象持续高发,虽然经过公安、电信、银行、互联网企业等单位的多方努力,进行了大量宣传、采取各种防范措施,但上当受骗者仍不在少数,严重危害人民群众财产安全,扰乱正常生产生活秩序,已成为影响社会稳定的突出问题。特别是网络诈骗,具有方式多样、手段翻新快、隐匿性强、技术化程度高、目标针对性广等特点,大量诈骗通过短信和通联应用向不特定对象传播、发送恶意URL,诱使当事人访问违法页面,进而落入各种诈骗陷阱。因此,及时准确识别违法URL,采取有效措施预先防范潜在违法行为,是构建网络安全防护体系的重要环节。
本文提出了一种基于字符卷积神经网络(Char-CNN)的违法URL识别算法[1],在第一节中,我们介绍当前识别违法URL的主流技术手段;第二节中,我们对本文提出的违法URL识别算法进行了详细介绍,第三节报告该算法在真实数据上的实验结果,最后对算法的应用进行了总结。
1 相关技术
1.1 启发式学习
针对违法URL的识别,黑名单是使用时间最久且目前仍然广泛使用的技术。使用黑名单作为违法URL的判别标准具有明显的优势和劣势,一方面,由于黑名单数据均经过人工确认,正确率高;另一方面,违法URL活跃时间较短,历史积累的黑名单数据随着时间推移会逐渐失效,基于人工举报、标记的黑名单数据更新速度远低于犯罪分子启用新URL的速度,导致无法识别新近出现的违法URL,漏报率高,仅能提供给较低程度的防护[2]。
为弥补其缺点,启发式算法应运而生。启发式算法利用累计的黑名单数据,挖掘历史数据的相似性规律,寻找历史数据的违法“签名”,使用相似性规则对违法URL进行判别。这些算法常常基于针对页面的动态分析,抓取多次重定向、非常规操作步骤等特征[3,4],因此有一定概率遭受网络攻击。这些算法可在一定程度上弥补黑名单技术仅使用精准碰撞来判别的弊端,但仍然具有规则更新慢、准确率低的缺点,时效性仍然较差。
1.2 机器学习
机器学习算法通过分析URL页面信息,提取页面内容特征,训练预测模型对页面内容进行判别[5-7]。机器学习算法主要分为监督学习和无监督学习两类。监督学习基于标注数据,不断基于已标注URL,提取页面特征进行训练,常用于URL识别的算法有支持向量机(SVM)、随机森林、C5.0等。无监督学习则使用没有标注的数据,通过对无标签样本的学习来揭示数据的内在特性及规律,按照数据的相对标准进行学习。无监督学习的URL识别模型中,常使用聚类方法来进行特征提取,将相似度较高的对象聚到同一个簇,不同簇间相似度较低,以此来区分违法URL和正常URL[8]。
相对启发式学习,使用机器学习方法判别违法URL不必拘泥于历史数据集,基于样本数据训练的模型可以挖掘更多违法URL,具有一定主动性。但“数据决定了机器学习的上限,而算法只是尽可能逼近这个上限”,高度依赖于训练集数据及特征工程的机器学习方法依然有其局限性。要建立价值较高的判别模型,首先需要准确率非常高的样本,且需不断更新,以适应违法URL的更新速度;其次,还需要通过特征工程进行特征构建、特征提取和特征选择,以最大限度地从原始数据中提取特征供算法和模型使用,人工预处理对模型的效果仍然有着至关重要的作用。
1.3 深度学习
深度学习是机器学习的一个分支,是一种基于对数据进行表征学习的算法。相较于需要大量人工参与进行特征工程的机器学习,深度学习预处理工作较少,使用非监督式或半监督式的特征学习和高效分层特征提取算法来代替人工,可以实现自动提取数据中包含的特征,避免人工耗费和可能出现的主观错误,本文使用的卷积神经网络(CNN)即为常用的一种深度学习算法[1,9,10]。
CNN与普通神经网络非常相似,由可学习的权重和偏置常量神经元组成。每个神经元都接收一些输入,并做点积计算,输出是每个分类的分数。卷积神经网络常应用于计算机视觉和自然语言处理领域,它能将大信息量数据在不影响结果的前提下降维为小量数据,并保留数据特征。CNN包含卷积层、池化层和全连接层。卷积层对信息的局部进行提取,保留數据的重要特征,类似于人类视觉原理,在每一小块中深入分析从而得到抽象程度更高的特征;池化层即下采样,通过数据降维减少运算量,可以有效避免过拟合;全连接层则根据算法需要,输出最终结果。CNN通过叠加上述三种结构,设计出适合应用场景的算法。
2 基于字符级卷积神经网络的违法URL识别模型与实现
字符级别的卷积神经网络,即Character-level Convolutional Networks(Char-CNN)。相较于基于短语和单词的自然语言处理算法,Char-CNN从字符粒度训练神经网络,不需要预先掌握单词、语法和语义知识,可以跨语言使用。不同于普通文本文章,URL文本较短,可提取信息量有限,且URL生成方式多样,多数不以单词为基本单位组成,缺乏语法语义特征,故对于URL的判别,使用字符作为基本单位是更加合适的信息挖掘方式[1,11]。
Char-CNN识别算法分为生成嵌入式表示、特征挖掘和分类三个阶段。生成特征图像环节需固定URL长度,将输入URL通过索引方式生成输入神经网络的二维张量;特征挖掘通过多个尺寸的卷积层,提取URL编辑距离、前后顺序等重要信息,并将这些信息合成为一个固定长度的特征向量;最后,被提取的信息通过全连接层进行判别分类。
图1为模型流程,整个算法由训练和预测两部分构成。在模型训练完成后,我们使用测试集对模型进行评估,通过准确率、召回率、F1值对模型进行评价,并依据结果对模型进行参数和层数调整。下面将详细阐述模型的训练过程。
2.1 生成特征图像
模型使用单个字符作为语义单元,单条URL可以看作是一个由基本语义单元组成的普通语句。根据RFC3986编码规范,URL只允许包含英文字母(a-zA-Z)、数字(0-9)、-_.~4个特殊字符以及所有保留字符!*'();:@&=+$,/?#[],共计84个有效字符[12]。在本次实验中,我们尝试将所有大写字母转换为小写字母,即使用58个有效字符,作为模型的语料库,同时,考虑到可能出现的非法字符,我们另增加一个词语unknown作为非法字符的表示,若出现语料库之外的字符,则使用unknown作为代替。
卷积神经网络最初运用于计算机视觉领域,对数据输入大小有一定要求,例如在LeNet-5中,每个输入都是[32×32]的图像文件[10]。一旦图像分辨率发生了变化,造成多余卷积操作结果丢失,就会对模型结果产生影响,或者使得网络内部状态发生混乱,在图像处理中,主要通过设置输入图像固定分辨率来解决这个问题。但是,在自然语言处理中,由于输入的是文档或者语句,输入内容长度是不固定的,通常采用截断过长文本、填充不足文本的方式进行处理,以保持文本长度的一致性[8]。不同于普通文本,URL的前半部分相对于后半部分而言包含的有用的信息更多,本实验中我们选择从后段进行截断或者填充。在对实验数据进行预处理和统计分析后发现数据集中95%的URL的字符数小于等于80个字符,使用80作为输入长度可以保留绝大部分实验样本的信息,在本文模型试验中,长度长于80个字符的URL从尾部进行截断,短于80的使用填充字符填充。
由于URL语料库较小,不会造成维度灾难,为方便实验,使用1-60代表语料库中60个字符(59个原始字符及1个填充字符)建立索引,根据索引使用一个一维向量对URL中字符进行表示,使得每条URL都生成一个[80×60]特征图像,输入后续的卷积层中。
2.2 特征挖掘
实验使用CNN作为分类模型,将上述阶段生成的特征图像作为输入,进行特征挖掘和分类。特征挖掘过程包含多个并列的卷积层[Convt, k]和对应的池化层,其中[t]为卷积核个数,[k]为卷积层大小。为提取足够多的上下文信息,实验中使用多个不同大小的卷积层,设置[k∈2, 3, 4, 5],并依据经验设置[t]值为256。
特征挖掘过程中,设初始输入一个长度为[M]的URL字符串,一个大小为[k]的卷积核应用到[第i]个长度为[k]的窗口上,将生成一个新特征[zi],新特征[zi]生成计算式如下文所示,其中[ωm]表示卷积核的[m]位置的权重,[xi:i+k-1]表示URL从[i]位置到[i+k-1]位置的字符数据,[b]是偏置项,[f]是一个非线性函数,实验使用RELU作为激活函数。
[zi=fm=0M-k-1ωm×xi:i+k-1+b] (1)
每一个卷积层对应一个最大池化层,只保留区域内的最大特征,忽略其他值,以降低噪声的影响、提高模型健壮性、避免过拟合。实验中256个卷积核在经过池化层后会得到256个[1×1]维度的输出,4个大小为[1×256]的卷积层输出结果将拼接展开为一个长度为1024的向量,进入RELU全连接层后再接一个sigmoid全连接层,最后输出二分类结果。
2.3 过拟合处理
在深度学习中,经常会出现某些神经元比另一些神经元具有更重要的预测能力,这种现象导致预测模型过度依赖于个别神经元以致模型对新样本的预测能力较差,通常使用dropout解决该问题,即随机移除神经网络中的一些神经元,防止过拟合,同时实现提高模型训练速度。在本文模型实验中,我们增加了Spatial dropout,并依据经验设置dropout参数为0.5,每个卷积层在经过池化后和第一次经过全连接层后做一次dropout,以防止本实验样本量不大的情况下出现过拟合。
然而,在实际实验中,因为初始epoch值设置过大,依然出现了过拟合问题。因此,除去dropout,在实验中我们还设置了早停机制,以解决epoch数量需要手动设置的问题,即使用一个及时停止的标准来提前结束训练,使模型尽可能产生最低的泛化错误[13]。具体过程如下所示。
1)将原始训练数据集划分成训练集和验证集。
2)只在训练集上进行训练,在验证集上进行验证并计算误差。实验中,我们使用100步作为计算周期,即每100步计算一次验证集误差,并统计比较验证集历史最低误差值。
3)当模型效果经过多轮训练后无明显提升时,结束实验。实验中,我们设置模型训练效果在1000轮后仍未提升,则结束训练。
4)使用最后一次迭代参数作为模型最终参数,生成预测模型。
3 实验
3.1 实验数据及评估标准
本次实验违法样本数据来源于公安、互联网安全公司,包含赌博、色情、诈骗等违法URL数据共70648条。合法样本则使用爬虫从Alexa爬取,共70571条数据。实验共包含141219条URL数据。
实验使用准确率、召回率及F1值对模型进行评估。由于实际运用中,违法网站被错误识别为合法网站可能产生较大风险,故在对比算法准确程度时,本文使用召回率作为主要評价标注。
3.2 实验结果及分析
本文实验使用一台Centos 7服务器进行训练,服务器均安装python3.7.7及TensorFlow 2.0.0软件环境,使用scikit-learn对实验结果进行评估。
实验设置训练集、验证集及测试集样本比例为8:1:1。为防止过拟合问题,设置1000步为早停参数,每100步使用当前模型对验证集进行测试,若1000步后模型对验证集预测的准确率没有提升,则停止训练。
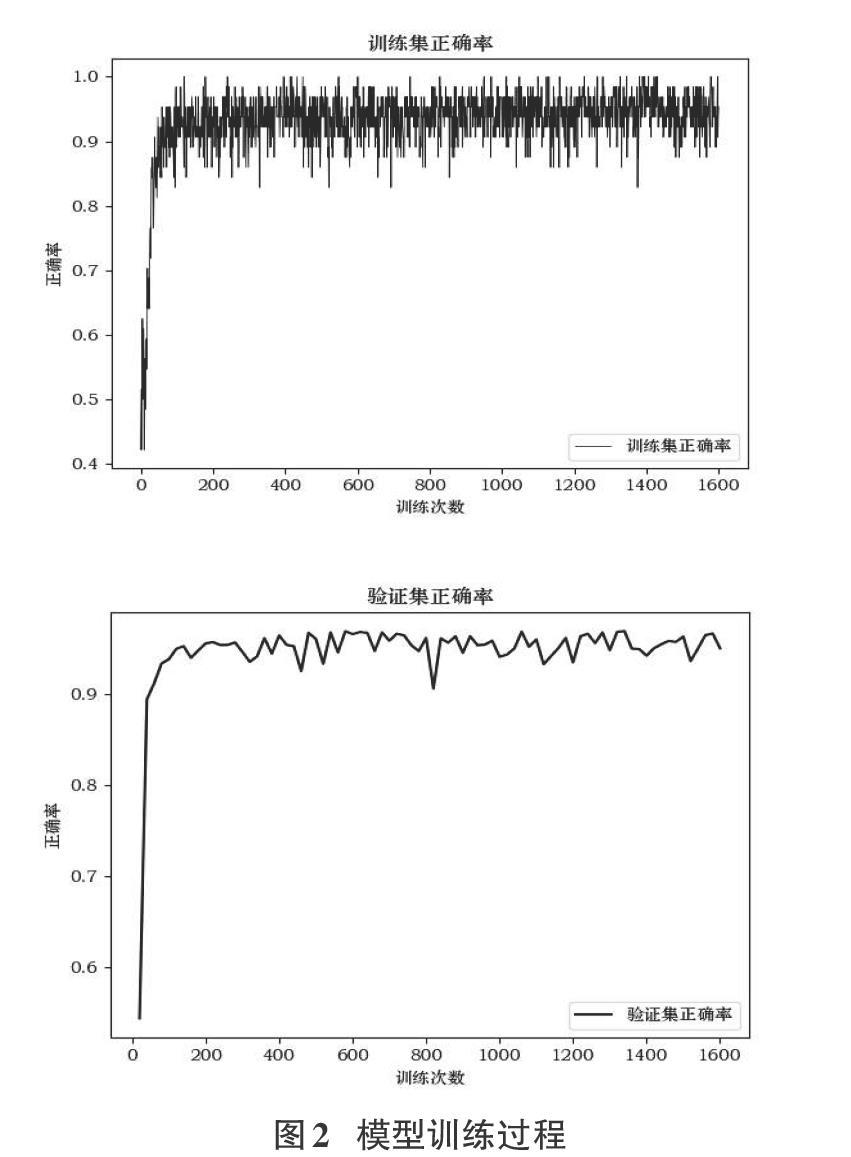
图2为模型训练过程,试验中,约400步后准确率逐渐稳定于0.95。由于实验加入了早停机制,验证集正确率未因epoch值设置有误出现明显过拟合。
表1为训练完成后准确率、召回率及F1值,表2为测试集上的混淆矩阵。在实验测试集上,完成训练后的模型准确率达到0.980,召回率达到0.987,F1值为0.983,三个判别评价标准均显示出良好的模型拟合效果。
实验中,早停机制发挥出了极大效果。前期测试中,因epoch设置过大,训练过程耗时过长,超过10个小时,且验证集准确率一度低于0.6。因此,对于该类型数据集而言,加入过拟合机制尤为重要。经试验,在本文数据集上,当全连接层核数为1024,截断长度为80,批处理数量为128,学习率为0.005时,试验效果最好。
4 结语
URL作为大量网络违法犯罪过程中的要素信息之一,实时识别并阻断违法网络请求可有效降低犯罪行为的发生,当前,各类模型和算法识别违法URL的效果还有待提高,但是计算机智能模型作为快速识别、自动处置的手段之一,具有较高的工程应用价值。本文针对如何利用机器学习算法进行违法URL识别的问题,提出了一种基于URL字符串的深度学习分类算法,并利用TensorFlow进行了代码实现。实验证明, 本文提出的违法URL识别分类方法, 在准确率与召回率方面都达到了较好的效果。目前模型仅实现了违法URL识别的二分类,主要用于判断URL是否为违法,随着数据的积累,我们将开展多分类模型研究,识别违法URL具体类型,促进网络违法行为的精确识别。
参考文献:
[1] ZhangXiang,ZhaoJun-bo,LeCunYann.Character-level Convolutional Networksfor Text Classification[J].NIPS'15:Proceedings of the 28th International Conferenceon Neural Information Processing Systems-Volume1,2015(12):649-657.
[2] KivinenJ,Smola A J,Williamson R C.Online learning with kernels[J].IEEE Transactions on Signal Processing,2004,52(8):2165-2176.
[3] Moshchuk Alexander,Bragin Tanya,Deville Damien,GribbleSteven D,Levy Henry M.SpyProxy:Executionbased Detection of Malicious Web Content[M].In Proceeding of the 16th USENIX Security Symposium.Berkeley,CA,United States:USENIX Association,2007:27-42.
[4] Khonji M,Iraqi Y,Jones A.Phishing detection:a literature survey[J].IEEE Communications Surveys&Tutorials,2013,15(4):2091-2121.
[5] PatilDharmaraj Rajaram,Patil J B.Surveyon Malicious Web Pages Detection Techniques[J].International Journal of uande Service,Science and Technology,2015,8(5):195-206
[6] 沙泓州,劉庆云,柳厅文,等.恶意网页识别研究综述[J].计算机学报,2016,39(3):529-542.
[7] 凡友荣,杨涛,王永剑,等.基于URL特征检测的违法网站识别方法[J].计算机工程,2018,44(3):171-177.
[8] Kim,Y.ConvolutionalNeuralNetworksforSentenceClassification[M].Proceedingsof the 2014ConferenceonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP),Doha,Qatar:Association for Computational Linguistics,2014:1746-1751.
[9] Sinha S,Bailey M,Jahanian F.Shades of grey: On the effectiveness of reputation-based “blacklists”[C]//2008 3rd International Conference on Malicious and Unwanted Software (MALWARE).October 7-8,2008,Alexandria,VA,USA.IEEE,2008:57-64.
[10] LeCun Y,BottouL,Bengio Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.
[11] 陈康,付华峥,向勇.基于深度学习的恶意URL识别[J].计算机系统应用,2018,27(6):27-33.
[12] Internet Engineering Task Force.Uniform Resource Identifier(URI):GenericSyntax(RFC3986)[Z].2005.
[13] Prechelt Lutz.Early Stopping But When?[M].Neural Networks:Tricks of the Trade,volume1524of LNCS,chapter2,Berlin:Springer Verlag,1997:55-69.
【通联编辑:唐一东】
